 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$C^2$: Scalable Auto-Feedback for LLM-based Chart Generation
Oct 24, 2024



Generating high-quality charts with Large Language Models presents significant challenges due to limited data and the high cost of scaling through human curation. Instruction, data, and code triplets are scarce and expensive to manually curate as their creation demands technical expertise. To address this scalability issue, we introduce a reference-free automatic feedback generator, which eliminates the need for costly human intervention. Our novel framework, $C^2$, consists of (1) an automatic feedback provider (ChartAF) and (2) a diverse, reference-free dataset (ChartUIE-8K). Quantitative results are compelling: in our first experiment, 74% of respondents strongly preferred, and 10% preferred, the results after feedback. The second post-feedback experiment demonstrates that ChartAF outperforms nine baselines. Moreover, ChartUIE-8K significantly improves data diversity by increasing queries, datasets, and chart types by 5982%, 1936%, and 91%, respectively, over benchmarks. Finally, an LLM user study revealed that 94% of participants preferred ChartUIE-8K's queries, with 93% deeming them aligned with real-world use cases. Core contributions are available as open-source at an anonymized project site, with ample qualitative examples.
Carpe Diem: On the Evaluation of World Knowledge in Lifelong Language Models
Nov 14, 2023



In an ever-evolving world, the dynamic nature of knowledge presents challenges for language models that are trained on static data, leading to outdated encoded information. However, real-world scenarios require models not only to acquire new knowledge but also to overwrite outdated information into updated ones. To address this under-explored issue, we introduce the temporally evolving question answering benchmark, EvolvingQA - a novel benchmark designed for training and evaluating LMs on an evolving Wikipedia database, where the construction of our benchmark is automated with our pipeline using large language models. Our benchmark incorporates question-answering as a downstream task to emulate real-world applications. Through EvolvingQA, we uncover that existing continual learning baselines have difficulty in updating and forgetting outdated knowledge. Our findings suggest that the models fail to learn updated knowledge due to the small weight gradient. Furthermore, we elucidate that the models struggle mostly on providing numerical or temporal answers to questions asking for updated knowledge. Our work aims to model the dynamic nature of real-world information, offering a robust measure for the evolution-adaptability of language models.
HARE: Explainable Hate Speech Detection with Step-by-Step Reasoning
Nov 01, 2023



With the proliferation of social media, accurate detection of hate speech has become critical to ensure safety online. To combat nuanced forms of hate speech, it is important to identify and thoroughly explain hate speech to help users understand its harmful effects. Recent benchmarks have attempted to tackle this issue by training generative models on free-text annotations of implications in hateful text. However, we find significant reasoning gaps in the existing annotations schemes, which may hinder the supervision of detection models. In this paper, we introduce a hate speech detection framework, HARE, which harnesses the reasoning capabilities of large language models (LLMs) to fill these gaps in explanations of hate speech, thus enabling effective supervision of detection models. Experiments on SBIC and Implicit Hate benchmarks show that our method, using model-generated data, consistently outperforms baselines, using existing free-text human annotations. Analysis demonstrates that our method enhances the explanation quality of trained models and improves generalization to unseen datasets. Our code is available at https://github.com/joonkeekim/hare-hate-speech.git.
Mitigating Dataset Bias by Using Per-sample Gradient
Jun 07, 2022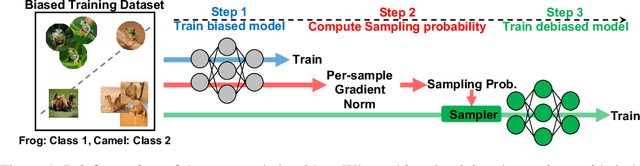


The performance of deep neural networks is strongly influenced by the training dataset setup. In particular, when attributes having a strong correlation with the target attribute are present, the trained model can provide unintended prejudgments and show significant inference errors (i.e., the dataset bias problem). Various methods have been proposed to mitigate dataset bias, and their emphasis is on weakly correlated samples, called bias-conflicting samples. These methods are based on explicit bias labels involving human or empirical correlation metrics (e.g., training loss). However, such metrics require human costs or have insufficient theoretical explanation. In this study, we propose a debiasing algorithm, called PGD (Per-sample Gradient-based Debiasing), that comprises three steps: (1) training a model on uniform batch sampling, (2) setting the importance of each sample in proportion to the norm of the sample gradient, and (3) training the model using importance-batch sampling, whose probability is obtained in step (2). Compared with existing baselines for various synthetic and real-world datasets, the proposed method showed state-of-the-art accuracy for a the classification task. Furthermore, we describe theoretical understandings about how PGD can mitigate dataset bias.