 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Next-gen traffic surveillance: AI-assisted mobile traffic violation detection system
Nov 24, 2023
Road traffic accidents pose a significant global public health concern, leading to injuries, fatalities, and vehicle damage. Approximately 1,3 million people lose their lives daily due to traffic accidents [World Health Organization, 2022]. Addressing this issue requires accurate traffic law violation detection systems to ensure adherence to regulations. The integration of Artificial Intelligence algorithms, leveraging machine learning and computer vision, has facilitated the development of precise traffic rule enforcement. This paper illustrates how computer vision and machine learning enable the creation of robust algorithms for detecting various traffic violations. Our model, capable of identifying six common traffic infractions, detects red light violations, illegal use of breakdown lanes, violations of vehicle following distance, breaches of marked crosswalk laws, illegal parking, and parking on marked crosswalks. Utilizing online traffic footage and a self-mounted on-dash camera, we apply the YOLOv5 algorithm's detection module to identify traffic agents such as cars, pedestrians, and traffic signs, and the strongSORT algorithm for continuous interframe tracking. Six discrete algorithms analyze agents' behavior and trajectory to detect violations. Subsequently, an Identification Module extracts vehicle ID information, such as the license plate, to generate violation notices sent to relevant authorities.
Efficient Open-world Reinforcement Learning via Knowledge Distillation and Autonomous Rule Discovery
Nov 24, 2023Deep reinforcement learning suffers from catastrophic forgetting and sample inefficiency making it less applicable to the ever-changing real world. However, the ability to use previously learned knowledge is essential for AI agents to quickly adapt to novelties. Often, certain spatial information observed by the agent in the previous interactions can be leveraged to infer task-specific rules. Inferred rules can then help the agent to avoid potentially dangerous situations in the previously unseen states and guide the learning process increasing agent's novelty adaptation speed. In