 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-Subject Domain Adaptation for Multi-Frame EEG Images
Jun 12, 2021
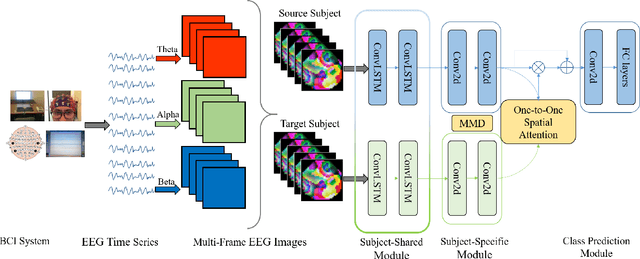

Working memory (WM) is a basic part of human cognition, which plays an important role in the study of human cognitive load. Among various brain imaging techniques, electroencephalography has shown its advantage on easy access and reliability. However, one of the critical challenges is that individual difference may cause the ineffective results, especially when the established model meets an unfamiliar subject. In this work, we propose a cross-subject deep adaptation model with spatial attention (CS-DASA) to generalize the workload classifications across subjects. First, we transform time-series EEG data into multi-frame EEG images incorporating more spatio-temporal information. First, the subject-shared module in CS-DASA receives multi-frame EEG image data from both source and target subjects and learns the common feature representations. Then, in subject-specific module, the maximum mean discrepancy is implemented to measure the domain distribution divergence in a reproducing kernel Hilbert space, which can add an effective penalty loss for domain adaptation. Additionally, the subject-to-subject spatial attention mechanism is employed to focus on the most discriminative spatial feature in EEG image data. Experiments conducted on a public WM EEG dataset containing 13 subjects show that the proposed model is capable of achieve better performance than existing state-of-the art methods.
Network Support for High-performance Distributed Machine Learning
Feb 05, 2021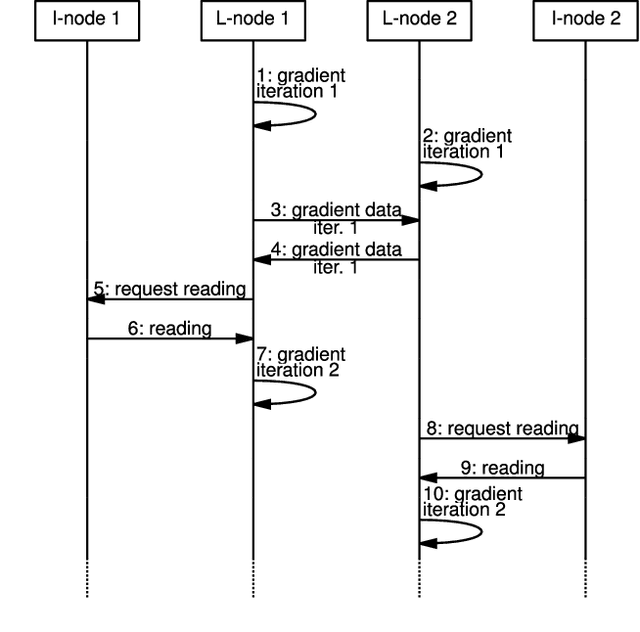

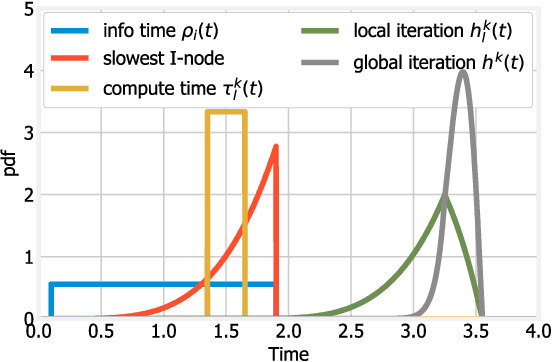
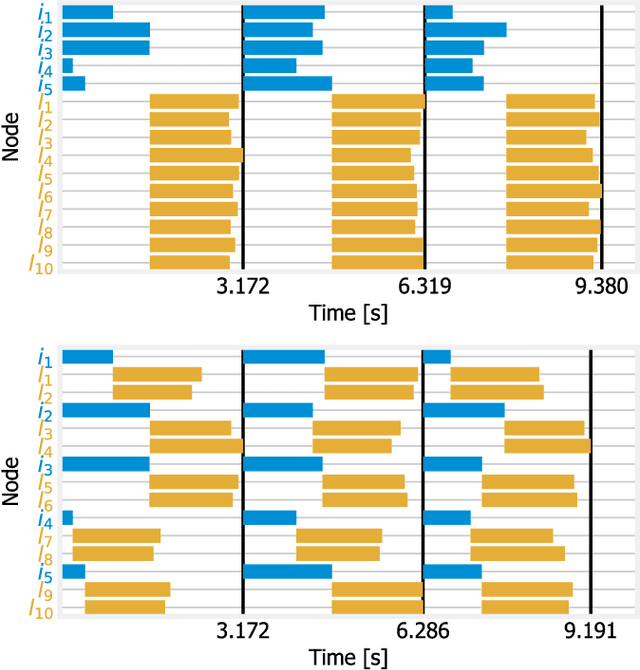
The traditional approach to distributed machine learning is to adapt learning algorithms to the network, e.g., reducing updates to curb overhead. Networks based on intelligent edge, instead, make it possible to follow the opposite approach, i.e., to define the logical network topology em around the learning task to perform, so as to meet the desired learning performance. In this paper, we propose a system model that captures such aspects in the context of supervised machine learning, accounting for both learning nodes (that perform computations) and information nodes (that provide