 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Weakly Supervised Temporal Action Localization Through Learning Explicit Subspaces for Action and Context
Mar 30, 2021
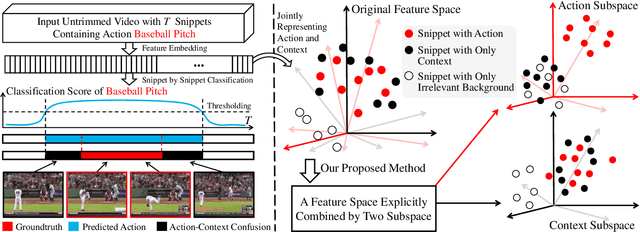

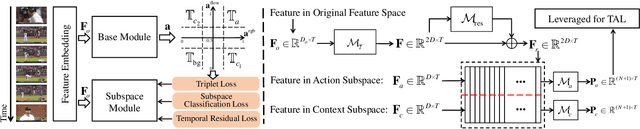
Weakly-supervised Temporal Action Localization (WS-TAL) methods learn to localize temporal starts and ends of action instances in a video under only video-level supervision. Existing WS-TAL methods rely on deep features learned for action recognition. However, due to the mismatch between classification and localization, these features cannot distinguish the frequently co-occurring contextual background, i.e., the context, and the actual action instances. We term this challenge action-context confusion, and it will adversely affect the action localization accuracy. To address this challenge, we introduce a framework that learns two feature subspaces respectively for actions and their context. By explicitly accounting for action visual elements, the action instances can be localized more precisely without the distraction from the context. To facilitate the learning of these two feature subspaces with only video-level categorical labels, we leverage the predictions from both spatial and temporal streams for snippets grouping. In addition, an unsupervised learning task is introduced to make the proposed module focus on mining temporal information. The proposed approach outperforms state-of-the-art WS-TAL methods on three benchmarks, i.e., THUMOS14, ActivityNet v1.2 and v1.3 datasets.
Temporal Action Detection with Multi-level Supervision
Nov 24, 2020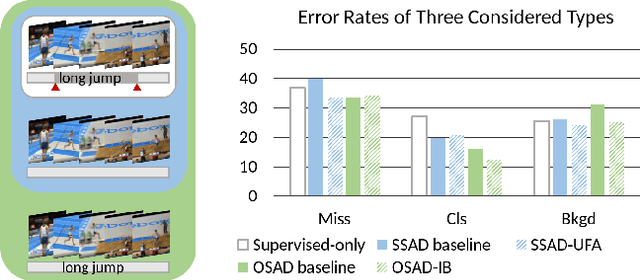
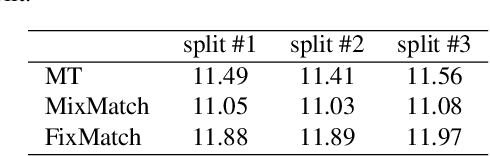
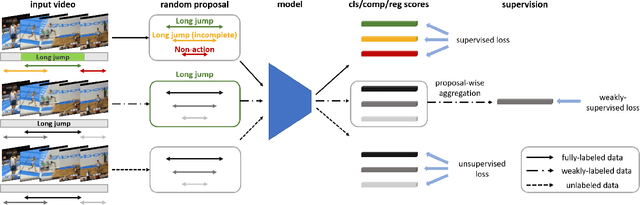
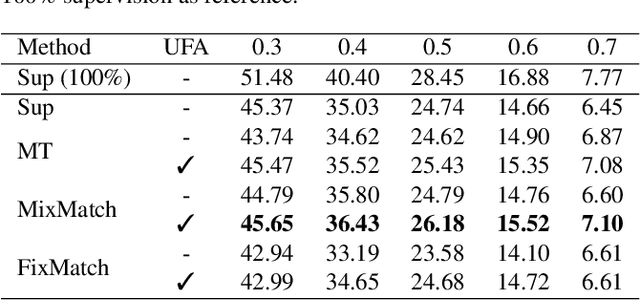
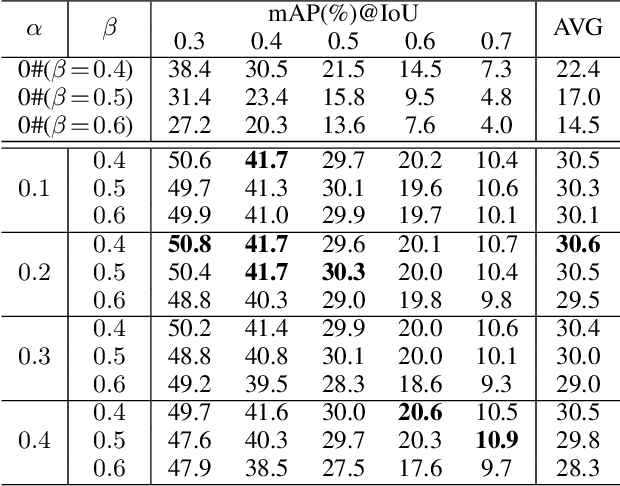
Training temporal action detection in videos requires large amounts of labeled data, yet such annotation is expensive to collect. Incorporating unlabeled or weakly-labeled data to train action detection model could help reduce annotation cost. In this work, we first introduce the Semi-supervised Action Detection (SSAD) task with a mixture of labeled and unlabeled data and analyze different types of errors in the proposed SSAD baselines which are directly adapted from the semi-supervised classification