 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Alternative Microfoundations for Strategic Classification
Jun 24, 2021
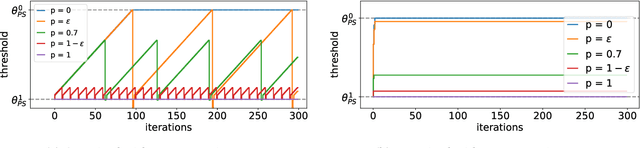
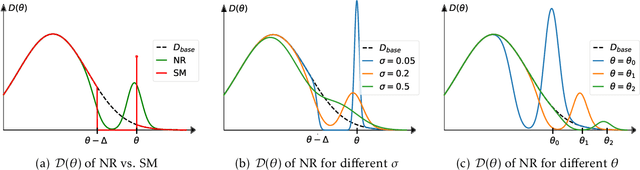
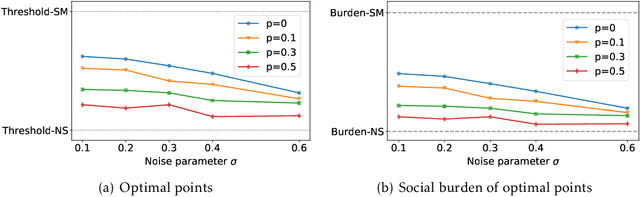
When reasoning about strategic behavior in a machine learning context it is tempting to combine standard microfoundations of rational agents with the statistical decision theory underlying classification. In this work, we argue that a direct combination of these standard ingredients leads to brittle solution concepts of limited descriptive and prescriptive value. First, we show that rational agents with perfect information produce discontinuities in the aggregate response to a decision rule that we often do not observe empirically. Second, when any positive fraction of agents is not perfectly strategic, desirable stable points -- where the classifier is optimal for the data it entails -- cease to exist. Third, optimal decision rules under standard microfoundations maximize a measure of negative externality known as social burden within a broad class of possible assumptions about agent behavior. Recognizing these limitations we explore alternatives to standard microfoundations for binary classification. We start by describing a set of desiderata that help navigate the space of possible assumptions about how agents respond to a decision rule. In particular, we analyze a natural constraint on feature manipulations, and discuss properties that are sufficient to guarantee the robust existence of stable points. Building on these insights, we then propose the noisy response model. Inspired by smoothed analysis and empirical observations, noisy response incorporates imperfection in the agent responses, which we show mitigates the limitations of standard microfoundations. Our model retains analytical tractability, leads to more robust insights about stable points, and imposes a lower social burden at optimality.
Medical Image Analysis on Left Atrial LGE MRI for Atrial Fibrillation Studies: A Review
Jun 18, 2021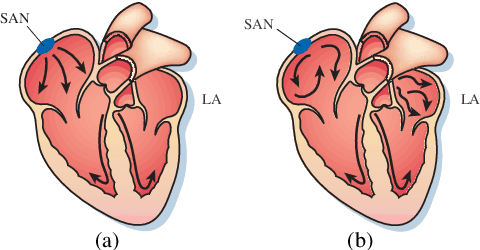
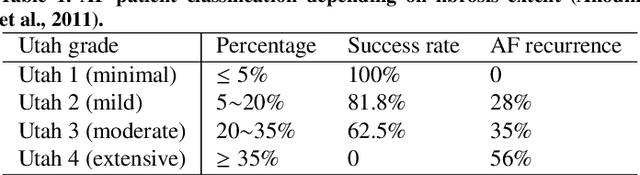
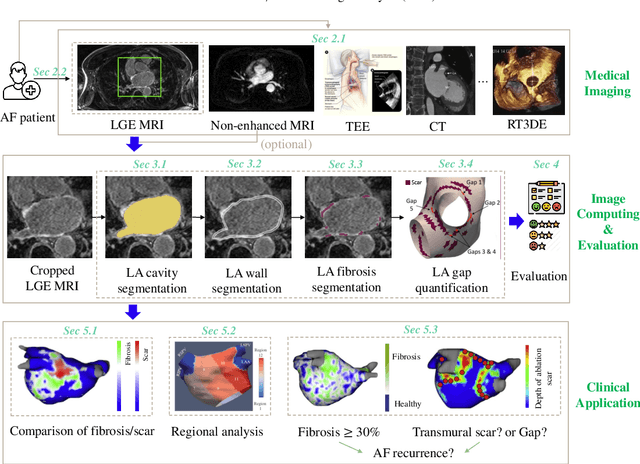

Late gadolinium enhancement magnetic resonance imaging (LGE MRI) is commonly used to visualize and quantify left atrial (LA) scars. The position and extent of scars provide important information of the pathophysiology and progression of atrial fibrillation (AF). Hence, LA scar segmentation and quantification from LGE MRI can be useful in computer-assisted diagnosis and treatment stratification