data). We then formulate the problem of selecting (i) which learning and information nodes should cooperate to complete the learning task, and (ii) the number of iterations to perform, in order to minimize the learning cost while meeting the target prediction error and execution time. After proving important properties of the above problem, we devise an algorithm, named DoubleClimb, that can find a 1+1/|I|-competitive solution (with I being the set of information nodes), with cubic worst-case complexity. Our performance evaluation, leveraging a real-world network topology and considering both classification and regression tasks, also shows that DoubleClimb closely matches the optimum, outperforming state-of-the-art alternatives.
Dialogue History Matters! Personalized Response Selectionin Multi-turn Retrieval-based Chatbots
Mar 17, 2021
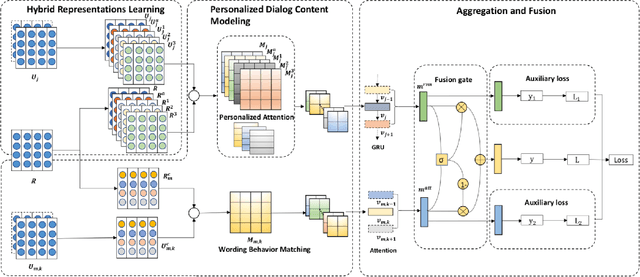
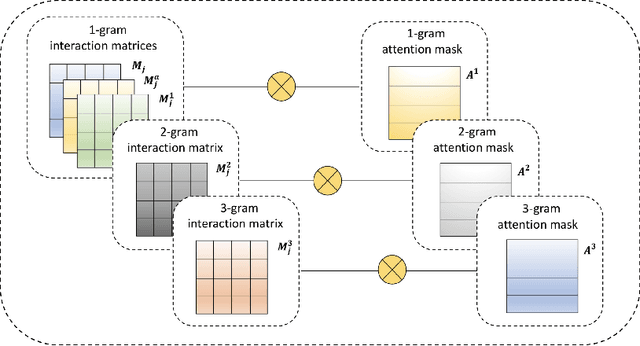
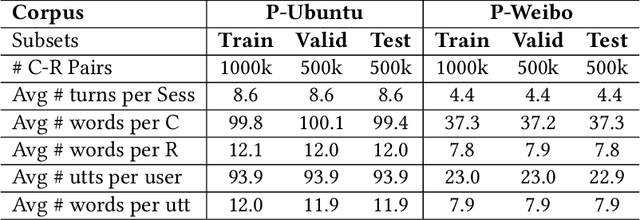
Existing multi-turn context-response matching methods mainly concentrate on obtaining multi-level and multi-dimension representations and better interactions between context utterances and response. However, in real-place conversation scenarios, whether a response candidate is suitable not only counts on the given dialogue context but also other backgrounds, e.g., wording habits, user-specific dialogue history content. To fill the gap between these up-to-date methods and the real-world applications, we incorporate user-specific dialogue history into the response selection and propose a personalized hybrid matching network (PHMN). Our contributions are two-fold: 1) our model extracts personalized wording behaviors from user-specific dialogue history as extra matching information; 2) we perform hybrid representation learning on context-response utterances and explicitly incorporate a customized attention mechanism to extract vital information from context-response interactions so as to improve the accuracy of matching. We evaluate our model on two large datasets with user identification, i.e., personalized Ubuntu dialogue Corpus (P-Ubuntu) and personalized Weibo dataset (P-Weibo). Experimental results confirm that our method significantly outperforms several strong models by combining personalized attention, wording behaviors, and hybrid representation learning.
