 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-script Handwritten Digit Recognition Using Multi-task Learning
Jun 15, 2021
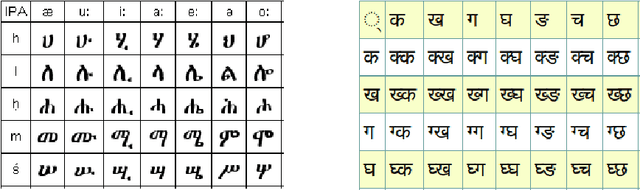

Handwritten digit recognition is one of the extensively studied area in machine learning. Apart from the wider research on handwritten digit recognition on MNIST dataset, there are many other research works on various script recognition. However, it is not very common for multi-script digit recognition which encourage the development of robust and multipurpose systems. Additionally working on multi-script digit recognition enables multi-task learning, considering the script classification as a related task for instance. It is evident that multi-task learning improves model performance through inductive transfer using the information contained in related tasks. Therefore, in this study multi-script handwritten digit recognition using multi-task learning will be investigated. As a specific case of demonstrating the solution to the problem, Amharic handwritten character recognition will also be experimented. The handwritten digits of three scripts including Latin, Arabic and Kannada are studied to show that multi-task models with reformulation of the individual tasks have shown promising results. In this study a novel way of using the individual tasks predictions was proposed to help classification performance and regularize the different loss for the purpose of the main task. This finding has outperformed the baseline and the conventional multi-task learning models. More importantly, it avoided the need for weighting the different losses of the tasks, which is one of the challenges in multi-task learning.
Self-Guided Instance-Aware Network for Depth Completion and Enhancement
May 25, 2021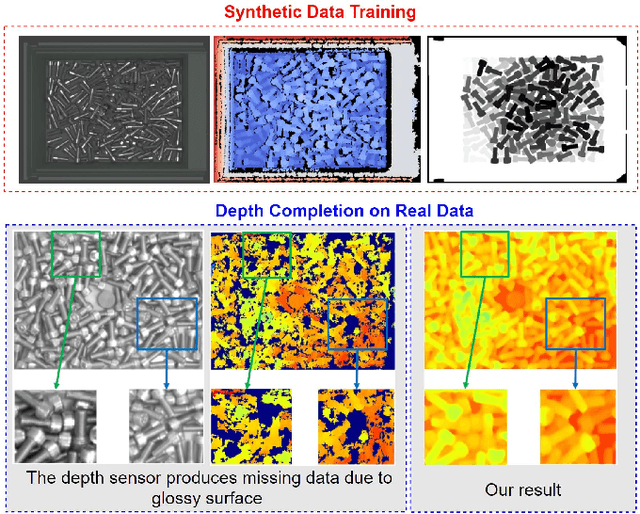
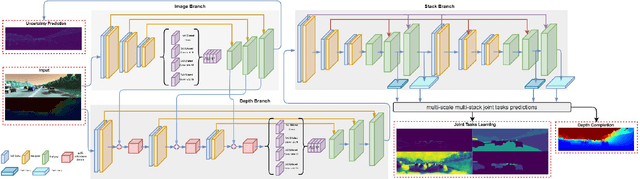
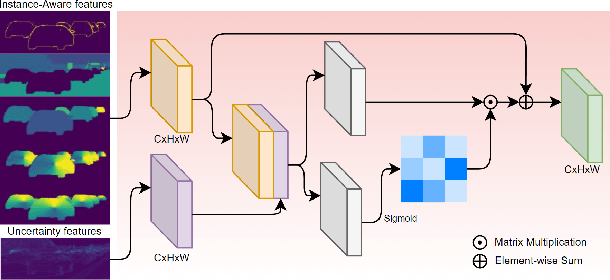