of AF patients. Since manual delineation can be time-consuming and subject to intra- and inter-expert variability, automating this computing is highly desired, which nevertheless is still challenging and under-researched. This paper aims to provide a systematic review on computing methods for LA cavity, wall, scar and ablation gap segmentation and quantification from LGE MRI, and the related literature for AF studies. Specifically, we first summarize AF-related imaging techniques, particularly LGE MRI. Then, we review the methodologies of the four computing tasks in detail, and summarize the validation strategies applied in each task. Finally, the possible future developments are outlined, with a brief survey on the potential clinical applications of the aforementioned methods. The review shows that the research into this topic is still in early stages. Although several methods have been proposed, especially for LA segmentation, there is still large scope for further algorithmic developments due to performance issues related to the high variability of enhancement appearance and differences in image acquisition.
Unsupervised Anomaly Segmentation using Image-Semantic Cycle Translation
Mar 16, 2021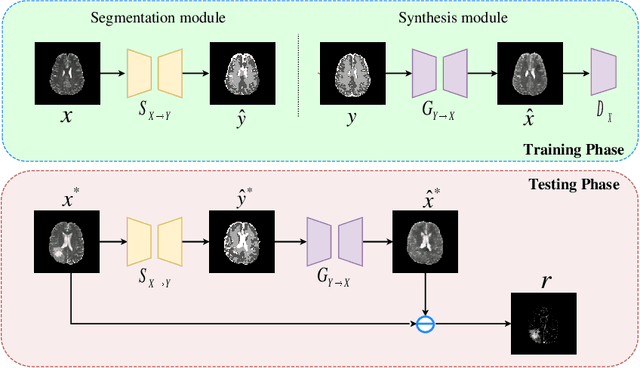

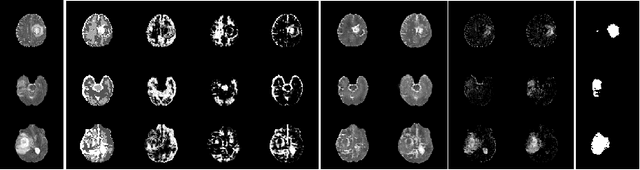
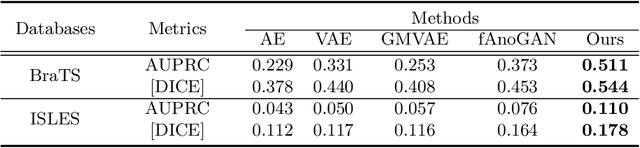
The goal of unsupervised anomaly segmentation (UAS) is to detect the pixel-level anomalies unseen during training. It is a promising field in the medical imaging community, e.g, we can use the model trained with only healthy data to segment the lesions of rare diseases. Existing methods are mainly based on Information Bottleneck, whose underlying principle is modeling the distribution of normal anatomy via learning to compress and recover the healthy data with a low-dimensional manifold, and then detecting lesions as the outlier from this learned distribution. However, this dimensionality reduction inevitably damages the localization information, which is especially essential for pixel-level anomaly detection. In this paper, to alleviate this issue, we introduce the semantic space of healthy anatomy in the process of modeling healthy-data distribution. More precisely, we view the couple of segmentation and synthesis as a special Autoencoder, and propose a novel cycle translation framework with a journey of 'image->semantic->image'. Experimental results on the BraTS and ISLES databases show that the proposed approach achieves significantly superior performance compared to several prior methods and segments the anomalies more accurately.
