 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Weakly-supervised Salient Instance Detection
Sep 29, 2020
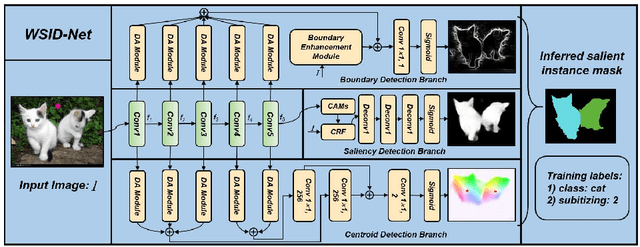
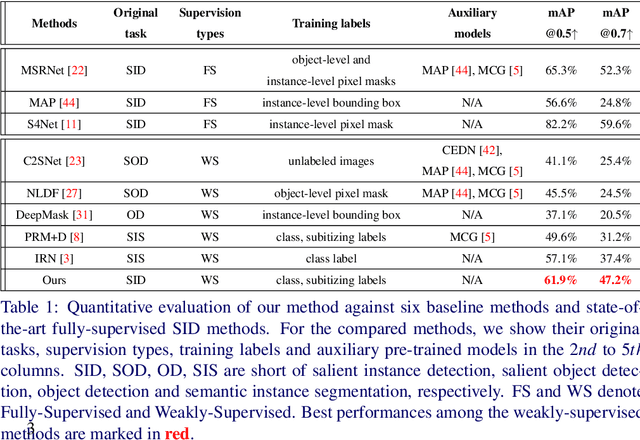

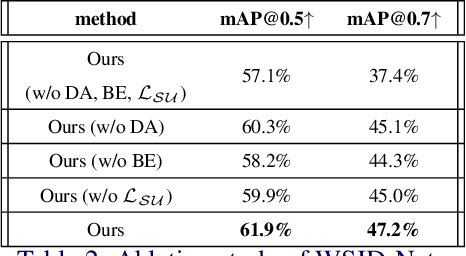
Existing salient instance detection (SID) methods typically learn from pixel-level annotated datasets. In this paper, we present the first weakly-supervised approach to the SID problem. Although weak supervision has been considered in general saliency detection, it is mainly based on using class labels for object localization. However, it is non-trivial to use only class labels to learn instance-aware saliency information, as salient instances with high semantic affinities may not be easily separated by the labels. We note that subitizing information provides an instant judgement on the number of salient items, which naturally relates to detecting salient instances and may help separate instances of the same class while grouping different parts of the same instance. Inspired by this insight, we propose to use class and subitizing labels as weak supervision for the SID problem. We propose a novel weakly-supervised network with three branches: a Saliency Detection Branch leveraging class consistency information to locate candidate objects; a Boundary Detection Branch exploiting class discrepancy information to delineate object boundaries; and a Centroid Detection Branch using subitizing information to detect salient instance centroids. This complementary information is further fused to produce salient instance maps. We conduct extensive experiments to demonstrate that the proposed method plays favorably against carefully designed baseline methods adapted from related tasks.
