 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSI-Diff: A Framework for Learning Search and High-Precision Insertion with a Force-Domain Diffusion Policy
May 12, 2026Contact-rich assembly is fundamental in robotics but poses significant challenges due to uncertainties in relative poses, such as misalignments and small clearances in peg-in-hole tasks. Existing approaches typically address search and high-precision insertion separately, because these tasks involve distinct action patterns. However, supporting both tasks within a single model, without switching models or weights, is desirable for intelligent assembly systems. In this work, we propose SI-Diff, a framework that learns both search and high-precision insertion through a force-domain diffusion policy. To this end, we introduce a new mode-conditioning mechanism that enables the policy to capture distinct action behaviors under a single framework. Moreover, we develop a new search teacher policy that can generate diverse trajectories. By training on successful and efficient demonstrations provided by the teacher policy, the model learns the mapping from tactile and end-effector velocity observations to effective action behaviors. We conduct thorough experiments to show that SI-Diff extends the tolerance to x-y misalignments from 2 mm to 5 mm compared to the state-of-the-art baseline, TacDiffusion, while also demonstrating strong zero-shot transferability to unseen shapes.
Self-Guided Instance-Aware Network for Depth Completion and Enhancement
May 27, 2021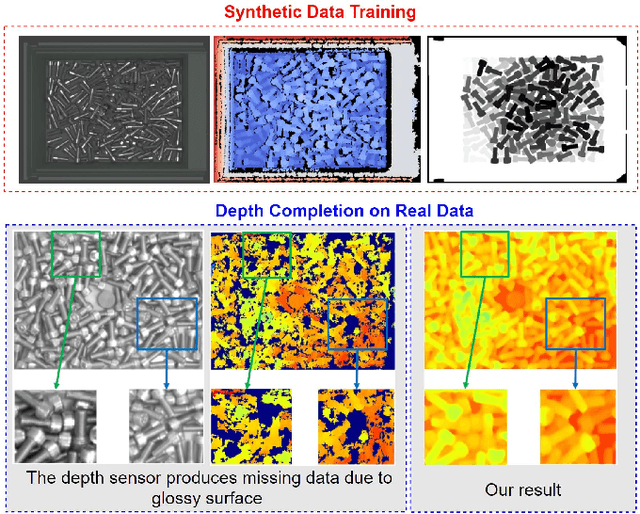
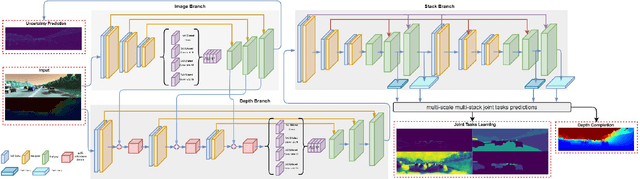
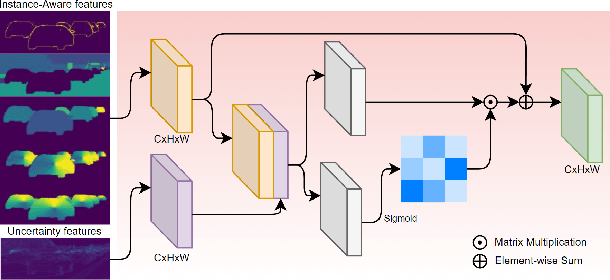
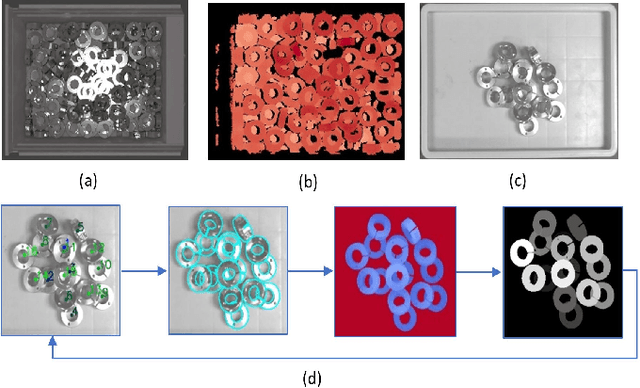
Depth completion aims at inferring a dense depth image from sparse depth measurement since glossy, transparent or distant surface cannot be scanned properly by the sensor. Most of existing methods directly interpolate the missing depth measurements based on pixel-wise image content and the corresponding neighboring depth values. Consequently, this leads to blurred boundaries or inaccurate structure of object. To address these problems, we propose a novel self-guided instance-aware network (SG-IANet) that: (1) utilize self-guided mechanism to extract instance-level features that is needed for depth restoration, (2) exploit the geometric and context information into network learning to conform to the underlying constraints for edge clarity and structure consistency, (3) regularize the depth estimation and mitigate the impact of noise by instance-aware learning, and (4) train with synthetic data only by domain randomization to bridge the reality gap. Extensive experiments on synthetic and real world dataset demonstrate that our proposed method outperforms previous works. Further ablation studies give more insights into the proposed method and demonstrate the generalization capability of our model.