Automated Generation of Robotic Planning Domains from Observations
May 28, 2021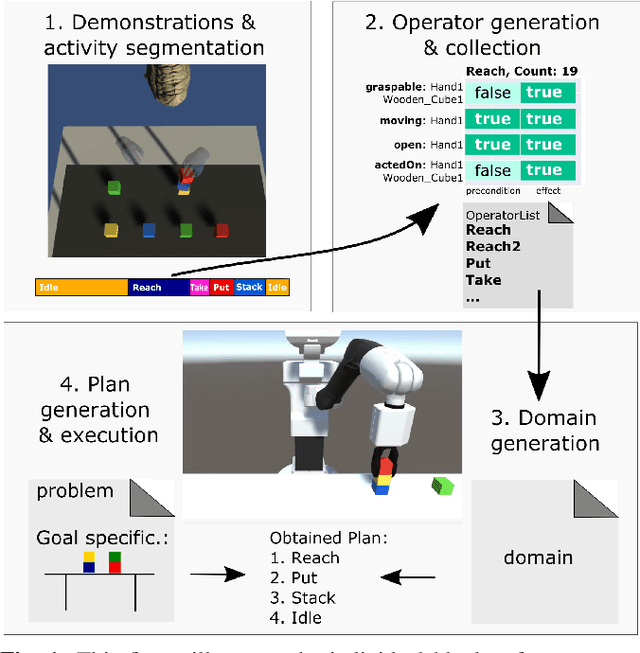
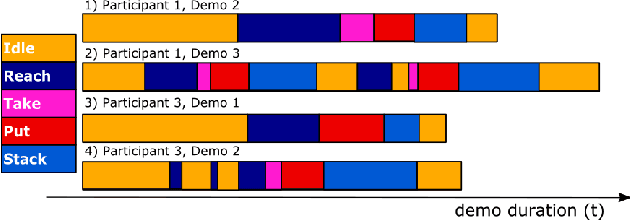
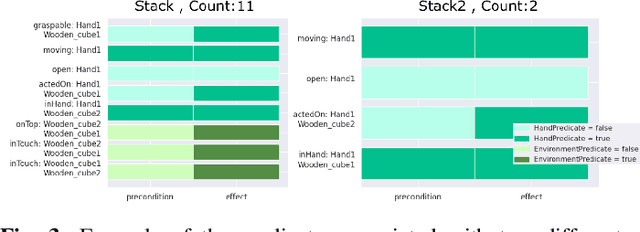
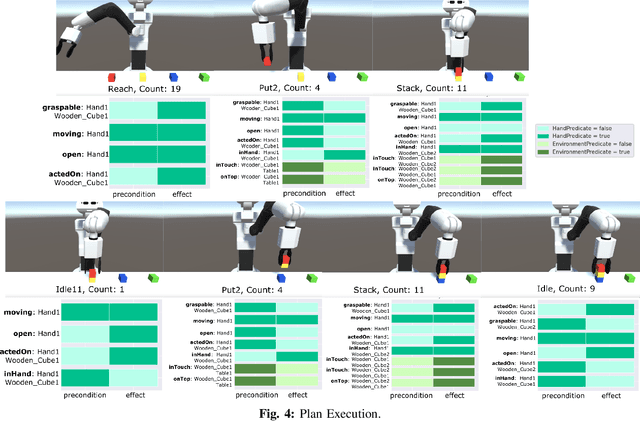
Automated planning enables robots to find plans to achieve complex, long-horizon tasks, given a planning domain. This planning domain consists of a list of actions, with their associated preconditions and effects, and is usually manually defined by a human expert, which is very time-consuming or even infeasible. In this paper, we introduce a novel method for generating this domain automatically from human demonstrations. First, we automatically segment and recognize the different observed actions from human demonstrations. From these demonstrations, the relevant preconditions and effects are obtained, and the associated planning operators are generated. Finally, a sequence of actions that satisfies a user-defined goal can be planned using a symbolic planner. The generated plan is executed in a simulated environment by the TIAGo robot. We tested our method on a dataset of 12 demonstrations collected from three different participants. The results show that our method is able to generate executable plans from using one single demonstration with a 92% success rate, and 100% when the information from all demonstrations are included, even for previously unknown stacking goals.
