 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding
Dec 07, 2023
Recent advances in text-to-image generation have made remarkable progress in synthesizing realistic human photos conditioned on given text prompts. However, existing personalized generation methods cannot simultaneously satisfy the requirements of high efficiency, promising identity (ID) fidelity, and flexible text controllability. In this work, we introduce PhotoMaker, an efficient personalized text-to-image generation method, which mainly encodes an arbitrary number of input ID images into a stack ID embedding for preserving ID information. Such an embedding, serving as a unified ID representation, can not only encapsulate the characteristics of the same input ID comprehensively, but also accommodate the characteristics of different IDs for subsequent integration. This paves the way for more intriguing and practically valuable applications. Besides, to drive the training of our PhotoMaker, we propose an ID-oriented data construction pipeline to assemble the training data. Under the nourishment of the dataset constructed through the proposed pipeline, our PhotoMaker demonstrates better ID preservation ability than test-time fine-tuning based methods, yet provides significant speed improvements, high-quality generation results, strong generalization capabilities, and a wide range of applications. Our project page is available at https://photo-maker.github.io/
Enhancing Polynomial Chaos Expansion Based Surrogate Modeling using a Novel Probabilistic Transfer Learning Strategy
Dec 07, 2023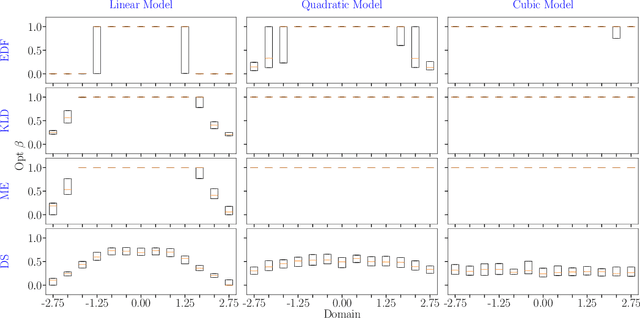
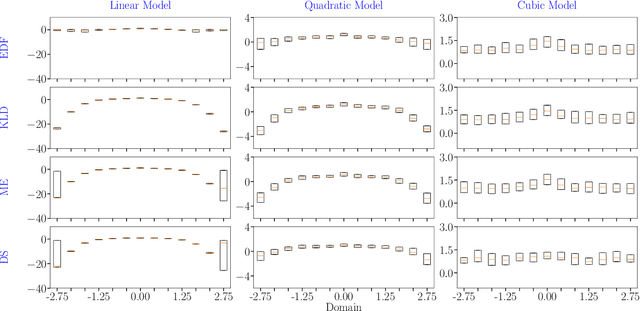
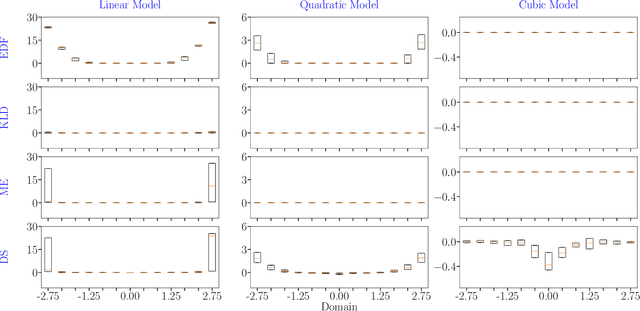
In the field of surrogate modeling, polynomial chaos expansion (PCE) allows practitioners to construct inexpensive yet accurate surrogates to be used in place of the expensive forward model simulations. For black-box simulations, non-intrusive PCE allows the construction of these surrogates using a set of simulation response evaluations. In this context, the PCE coefficients can be obtained using linear regression, which is also known as point collocation or stochastic response surfaces. Regression exhibits better scalability and can handle noisy function evaluations in contrast to other non-intrusive approaches, such as projection. However, since over-sampling is generally advisable for the linear regression approach, the simulation requirements become prohibitive for expensive forward models. We propose to leverage transfer learning whereby knowledge gained through similar PCE surrogate construction tasks (source domains) is transferred to a new surrogate-construction task (target domain) which has a limited number of forward model simulations (training data). The proposed transfer learning strategy determines how much, if any, information to transfer using new techniques inspired by Bayesian modeling and data assimilation. The strategy is scrutinized using numerical investigations and applied to an engineering problem from the oil and gas industry.