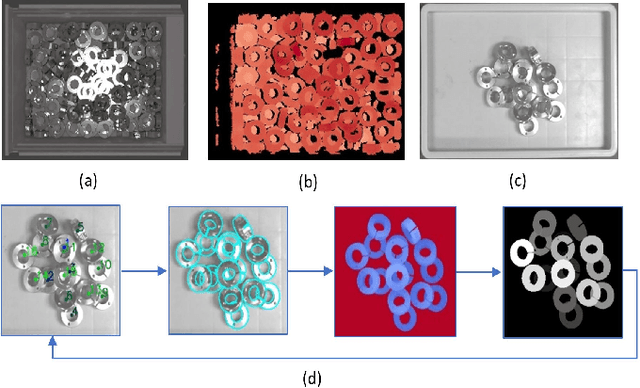
Depth completion aims at inferring a dense depth image from sparse depth measurement since glossy, transparent or distant surface cannot be scanned properly by the sensor. Most of existing methods directly interpolate the missing depth measurements based on pixel-wise image content and the corresponding neighboring depth values. Consequently, this leads to blurred boundaries or inaccurate structure of object. To address these problems, we propose a novel self-guided instance-aware network (SG-IANet) that: (1) utilize self-guided mechanism to extract instance-level features that is needed for depth restoration, (2) exploit the geometric and context information into network learning to conform to the underlying constraints for edge clarity and structure consistency, (3) regularize the depth estimation and mitigate the impact of noise by instance-aware learning, and (4) train with synthetic data only by domain randomization to bridge the reality gap. Extensive experiments on synthetic and real world dataset demonstrate that our proposed method outperforms previous works. Further ablation studies give more insights into the proposed method and demonstrate the generalization capability of our model.
Transferring Semantic Roles Using Translation and Syntactic Information
Oct 03, 2017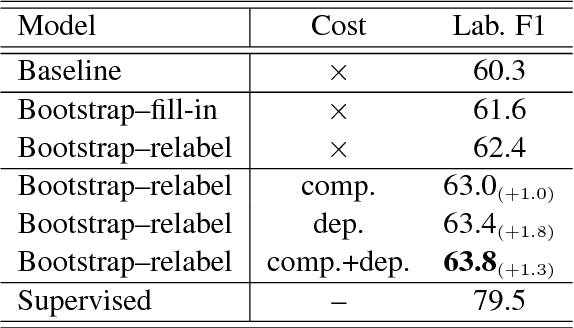
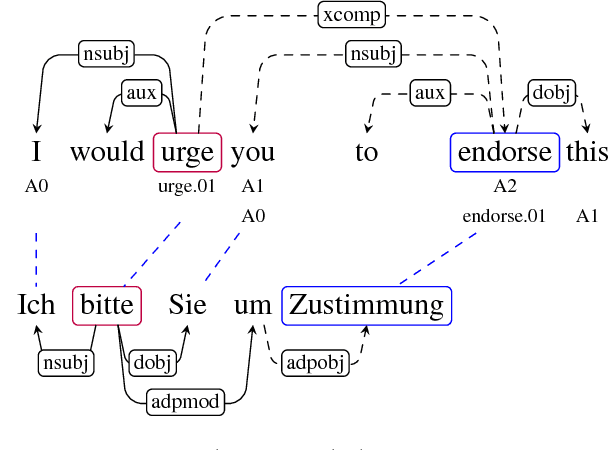
Our paper addresses the problem of annotation projection for semantic role labeling for resource-poor languages using supervised annotations from a resource-rich language through parallel data. We propose a transfer method that employs information from source and target syntactic dependencies as well as word alignment density to improve the quality of an iterative bootstrapping method. Our experiments yield a $3.5$ absolute labeled F-score improvement over a standard annotation projection method.
