 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Spectral Characteristics for Single Image Reflection Removal
Sep 16, 2025



Eliminating reflections caused by incident light interacting with reflective medium remains an ill-posed problem in the image restoration area. The primary challenge arises from the overlapping of reflection and transmission components in the captured images, which complicates the task of accurately distinguishing and recovering the clean background. Existing approaches typically address reflection removal solely in the image domain, ignoring the spectral property variations of reflected light, which hinders their ability to effectively discern reflections. In this paper, we start with a new perspective on spectral learning, and propose the Spectral Codebook to reconstruct the optical spectrum of the reflection image. The reflections can be effectively distinguished by perceiving the wavelength differences between different light sources in the spectrum. To leverage the reconstructed spectrum, we design two spectral prior refinement modules to re-distribute pixels in the spatial dimension and adaptively enhance the spectral differences along the wavelength dimension. Furthermore, we present the Spectrum-Aware Transformer to jointly recover the transmitted content in spectral and pixel domains. Experimental results on three different reflection benchmarks demonstrate the superiority and generalization ability of our method compared to state-of-the-art models.
A Scenario-Oriented Survey of Federated Recommender Systems: Techniques, Challenges, and Future Directions
Aug 27, 2025Extending recommender systems to federated learning (FL) frameworks to protect the privacy of users or platforms while making recommendations has recently gained widespread attention in academia. This is due to the natural coupling of recommender systems and federated learning architectures: the data originates from distributed clients (mostly mobile devices held by users), which are highly related to privacy. In a centralized recommender system (CenRec), the central server collects clients' data, trains the model, and provides the service. Whereas in federated recommender systems (FedRec), the step of data collecting is omitted, and the step of model training is offloaded to each client. The server only aggregates the model and other knowledge, thus avoiding client privacy leakage. Some surveys of federated recommender systems discuss and analyze related work from the perspective of designing FL systems. However, their utility drops by ignoring specific recommendation scenarios' unique characteristics and practical challenges. For example, the statistical heterogeneity issue in cross-domain FedRec originates from the label drift of the data held by different platforms, which is mainly caused by the recommender itself, but not the federated architecture. Therefore, it should focus more on solving specific problems in real-world recommendation scenarios to encourage the deployment FedRec. To this end, this review comprehensively analyzes the coupling of recommender systems and federated learning from the perspective of recommendation researchers and practitioners. We establish a clear link between recommendation scenarios and FL frameworks, systematically analyzing scenario-specific approaches, practical challenges, and potential opportunities. We aim to develop guidance for the real-world deployment of FedRec, bridging the gap between existing research and applications.
A Model-agnostic Strategy to Mitigate Embedding Degradation in Personalized Federated Recommendation
Aug 27, 2025Centralized recommender systems encounter privacy leakage due to the need to collect user behavior and other private data. Hence, federated recommender systems (FedRec) have become a promising approach with an aggregated global model on the server. However, this distributed training paradigm suffers from embedding degradation caused by suboptimal personalization and dimensional collapse, due to the existence of sparse interactions and heterogeneous preferences. To this end, we propose a novel model-agnostic strategy for FedRec to strengthen the personalized embedding utility, which is called Personalized Local-Global Collaboration (PLGC). It is the first research in federated recommendation to alleviate the dimensional collapse issue. Particularly, we incorporate the frozen global item embedding table into local devices. Based on a Neural Tangent Kernel strategy that dynamically balances local and global information, PLGC optimizes personalized representations during forward inference, ultimately converging to user-specific preferences. Additionally, PLGC carries on a contrastive objective function to reduce embedding redundancy by dissolving dependencies between dimensions, thereby improving the backward representation learning process. We introduce PLGC as a model-agnostic personalized training strategy for federated recommendations that can be applied to existing baselines to alleviate embedding degradation. Extensive experiments on five real-world datasets have demonstrated the effectiveness and adaptability of PLGC, which outperforms various baseline algorithms.
Large Language Model Empowered Recommendation Meets All-domain Continual Pre-Training
Apr 11, 2025Recent research efforts have investigated how to integrate Large Language Models (LLMs) into recommendation, capitalizing on their semantic comprehension and open-world knowledge for user behavior understanding. These approaches predominantly employ supervised fine-tuning on single-domain user interactions to adapt LLMs for specific recommendation tasks. However, they typically encounter dual challenges: the mismatch between general language representations and domain-specific preference patterns, as well as the limited adaptability to multi-domain recommendation scenarios. To bridge these gaps, we introduce CPRec -- an All-domain Continual Pre-Training framework for Recommendation -- designed to holistically align LLMs with universal user behaviors through the continual pre-training paradigm. Specifically, we first design a unified prompt template and organize users' multi-domain behaviors into domain-specific behavioral sequences and all-domain mixed behavioral sequences that emulate real-world user decision logic. To optimize behavioral knowledge infusion, we devise a Warmup-Stable-Annealing learning rate schedule tailored for the continual pre-training paradigm in recommendation to progressively enhance the LLM's capability in knowledge adaptation from open-world knowledge to universal recommendation tasks. To evaluate the effectiveness of our CPRec, we implement it on a large-scale dataset covering seven domains and conduct extensive experiments on five real-world datasets from two distinct platforms. Experimental results confirm that our continual pre-training paradigm significantly mitigates the semantic-behavioral discrepancy and achieves state-of-the-art performance in all recommendation scenarios. The source code will be released upon acceptance.
Adaptive Multi-Modality Prompt Learning
Nov 30, 2023