Anti-UAV: A Large Multi-Modal Benchmark for UAV Tracking
Jan 21, 2021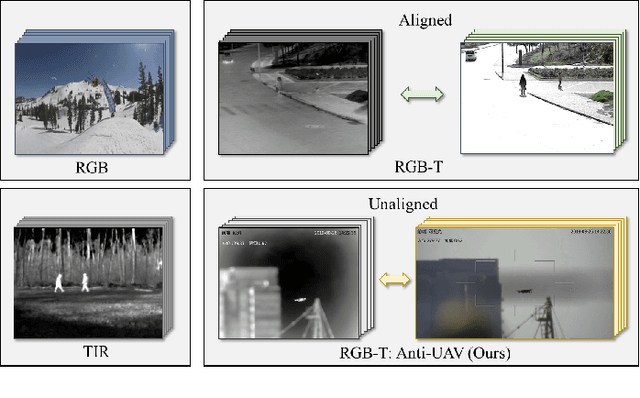

Unmanned Aerial Vehicle (UAV) offers lots of applications in both commerce and recreation. With this, monitoring the operation status of UAVs is crucially important. In this work, we consider the task of tracking UAVs, providing rich information such as location and trajectory. To facilitate research in this topic, we propose a dataset, Anti-UAV, with more than 300 video pairs containing over 580k manually annotated bounding boxes. The releasing of such a large-scale dataset could be a useful initial step in research of tracking UAVs. Furthermore, the advancement of addressing research challenges in Anti-UAV can help the design of anti-UAV systems, leading to better surveillance of UAVs. Besides, a novel approach named dual-flow semantic consistency (DFSC) is proposed for UAV tracking. Modulated by the semantic flow across video sequences, the tracker learns more robust class-level semantic information and obtains more discriminative instance-level features. Experimental results demonstrate that Anti-UAV is very challenging, and the proposed method can effectively improve the tracker's performance. The Anti-UAV benchmark and the code of the proposed approach will be publicly available at https://github.com/ucas-vg/Anti-UAV.
Potential Idiomatic Expression (PIE)-English: Corpus for Classes of Idioms
Apr 25, 2021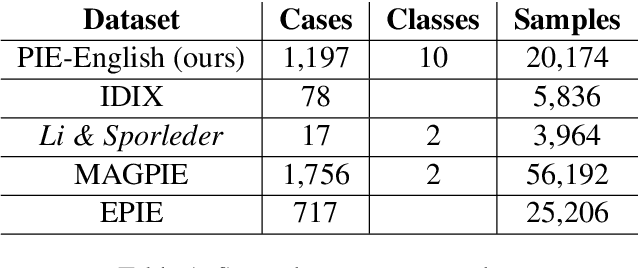
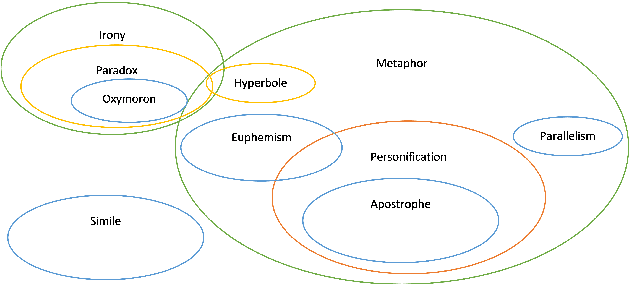
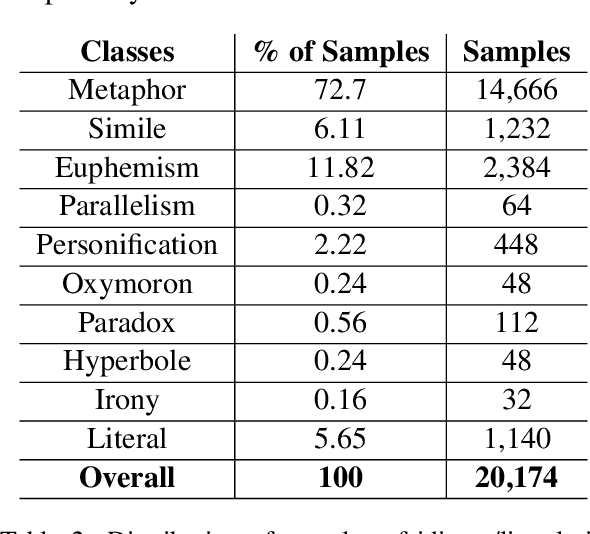
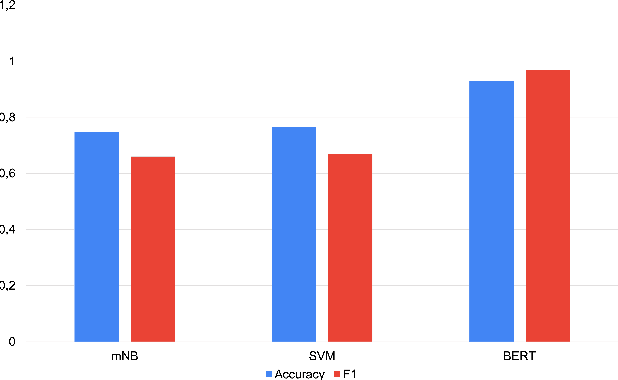
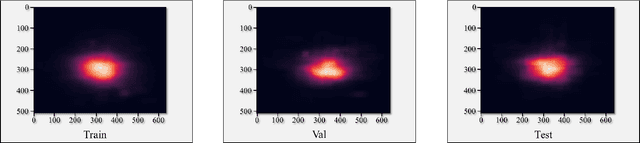
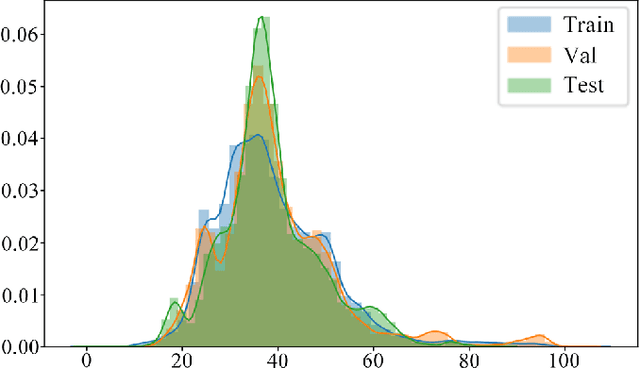
We present a fairly large, Potential Idiomatic Expression (PIE) dataset for Natural Language Processing (NLP) in English. The challenges with NLP systems with regards to tasks such as Machine Translation (MT), word sense disambiguation (WSD) and information retrieval make it imperative to have a labelled idioms dataset with classes such as it is in this work. To the best of the authors' knowledge, this is the