task. To alleviate the main error of action incompleteness (i.e., missing parts of actions) in SSAD baselines, we further design an unsupervised foreground attention (UFA) module utilizing the "independence" between foreground and background motion. Then we incorporate weakly-labeled data into SSAD and propose Omni-supervised Action Detection (OSAD) with three levels of supervision. An information bottleneck (IB) suppressing the scene information in non-action frames while preserving the action information is designed to help overcome the accompanying action-context confusion problem in OSAD baselines. We extensively benchmark against the baselines for SSAD and OSAD on our created data splits in THUMOS14 and ActivityNet1.2, and demonstrate the effectiveness of the proposed UFA and IB methods. Lastly, the benefit of our full OSAD-IB model under limited annotation budgets is shown by exploring the optimal annotation strategy for labeled, unlabeled and weakly-labeled data.
Encoding Syntactic Knowledge in Transformer Encoder for Intent Detection and Slot Filling
Dec 21, 2020
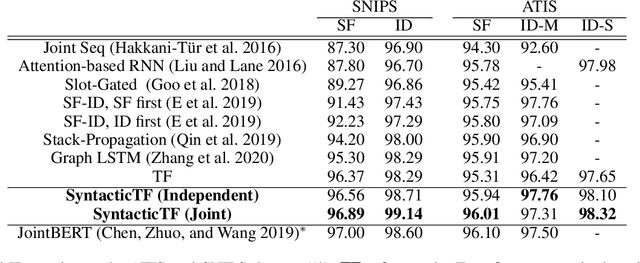
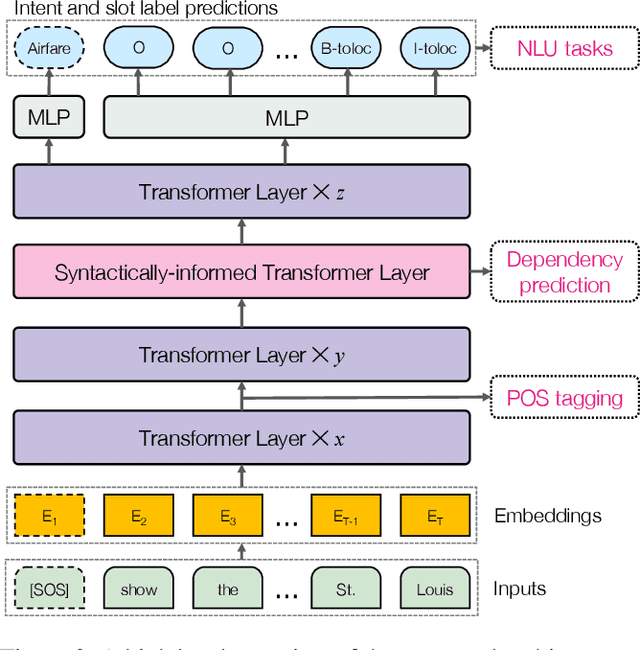

We propose a novel Transformer encoder-based architecture with syntactical knowledge encoded for intent detection and slot filling. Specifically, we encode syntactic knowledge into the Transformer encoder by jointly training it to predict syntactic parse ancestors and part-of-speech of each token via multi-task learning. Our model is based on self-attention and feed-forward layers and does not require external syntactic information to be available at inference time. Experiments show that on two benchmark datasets, our models with only two Transformer encoder layers achieve state-of-the-art results. Compared to the previously best performed model without pre-training, our models achieve absolute F1 score and accuracy improvement of 1.59% and 0.85% for slot filling and intent detection on the SNIPS dataset, respectively. Our models also achieve absolute F1 score and accuracy improvement of 0.1% and 0.34% for slot filling and intent detection on the ATIS dataset, respectively, over the previously best performed model. Furthermore, the visualization of the self-attention weights illustrates the benefits of incorporating syntactic information during training.