One Million Scenes for Autonomous Driving: ONCE Dataset
Jun 21, 2021
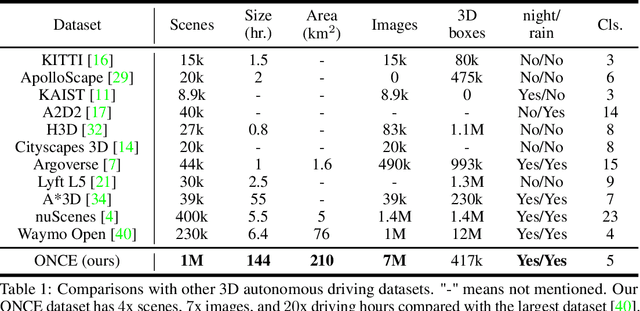
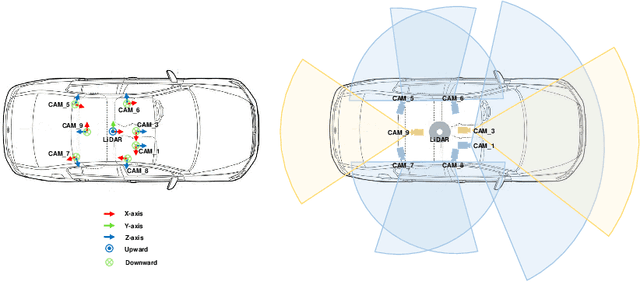

Current perception models in autonomous driving have become notorious for greatly relying on a mass of annotated data to cover unseen cases and address the long-tail problem. On the other hand, learning from unlabeled large-scale collected data and incrementally self-training powerful recognition models have received increasing attention and may become the solutions of next-generation industry-level powerful and robust perception models in autonomous driving. However, the research community generally suffered from data inadequacy of those essential real-world scene data, which hampers the future exploration of fully/semi/self-supervised methods for 3D perception. In this paper, we introduce the ONCE (One millioN sCenEs) dataset for 3D object detection in the autonomous driving scenario. The ONCE dataset consists of 1 million LiDAR scenes and 7 million corresponding camera images. The data is selected from 144 driving hours, which is 20x longer than the largest 3D autonomous driving dataset available (e.g. nuScenes and Waymo), and it is collected across a range of different areas, periods and weather conditions. To facilitate future research on exploiting unlabeled data for 3D detection, we additionally provide a benchmark in which we reproduce and evaluate a variety of self-supervised and semi-supervised methods on the ONCE dataset. We conduct extensive analyses on those methods and provide valuable observations on their performance related to the scale of used data. Data, code, and more information are available at https://once-for-auto-driving.github.io/index.html.
A Convolutional Architecture for 3D Model Embedding
Mar 05, 2021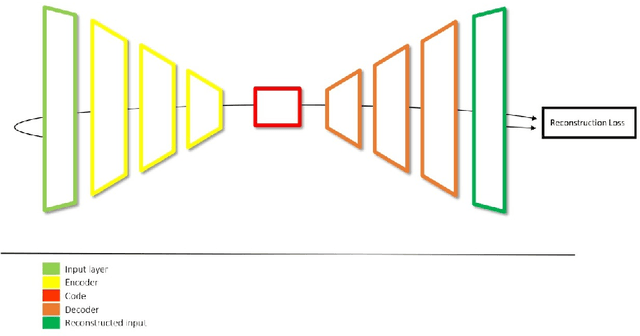
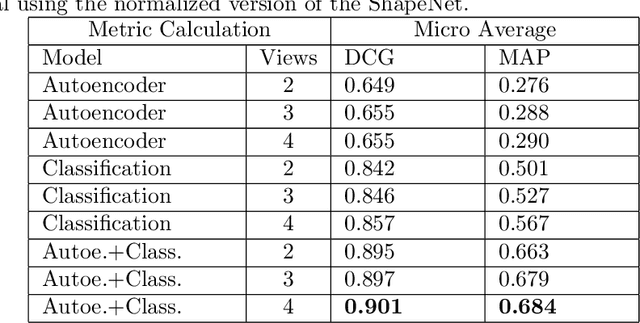
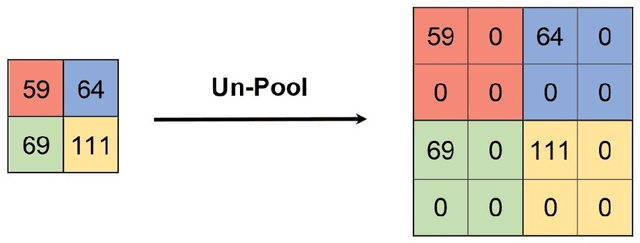
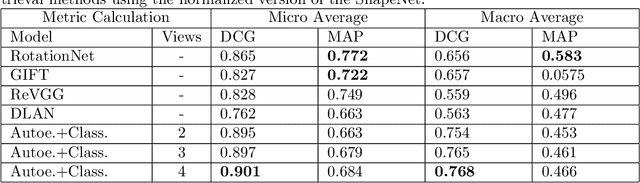
During the last years, many advances have been made in tasks like3D model retrieval, 3D model classification, and 3D model segmentation.The typical 3D representations such as point clouds, voxels, and poly-gon meshes are mostly suitable for rendering purposes, while their use forcognitive processes (retrieval, classification, segmentation) is limited dueto their high redundancy and complexity. We propose a deep learningarchitecture to handle 3D models as an input. We combine this architec-ture with other standard architectures like Convolutional Neural Networksand autoencoders for computing 3D model embeddings. Our goal is torepresent a 3D model as a vector with enough information to substitutethe 3D model for high-level tasks. Since this vector is a learned repre-sentation which tries to capture the relevant information of a 3D model,we show that the embedding representation conveys semantic informationthat helps to deal with the similarity assessment of 3D objects. Our ex-periments show the benefit of computing the embeddings of a 3D modeldata set and use them for effective 3D Model Retrieval.