An Information-Theoretic Approach for Path Planning in Agents with Computational Constraints
May 19, 2020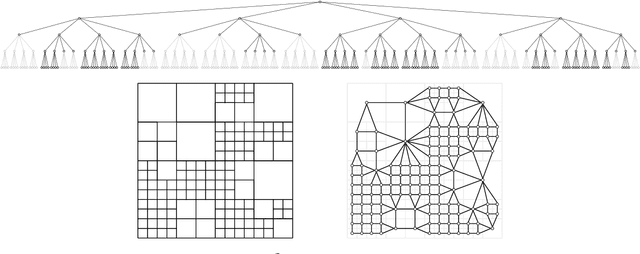
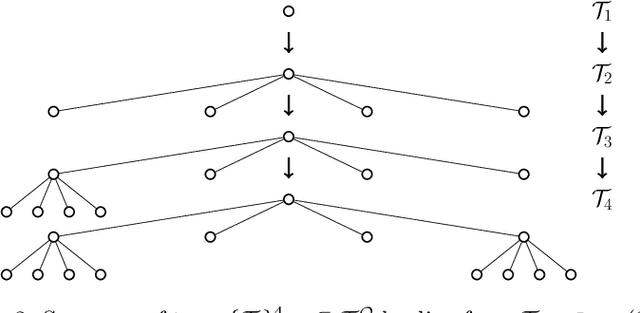
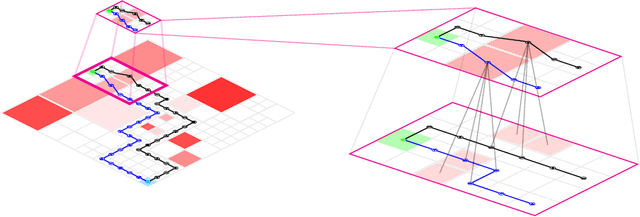
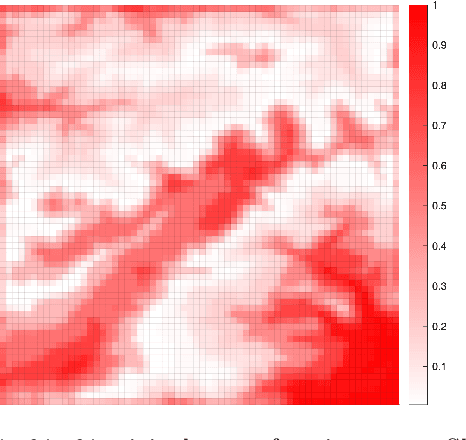
In this paper, we develop a framework for path-planning on abstractions that are not provided to the system a-priori but instead emerge as a function of the agent's available computational resources. We show how a path-planning problem in an environment can be systematically approximated by solving a sequence of easier to solve problems on abstractions of the original space. The properties of the problem are analyzed, and supporting theoretical results presented and discussed. A numerical example is presented to show the utility of the approach and to corroborate the theoretical findings. We conclude by providing a discussion of the results and their interpretation relating to anytime algorithms and bounded rationality.
Short-Term Stock Price-Trend Prediction Using Meta-Learning
May 28, 2021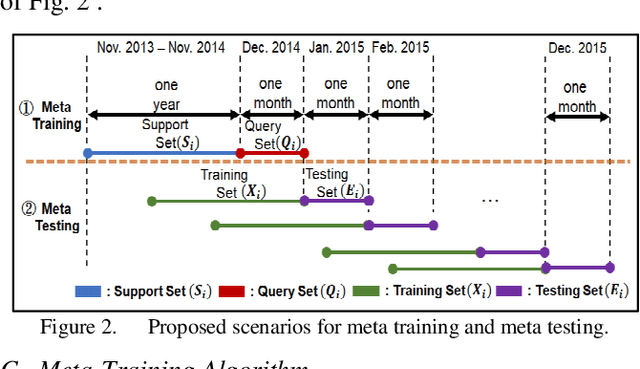
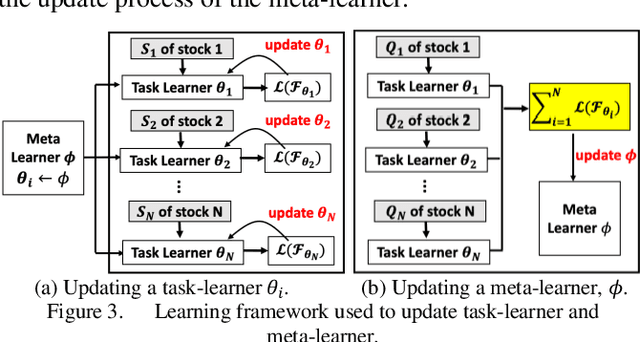
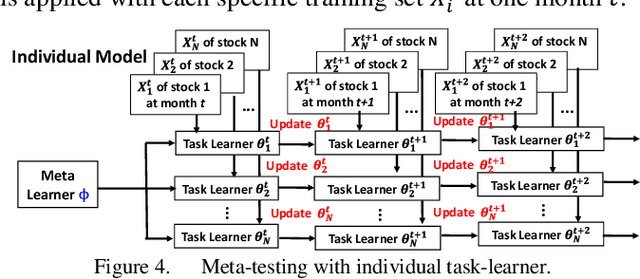
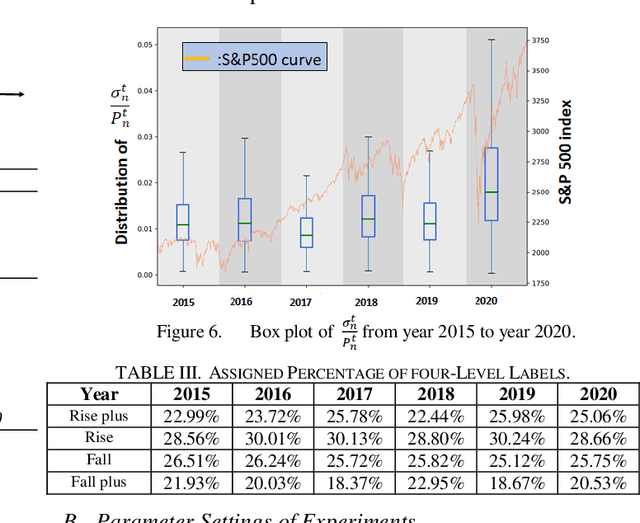
Although conventional machine learning algorithms have been widely adopted for stock-price predictions in recent years, the massive volume of specific labeled data required are not always available. In contrast, meta-learning technology uses relatively small amounts of training