 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
KhabarChin: Automatic Detection of Important News in the Persian Language
Dec 06, 2023
Being aware of important news is crucial for staying informed and making well-informed decisions efficiently. Natural Language Processing (NLP) approaches can significantly automate this process. This paper introduces the detection of important news, in a previously unexplored area, and presents a new benchmarking dataset (Khabarchin) for detecting important news in the Persian language. We define important news articles as those deemed significant for a considerable portion of society, capable of influencing their mindset or decision-making. The news articles are obtained from seven different prominent Persian news agencies, resulting in the annotation of 7,869 samples and the creation of the dataset. Two challenges of high disagreement and imbalance between classes were faced, and solutions were provided for them. We also propose several learning-based models, ranging from conventional machine learning to state-of-the-art transformer models, to tackle this task. Furthermore, we introduce the second task of important sentence detection in news articles, as they often come with a significant contextual length that makes it challenging for readers to identify important information. We identify these sentences in a weakly supervised manner.
GCFA:Geodesic Curve Feature Augmentation via Shape Space Theory
Dec 06, 2023Deep learning has yielded remarkable outcomes in various domains. However, the challenge of requiring large-scale labeled samples still persists in deep learning. Thus, data augmentation has been introduced as a critical strategy to train deep learning models. However, data augmentation suffers from information loss and poor performance in small sample environments. To overcome these drawbacks, we propose a feature augmentation method based on shape space theory, i.e., Geodesic curve feature augmentation, called GCFA in brevity. First, we extract features from the image with the neural network model. Then, the multiple image features are projected into a pre-shape space as features. In the pre-shape space, a Geodesic curve is built to fit the features. Finally, the many generated features on the Geodesic curve are used to train the various machine learning models. The GCFA module can be seamlessly integrated with most machine learning methods. And the proposed method is simple, effective and insensitive for the small sample datasets. Several examples demonstrate that the GCFA method can greatly improve the performance of the data preprocessing model in a small sample environment.
Channel-Transferable Semantic Communications for Multi-User OFDM-NOMA Systems
Dec 06, 2023Semantic communications are expected to become the core new paradigms of the sixth generation (6G) wireless networks. Most existing works implicitly utilize channel information for codecs training, which leads to poor communications when channel type or statistical characteristics change. To tackle this issue posed by various channels, a novel channel-transferable semantic communications (CT-SemCom) framework is proposed, which adapts the codecs learned on one type of channel to other types of channels. Furthermore, integrating the proposed framework and the orthogonal frequency division multiplexing systems integrating non-orthogonal multiple access technologies, i.e., OFDM-NOMA systems, a power allocation problem to realize the transfer from additive white Gaussian noise (AWGN) channels to multi-subcarrier Rayleigh fading channels is formulated. We then design a semantics-similar dual transformation (SSDT) algorithm to derive analytical solutions with low complexity. Simulation results show that the proposed CT-SemCom framework with SSDT algorithm significantly outperforms the existing work w.r.t. channel transferability, e.g., the peak signal-to-noise ratio (PSNR) of image transmission improves by 4.2-7.3 dB under different variances of Rayleigh fading channels.
Balanced Marginal and Joint Distributional Learning via Mixture Cramer-Wold Distance
Dec 06, 2023


In the process of training a generative model, it becomes essential to measure the discrepancy between two high-dimensional probability distributions: the generative distribution and the ground-truth distribution of the observed dataset. Recently, there has been growing interest in an approach that involves slicing high-dimensional distributions, with the Cramer-Wold distance emerging as a promising method. However, we have identified that the Cramer-Wold distance primarily focuses on joint distributional learning, whereas understanding marginal distributional patterns is crucial for effective synthetic data generation. In this paper, we introduce a novel measure of dissimilarity, the mixture Cramer-Wold distance. This measure enables us to capture both marginal and joint distributional information simultaneously, as it incorporates a mixture measure with point masses on standard basis vectors. Building upon the mixture Cramer-Wold distance, we propose a new generative model called CWDAE (Cramer-Wold Distributional AutoEncoder), which shows remarkable performance in generating synthetic data when applied to real tabular datasets. Furthermore, our model offers the flexibility to adjust the level of data privacy with ease.