JUMBO: Scalable Multi-task Bayesian Optimization using Offline Data
Jun 02, 2021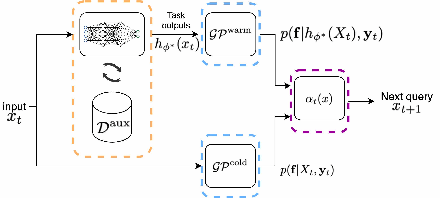

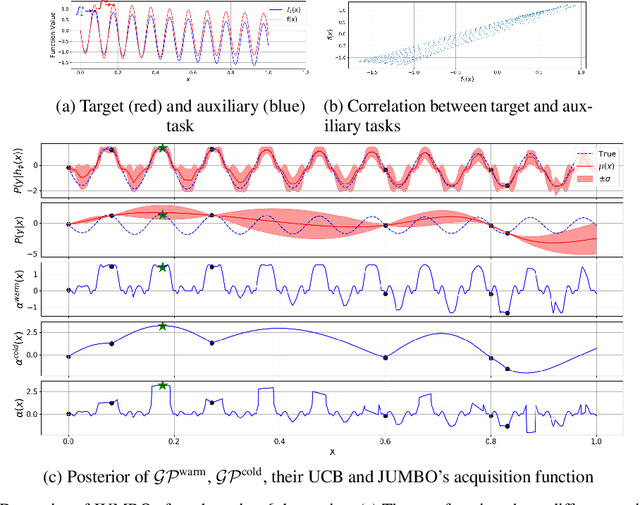
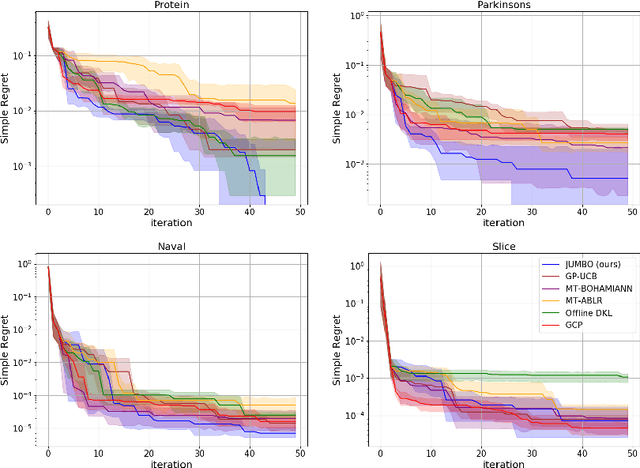
The goal of Multi-task Bayesian Optimization (MBO) is to minimize the number of queries required to accurately optimize a target black-box function, given access to offline evaluations of other auxiliary functions. When offline datasets are large, the scalability of prior approaches comes at the expense of expressivity and inference quality. We propose JUMBO, an MBO algorithm that sidesteps these limitations by querying additional data based on a combination of acquisition signals derived from training two Gaussian Processes (GP): a cold-GP operating directly in the input domain and a warm-GP that operates in the feature space of a deep neural network pretrained using the offline data. Such a decomposition can dynamically control the reliability of information derived from the online and offline data and the use of pretrained neural networks permits scalability to large offline datasets. Theoretically, we derive regret bounds for JUMBO and show that it achieves no-regret under conditions analogous to GP-UCB (Srinivas et. al. 2010). Empirically, we demonstrate significant performance improvements over existing approaches on two real-world optimization problems: hyper-parameter optimization and automated circuit design.
