 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Radar Perception in Autonomous Driving: Exploring Different Data Representations
Dec 08, 2023
With the rapid advancements of sensor technology and deep learning, autonomous driving systems are providing safe and efficient access to intelligent vehicles as well as intelligent transportation. Among these equipped sensors, the radar sensor plays a crucial role in providing robust perception information in diverse environmental conditions. This review focuses on exploring different radar data representations utilized in autonomous driving systems. Firstly, we introduce the capabilities and limitations of the radar sensor by examining the working principles of radar perception and signal processing of radar measurements. Then, we delve into the generation process of five radar representations, including the ADC signal, radar tensor, point cloud, grid map, and micro-Doppler signature. For each radar representation, we examine the related datasets, methods, advantages and limitations. Furthermore, we discuss the challenges faced in these data representations and propose potential research directions. Above all, this comprehensive review offers an in-depth insight into how these representations enhance autonomous system capabilities, providing guidance for radar perception researchers. To facilitate retrieval and comparison of different data representations, datasets and methods, we provide an interactive website at https://radar-camera-fusion.github.io/radar.
Learning Generalizable Perceptual Representations for Data-Efficient No-Reference Image Quality Assessment
Dec 08, 2023No-reference (NR) image quality assessment (IQA) is an important tool in enhancing the user experience in diverse visual applications. A major drawback of state-of-the-art NR-IQA techniques is their reliance on a large number of human annotations to train models for a target IQA application. To mitigate this requirement, there is a need for unsupervised learning of generalizable quality representations that capture diverse distortions. We enable the learning of low-level quality features agnostic to distortion types by introducing a novel quality-aware contrastive loss. Further, we leverage the generalizability of vision-language models by fine-tuning one such model to extract high-level image quality information through relevant text prompts. The two sets of features are combined to effectively predict quality by training a simple regressor with very few samples on a target dataset. Additionally, we design zero-shot quality predictions from both pathways in a completely blind setting. Our experiments on diverse datasets encompassing various distortions show the generalizability of the features and their superior performance in the data-efficient and zero-shot settings. Code will be made available at https://github.com/suhas-srinath/GRepQ.
HALO: An Ontology for Representing Hallucinations in Generative Models
Dec 08, 2023Recent progress in generative AI, including large language models (LLMs) like ChatGPT, has opened up significant opportunities in fields ranging from natural language processing to knowledge discovery and data mining. However, there is also a growing awareness that the models can be prone to problems such as making information up or `hallucinations', and faulty reasoning on seemingly simple problems. Because of the popularity of models like ChatGPT, both academic scholars and citizen scientists have documented hallucinations of several different types and severity. Despite this body of work, a formal model for describing and representing these hallucinations (with relevant meta-data) at a fine-grained level, is still lacking. In this paper, we address this gap by presenting the Hallucination Ontology or HALO, a formal, extensible ontology written in OWL that currently offers support for six different types of hallucinations known to arise in LLMs, along with support for provenance and experimental metadata. We also collect and publish a dataset containing hallucinations that we inductively gathered across multiple independent Web sources, and show that HALO can be successfully used to model this dataset and answer competency questions.
Markov Chain Monte Carlo Data Association for Sets of Trajectories
Dec 06, 2023This paper considers a batch solution to the multi-object tracking problem based on sets of trajectories. Specifically, we present two offline implementations of the trajectory Poisson multi-Bernoulli mixture (TPMBM) filter for batch data based on Markov chain Monte Carlo (MCMC) sampling of the data association hypotheses. In contrast to online TPMBM implementations, the proposed offline implementations solve a large-scale, multi-scan data association problem across the entire time interval of interest, and therefore they can fully exploit all the measurement information available. Furthermore, by leveraging the efficient hypothesis structure of TPMBM filters, the proposed implementations compare favorably with other MCMC-based multi-object tracking algorithms. Simulation results show that the TPMBM implementation using the Metropolis-Hastings algorithm presents state-of-the-art multiple trajectory estimation performance.