Deep Fair Discriminative Clustering
May 28, 2021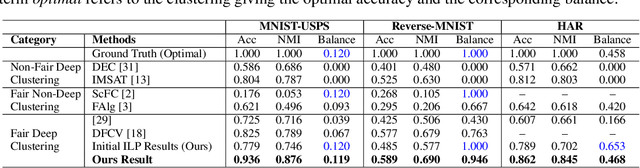

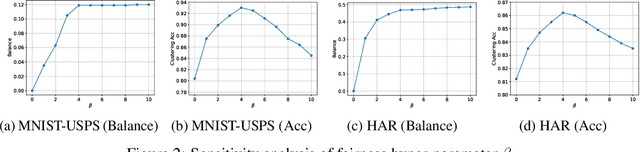
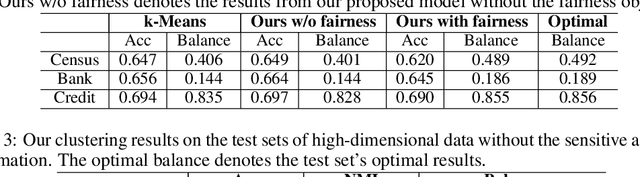
Deep clustering has the potential to learn a strong representation and hence better clustering performance compared to traditional clustering methods such as $k$-means and spectral clustering. However, this strong representation learning ability may make the clustering unfair by discovering surrogates for protected information which we empirically show in our experiments. In this work, we study a general notion of group-level fairness for both binary and multi-state protected status variables (PSVs). We begin by formulating the group-level fairness problem as an integer linear programming formulation whose totally unimodular constraint matrix means it can be efficiently solved via linear programming. We then show how to inject this solver into a discriminative deep clustering backbone and hence propose a refinement learning algorithm to combine the clustering goal with the fairness objective to learn fair clusters adaptively. Experimental results on real-world datasets demonstrate that our model consistently outperforms state-of-the-art fair clustering algorithms. Our framework shows promising results for novel clustering tasks including flexible fairness constraints, multi-state PSVs and predictive clustering.