Event-based Synthetic Aperture Imaging with a Hybrid Network
Mar 30, 2021
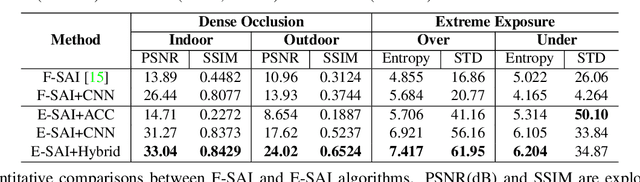


Synthetic aperture imaging (SAI) is able to achieve the see through effect by blurring out the off-focus foreground occlusions and reconstructing the in-focus occluded targets from multi-view images. However, very dense occlusions and extreme lighting conditions may bring significant disturbances to the SAI based on conventional frame-based cameras, leading to performance degeneration. To address these problems, we propose a novel SAI system based on the event camera which can produce asynchronous events with extremely low latency and high dynamic range. Thus, it can eliminate the interference of dense occlusions by measuring with almost continuous views, and simultaneously tackle the over/under exposure problems. To reconstruct the occluded targets, we propose a hybrid encoder-decoder network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs). In the hybrid network, the spatio-temporal information of the collected events is first encoded by SNN layers, and then transformed to the visual image of the occluded targets by a style-transfer CNN decoder. Through experiments, the proposed method shows remarkable performance in dealing with very dense occlusions and extreme lighting conditions, and high quality visual images can be reconstructed using pure event data.
Fine-tuning Handwriting Recognition systems with Temporal Dropout
Jan 31, 2021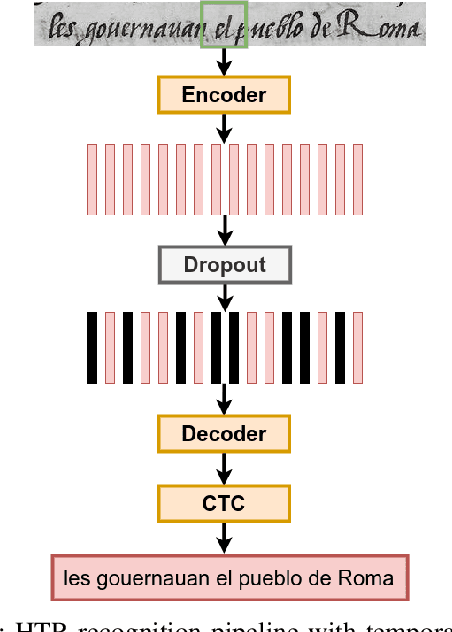
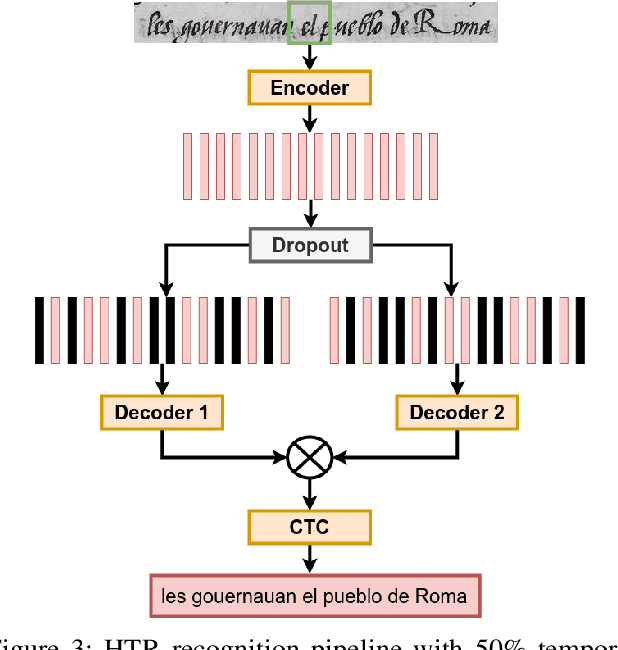
This paper introduces a novel method to fine-tune handwriting recognition systems based on Recurrent Neural Networks (RNN). Long Short-Term Memory (LSTM) networks are good at modeling long sequences but they tend to overfit over time. To improve the system's ability to model sequences, we propose to drop information at random positions in the sequence. We call our approach Temporal Dropout (TD). We apply TD at the image level as well to internal network representation. We show that TD improves the results on two different datasets. Our method outperforms previous state-of-the-art on Rodrigo dataset.