Symmetric Monoidal Categories with Attributes
Jan 26, 2021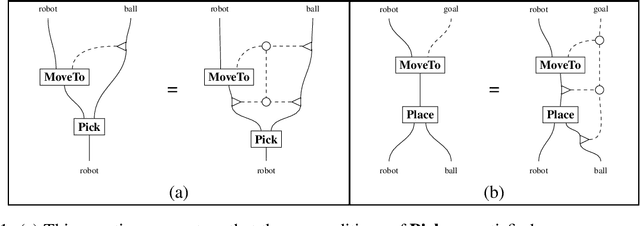
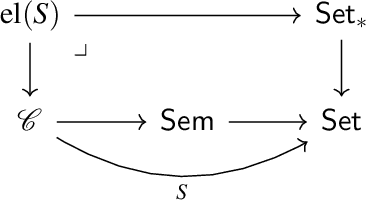
When designing plans in engineering, it is often necessary to consider attributes associated to objects, e.g. the location of a robot. Our aim in this paper is to incorporate attributes into existing categorical formalisms for planning, namely those based on symmetric monoidal categories and string diagrams. To accomplish this, we define a notion of a "symmetric monoidal category with attributes." This is a symmetric monoidal category in which objects are equipped with retrievable information and where the interactions between objects and information are governed by an "attribute structure." We discuss examples and semantics of such categories in the context of robotics to illustrate our definition.
* In Proceedings ACT 2020, arXiv:2101.07888
Generalized Spatially Coupled Parallel Concatenated Convolutional Codes With Partial Repetition
May 03, 2021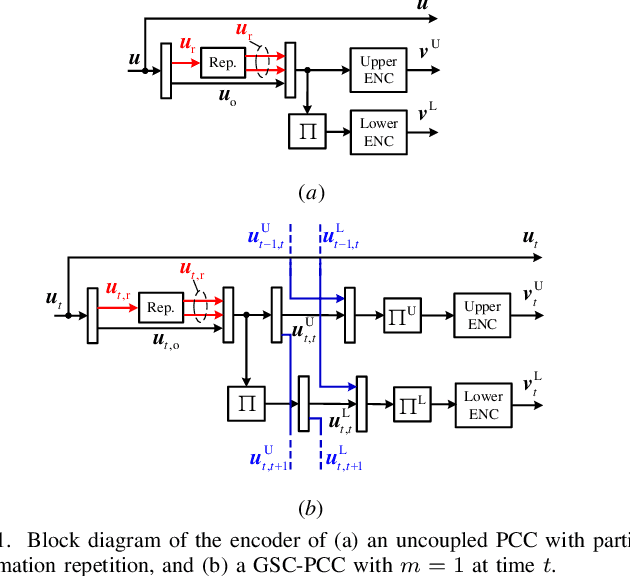
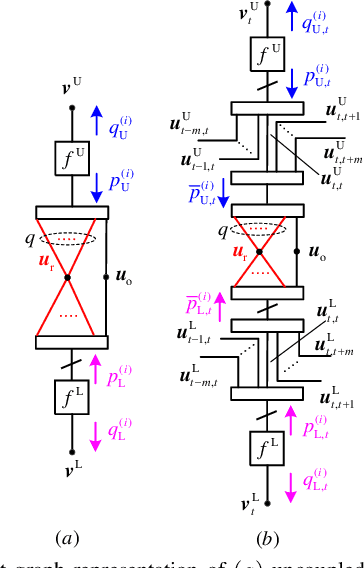
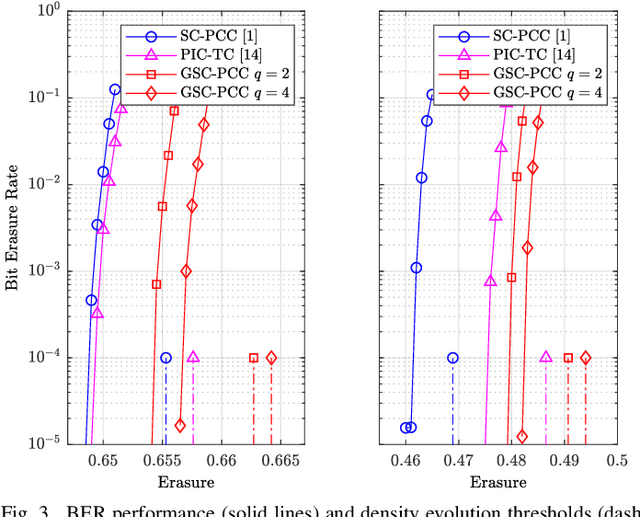
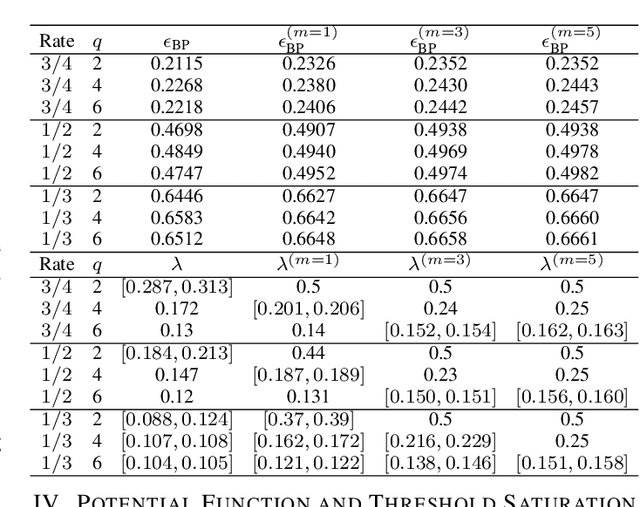
We introduce generalized spatially coupled parallel concatenated codes (GSC-PCCs), a class of spatially coupled turbo-like codes obtained by coupling parallel concatenated codes (PCCs) with a fraction of information bits repeated before the PCC encoding. GSC-PCCs can be seen as a generalization of the original spatially coupled parallel