Although current prompt learning methods have successfully been designed to effectively reuse the large pre-trained models without fine-tuning their large number of parameters, they still have limitations to be addressed, i.e., without considering the adverse impact of meaningless patches in every image and without simultaneously considering in-sample generalization and out-of-sample generalization. In this paper, we propose an adaptive multi-modality prompt learning to address the above issues. To do this, we employ previous text prompt learning and propose a new image prompt learning. The image prompt learning achieves in-sample and out-of-sample generalization, by first masking meaningless patches and then padding them with the learnable parameters and the information from texts. Moreover, each of the prompts provides auxiliary information to each other, further strengthening these two kinds of generalization. Experimental results on real datasets demonstrate that our method outperforms SOTA methods, in terms of different downstream tasks.
Rethinking the Localization in Weakly Supervised Object Localization
Aug 11, 2023



Weakly supervised object localization (WSOL) is one of the most popular and challenging tasks in computer vision. This task is to localize the objects in the images given only the image-level supervision. Recently, dividing WSOL into two parts (class-agnostic object localization and object classification) has become the state-of-the-art pipeline for this task. However, existing solutions under this pipeline usually suffer from the following drawbacks: 1) they are not flexible since they can only localize one object for each image due to the adopted single-class regression (SCR) for localization; 2) the generated pseudo bounding boxes may be noisy, but the negative impact of such noise is not well addressed. To remedy these drawbacks, we first propose to replace SCR with a binary-class detector (BCD) for localizing multiple objects, where the detector is trained by discriminating the foreground and background. Then we design a weighted entropy (WE) loss using the unlabeled data to reduce the negative impact of noisy bounding boxes. Extensive experiments on the popular CUB-200-2011 and ImageNet-1K datasets demonstrate the effectiveness of our method.
LGViT: Dynamic Early Exiting for Accelerating Vision Transformer
Aug 01, 2023



Recently, the efficient deployment and acceleration of powerful vision transformers (ViTs) on resource-limited edge devices for providing multimedia services have become attractive tasks. Although early exiting is a feasible solution for accelerating inference, most works focus on convolutional neural networks (CNNs) and transformer models in natural language processing (NLP).Moreover, the direct application of early exiting methods to ViTs may result in substantial performance degradation. To tackle this challenge, we systematically investigate the efficacy of early exiting in ViTs and point out that the insufficient feature representations in shallow internal classifiers and the limited ability to capture target semantic information in deep internal classifiers restrict the performance of these methods. We then propose an early exiting framework for general ViTs termed LGViT, which incorporates heterogeneous exiting heads, namely, local perception head and global aggregation head, to achieve an efficiency-accuracy trade-off. In particular, we develop a novel two-stage training scheme, including end-to-end training and self-distillation with the backbone frozen to generate early exiting ViTs, which facilitates the fusion of global and local information extracted by the two types of heads. We conduct extensive experiments using three popular ViT backbones on three vision datasets. Results demonstrate that our LGViT can achieve competitive performance with approximately 1.8 $\times$ speed-up.
Exploring Representativeness and Informativeness for Active Learning
Apr 14, 2019