Spatio-Temporal Pruning and Quantization for Low-latency Spiking Neural Networks
Apr 26, 2021
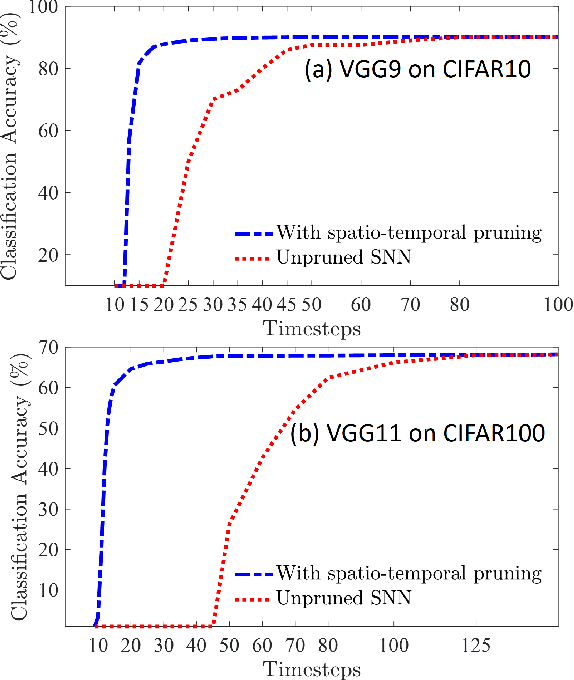
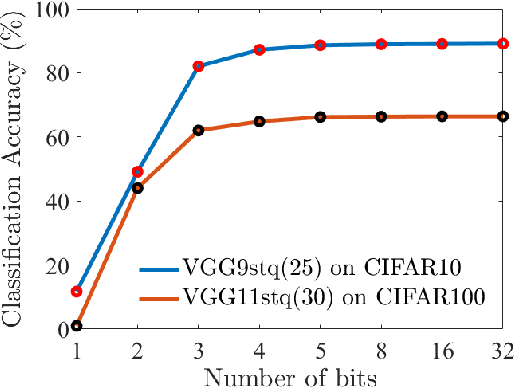
Spiking Neural Networks (SNNs) are a promising alternative to traditional deep learning methods since they perform event-driven information processing. However, a major drawback of SNNs is high inference latency. The efficiency of SNNs could be enhanced using compression methods such as pruning and quantization. Notably, SNNs, unlike their non-spiking counterparts, consist of a temporal dimension, the compression of which can lead to latency reduction. In this paper, we propose spatial and temporal pruning of SNNs. First, structured spatial pruning is performed by determining the layer-wise significant dimensions using principal component analysis of the average accumulated membrane potential of the neurons. This step leads to 10-14X model compression. Additionally, it enables inference with lower latency and decreases the spike count per inference. To further reduce latency, temporal pruning is performed by gradually reducing the timesteps while training. The networks are trained using surrogate gradient descent based backpropagation and we validate the results on CIFAR10 and CIFAR100, using VGG architectures. The spatiotemporally pruned SNNs achieve 89.04% and 66.4% accuracy on CIFAR10 and CIFAR100, respectively, while performing inference with 3-30X reduced latency compared to state-of-the-art SNNs. Moreover, they require 8-14X lesser compute energy compared to their unpruned standard deep learning counterparts. The energy numbers are obtained by multiplying the number of operations with energy per operation. These SNNs also provide 1-4% higher robustness against Gaussian noise corrupted inputs. Furthermore, we perform weight quantization and find that performance remains reasonably stable up to 5-bit quantization.
Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments
Mar 30, 2021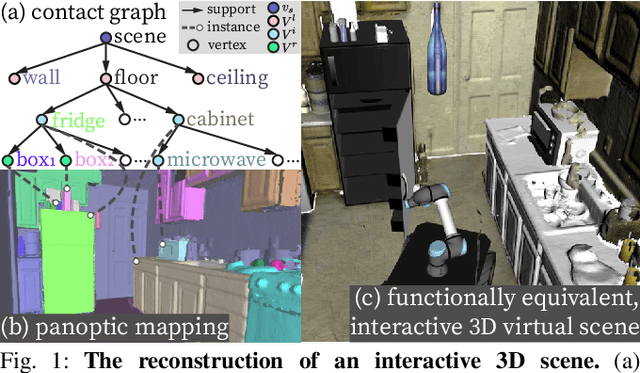
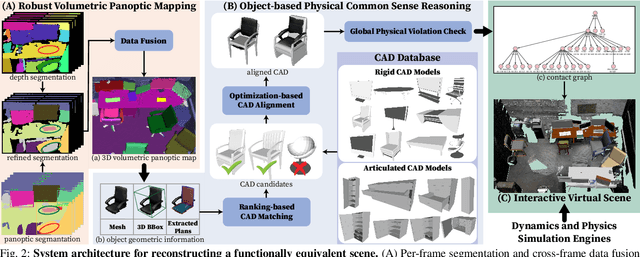
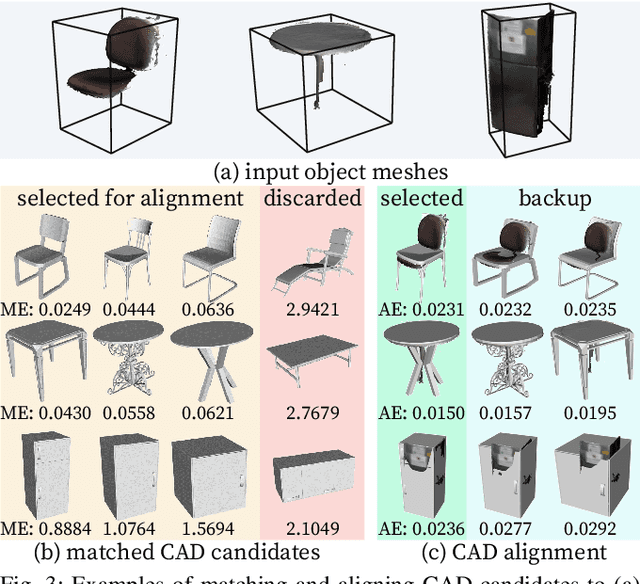
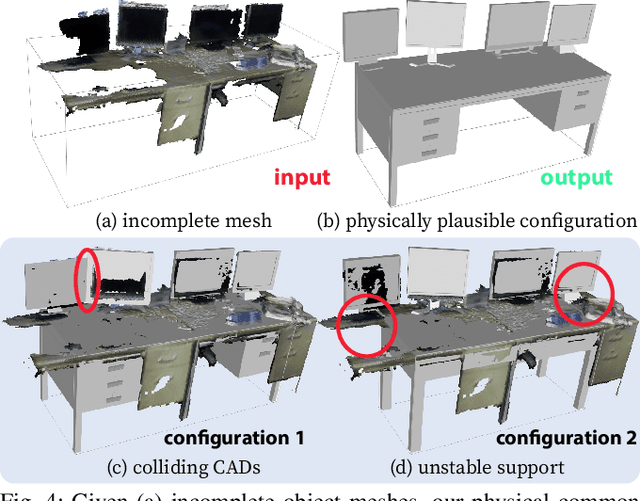
In this paper, we rethink the problem of scene reconstruction from an embodied agent's perspective: While the classic view focuses on the reconstruction accuracy, our new perspective emphasizes the underlying functions and constraints such that the reconstructed scenes provide \em{actionable} information for simulating \em{interactions} with agents. Here, we address this challenging problem by reconstructing an interactive scene using RGB-D data stream, which captures (i) the semantics and geometry of objects and layouts by a 3D volumetric panoptic mapping module, and (ii) object affordance and contextual relations by reasoning over physical common sense among objects, organized by a graph-based scene representation. Crucially, this reconstructed scene replaces the object meshes in the dense panoptic map with part-based articulated CAD models for finer-grained robot interactions. In the experiments, we demonstrate that (i) our panoptic mapping module outperforms previous state-of-the-art methods, (ii) a high-performant physical reasoning procedure that matches, aligns, and replaces objects' meshes with best-fitted CAD models, and (iii) reconstructed scenes are physically plausible and naturally afford actionable interactions; without any manual labeling, they are seamlessly imported to ROS-based simulators and virtual environments for complex robot task executions.