first idioms corpus with classes of idioms beyond the literal and the general idioms classification. In particular, the following classes are labelled in the dataset: metaphor, simile, euphemism, parallelism, personification, oxymoron, paradox, hyperbole, irony and literal. Many past efforts have been limited in the corpus size and classes of samples but this dataset contains over 20,100 samples with almost 1,200 cases of idioms (with their meanings) from 10 classes (or senses). The corpus may also be extended by researchers to meet specific needs. The corpus has part of speech (PoS) tagging from the NLTK library. Classification experiments performed on the corpus to obtain a baseline and comparison among three common models, including the BERT model, give good results. We also make publicly available the corpus and the relevant codes for working with it for NLP tasks.
Fusing RGBD Tracking and Segmentation Tree Sampling for Multi-Hypothesis Volumetric Segmentation
Apr 01, 2021
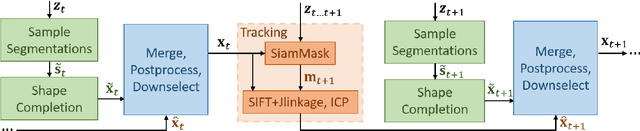


Despite rapid progress in scene segmentation in recent years, 3D segmentation methods are still limited when there is severe occlusion. The key challenge is estimating the segment boundaries of (partially) occluded objects, which are inherently ambiguous when considering only a single frame. In this work, we propose Multihypothesis Segmentation Tracking (MST), a novel method for volumetric segmentation in changing scenes, which allows scene ambiguity to be tracked and our estimates to be adjusted over time as we interact with the scene. Two main innovations allow us to tackle this difficult problem: 1) A novel way to sample possible segmentations from a segmentation tree; and 2) A novel approach to fusing tracking results with multiple segmentation estimates. These methods allow MST to track the segmentation state over time and incorporate new information, such as new objects being revealed. We evaluate our method on several cluttered tabletop environments in simulation and reality. Our results show that MST outperforms baselines in all tested scenes.