An Evolving Population Approach to Data-Stream Classification with Extreme Verification Latency
Dec 07, 2023Recognising and reacting to change in non-stationary data-streams is a challenging task. The majority of research in this area assumes that the true class label of incoming points are available, either at each time step or intermittently with some latency. In the worse case this latency approaches infinity and we can assume that no labels are available beyond the initial training set. When change is expected and no further training labels are provided the challenge of maintaining a high classification accuracy is very great. The challenge is to propagate the original training information through several timesteps, possibly indefinitely, while adapting to underlying change in the data-stream. In this paper we conduct an initial study into the effectiveness of using an evolving, population-based approach as the mechanism for adapting to change. An ensemble of one-class-classifiers is maintained for each class. Each classifier is considered as an agent in the sub-population and is subject to selection pressure to find interesting areas of the feature space. This selection pressure forces the ensemble to adapt to the underlying change in the data-stream.
Integrating Plug-and-Play Data Priors with Weighted Prediction Error for Speech Dereverberation
Dec 05, 2023Speech dereverberation aims to alleviate the detrimental effects of late-reverberant components. While the weighted prediction error (WPE) method has shown superior performance in dereverberation, there is still room for further improvement in terms of performance and robustness in complex and noisy environments. Recent research has highlighted the effectiveness of integrating physics-based and data-driven methods, enhancing the performance of various signal processing tasks while maintaining interpretability. Motivated by these advancements, this paper presents a novel dereverberation frame-work, which incorporates data-driven methods for capturing speech priors within the WPE framework. The plug-and-play strategy (PnP), specifically the regularization by denoising (RED) strategy, is utilized to incorporate speech prior information learnt from data during the optimization problem solving iterations. Experimental results validate the effectiveness of the proposed approach.
Generator Born from Classifier
Dec 05, 2023In this paper, we make a bold attempt toward an ambitious task: given a pre-trained classifier, we aim to reconstruct an image generator, without relying on any data samples. From a black-box perspective, this challenge seems intractable, since it inevitably involves identifying the inverse function for a classifier, which is, by nature, an information extraction process. As such, we resort to leveraging the knowledge encapsulated within the parameters of the neural network. Grounded on the theory of Maximum-Margin Bias of gradient descent, we propose a novel learning paradigm, in which the generator is trained to ensure that the convergence conditions of the network parameters are satisfied over the generated distribution of the samples. Empirical validation from various image generation tasks substantiates the efficacy of our strategy.
Subject-Based Domain Adaptation for Facial Expression Recognition
Dec 09, 2023Adapting a deep learning (DL) model to a specific target individual is a challenging task in facial expression recognition (FER) that may be achieved using unsupervised domain adaptation (UDA) methods. Although several UDA methods have been proposed to adapt deep FER models across source and target data sets, multiple subject-specific source domains are needed to accurately represent the intra- and inter-person variability in subject-based adaption. In this paper, we consider the setting where domains correspond to individuals, not entire datasets. Unlike UDA, multi-source domain adaptation (MSDA) methods can leverage multiple source datasets to improve the accuracy and robustness of the target model. However, previous methods for MSDA adapt image classification models across datasets and do not scale well to a larger number of source domains. In this paper, a new MSDA method is introduced for subject-based domain adaptation in FER. It efficiently leverages information from multiple source subjects (labeled source domain data) to adapt a deep FER model to a single target individual (unlabeled target domain data). During adaptation, our Subject-based MSDA first computes a between-source discrepancy loss to mitigate the domain shift among data from several source subjects. Then, a new strategy is employed to generate augmented confident pseudo-labels for the target subject, allowing a reduction in the domain shift between source and target subjects. Experiments\footnote{\textcolor{red}{\textbf{Supplementary material} contains our code, which will be made public, and additional experimental results.}} on the challenging BioVid heat and pain dataset (PartA) with 87 subjects shows that our Subject-based MSDA can outperform state-of-the-art methods yet scale well to multiple subject-based source domains.
