 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Self-Taught Faithfulness Evaluators
Jul 28, 2025The growing use of large language models (LLMs) has increased the need for automatic evaluation systems, particularly to address the challenge of information hallucination. Although existing faithfulness evaluation approaches have shown promise, they are predominantly English-focused and often require expensive human-labeled training data for fine-tuning specialized models. As LLMs see increased adoption in multilingual contexts, there is a need for accurate faithfulness evaluators that can operate across languages without extensive labeled data. This paper presents Self-Taught Evaluators for Multilingual Faithfulness, a framework that learns exclusively from synthetic multilingual summarization data while leveraging cross-lingual transfer learning. Through experiments comparing language-specific and mixed-language fine-tuning approaches, we demonstrate a consistent relationship between an LLM's general language capabilities and its performance in language-specific evaluation tasks. Our framework shows improvements over existing baselines, including state-of-the-art English evaluators and machine translation-based approaches.
Differentially Private Best-Arm Identification
Jun 10, 2024



Best Arm Identification (BAI) problems are progressively used for data-sensitive applications, such as designing adaptive clinical trials, tuning hyper-parameters, and conducting user studies. Motivated by the data privacy concerns invoked by these applications, we study the problem of BAI with fixed confidence in both the local and central models, i.e. $\epsilon$-local and $\epsilon$-global Differential Privacy (DP). First, to quantify the cost of privacy, we derive lower bounds on the sample complexity of any $\delta$-correct BAI algorithm satisfying $\epsilon$-global DP or $\epsilon$-local DP. Our lower bounds suggest the existence of two privacy regimes. In the high-privacy regime, the hardness depends on a coupled effect of privacy and novel information-theoretic quantities involving the Total Variation. In the low-privacy regime, the lower bounds reduce to the non-private lower bounds. We propose $\epsilon$-local DP and $\epsilon$-global DP variants of a Top Two algorithm, namely CTB-TT and AdaP-TT*, respectively. For $\epsilon$-local DP, CTB-TT is asymptotically optimal by plugging in a private estimator of the means based on Randomised Response. For $\epsilon$-global DP, our private estimator of the mean runs in arm-dependent adaptive episodes and adds Laplace noise to ensure a good privacy-utility trade-off. By adapting the transportation costs, the expected sample complexity of AdaP-TT* reaches the asymptotic lower bound up to multiplicative constants.
On the Complexity of Differentially Private Best-Arm Identification with Fixed Confidence
Sep 05, 2023Best Arm Identification (BAI) problems are progressively used for data-sensitive applications, such as designing adaptive clinical trials, tuning hyper-parameters, and conducting user studies to name a few. Motivated by the data privacy concerns invoked by these applications, we study the problem of BAI with fixed confidence under $\epsilon$-global Differential Privacy (DP). First, to quantify the cost of privacy, we derive a lower bound on the sample complexity of any $\delta$-correct BAI algorithm satisfying $\epsilon$-global DP. Our lower bound suggests the existence of two privacy regimes depending on the privacy budget $\epsilon$. In the high-privacy regime (small $\epsilon$), the hardness depends on a coupled effect of privacy and a novel information-theoretic quantity, called the Total Variation Characteristic Time. In the low-privacy regime (large $\epsilon$), the sample complexity lower bound reduces to the classical non-private lower bound. Second, we propose AdaP-TT, an $\epsilon$-global DP variant of the Top Two algorithm. AdaP-TT runs in arm-dependent adaptive episodes and adds Laplace noise to ensure a good privacy-utility trade-off. We derive an asymptotic upper bound on the sample complexity of AdaP-TT that matches with the lower bound up to multiplicative constants in the high-privacy regime. Finally, we provide an experimental analysis of AdaP-TT that validates our theoretical results.