Unsupervised Person Re-identification via Simultaneous Clustering and Consistency Learning
Apr 01, 2021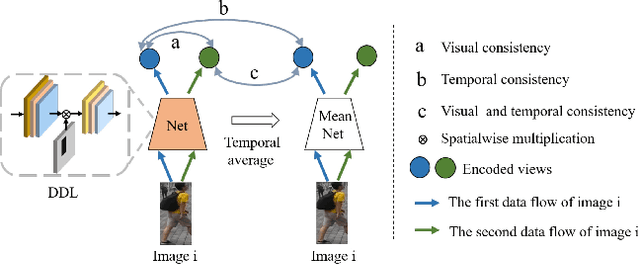
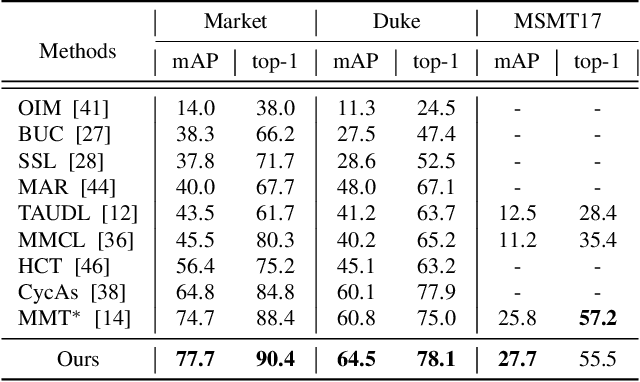
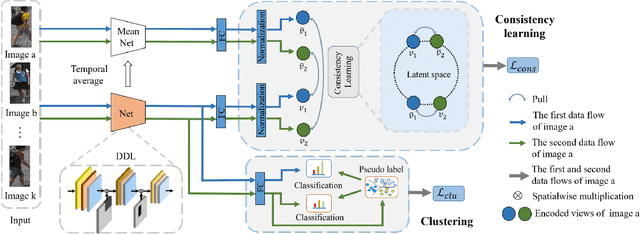
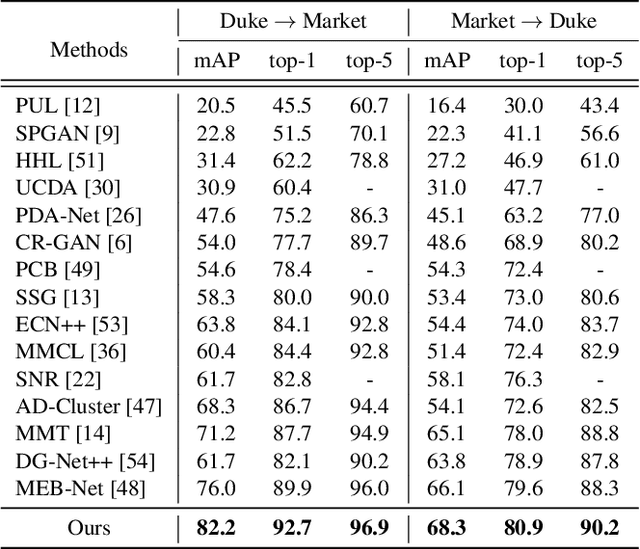
Unsupervised person re-identification (re-ID) has become an important topic due to its potential to resolve the scalability problem of supervised re-ID models. However, existing methods simply utilize pseudo labels from clustering for supervision and thus have not yet fully explored the semantic information in data itself, which limits representation capabilities of learned models. To address this problem, we design a pretext task for unsupervised re-ID by learning visual consistency from still images and temporal consistency during training process, such that the clustering network can separate the images into semantic clusters automatically. Specifically, the pretext task learns semantically meaningful representations by maximizing the agreement between two encoded views of the same image via a consistency loss in latent space. Meanwhile, we optimize the model by grouping the two encoded views into same cluster, thus enhancing the visual consistency between views. Experiments on Market-1501, DukeMTMC-reID and MSMT17 datasets demonstrate that our proposed approach outperforms the state-of-the-art methods by large margins.