RDA: Robust Domain Adaptation via Fourier Adversarial Attacking
Jun 05, 2021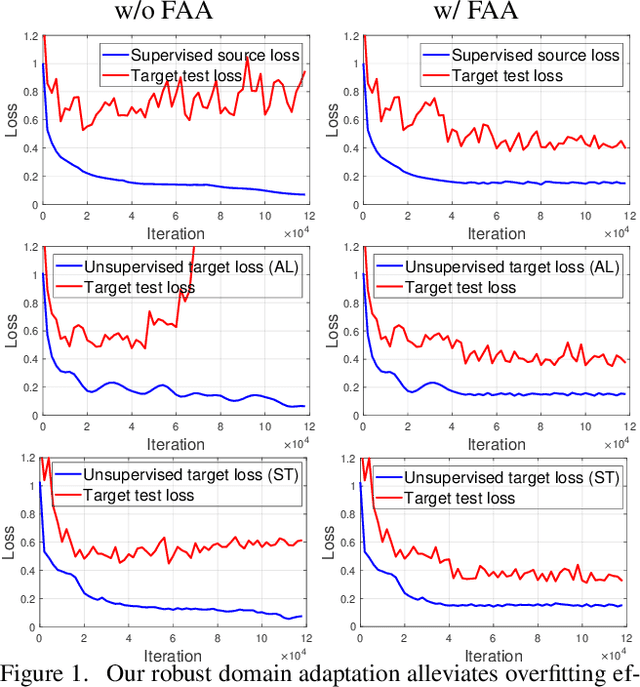
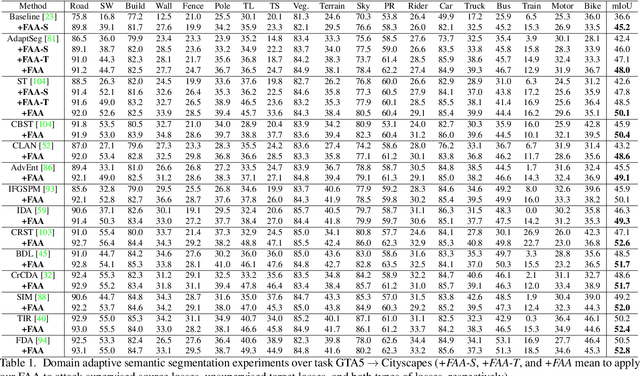
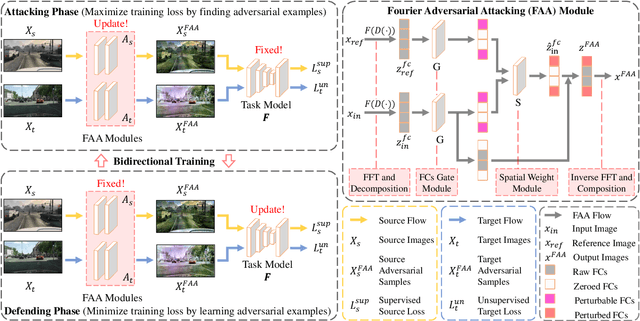
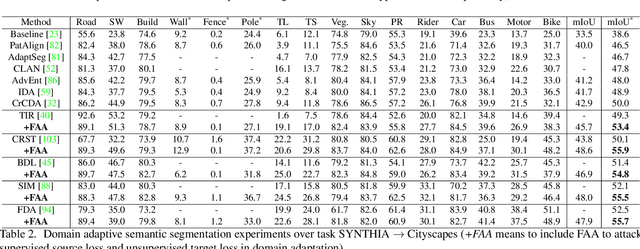
Unsupervised domain adaptation (UDA) involves a supervised loss in a labeled source domain and an unsupervised loss in an unlabeled target domain, which often faces more severe overfitting (than classical supervised learning) as the supervised source loss has clear domain gap and the unsupervised target loss is often noisy due to the lack of annotations. This paper presents RDA, a robust domain adaptation technique that introduces adversarial attacking to mitigate overfitting in UDA. We achieve robust domain adaptation by a novel Fourier adversarial attacking (FAA) method that allows large magnitude of perturbation noises but has minimal modification of image semantics, the former is critical to the effectiveness of its generated adversarial samples due to the existence of 'domain gaps'. Specifically, FAA decomposes images into multiple frequency components (FCs) and generates adversarial samples by just perturbating certain FCs that capture little semantic information. With FAA-generated samples, the training can continue the 'random walk' and drift into an area with a flat loss landscape, leading to more robust domain adaptation. Extensive experiments over multiple domain adaptation tasks show that RDA can work with different computer vision tasks with superior performance.