data, called fast learners. Such methods are beneficial under conditions of limited data availability, which often obtain for trend prediction based on time-series data limited by sparse information. In this study, we consider short-term stock price prediction using a meta-learning framework with several convolutional neural networks, including the temporal convolution network, fully convolutional network, and residual neural network. We propose a sliding time horizon to label stocks according to their predicted price trends, referred to as called dynamic k-average labeling, using prediction labels including "rise plus", "rise", "fall", and "fall plus". The effectiveness of the proposed meta-learning framework was evaluated by application to the S&P500. The experimental results show that the inclusion of the proposed meta-learning framework significantly improved both regular and balanced prediction accuracy and profitability.
Space-time Mixing Attention for Video Transformer
Jun 11, 2021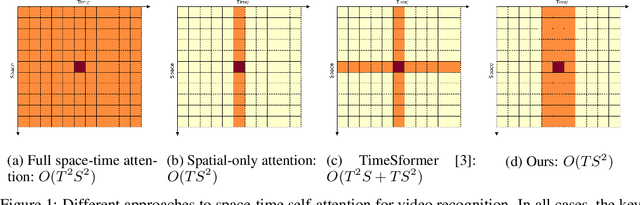
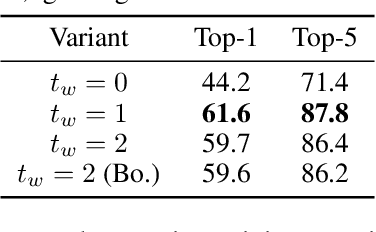
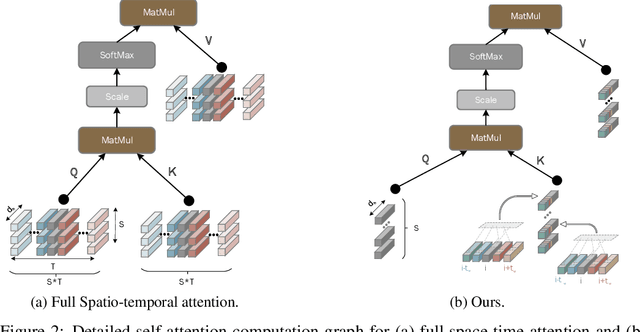
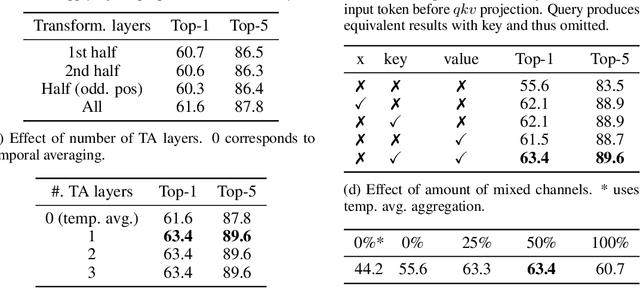
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
ASFM-Net: Asymmetrical Siamese Feature Matching Network for Point Completion
Apr 19, 2021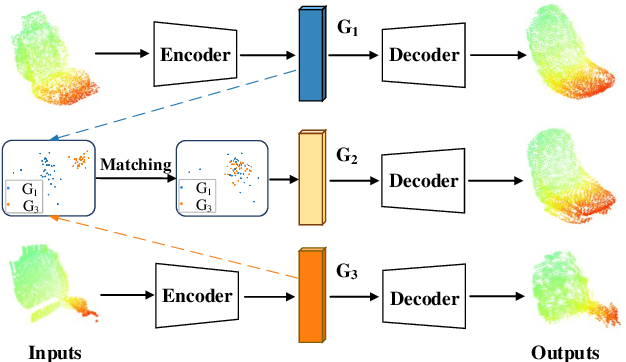

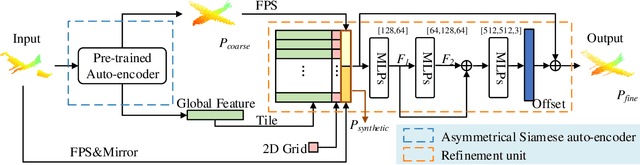
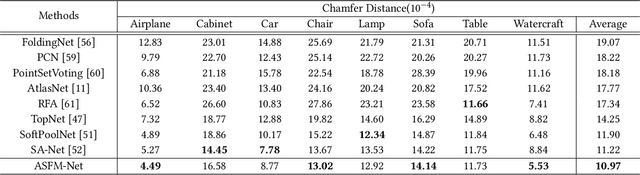