Real-Time Surface Fitting to RGBD Sensor Data
Mar 11, 2021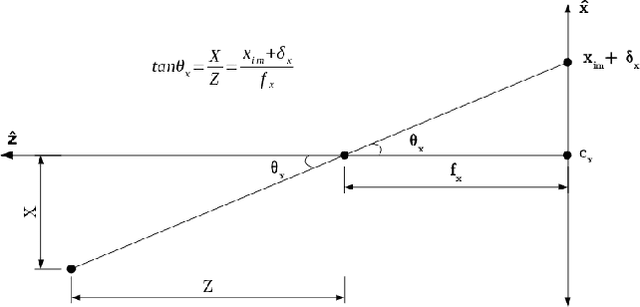
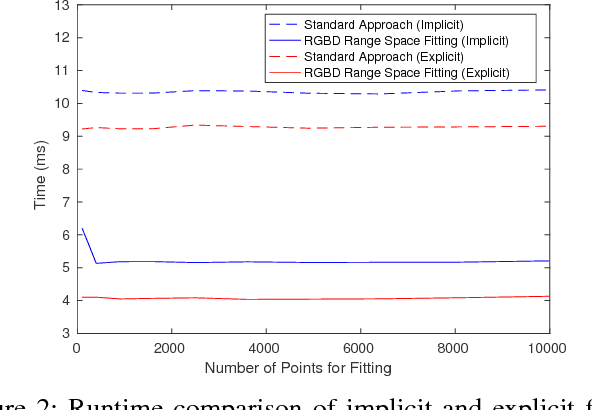
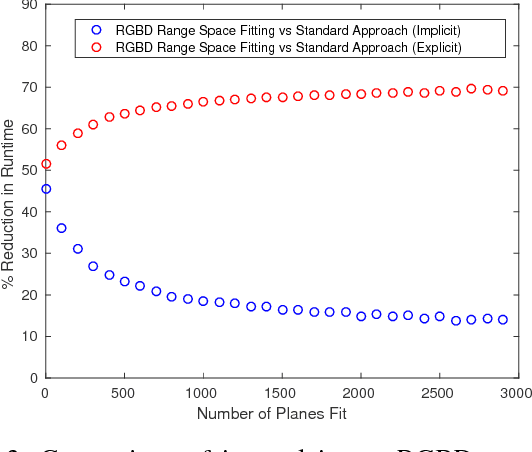

This article describes novel approaches to quickly estimate planar surfaces from RGBD sensor data. The approach manipulates the standard algebraic fitting equations into a form that allows many of the needed regression variables to be computed directly from the camera calibration information. As such, much of the computational burden required by a standard algebraic surface fit can be pre-computed. This provides a significant time and resource savings, especially when many surface fits are being performed which is often the case when RGBD point-cloud data is being analyzed for normal estimation, curvature estimation, polygonization or 3D segmentation applications. Using an integral image implementation, the proposed approaches show a significant increase in performance compared to the standard algebraic fitting approaches.
ActBERT: Learning Global-Local Video-Text Representations
Nov 14, 2020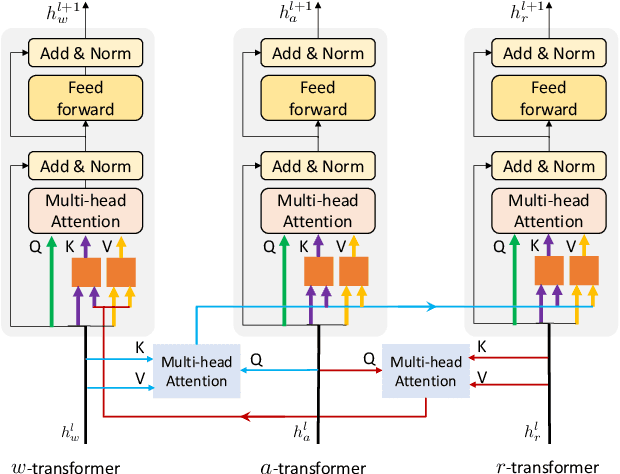
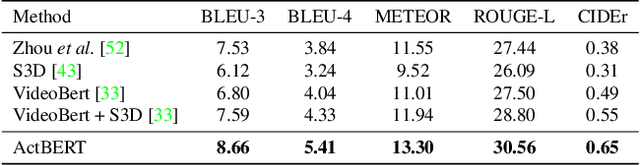
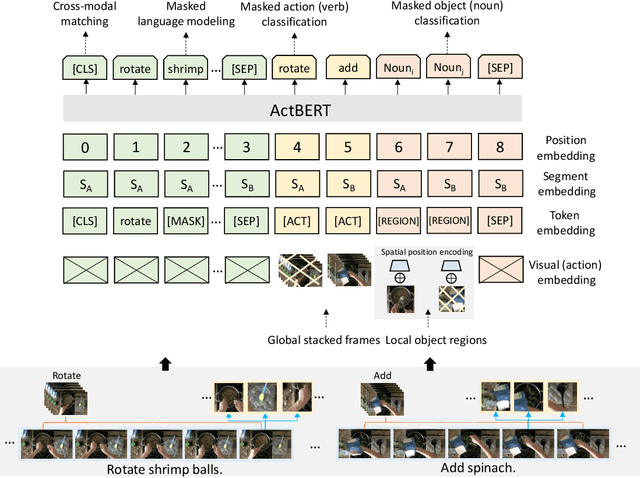

In this paper, we introduce ActBERT for self-supervised learning of joint video-text representations from unlabeled data. First, we leverage global action information to catalyze the mutual interactions between linguistic texts and local regional objects. It uncovers global and local visual clues from paired video sequences and text descriptions for detailed visual and text relation modeling. Second, we introduce an ENtangled Transformer block (ENT) to encode three sources of information, i.e., global actions, local regional objects, and linguistic descriptions. Global-local correspondences are