CREAD: Combined Resolution of Ellipses and Anaphora in Dialogues
May 20, 2021
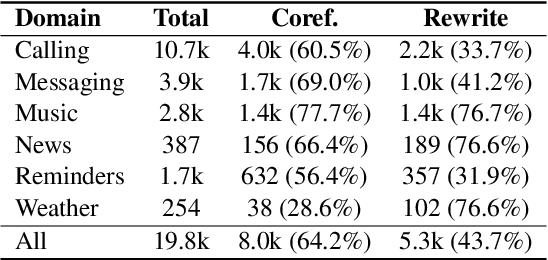

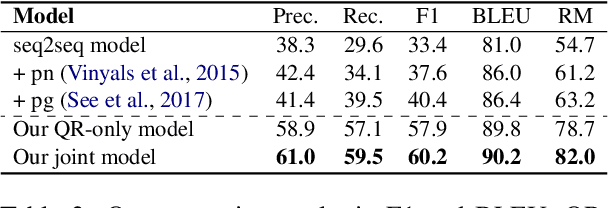
Anaphora and ellipses are two common phenomena in dialogues. Without resolving referring expressions and information omission, dialogue systems may fail to generate consistent and coherent responses. Traditionally, anaphora is resolved by coreference resolution and ellipses by query rewrite. In this work, we propose a novel joint learning framework of modeling coreference resolution and query rewriting for complex, multi-turn dialogue understanding. Given an ongoing dialogue between a user and a dialogue assistant, for the user query, our joint learning model first predicts coreference links between the query and the dialogue context, and then generates a self-contained rewritten user query. To evaluate our model, we annotate a dialogue based coreference resolution dataset, MuDoCo, with rewritten queries. Results show that the performance of query rewrite can be substantially boosted (+2.3% F1) with the aid of coreference modeling. Furthermore, our joint model outperforms the state-of-the-art coreference resolution model (+2% F1) on this dataset.
Learning Multiple Stock Trading Patterns with Temporal Routing Adaptor and Optimal Transport
Jun 24, 2021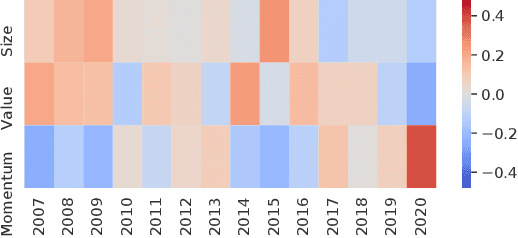
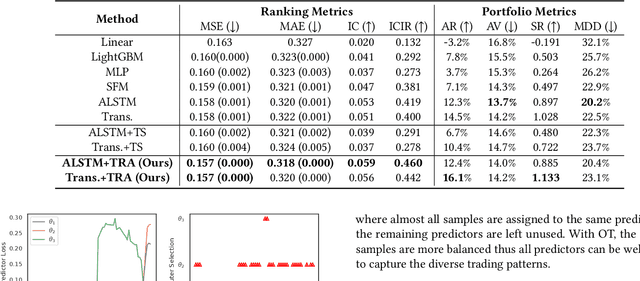
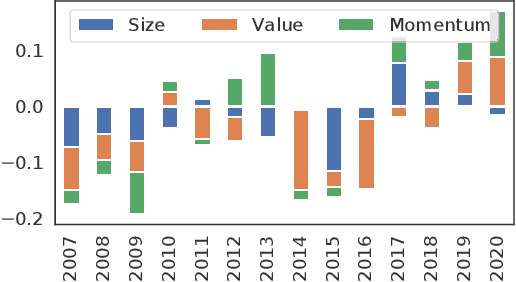
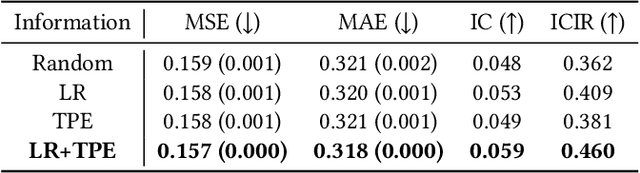
Successful quantitative investment usually relies on precise predictions of the future movement of the stock price. Recently, machine learning based solutions have shown their capacity to give more accurate stock prediction and become indispensable components in modern quantitative investment systems. However, the i.i.d. assumption behind existing methods is inconsistent with the existence of diverse trading patterns in the stock market, which inevitably limits their ability to achieve better stock prediction performance. In this paper, we propose a novel architecture, Temporal Routing Adaptor (TRA), to empower existing stock prediction models with the ability to model multiple stock trading patterns. Essentially, TRA is a lightweight module that consists of a set of independent predictors for learning multiple patterns as well as a router to dispatch samples to different predictors. Nevertheless, the lack of explicit pattern identifiers makes it quite challenging to train an effective TRA-based model. To tackle this challenge, we further design a learning algorithm based on Optimal Transport (OT) to obtain the optimal sample to predictor assignment and effectively optimize the router with such assignment through an auxiliary loss term. Experiments on the real-world stock ranking task show that compared to the state-of-the-art baselines, e.g., Attention LSTM and Transformer, the proposed method can improve information coefficient (IC) from 0.053 to 0.059 and 0.051 to 0.056 respectively. Our dataset and code used in this work are publicly available: https://github.com/microsoft/qlib.