Isomorphic-Consistent Variational Graph Auto-Encoders for Multi-Level Graph Representation Learning
Dec 09, 2023Graph representation learning is a fundamental research theme and can be generalized to benefit multiple downstream tasks from the node and link levels to the higher graph level. In practice, it is desirable to develop task-agnostic general graph representation learning methods that are typically trained in an unsupervised manner. Related research reveals that the power of graph representation learning methods depends on whether they can differentiate distinct graph structures as different embeddings and map isomorphic graphs to consistent embeddings (i.e., the isomorphic consistency of graph models). However, for task-agnostic general graph representation learning, existing unsupervised graph models, represented by the variational graph auto-encoders (VGAEs), can only keep the isomorphic consistency within the subgraphs of 1-hop neighborhoods and thus usually manifest inferior performance on the more difficult higher-level tasks. To overcome the limitations of existing unsupervised methods, in this paper, we propose the Isomorphic-Consistent VGAE (IsoC-VGAE) for multi-level task-agnostic graph representation learning. We first devise a decoding scheme to provide a theoretical guarantee of keeping the isomorphic consistency under the settings of unsupervised learning. We then propose the Inverse Graph Neural Network (Inv-GNN) decoder as its intuitive realization, which trains the model via reconstructing the GNN node embeddings with multi-hop neighborhood information, so as to maintain the high-order isomorphic consistency within the VGAE framework. We conduct extensive experiments on the representative graph learning tasks at different levels, including node classification, link prediction and graph classification, and the results verify that our proposed model generally outperforms both the state-of-the-art unsupervised methods and representative supervised methods.
Spatial Diarization for Meeting Transcription with Ad-Hoc Acoustic Sensor Networks
Nov 27, 2023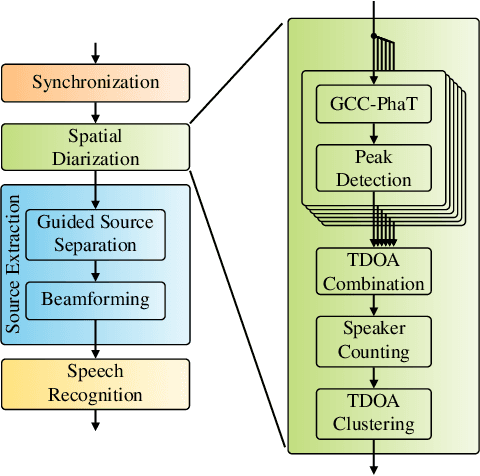
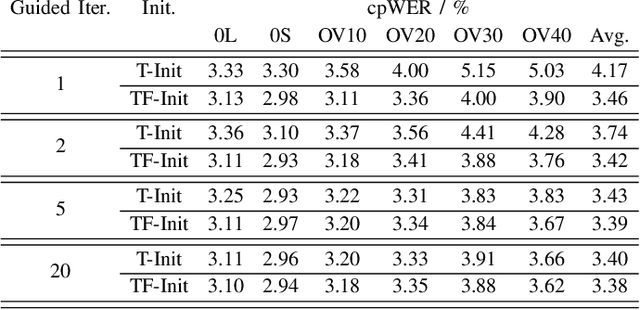
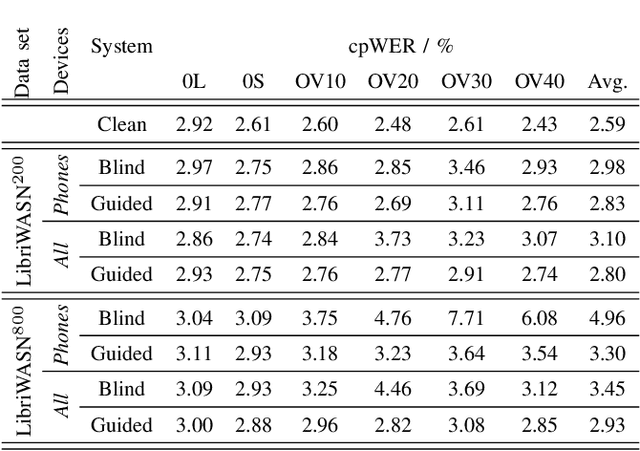