discovered via judicious clues extraction from contextual information. It enforces the joint videotext representation to be aware of fine-grained objects as well as global human intention. We validate the generalization capability of ActBERT on downstream video-and language tasks, i.e., text-video clip retrieval, video captioning, video question answering, action segmentation, and action step localization. ActBERT significantly outperforms the state-of-the-arts, demonstrating its superiority in video-text representation learning.
KLearn: Background Knowledge Inference from Summarization Data
Oct 13, 2020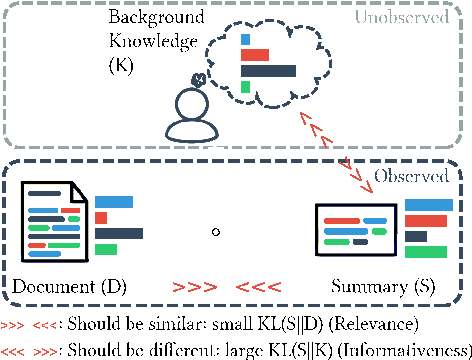
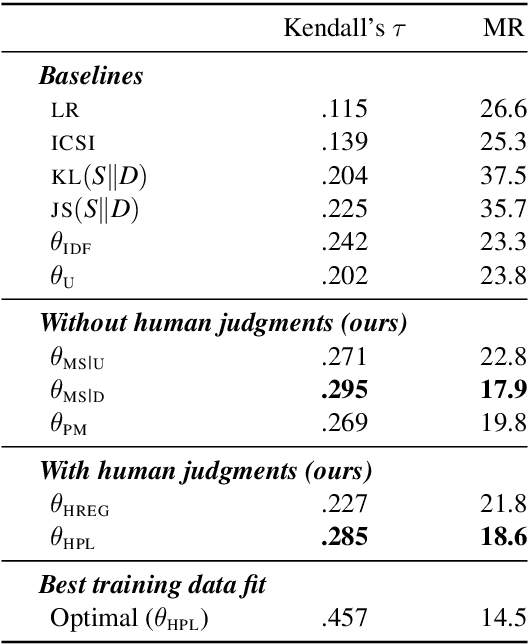
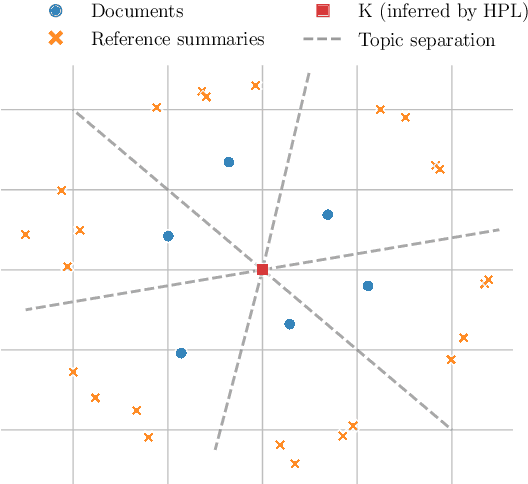
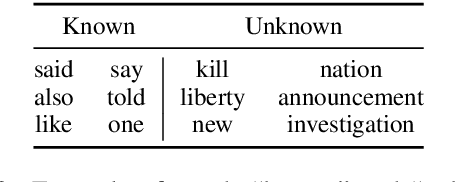
The goal of text summarization is to compress documents to the relevant information while excluding background information already known to the receiver. So far, summarization researchers have given considerably more attention to relevance than to background knowledge. In contrast, this work puts background knowledge in the foreground. Building on the realization that the choices made by human summarizers and annotators contain implicit information about their background knowledge, we develop and compare techniques for inferring background knowledge from summarization data. Based on this framework, we define summary scoring functions that explicitly model background knowledge, and show that these scoring functions fit human judgments significantly better than baselines. We illustrate some of the many potential applications of our framework. First, we provide insights into human information importance priors. Second, we demonstrate that averaging the background knowledge of multiple, potentially biased annotators or corpora greatly improves summary-scoring performance. Finally, we discuss potential applications of our framework beyond summarization.