Inverse Design of Vitrimeric Polymers by Molecular Dynamics and Generative Modeling
Dec 06, 2023Vitrimer is a new class of sustainable polymers with the ability of self-healing through rearrangement of dynamic covalent adaptive networks. However, a limited choice of constituent molecules restricts their property space, prohibiting full realization of their potential applications. Through a combination of molecular dynamics (MD) simulations and machine learning (ML), particularly a novel graph variational autoencoder (VAE) model, we establish a method for generating novel vitrimers and guide their inverse design based on desired glass transition temperature (Tg). We build the first vitrimer dataset of one million and calculate Tg on 8,424 of them by high-throughput MD simulations calibrated by a Gaussian process model. The proposed VAE employs dual graph encoders and a latent dimension overlapping scheme which allows for individual representation of multi-component vitrimers. By constructing a continuous latent space containing necessary information of vitrimers, we demonstrate high accuracy and efficiency of our framework in discovering novel vitrimers with desirable Tg beyond the training regime. The proposed vitrimers with reasonable synthesizability cover a wide range of Tg and broaden the potential widespread usage of vitrimeric materials.
DreamComposer: Controllable 3D Object Generation via Multi-View Conditions
Dec 06, 2023Utilizing pre-trained 2D large-scale generative models, recent works are capable of generating high-quality novel views from a single in-the-wild image. However, due to the lack of information from multiple views, these works encounter difficulties in generating controllable novel views. In this paper, we present DreamComposer, a flexible and scalable framework that can enhance existing view-aware diffusion models by injecting multi-view conditions. Specifically, DreamComposer first uses a view-aware 3D lifting module to obtain 3D representations of an object from multiple views. Then, it renders the latent features of the target view from 3D representations with the multi-view feature fusion module. Finally the target view features extracted from multi-view inputs are injected into a pre-trained diffusion model. Experiments show that DreamComposer is compatible with state-of-the-art diffusion models for zero-shot novel view synthesis, further enhancing them to generate high-fidelity novel view images with multi-view conditions, ready for controllable 3D object reconstruction and various other applications.
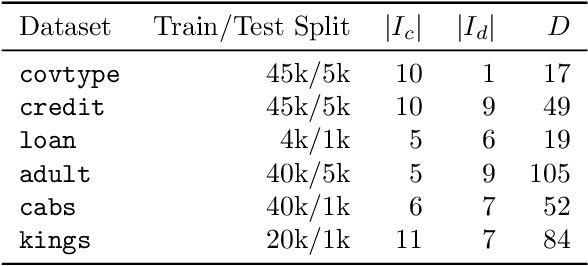
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Dec 03, 2023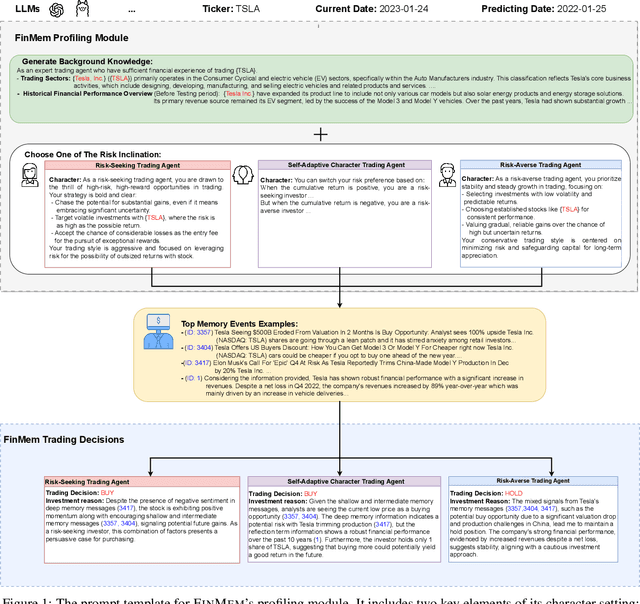
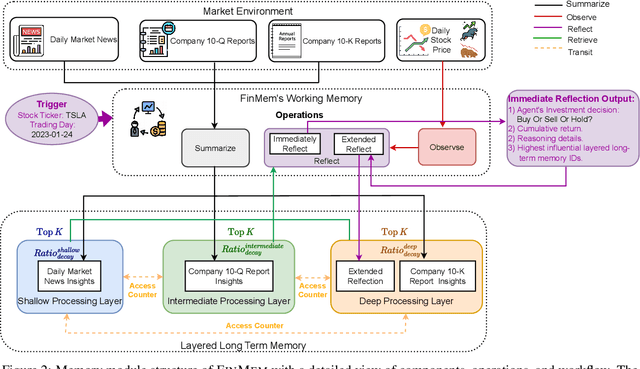
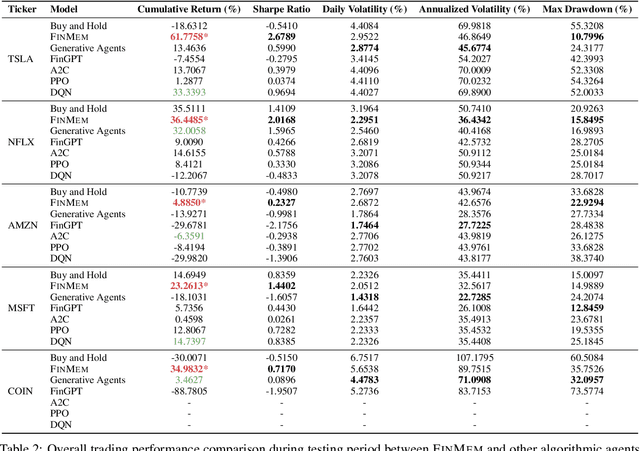

Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMem}, a novel LLM-based agent framework devised for financial decision-making. It encompasses three core modules: Profiling, to customize the agent's characteristics; Memory, with layered message processing, to aid the agent in assimilating hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMem}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMem} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks. We then fine-tuned the agent's perceptual span and character setting to achieve a significantly enhanced trading performance. Collectively, \textsc{FinMem} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
Visual Encoders for Data-Efficient Imitation Learning in Modern Video Games
