 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Brain over Brawn -- Using a Stereo Camera to Detect, Track and Intercept a Faster UAV by Reconstructing Its Trajectory
Jul 02, 2021
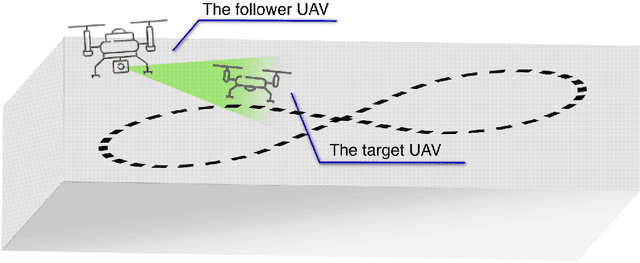
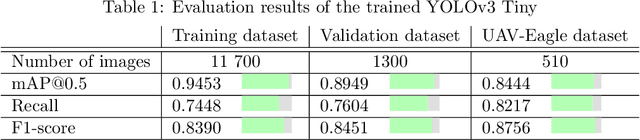

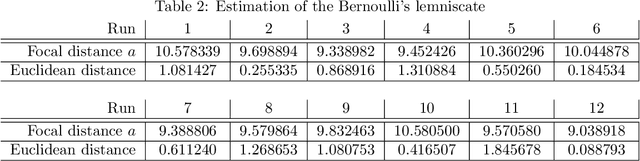
The work presented in this paper demonstrates our approach to intercepting a faster intruder UAV, inspired by the MBZIRC2020 Challenge 1. By leveraging the knowledge of the shape of the intruder's trajectory we are able to calculate the interception point. Target tracking is based on image processing by a YOLOv3 Tiny convolutional neural network, combined with depth calculation using a gimbal-mounted ZED Mini stereo camera. We use RGB and depth data from ZED Mini to extract the 3D position of the target, for which we devise a histogram-of-depth based processing to reduce noise. Obtained 3D measurements of target's position are used to calculate the position, the orientation and the size of a figure-eight shaped trajectory, which we approximate using lemniscate of Bernoulli. Once the approximation is deemed sufficiently precise, measured by Hausdorff distance between measurements and the approximation, an interception point is calculated to position the intercepting UAV right on the path of the target. The proposed method, which has been significantly improved based on the experience gathered during the MBZIRC competition, has been validated in simulation and through field experiments. The results confirmed that an efficient visual perception module which extracts information related to the motion of the target UAV as a basis for the interception, has been developed. The system is able to track and intercept the target which is 30% faster than the interceptor in majority of simulation experiments. Tests in the unstructured environment yielded 9 out of 12 successful results.
A Little Pretraining Goes a Long Way: A Case Study on Dependency Parsing Task for Low-resource Morphologically Rich Languages
Feb 12, 2021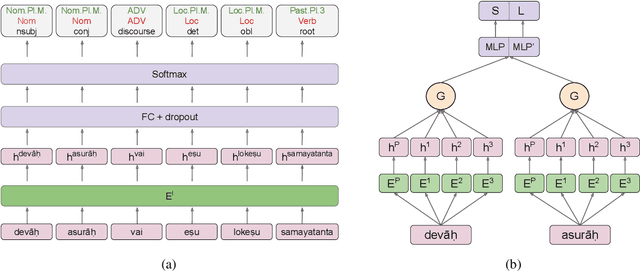
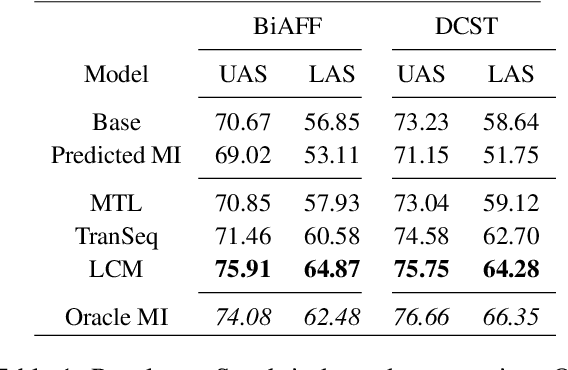
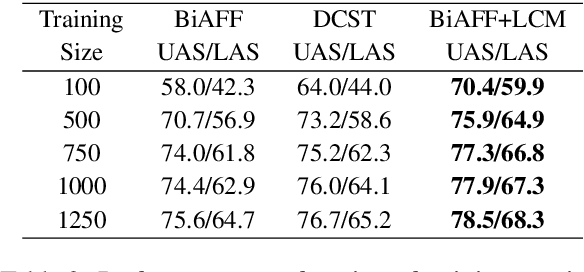
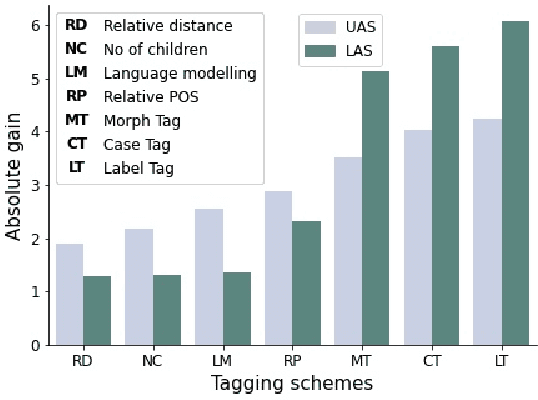