this work, we propose a general framework that is applicable to deep reinforcement learning agents. Our framework provides the agent with an autonomous way to discover the task-specific rules in the novel environments and self-supervise it's learning. We provide a rule-driven deep Q-learning agent (RDQ) as one possible implementation of that framework. We show that RDQ successfully extracts task-specific rules as it interacts with the world and uses them to drastically increase its learning efficiency. In our experiments, we show that the RDQ agent is significantly more resilient to the novelties than the baseline agents, and is able to detect and adapt to novel situations faster.
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
Nov 24, 2023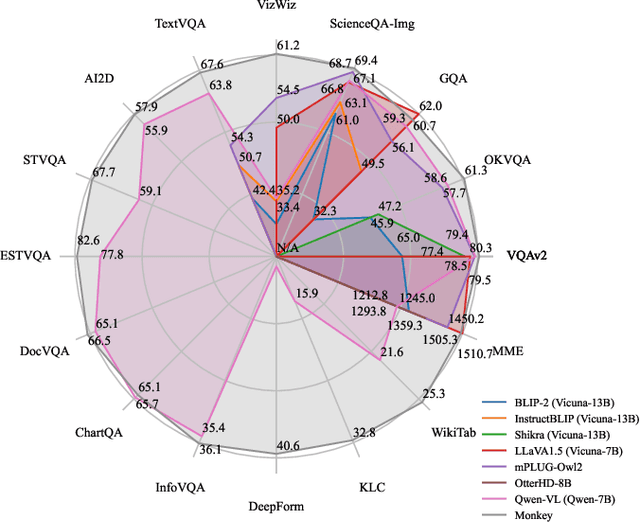
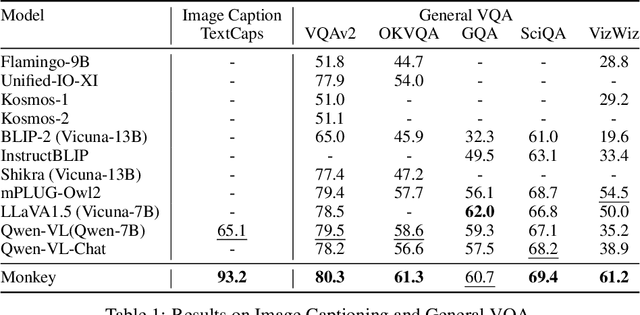
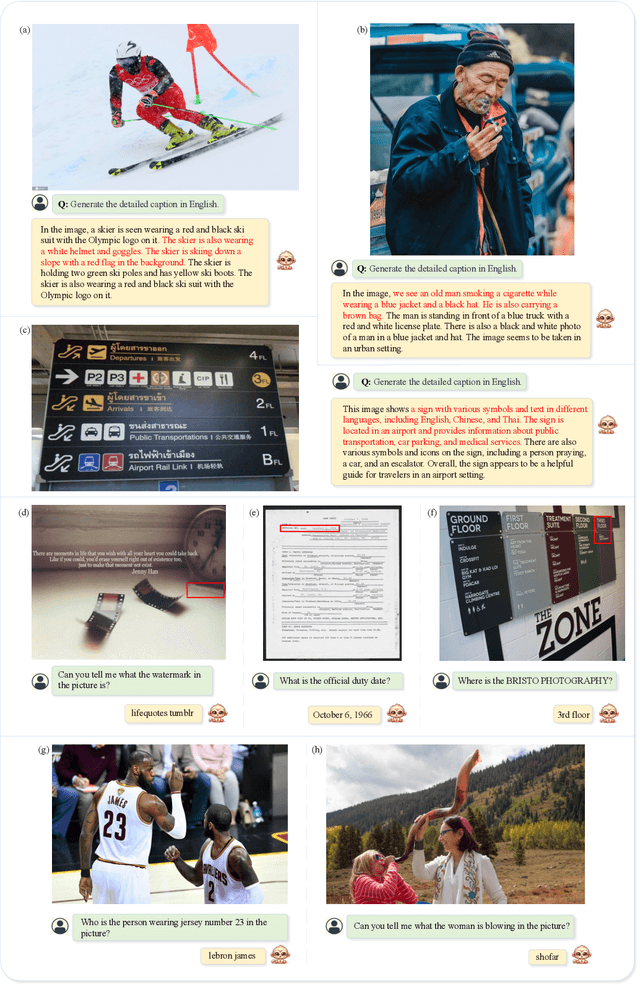
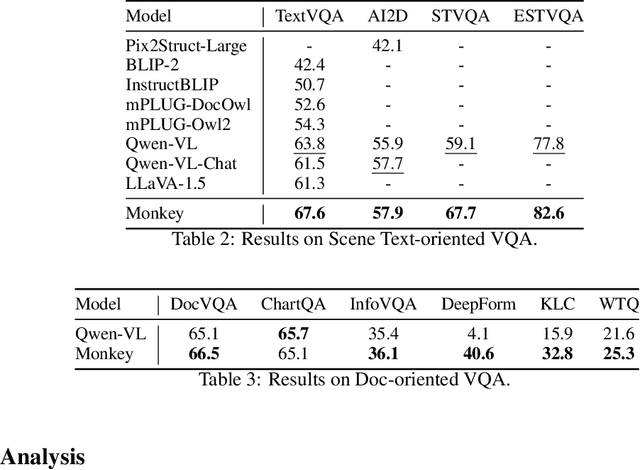
Large Multimodal Models (LMMs) have shown promise in vision-language tasks but struggle with high-resolution input and detailed scene understanding. Addressing these challenges, we introduce Monkey to enhance LMM capabilities. Firstly, Monkey processes input images by dividing them into uniform patches, each matching the size (e.g., 448x448) used in the original training of the well-trained vision encoder. Equipped with individual adapter for each patch, Monkey can handle higher resolutions up to 1344x896 pixels, enabling the detailed capture of complex visual information. Secondly, it employs a multi-level description generation method, enriching the context for scene-object associations. This two-part strategy ensures more effective learning from generated data: the higher resolution allows for a more detailed capture of visuals, which in turn enhances the effectiveness of comprehensive descriptions. Extensive ablative results validate the effectiveness of our designs. Additionally, experiments on 18 datasets further demonstrate that Monkey surpasses existing LMMs in many tasks like Image Captioning and various Visual Question Answering formats. Specially, in qualitative tests focused on dense text question answering, Monkey has exhibited encouraging results compared with GPT4V. Code is available at https://github.com/Yuliang-Liu/Monkey.