We tackle the problem of object completion from point clouds and propose a novel point cloud completion network using a feature matching strategy, termed as ASFM-Net. Specifically, the asymmetrical Siamese auto-encoder neural network is adopted to map the partial and complete input point cloud into a shared latent space, which can capture detailed shape prior. Then we design an iterative refinement unit to generate complete shapes with fine-grained details by integrating prior information. Experiments are conducted on the PCN dataset and the Completion3D benchmark, demonstrating the state-of-the-art performance of the proposed ASFM-Net. The codes and trained models will be open-sourced.
A Deep Neural Network Sentence Level Classification Method with Context Information
Aug 31, 2018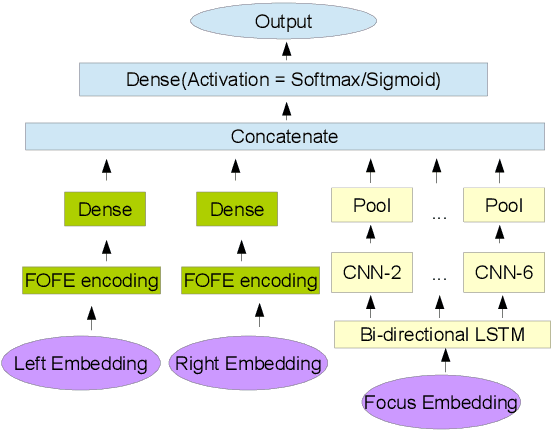
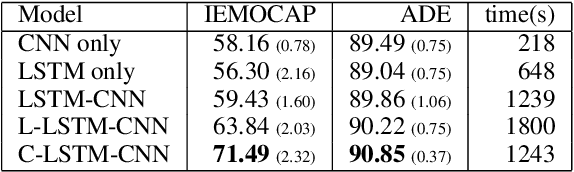

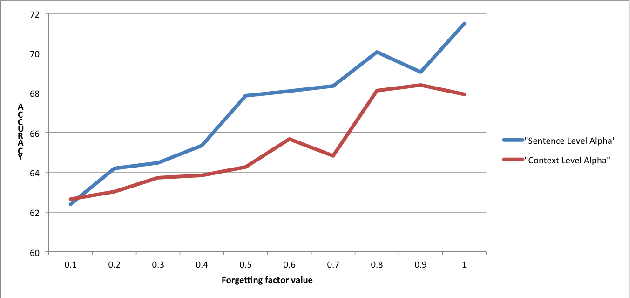
In the sentence classification task, context formed from sentences adjacent to the sentence being classified can provide important information for classification. This context is, however, often ignored. Where methods do make use of context, only small amounts are considered, making it difficult to scale. We present a new method for sentence classification, Context-LSTM-CNN, that makes use of potentially large contexts. The method also utilizes long-range dependencies within the sentence being classified, using an LSTM, and short-span features, using a stacked CNN. Our experiments demonstrate that this approach consistently improves over previous methods on two different datasets.