Dec 04, 2023Video games have served as useful benchmarks for the decision making community, but going beyond Atari games towards training agents in modern games has been prohibitively expensive for the vast majority of the research community. Recent progress in the research, development and open release of large vision models has the potential to amortize some of these costs across the community. However, it is currently unclear which of these models have learnt representations that retain information critical for sequential decision making. Towards enabling wider participation in the research of gameplaying agents in modern games, we present a systematic study of imitation learning with publicly available visual encoders compared to the typical, task-specific, end-to-end training approach in Minecraft, Minecraft Dungeons and Counter-Strike: Global Offensive.
Exploring a Hybrid Deep Learning Framework to Automatically Discover Topic and Sentiment in COVID-19 Tweets
Dec 02, 2023COVID-19 has created a major public health problem worldwide and other problems such as economic crisis, unemployment, mental distress, etc. The pandemic is deadly in the world and involves many people not only with infection but also with problems, stress, wonder, fear, resentment, and hatred. Twitter is a highly influential social media platform and a significant source of health-related information, news, opinion and public sentiment where information is shared by both citizens and government sources. Therefore an effective analysis of COVID-19 tweets is essential for policymakers to make wise decisions. However, it is challenging to identify interesting and useful content from major streams of text to understand people's feelings about the important topics of the COVID-19 tweets. In this paper, we propose a new \textit{framework} for analyzing topic-based sentiments by extracting key topics with significant labels and classifying positive, negative, or neutral tweets on each topic to quickly find common topics of public opinion and COVID-19-related attitudes. While building our model, we take into account hybridization of BiLSTM and GRU structures for sentiment analysis to achieve our goal. The experimental results show that our topic identification method extracts better topic labels and the sentiment analysis approach using our proposed hybrid deep learning model achieves the highest accuracy compared to traditional models.
Adaptive Multi-Modality Prompt Learning
Nov 30, 2023Although current prompt learning methods have successfully been designed to effectively reuse the large pre-trained models without fine-tuning their large number of parameters, they still have limitations to be addressed, i.e., without considering the adverse impact of meaningless patches in every image and without simultaneously considering in-sample generalization and out-of-sample generalization. In this paper, we propose an adaptive multi-modality prompt learning to address the above issues. To do this, we employ previous text prompt learning and propose a new image prompt learning. The image prompt learning achieves in-sample and out-of-sample generalization, by first masking meaningless patches and then padding them with the learnable parameters and the information from texts. Moreover, each of the prompts provides auxiliary information to each other, further strengthening these two kinds of generalization. Experimental results on real datasets demonstrate that our method outperforms SOTA methods, in terms of different downstream tasks.