Navigating to the Best Policy in Markov Decision Processes
Jun 05, 2021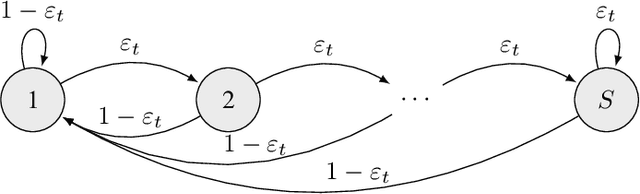

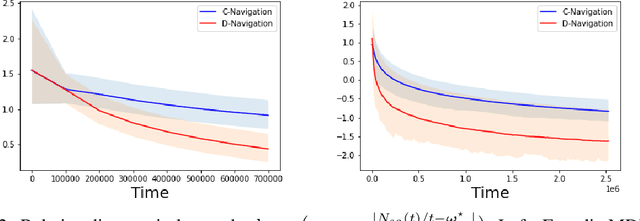
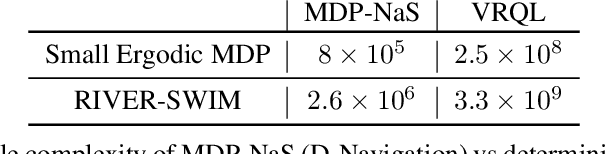
We investigate the classical active pure exploration problem in Markov Decision Processes, where the agent sequentially selects actions and, from the resulting system trajectory, aims at identifying the best policy as fast as possible. We propose an information-theoretic lower bound on the average number of steps required before a correct answer can be given with probability at least $1-\delta$. This lower bound involves a non-convex optimization problem, for which we propose a convex relaxation. We further provide an algorithm whose sample complexity matches the relaxed lower bound up to a factor $2$. This algorithm addresses general communicating MDPs; we propose a variant with reduced exploration rate (and hence faster convergence) under an additional ergodicity assumption. This work extends previous results relative to the \emph{generative setting}~\cite{marjani2020adaptive}, where the agent could at each step observe the random outcome of any (state, action) pair. In contrast, we show here how to deal with the \emph{navigation constraints}. Our analysis relies on an ergodic theorem for non-homogeneous Markov chains which we consider of wide interest in the analysis of Markov Decision Processes.