Intelligent Conversational Android ERICA Applied to Attentive Listening and Job Interview
May 02, 2021

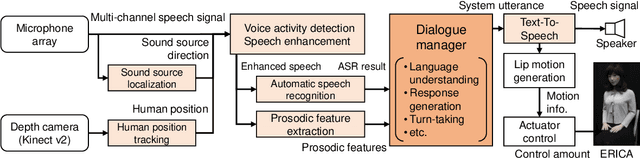
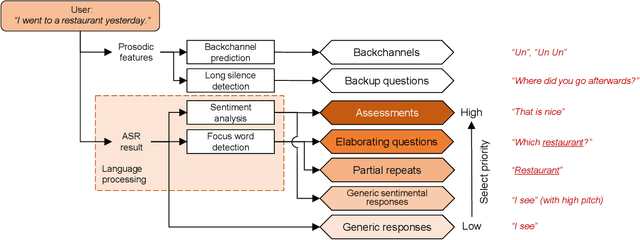
Following the success of spoken dialogue systems (SDS) in smartphone assistants and smart speakers, a number of communicative robots are developed and commercialized. Compared with the conventional SDSs designed as a human-machine interface, interaction with robots is expected to be in a closer manner to talking to a human because of the anthropomorphism and physical presence. The goal or task of dialogue may not be information retrieval, but the conversation itself. In order to realize human-level "long and deep" conversation, we have developed an intelligent conversational android ERICA. We set up several social interaction tasks for ERICA, including attentive listening, job interview, and speed dating. To allow for spontaneous, incremental multiple utterances, a robust turn-taking model is implemented based on TRP (transition-relevance place) prediction, and a variety of backchannels are generated based on time frame-wise prediction instead of IPU-based prediction. We have realized an open-domain attentive listening system with partial repeats and elaborating questions on focus words as well as assessment responses. It has been evaluated with 40 senior people, engaged in conversation of 5-7 minutes without a conversation breakdown. It was also compared against the WOZ setting. We have also realized a job interview system with a set of base questions followed by dynamic generation of elaborating questions. It has also been evaluated with student subjects, showing promising results.