We propose a diarization system, that estimates "who spoke when" based on spatial information, to be used as a front-end of a meeting transcription system running on the signals gathered from an acoustic sensor network (ASN). Although the spatial distribution of the microphones is advantageous, exploiting the spatial diversity for diarization and signal enhancement is challenging, because the microphones' positions are typically unknown, and the recorded signals are initially unsynchronized in general. Here, we approach these issues by first blindly synchronizing the signals and then estimating time differences of arrival (TDOAs). The TDOA information is exploited to estimate the speakers' activity, even in the presence of multiple speakers being simultaneously active. This speaker activity information serves as a guide for a spatial mixture model, on which basis the individual speaker's signals are extracted via beamforming. Finally, the extracted signals are forwarded to a speech recognizer. Additionally, a novel initialization scheme for spatial mixture models based on the TDOA estimates is proposed. Experiments conducted on real recordings from the LibriWASN data set have shown that our proposed system is advantageous compared to a system using a spatial mixture model, which does not make use of external diarization information.
Automatic Detection of Alzheimer's Disease with Multi-Modal Fusion of Clinical MRI Scans
Nov 30, 2023The aging population of the U.S. drives the prevalence of Alzheimer's disease. Brookmeyer et al. forecasts approximately 15 million Americans will have either clinical AD or mild cognitive impairment by 2060. In response to this urgent call, methods for early detection of Alzheimer's disease have been developed for prevention and pre-treatment. Notably, literature on the application of deep learning in the automatic detection of the disease has been proliferating. This study builds upon previous literature and maintains a focus on leveraging multi-modal information to enhance automatic detection. We aim to predict the stage of the disease - Cognitively Normal (CN), Mildly Cognitive Impairment (MCI), and Alzheimer's Disease (AD), based on two different types of brain MRI scans. We design an AlexNet-based deep learning model that learns the synergy of complementary information from both T1 and FLAIR MRI scans.