Neural dependency parsing has achieved remarkable performance for many domains and languages. The bottleneck of massive labeled data limits the effectiveness of these approaches for low resource languages. In this work, we focus on dependency parsing for morphological rich languages (MRLs) in a low-resource setting. Although morphological information is essential for the dependency parsing task, the morphological disambiguation and lack of powerful analyzers pose challenges to get this information for MRLs. To address these challenges, we propose simple auxiliary tasks for pretraining. We perform experiments on 10 MRLs in low-resource settings to measure the efficacy of our proposed pretraining method and observe an average absolute gain of 2 points (UAS) and 3.6 points (LAS). Code and data available at: https://github.com/jivnesh/LCM
Hierarchical Text Classification of Urdu News using Deep Neural Network
Jul 07, 2021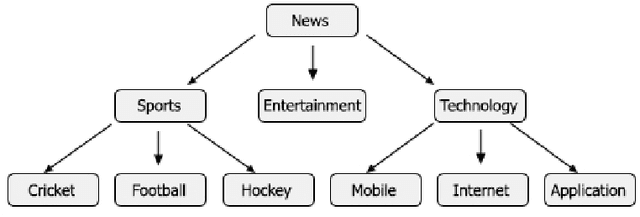
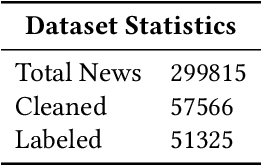
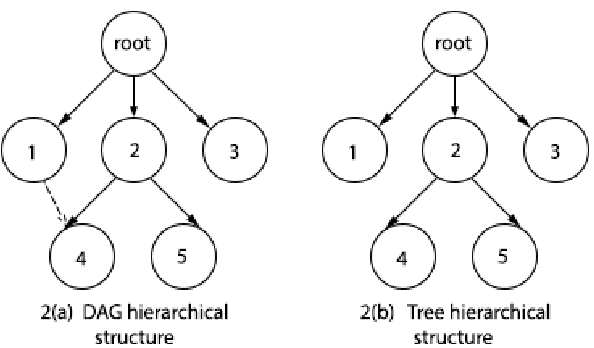
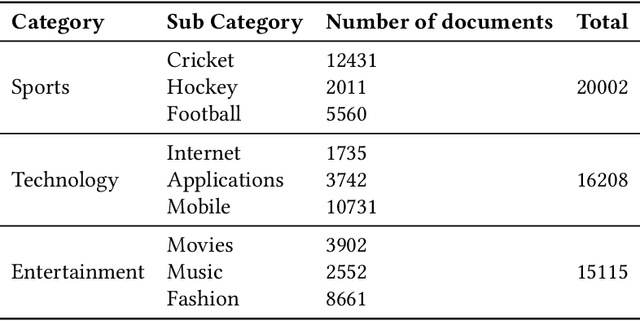
Digital text is increasing day by day on the internet. It is very challenging to classify a large and heterogeneous collection of data, which require improved information processing methods to organize text. To classify large size of corpus, one common approach is to use hierarchical text classification, which aims to classify textual data in a hierarchical structure. Several approaches have been proposed to tackle classification of text but most of the research has been done on English language. This paper proposes a deep learning model for hierarchical text classification of news in Urdu language - consisting of 51,325 sentences from 8 online news websites belonging to the following genres: Sports; Technology; and Entertainment. The objectives of this paper are twofold: (1) to develop a large human-annotated dataset of news in Urdu language for hierarchical text classification; and (2) to classify Urdu news hierarchically using our proposed model based on LSTM mechanism named as Hierarchical Multi-layer LSTMs (HMLSTM). Our model consists of two modules: Text Representing Layer, for obtaining text representation in which we use Word2vec embedding to transform the words to vector and Urdu Hierarchical LSTM Layer (UHLSTML) an end-to-end fully connected deep LSTMs network to perform automatic feature learning, we train one LSTM layer for each level of the class hierarchy. We have performed extensive experiments on our self created dataset named as Urdu News Dataset for Hierarchical Text Classification (UNDHTC). The result shows that our proposed method is very effective for hierarchical text classification and it outperforms baseline methods significantly and also achieved good results as compare to deep neural model.