Temporal Graph Modeling for Skeleton-based Action Recognition
Dec 16, 2020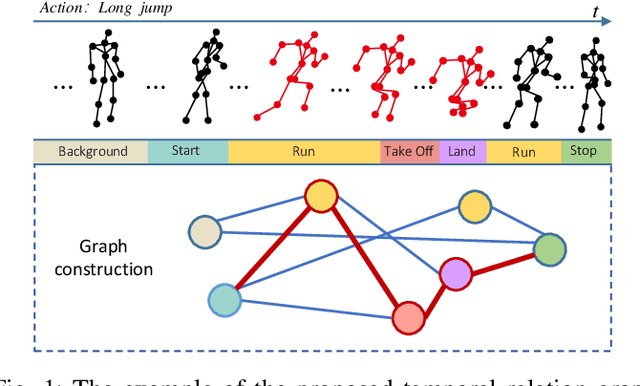
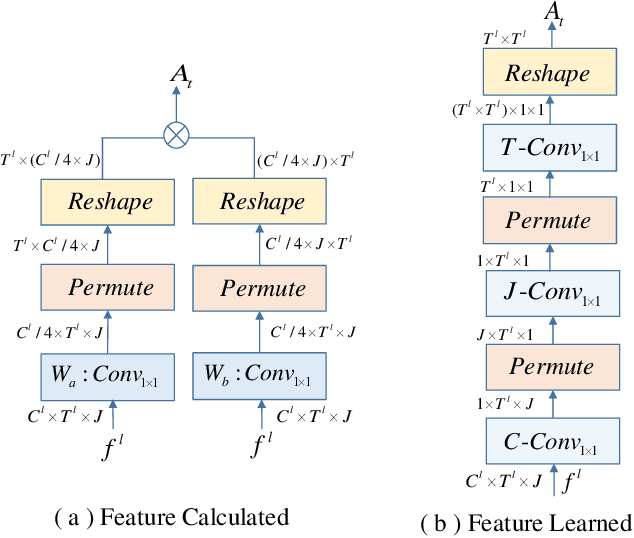
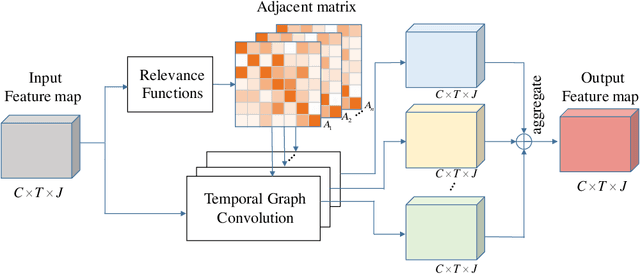
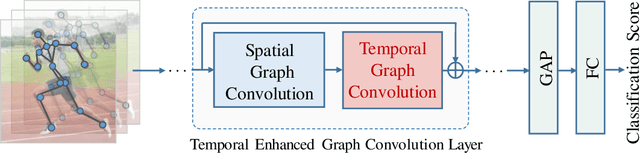
Graph Convolutional Networks (GCNs), which model skeleton data as graphs, have obtained remarkable performance for skeleton-based action recognition. Particularly, the temporal dynamic of skeleton sequence conveys significant information in the recognition task. For temporal dynamic modeling, GCN-based methods only stack multi-layer 1D local convolutions to extract temporal relations between adjacent time steps. With the repeat of a lot of local convolutions, the key temporal information with non-adjacent temporal distance may be ignored due to the information dilution. Therefore, these methods still remain unclear how to fully explore temporal dynamic of skeleton sequence. In this paper, we propose a Temporal Enhanced Graph Convolutional Network (TE-GCN) to tackle this limitation. The proposed TE-GCN constructs temporal relation graph to capture complex temporal dynamic. Specifically, the constructed temporal relation graph explicitly builds connections between semantically related temporal features to model temporal relations between both adjacent and non-adjacent time steps. Meanwhile, to further explore the sufficient temporal dynamic, multi-head mechanism is designed to investigate multi-kinds of temporal relations. Extensive experiments are performed on two widely used large-scale datasets, NTU-60 RGB+D and NTU-120 RGB+D. And experimental results show that the proposed model achieves the state-of-the-art performance by making contribution to temporal modeling for action recognition.