How to select and use tools? : Active Perception of Target Objects Using Multimodal Deep Learning
Jun 04, 2021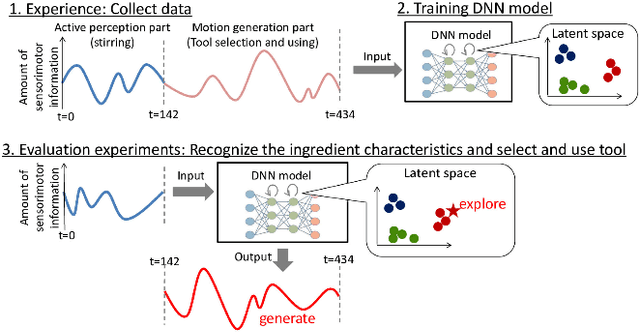
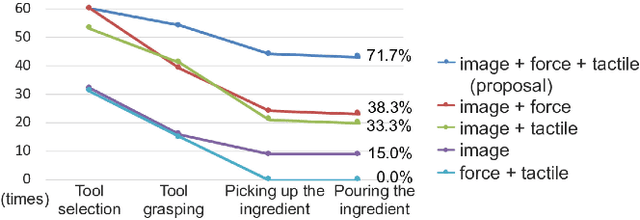
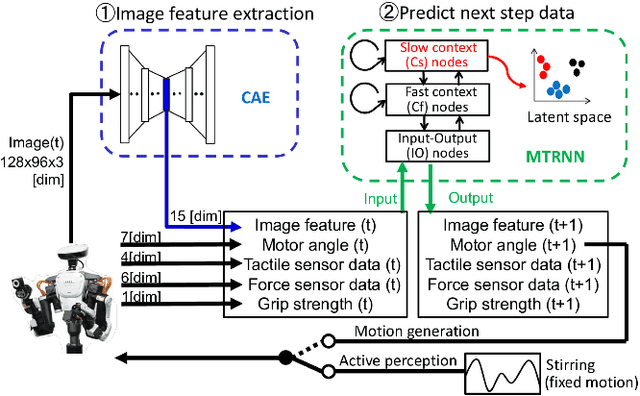

Selection of appropriate tools and use of them when performing daily tasks is a critical function for introducing robots for domestic applications. In previous studies, however, adaptability to target objects was limited, making it difficult to accordingly change tools and adjust actions. To manipulate various objects with tools, robots must both understand tool functions and recognize object characteristics to discern a tool-object-action relation. We focus on active perception using multimodal sensorimotor data while a robot interacts with objects, and allow the robot to recognize their extrinsic and intrinsic characteristics. We construct a deep neural networks (DNN) model that learns to recognize object characteristics, acquires tool-object-action relations, and generates motions for tool selection and handling. As an example tool-use situation, the robot performs an ingredients transfer task, using a turner or ladle to transfer an ingredient from a pot to a bowl. The results confirm that the robot recognizes object characteristics and servings even when the target ingredients are unknown. We also examine the contributions of images, force, and tactile data and show that learning a variety of multimodal information results in rich perception for tool use.
* Best Paper Award of Cognitive Robotics in ICRA2021 IEEE Robotics and Automation Letters 2021, Proceedings of the 2021 International Conference on Robotics and Automation (ICRA 2021), 2021