Unsupervised Graph Attention Autoencoder for Attributed Networks using K-means Loss
Nov 24, 2023Several natural phenomena and complex systems are often represented as networks. Discovering their community structure is a fundamental task for understanding these networks. Many algorithms have been proposed, but recently, Graph Neural Networks (GNN) have emerged as a compelling approach for enhancing this task.In this paper, we introduce a simple, efficient, and clustering-oriented model based on unsupervised \textbf{G}raph Attention \textbf{A}uto\textbf{E}ncoder for community detection in attributed networks (GAECO). The proposed model adeptly learns representations from both the network's topology and attribute information, simultaneously addressing dual objectives: reconstruction and community discovery. It places a particular emphasis on discovering compact communities by robustly minimizing clustering errors. The model employs k-means as an objective function and utilizes a multi-head Graph Attention Auto-Encoder for decoding the representations. Experiments conducted on three datasets of attributed networks show that our method surpasses state-of-the-art algorithms in terms of NMI and ARI. Additionally, our approach scales effectively with the size of the network, making it suitable for large-scale applications. The implications of our findings extend beyond biological network interpretation and social network analysis, where knowledge of the fundamental community structure is essential.
Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks
Sep 29, 2023
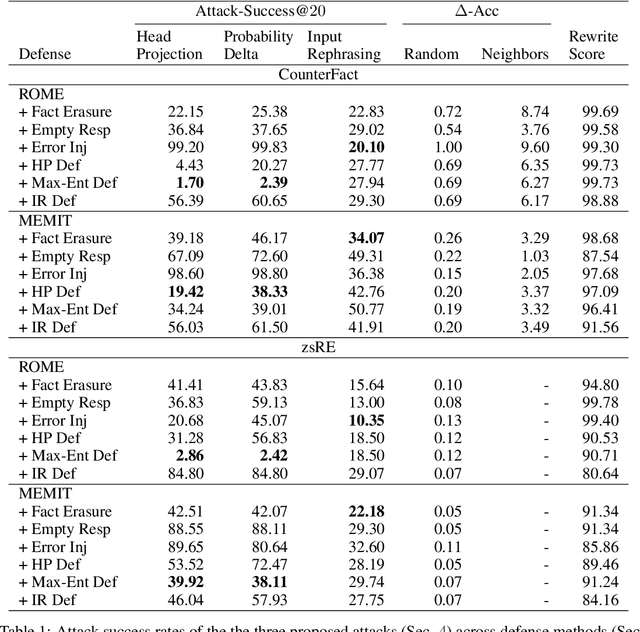
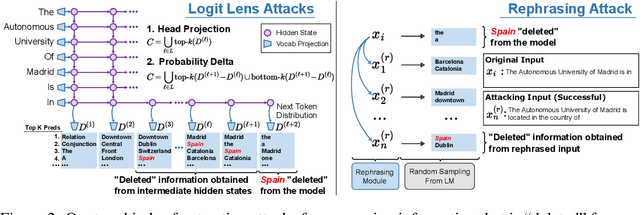

Pretrained language models sometimes possess knowledge that we do not wish them to, including memorized personal information and knowledge that could be used to harm people. They can also output toxic or harmful text. To mitigate these safety and informational issues, we propose an attack-and-defense framework for studying the task of deleting sensitive information directly from model weights. We study direct edits to model weights because (1) this approach should guarantee that particular deleted information is never extracted by future prompt attacks, and (2) it should protect against whitebox attacks, which is necessary for making claims about safety/privacy in a setting where publicly available model weights could be used to elicit sensitive information. Our threat model assumes that an attack succeeds if the answer to a sensitive question is located among a set of B generated candidates, based on scenarios where the information would be insecure if the answer is among B candidates. Experimentally, we show that even state-of-the-art model editing methods such as ROME struggle to truly delete factual information from models like GPT-J, as our whitebox and blackbox attacks can recover "deleted" information from an edited model 38% of the time. These attacks leverage two key observations: (1) that traces of deleted information can be found in intermediate model hidden states, and (2) that applying an editing method for one question may not delete information across rephrased versions of the question. Finally, we provide new defense methods that protect against some extraction attacks, but we do not find a single universally effective defense method. Our results suggest that truly deleting sensitive information is a tractable but difficult problem, since even relatively low attack success rates have potentially severe societal implications for real-world deployment of language models.