TokenCompose: Grounding Diffusion with Token-level Supervision
Dec 06, 2023We present TokenCompose, a Latent Diffusion Model for text-to-image generation that achieves enhanced consistency between user-specified text prompts and model-generated images. Despite its tremendous success, the standard denoising process in the Latent Diffusion Model takes text prompts as conditions only, absent explicit constraint for the consistency between the text prompts and the image contents, leading to unsatisfactory results for composing multiple object categories. TokenCompose aims to improve multi-category instance composition by introducing the token-wise consistency terms between the image content and object segmentation maps in the finetuning stage. TokenCompose can be applied directly to the existing training pipeline of text-conditioned diffusion models without extra human labeling information. By finetuning Stable Diffusion, the model exhibits significant improvements in multi-category instance composition and enhanced photorealism for its generated images.
$Q_{bias}$ -- A Dataset on Media Bias in Search Queries and Query Suggestions
Nov 29, 2023This publication describes the motivation and generation of $Q_{bias}$, a large dataset of Google and Bing search queries, a scraping tool and dataset for biased news articles, as well as language models for the investigation of bias in online search. Web search engines are a major factor and trusted source in information search, especially in the political domain. However, biased information can influence opinion formation and lead to biased opinions. To interact with search engines, users formulate search queries and interact with search query suggestions provided by the search engines. A lack of datasets on search queries inhibits research on the subject. We use $Q_{bias}$ to evaluate different approaches to fine-tuning transformer-based language models with the goal of producing models capable of biasing text with left and right political stance. Additionally to this work we provided datasets and language models for biasing texts that allow further research on bias in online information search.
CoSeR: Bridging Image and Language for Cognitive Super-Resolution
Nov 29, 2023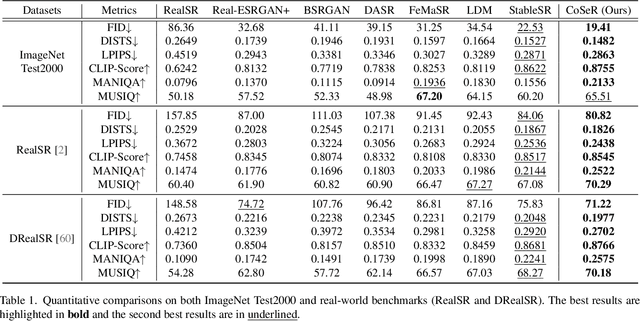
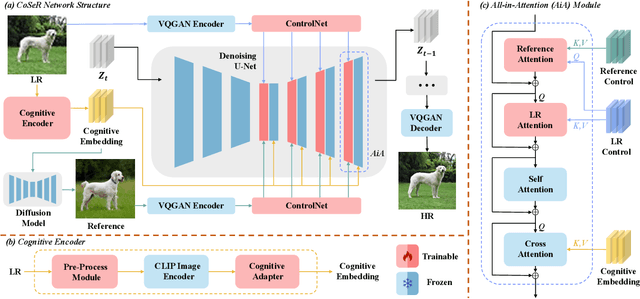
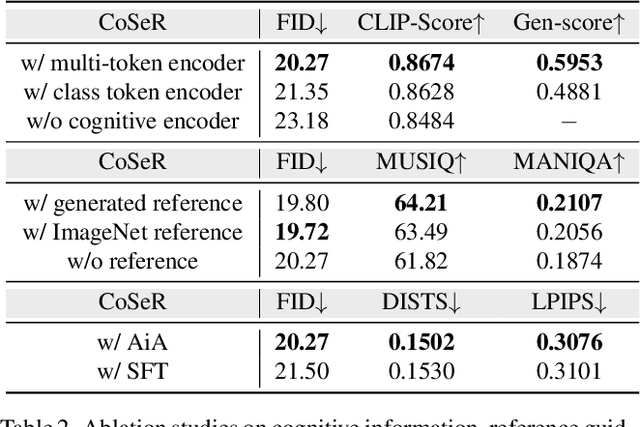
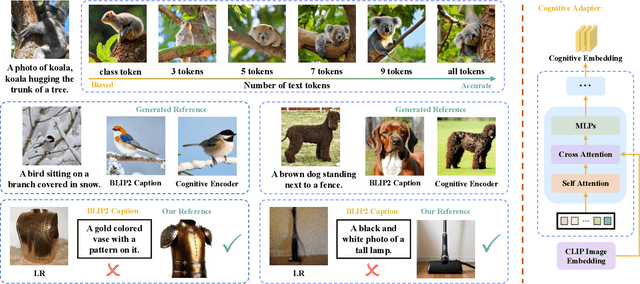