On the complexity of All $\varepsilon$-Best Arms Identification
Feb 13, 2022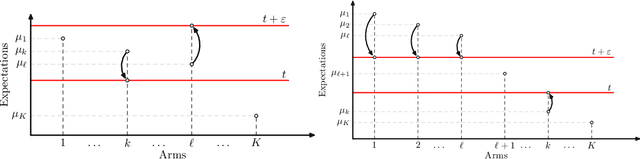
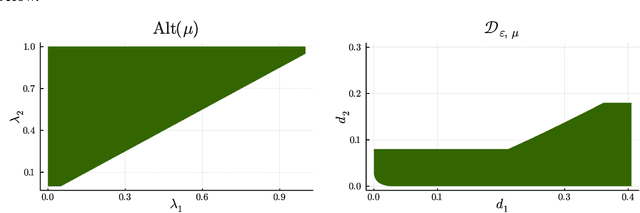
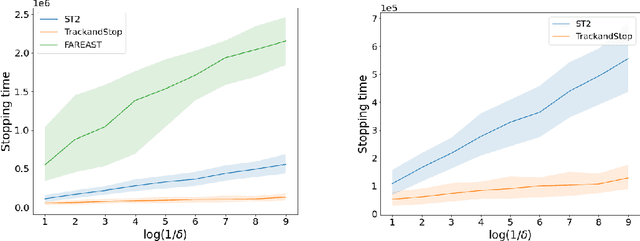
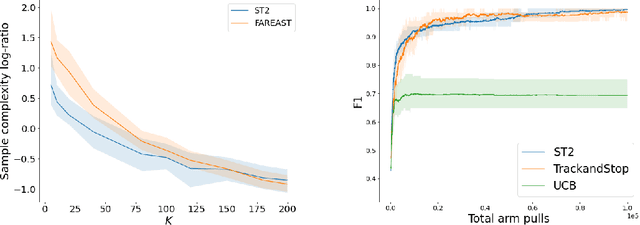
We consider the problem introduced by \cite{Mason2020} of identifying all the $\varepsilon$-optimal arms in a finite stochastic multi-armed bandit with Gaussian rewards. In the fixed confidence setting, we give a lower bound on the number of samples required by any algorithm that returns the set of $\varepsilon$-good arms with a failure probability less than some risk level $\delta$. This bound writes as $T_{\varepsilon}^*(\mu)\log(1/\delta)$, where $T_{\varepsilon}^*(\mu)$ is a characteristic time that depends on the vector of mean rewards $\mu$ and the accuracy parameter $\varepsilon$. We also provide an efficient numerical method to solve the convex max-min program that defines the characteristic time. Our method is based on a complete characterization of the alternative bandit instances that the optimal sampling strategy needs to rule out, thus making our bound tighter than the one provided by \cite{Mason2020}. Using this method, we propose a Track-and-Stop algorithm that identifies the set of $\varepsilon$-good arms w.h.p and enjoys asymptotic optimality (when $\delta$ goes to zero) in terms of the expected sample complexity. Finally, using numerical simulations, we demonstrate our algorithm's advantage over state-of-the-art methods, even for moderate values of the risk parameter.
Navigating to the Best Policy in Markov Decision Processes
Jun 05, 2021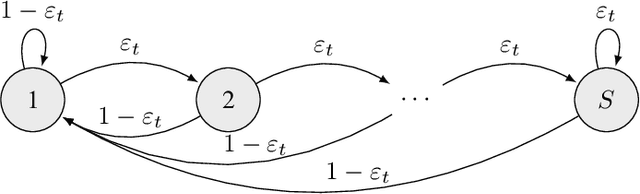

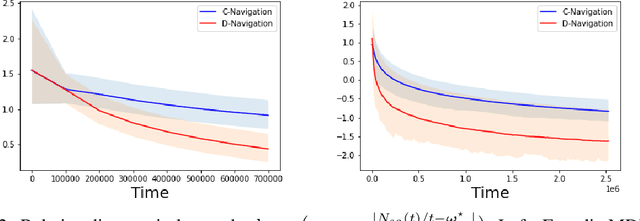
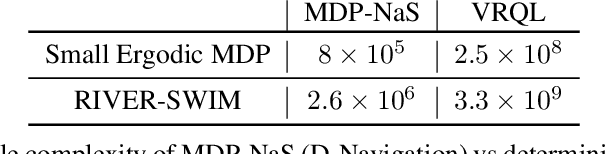
We investigate the classical active pure exploration problem in Markov Decision Processes, where the agent sequentially selects actions and, from the resulting system trajectory, aims at identifying the best policy as fast as possible. We propose an information-theoretic lower bound on the average number of steps required before a correct answer can be given with probability at least $1-\delta$. This lower bound involves a non-convex optimization problem, for which we propose a convex relaxation. We further provide an algorithm whose sample complexity matches the relaxed lower bound up to a factor $2$. This algorithm addresses general communicating MDPs; we propose a variant with reduced exploration rate (and hence faster convergence) under an additional ergodicity assumption. This work extends previous results relative to the \emph{generative setting}~\cite{marjani2020adaptive}, where the agent could at each step observe the random outcome of any (state, action) pair. In contrast, we show here how to deal with the \emph{navigation constraints}. Our analysis relies on an ergodic theorem for non-homogeneous Markov chains which we consider of wide interest in the analysis of Markov Decision Processes.