TURBO: The Swiss Knife of Auto-Encoders
Nov 11, 2023We present a novel information-theoretic framework, termed as TURBO, designed to systematically analyse and generalise auto-encoding methods. We start by examining the principles of information bottleneck and bottleneck-based networks in the auto-encoding setting and identifying their inherent limitations, which become more prominent for data with multiple relevant, physics-related representations. The TURBO framework is then introduced, providing a comprehensive derivation of its core concept consisting of the maximisation of mutual information between various data representations expressed in two directions reflecting the information flows. We illustrate that numerous prevalent neural network models are encompassed within this framework. The paper underscores the insufficiency of the information bottleneck concept in elucidating all such models, thereby establishing TURBO as a preferable theoretical reference. The introduction of TURBO contributes to a richer understanding of data representation and the structure of neural network models, enabling more efficient and versatile applications.
Can LLMs Effectively Leverage Graph Structural Information: When and Why
Sep 29, 2023
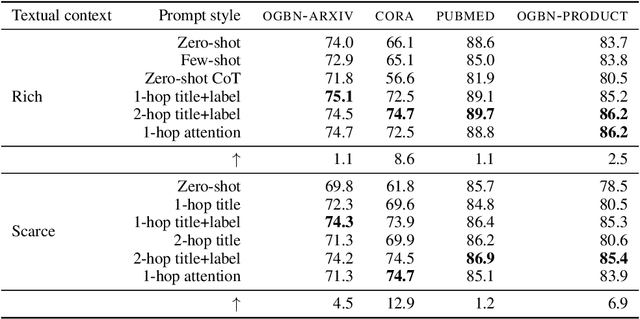
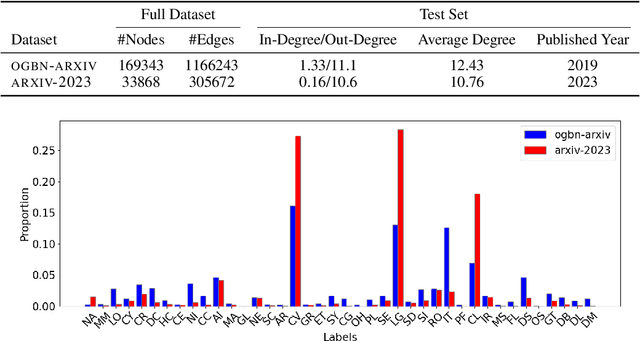
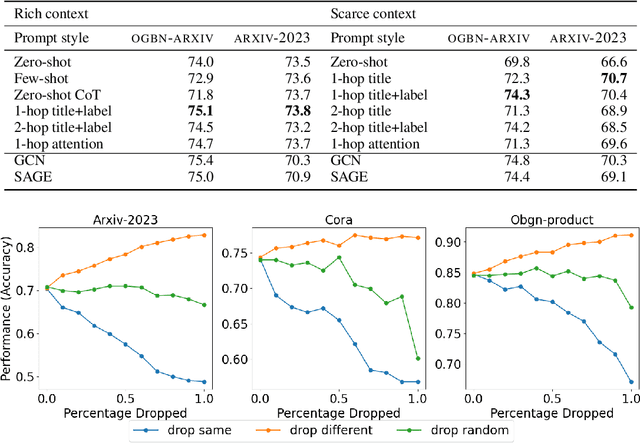
This paper studies Large Language Models (LLMs) augmented with structured data--particularly graphs--a crucial data modality that remains underexplored in the LLM literature. We aim to understand when and why the incorporation of structural information inherent in graph data can improve the prediction performance of LLMs on node classification tasks with textual features. To address the ``when'' question, we examine a variety of prompting methods for encoding structural information, in settings where textual node features are either rich or scarce. For the ``why'' questions, we probe into two potential contributing factors to the LLM performance: data leakage and homophily. Our exploration of these questions reveals that (i) LLMs can benefit from structural information, especially when textual node features are scarce; (ii) there is no substantial evidence indicating that the performance of LLMs is significantly attributed to data leakage; and (iii) the performance of LLMs on a target node is strongly positively related to the local homophily ratio of the node\footnote{Codes and datasets are at: \url{https://github.com/TRAIS-Lab/LLM-Structured-Data}}.