Existing super-resolution (SR) models primarily focus on restoring local texture details, often neglecting the global semantic information within the scene. This oversight can lead to the omission of crucial semantic details or the introduction of inaccurate textures during the recovery process. In our work, we introduce the Cognitive Super-Resolution (CoSeR) framework, empowering SR models with the capacity to comprehend low-resolution images. We achieve this by marrying image appearance and language understanding to generate a cognitive embedding, which not only activates prior information from large text-to-image diffusion models but also facilitates the generation of high-quality reference images to optimize the SR process. To further improve image fidelity, we propose a novel condition injection scheme called "All-in-Attention", consolidating all conditional information into a single module. Consequently, our method successfully restores semantically correct and photorealistic details, demonstrating state-of-the-art performance across multiple benchmarks. Code: https://github.com/VINHYU/CoSeR
From Simulations to Reality: Enhancing Multi-Robot Exploration for Urban Search and Rescue
Nov 28, 2023In this study, we present a novel hybrid algorithm, combining Levy Flight (LF) and Particle Swarm Optimization (PSO) (LF-PSO), tailored for efficient multi-robot exploration in unknown environments with limited communication and no global positioning information. The research addresses the growing interest in employing multiple autonomous robots for exploration tasks, particularly in scenarios such as Urban Search and Rescue (USAR) operations. Multiple robots offer advantages like increased task coverage, robustness, flexibility, and scalability. However, existing approaches often make assumptions such as search area, robot positioning, communication restrictions, and target information that may not hold in real-world situations. The hybrid algorithm leverages LF, known for its effectiveness in large space exploration with sparse targets, and incorporates inter-robot repulsion as a social component through PSO. This combination enhances area exploration efficiency. We redefine the local best and global best positions to suit scenarios without continuous target information. Experimental simulations in a controlled environment demonstrate the algorithm's effectiveness, showcasing improved area coverage compared to traditional methods. In the process of refining our approach and testing it in complex, obstacle-rich environments, the presented work holds promise for enhancing multi-robot exploration in scenarios with limited information and communication capabilities.
Search-Adaptor: Text Embedding Customization for Information Retrieval
Oct 12, 2023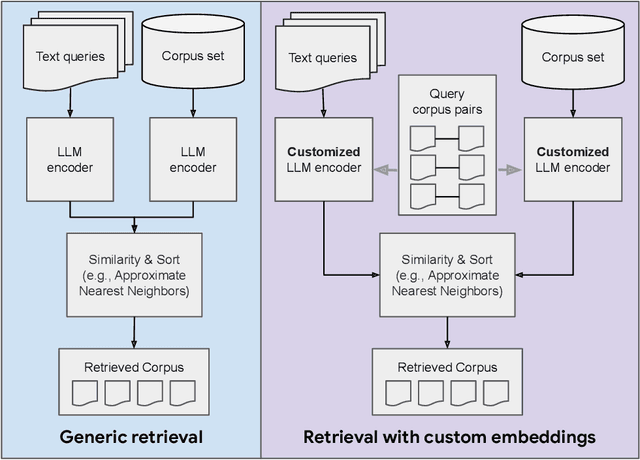
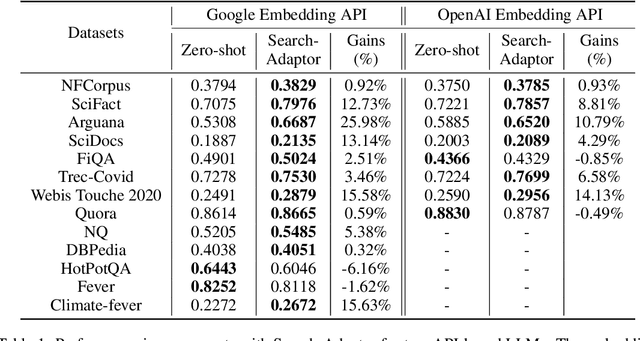
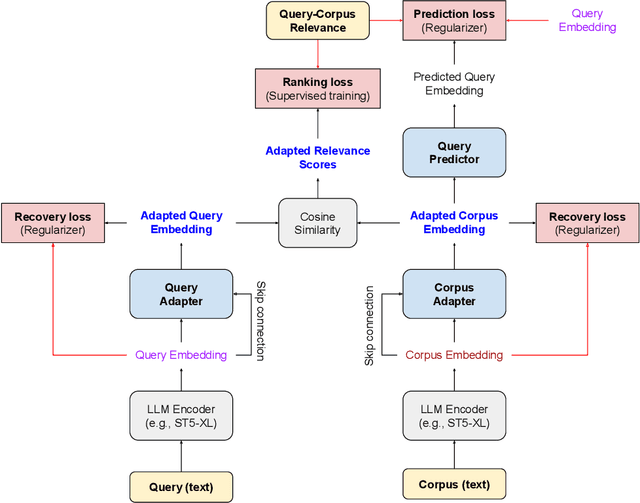
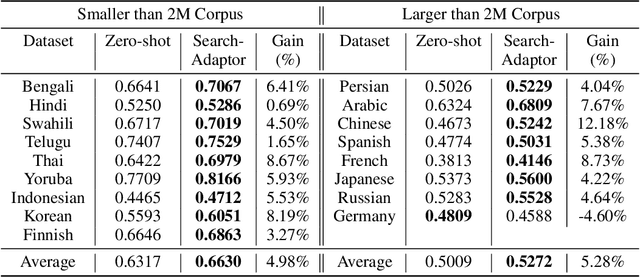