Localization of Autonomous Vehicles: Proof of Concept for A Computer Vision Approach
Apr 06, 2021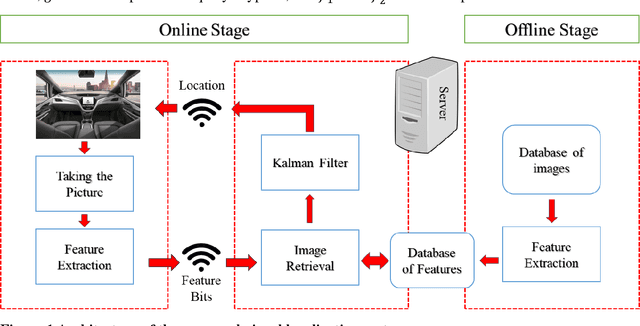


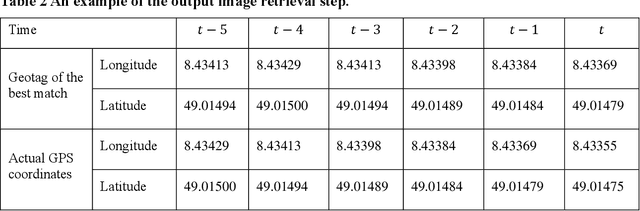
This paper introduces a visual-based localization method for autonomous vehicles (AVs) that operate in the absence of any complicated hardware system but a single camera. Visual localization refers to techniques that aim to find the location of an object based on visual information of its surrounding area. The problem of localization has been of interest for many years. However, visual localization is a relatively new subject in the literature of transportation. Moreover, the inevitable application of this type of localization in the context of autonomous vehicles demands special attention from the transportation community to this problem. This study proposes a two-step localization method that requires a database of geotagged images and a camera mounted on a vehicle that can take pictures while the car is moving. The first step which is image retrieval uses SIFT local feature descriptor to find an initial location for the vehicle using image matching. The next step is to utilize the Kalman filter to estimate a more accurate location for the vehicle as it is moving. All stages of the introduced method are implemented as a complete system using different Python libraries. The proposed system is tested on the KITTI dataset and has shown an average accuracy of 2 meters in finding the final location of the vehicle.