Thinking Outside the Box: Orthogonal Approach to Equalizing Protected Attributes
Nov 21, 2023There is growing concern that the potential of black box AI may exacerbate health-related disparities and biases such as gender and ethnicity in clinical decision-making. Biased decisions can arise from data availability and collection processes, as well as from the underlying confounding effects of the protected attributes themselves. This work proposes a machine learning-based orthogonal approach aiming to analyze and suppress the effect of the confounder through discriminant dimensionality reduction and orthogonalization of the protected attributes against the primary attribute information. By doing so, the impact of the protected attributes on disease diagnosis can be realized, undesirable feature correlations can be mitigated, and the model prediction performance can be enhanced.
SegVol: Universal and Interactive Volumetric Medical Image Segmentation
Nov 22, 2023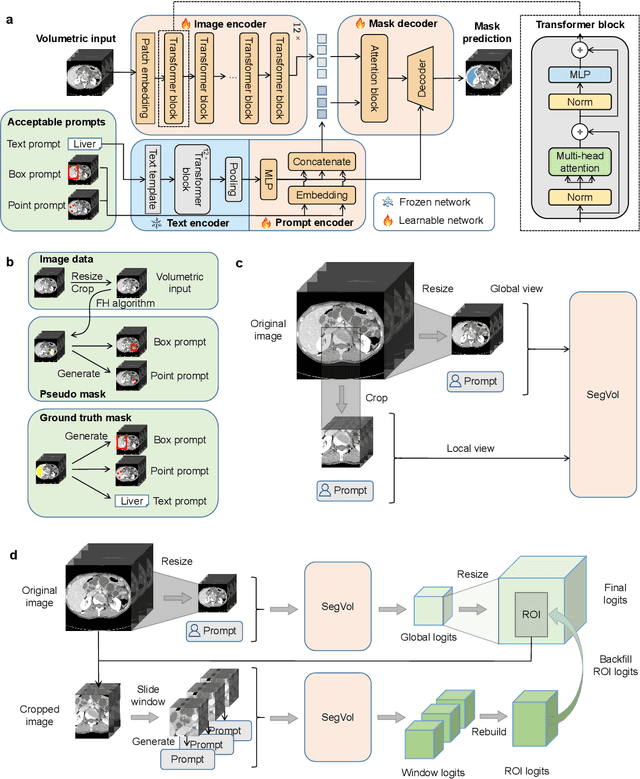
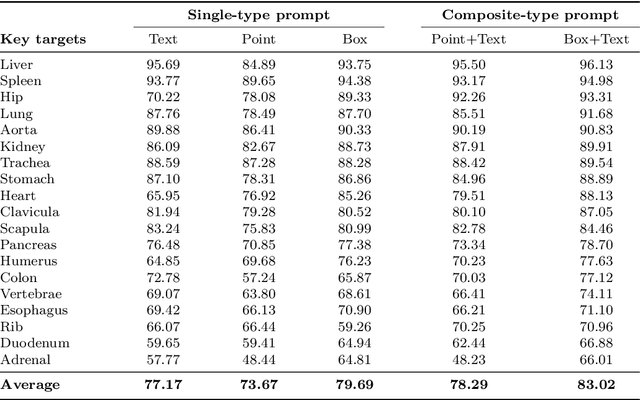
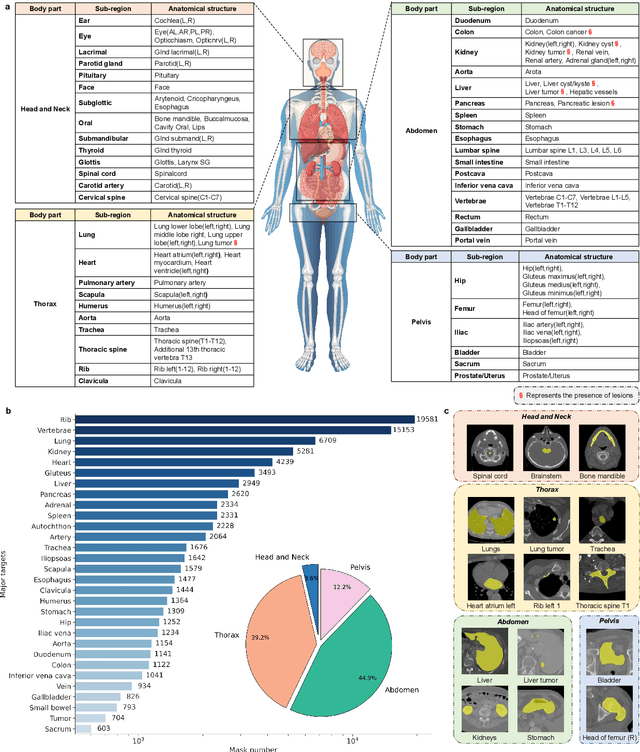
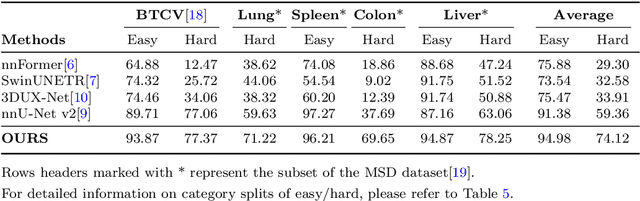
Precise image segmentation provides clinical study with meaningful and well-structured information. Despite the remarkable progress achieved in medical image segmentation, there is still an absence of foundation segmentation model that can segment a wide range of anatomical categories with easy user interaction. In this paper, we propose a universal and interactive volumetric medical image segmentation model, named