Text embeddings extracted by pre-trained Large Language Models (LLMs) have significant potential to improve information retrieval and search. Beyond the zero-shot setup in which they are being conventionally used, being able to take advantage of the information from the relevant query-corpus paired data has the power to further boost the LLM capabilities. In this paper, we propose a novel method, Search-Adaptor, for customizing LLMs for information retrieval in an efficient and robust way. Search-Adaptor modifies the original text embedding generated by pre-trained LLMs, and can be integrated with any LLM, including those only available via APIs. On multiple real-world English and multilingual retrieval datasets, we show consistent and significant performance benefits for Search-Adaptor -- e.g., more than 5.2% improvements over the Google Embedding APIs in nDCG@10 averaged over 13 BEIR datasets.
Hyper-Relational Knowledge Graph Neural Network for Next POI
Nov 28, 2023With the advancement of mobile technology, Point of Interest (POI) recommendation systems in Location-based Social Networks (LBSN) have brought numerous benefits to both users and companies. Many existing works employ Knowledge Graph (KG) to alleviate the data sparsity issue in LBSN. These approaches primarily focus on modeling the pair-wise relations in LBSN to enrich the semantics and thereby relieve the data sparsity issue. However, existing approaches seldom consider the hyper-relations in LBSN, such as the mobility relation (a 3-ary relation: user-POI-time). This makes the model hard to exploit the semantics accurately. In addition, prior works overlook the rich structural information inherent in KG, which consists of higher-order relations and can further alleviate the impact of data sparsity.To this end, we propose a Hyper-Relational Knowledge Graph Neural Network (HKGNN) model. In HKGNN, a Hyper-Relational Knowledge Graph (HKG) that models the LBSN data is constructed to maintain and exploit the rich semantics of hyper-relations. Then we proposed a Hypergraph Neural Network to utilize the structural information of HKG in a cohesive way. In addition, a self-attention network is used to leverage sequential information and make personalized recommendations. Furthermore, side information, essential in reducing data sparsity by providing background knowledge of POIs, is not fully utilized in current methods. In light of this, we extended the current dataset with available side information to further lessen the impact of data sparsity. Results of experiments on four real-world LBSN datasets demonstrate the effectiveness of our approach compared to existing state-of-the-art methods.