Reducing false-positive biopsies with deep neural networks that utilize local and global information in screening mammograms
Sep 19, 2020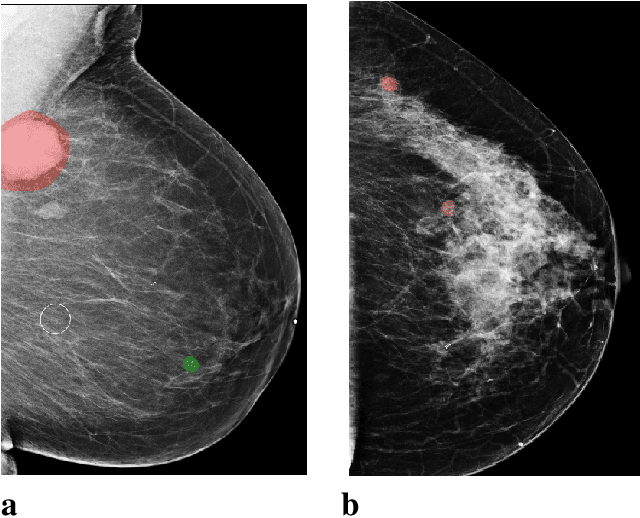
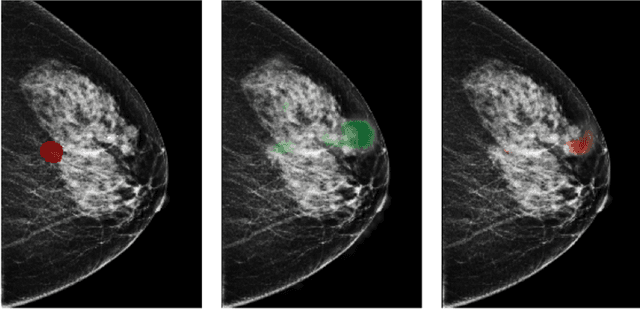
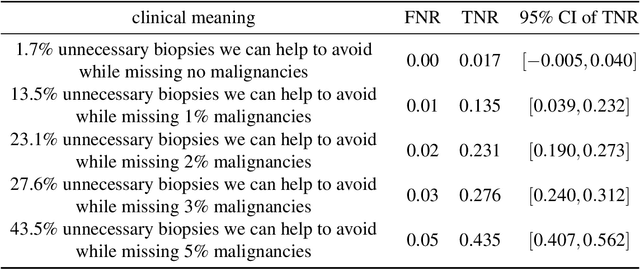
Breast cancer is the most common cancer in women, and hundreds of thousands of unnecessary biopsies are done around the world at a tremendous cost. It is crucial to reduce the rate of biopsies that turn out to be benign tissue. In this study, we build deep neural networks (DNNs) to classify biopsied lesions as being either malignant or benign, with the goal of using these networks as second readers serving radiologists to further reduce the number of false positive findings. We enhance the performance of DNNs that are trained to learn from small image patches by integrating global context provided in the form of saliency maps learned from the entire image into their reasoning, similar to how radiologists consider global context when evaluating areas of interest. Our experiments are conducted on a dataset of 229,426 screening mammography exams from 141,473 patients. We achieve an AUC of 0.8 on a test set consisting of 464 benign and 136 malignant lesions.
SemEval-2021 Task 9: Fact Verification and Evidence Finding for Tabular Data in Scientific Documents (SEM-TAB-FACTS)
May 28, 2021
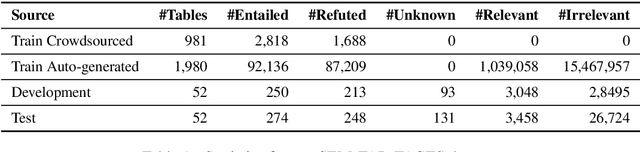
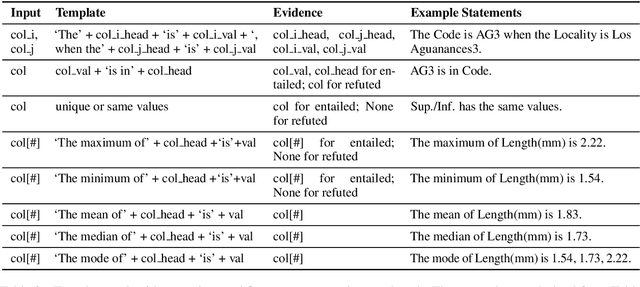
Understanding tables is an important and relevant task that involves understanding table structure as well as being able to compare and contrast information within cells. In this paper, we address this challenge by presenting a new dataset and tasks that addresses this goal in a shared task in SemEval 2020 Task 9: Fact Verification and Evidence Finding for Tabular Data in Scientific Documents (SEM-TAB-FACTS). Our dataset contains 981 manually-generated tables and an auto-generated dataset of 1980 tables providing over 180K statement and over 16M evidence annotations. SEM-TAB-FACTS featured two sub-tasks. In sub-task A, the goal was to determine if a statement is supported, refuted or unknown in relation to a table. In sub-task B, the focus was on identifying the specific cells of a table that provide evidence for the statement. 69 teams signed up to participate in the task with 19 successful submissions to subtask A and 12 successful submissions to subtask B. We present our results and main findings from the competition.