concatenated convolutional codes (SC-PCCs) proposed by Moloudi et al. [1]. To characterize the asymptotic performance of GSC-PCCs, we derive the corresponding density evolution equations and compute their decoding thresholds. We show that the proposed codes have some nice properties such as threshold saturation and that their decoding thresholds improve with the repetition factor $q$. Most notably, our analysis suggests that the proposed codes asymptotically approach the capacity as $q$ tends to infinity with any given constituent convolutional code.
Collaborative Mapping of Archaeological Sites using multiple UAVs
May 17, 2021
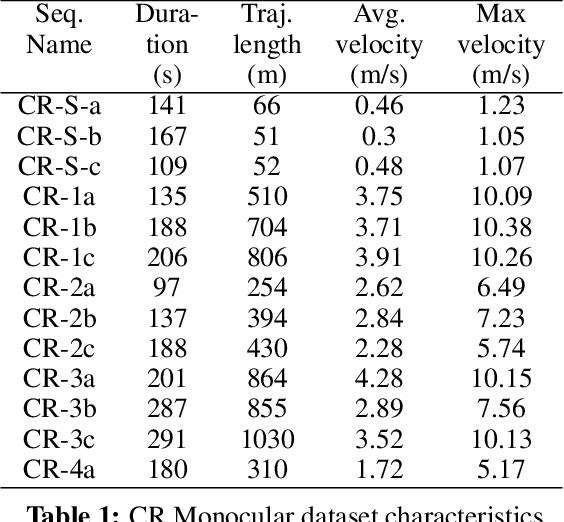
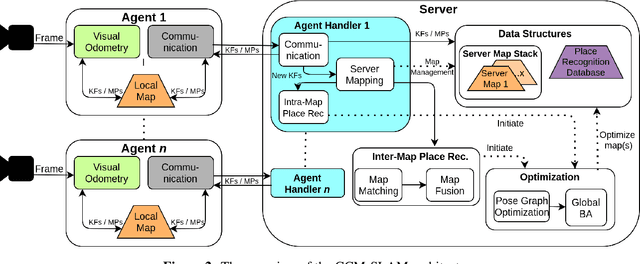
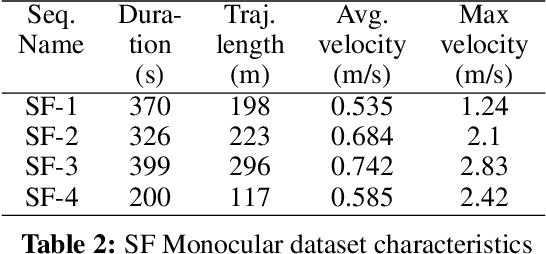
UAVs have found an important application in archaeological mapping. Majority of the existing methods employ an offline method to process the data collected from an archaeological site. They are time-consuming and computationally expensive. In this paper, we present a multi-UAV approach for faster mapping of archaeological sites. Employing a team of UAVs not only reduces the mapping time by distribution of coverage area, but also improves the map accuracy by exchange of information. Through extensive experiments in a realistic simulation (AirSim), we demonstrate the advantages of using a collaborative mapping approach. We then create the first 3D map of the Sadra Fort, a 15th Century Fort located in Gujarat, India using our proposed