Joint Detection Algorithm for Multiple Cognitive Users in Spectrum Sensing
Dec 01, 2023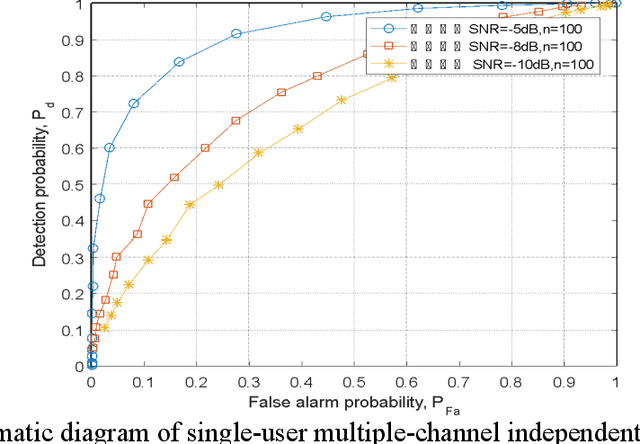
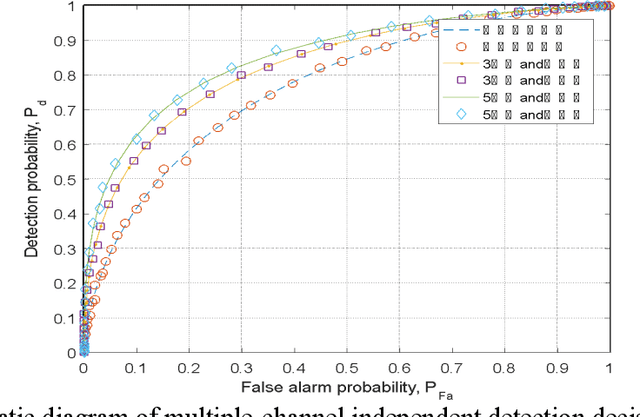
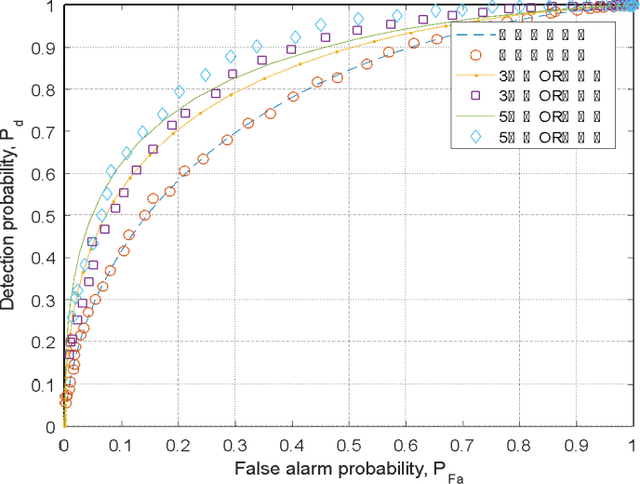
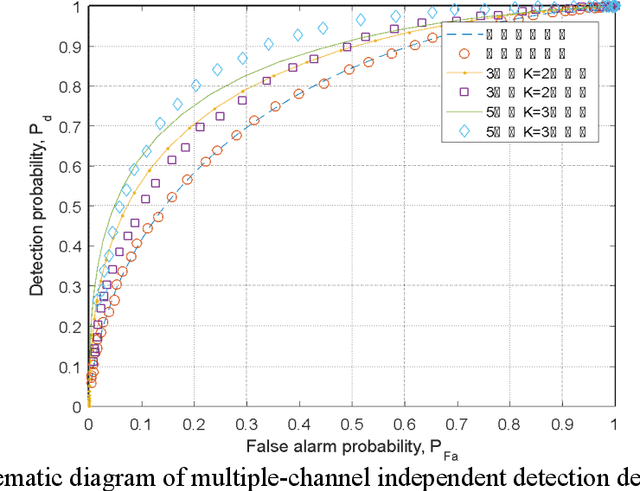
Spectrum sensing technology is a crucial aspect of modern communication technology, serving as one of the essential techniques for efficiently utilizing scarce information resources in tight frequency bands. This paper first introduces three common logical circuit decision criteria in hard decisions and analyzes their decision rigor. Building upon hard decisions, the paper further introduces a method for multi-user spectrum sensing based on soft decisions. Then the paper simulates the false alarm probability and detection probability curves corresponding to the three criteria. The simulated results of multi-user collaborative sensing indicate that the simulation process significantly reduces false alarm probability and enhances detection probability. This approach effectively detects spectrum resources unoccupied during idle periods, leveraging the concept of time-division multiplexing and rationalizing the redistribution of information resources. The entire computation process relies on the calculation principles of power spectral density in communication theory, involving threshold decision detection for noise power and the sum of noise and signal power. It provides a secondary decision detection, reflecting the perceptual decision performance of logical detection methods with relative accuracy.
* https://aei.ewapublishing.org/article.html?pk=e24c40d220434209ae2fe2e984bcf2c2