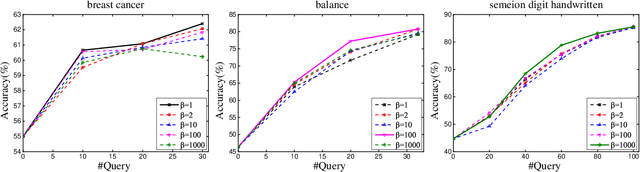

How can we find a general way to choose the most suitable samples for training a classifier? Even with very limited prior information? Active learning, which can be regarded as an iterative optimization procedure, plays a key role to construct a refined training set to improve the classification performance in a variety of applications, such as text analysis, image recognition, social network modeling, etc. Although combining representativeness and informativeness of samples has been proven promising for active sampling, state-of-the-art methods perform well under certain data structures. Then can we find a way to fuse the two active sampling criteria without any assumption on data? This paper proposes a general active learning framework that effectively fuses the two criteria. Inspired by a two-sample discrepancy problem, triple measures are elaborately designed to guarantee that the query samples not only possess the representativeness of the unlabeled data but also reveal the diversity of the labeled data. Any appropriate similarity measure can be employed to construct the triple measures. Meanwhile, an uncertain measure is leveraged to generate the informativeness criterion, which can be carried out in different ways. Rooted in this framework, a practical active learning algorithm is proposed, which exploits a radial basis function together with the estimated probabilities to construct the triple measures and a modified Best-versus-Second-Best strategy to construct the uncertain measure, respectively. Experimental results on benchmark datasets demonstrate that our algorithm consistently achieves superior performance over the state-of-the-art active learning algorithms.
NAIRS: A Neural Attentive Interpretable Recommendation System
Feb 20, 2019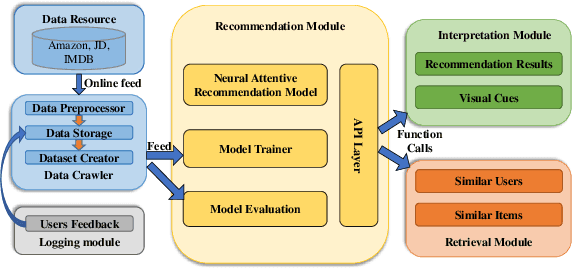
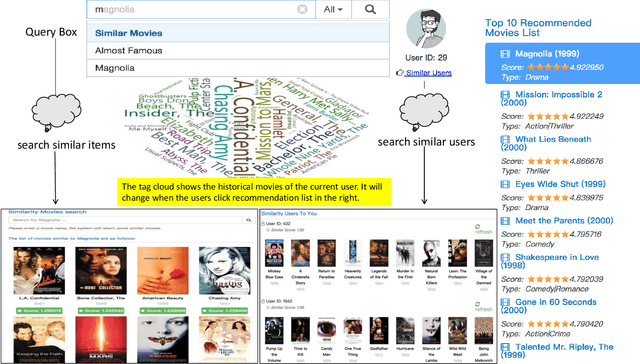
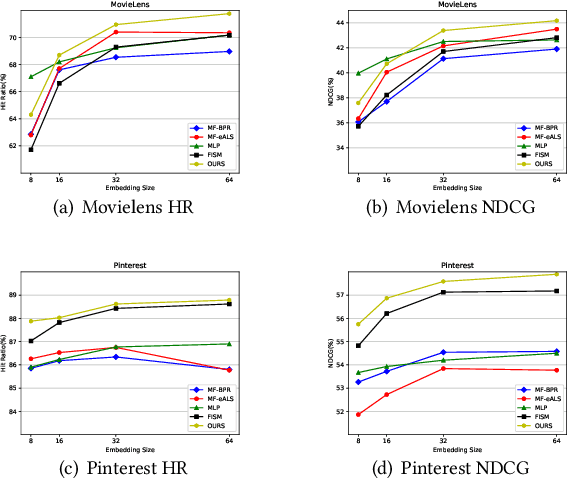
In this paper, we develop a neural attentive interpretable recommendation system, named NAIRS. A self-attention network, as a key component of the system, is designed to assign attention weights to interacted items of a user. This attention mechanism can distinguish the importance of the various interacted items in contributing to a user profile. Based on the user profiles obtained by the self-attention network, NAIRS offers personalized high-quality recommendation. Moreover, it develops visual cues to interpret recommendations. This demo application with the implementation of NAIRS enables users to interact with a recommendation system, and it persistently collects training data to improve the system. The demonstration and experimental results show the effectiveness of NAIRS.