SegVol. By training on 90k unlabeled Computed Tomography (CT) volumes and 6k labeled CTs, this foundation model supports the segmentation of over 200 anatomical categories using semantic and spatial prompts. Extensive experiments verify that SegVol outperforms the state of the art by a large margin on multiple segmentation benchmarks. Notably, on three challenging lesion datasets, our method achieves around 20% higher Dice score than nnU-Net. The model and data are publicly available at: https://github.com/BAAI-DCAI/SegVol.
PIE-NeRF: Physics-based Interactive Elastodynamics with NeRF
Nov 22, 2023We show that physics-based simulations can be seamlessly integrated with NeRF to generate high-quality elastodynamics of real-world objects. Unlike existing methods, we discretize nonlinear hyperelasticity in a meshless way, obviating the necessity for intermediate auxiliary shape proxies like a tetrahedral mesh or voxel grid. A quadratic generalized moving least square (Q-GMLS) is employed to capture nonlinear dynamics and large deformation on the implicit model. Such meshless integration enables versatile simulations of complex and codimensional shapes. We adaptively place the least-square kernels according to the NeRF density field to significantly reduce the complexity of the nonlinear simulation. As a result, physically realistic animations can be conveniently synthesized using our method for a wide range of hyperelastic materials at an interactive rate. For more information, please visit our project page at https://fytalon.github.io/pienerf/.