Adaptive Sampling for Best Policy Identification in Markov Decision Processes
Oct 16, 2020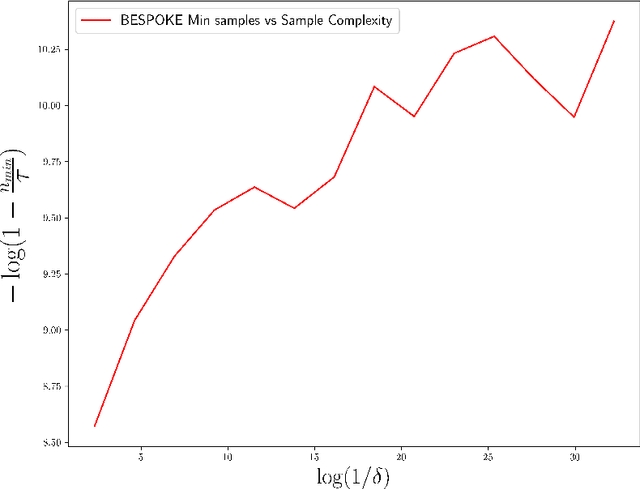
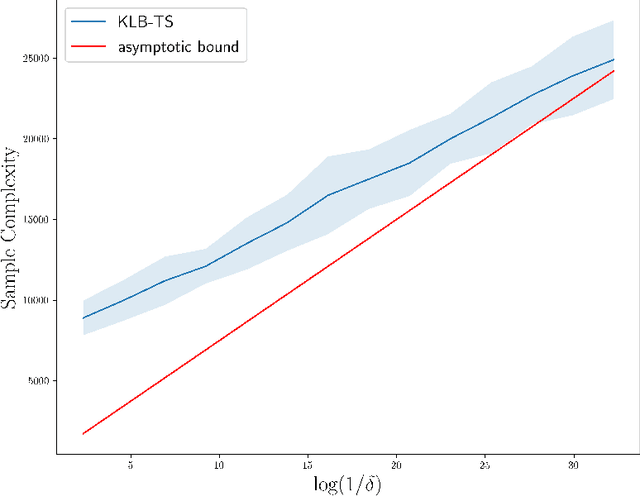
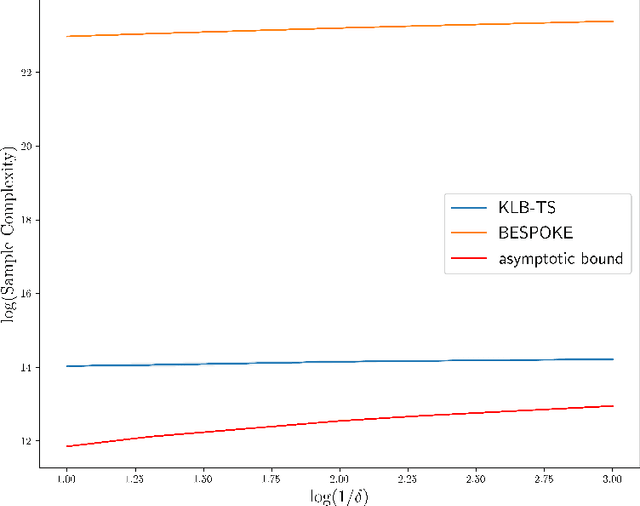
We investigate the problem of best-policy identification in discounted Markov Decision Processes (MDPs) when the learner has access to a generative model. The objective is to devise a learning algorithm returning the best policy as early as possible. We first derive a problem-specific lower bound of the sample complexity satisfied by any learning algorithm. This lower bound corresponds to an optimal sample allocation that solves a non-convex program, and hence, is hard to exploit in the design of efficient algorithms. We then provide a simple and tight upper bound of the sample complexity lower bound, whose corresponding nearly-optimal sample allocation becomes explicit. The upper bound depends on specific functionals of the MDP such as the sub-optimality gaps and the variance of the next-state value function, and thus really captures the hardness of the MDP. Finally, we devise KLB-TS (KL Ball Track-and-Stop), an algorithm tracking this nearly-optimal allocation, and provide asymptotic guarantees for its sample complexity (both almost surely and in expectation). The advantages of KLB-TS against state-of-the-art algorithms are discussed and illustrated numerically.