method. Additionally, we present two novel archaeological datasets recorded in both simulation and real-world to facilitate research on collaborative archaeological mapping. For the benefit of the community, we make the AirSim simulation environment, as well as the datasets publicly available.
Improving Document Representations by Generating Pseudo Query Embeddings for Dense Retrieval
May 08, 2021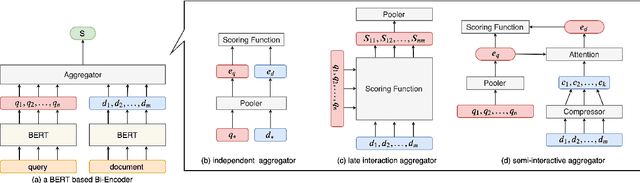
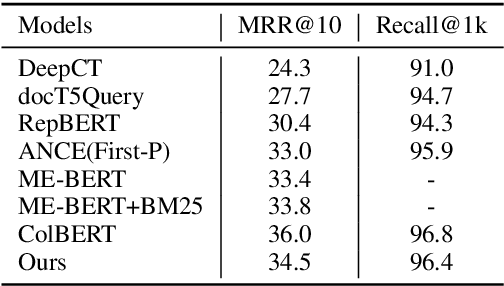
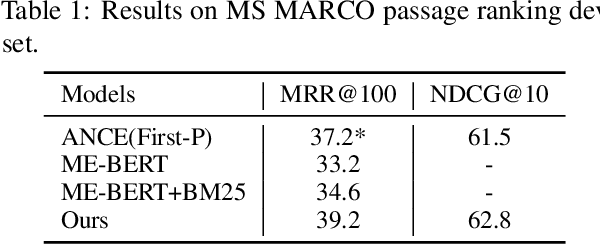
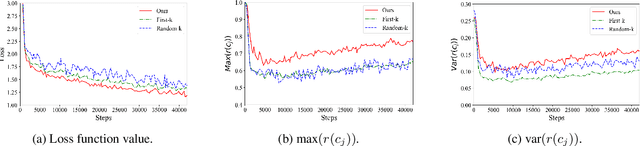
Recently, the retrieval models based on dense representations have been gradually applied in the first stage of the document retrieval tasks, showing better performance than traditional sparse vector space models. To obtain high efficiency, the basic structure of these models is Bi-encoder in most cases. However, this simple structure may cause serious information loss during the encoding of documents since the queries are agnostic. To address this problem, we design a method to mimic the queries on each of the documents by an iterative clustering process and represent the documents by multiple pseudo queries (i.e., the cluster centroids). To boost the retrieval process using approximate nearest neighbor search library, we also optimize the matching function with a two-step score calculation procedure. Experimental results on several popular ranking and QA datasets show that our model can achieve state-of-the-art results.