Self-Feature Regularization: Self-Feature Distillation Without Teacher Models
Mar 12, 2021
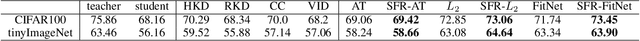
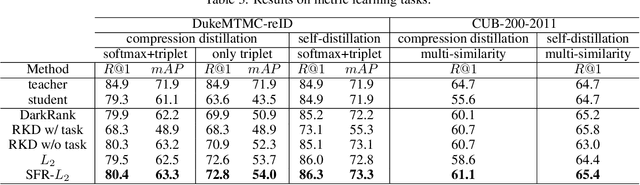
Knowledge distillation is the process of transferring the knowledge from a large model to a small model. In this process, the small model learns the generalization ability of the large model and retains the performance close to that of the large model. Knowledge distillation provides a training means to migrate the knowledge of models, facilitating model deployment and speeding up inference. However, previous distillation methods require pre-trained teacher models, which still bring computational and storage overheads. In this paper, a novel general training framework called Self-Feature Regularization~(SFR) is proposed, which uses features in the deep layers to supervise feature learning in the shallow layers, retains more semantic information. Specifically, we firstly use EMD-l2 loss to match local features and a many-to-one approach to distill features more intensively in the channel dimension. Then dynamic label smoothing is used in the output layer to achieve better performance. Experiments further show the effectiveness of our proposed framework.
Second-Order Component Analysis for Fault Detection
Mar 12, 2021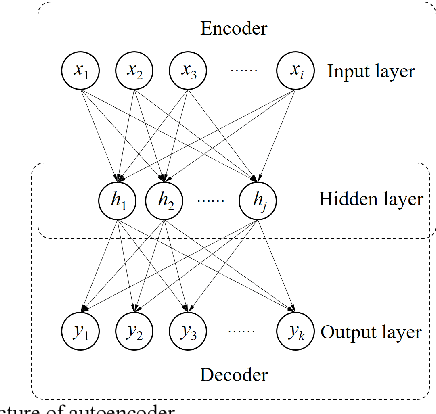
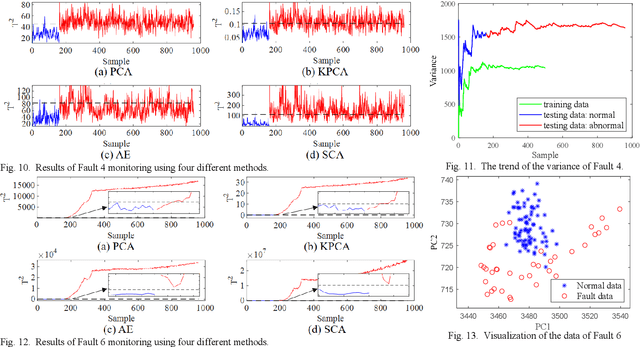
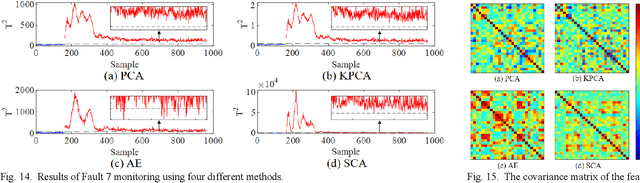
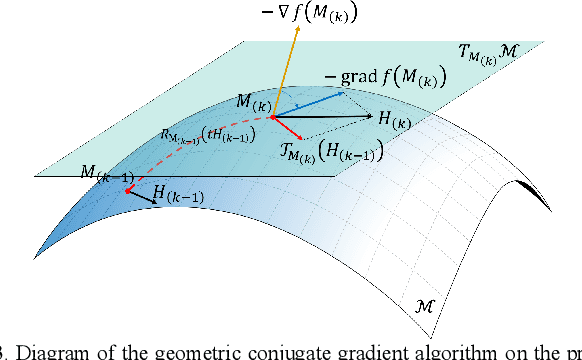
Process monitoring based on neural networks is getting more and more attention. Compared with classical neural networks, high-order neural networks have natural advantages in dealing with heteroscedastic data. However, high-order neural networks might bring the risk of overfitting and learning both the key information from original data and noises or anomalies. Orthogonal constraints can greatly reduce correlations between extracted features, thereby reducing the overfitting risk. This paper proposes a novel fault detection method called second-order component analysis (SCA). SCA rules out the heteroscedasticity of pro-cess data by optimizing a second-order autoencoder with orthogonal constraints. In order to deal with this constrained optimization problem, a geometric conjugate gradient algorithm is adopted in this paper, which performs geometric optimization on the combination of Stiefel manifold and Euclidean manifold. Extensive experiments on the Tennessee-Eastman benchmark pro-cess show that SCA outperforms PCA, KPCA, and autoencoder in missed detection rate (MDR) and false alarm rate (FAR).