ACNet: Mask-Aware Attention with Dynamic Context Enhancement for Robust Acne Detection
May 31, 2021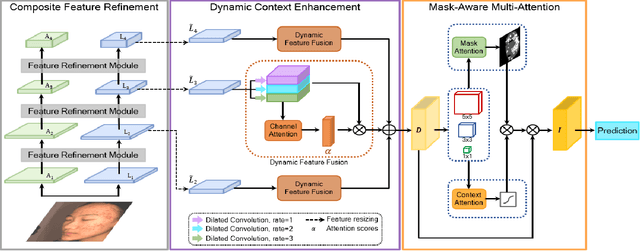
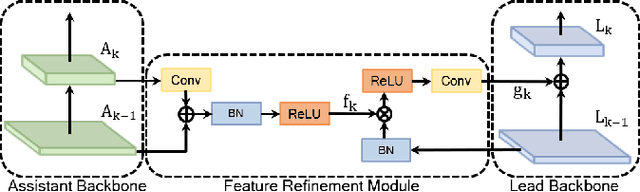
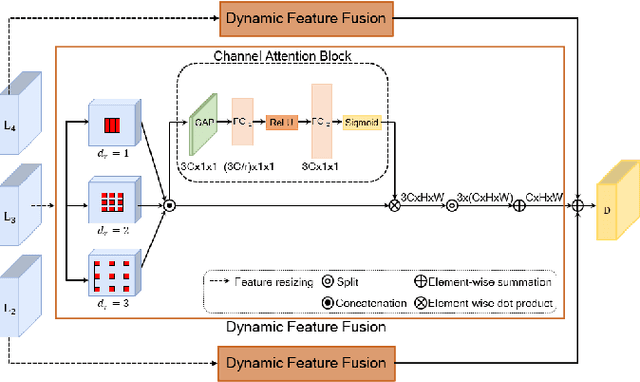
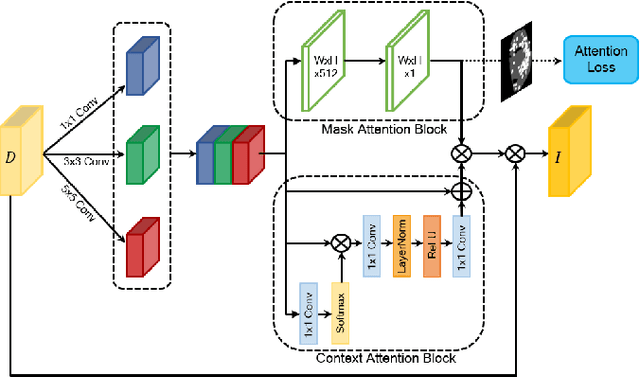
Computer-aided diagnosis has recently received attention for its advantage of low cost and time efficiency. Although deep learning played a major role in the recent success of acne detection, there are still several challenges such as color shift by inconsistent illumination, variation in scales, and high density distribution. To address these problems, we propose an acne detection network which consists of three components, specifically: Composite Feature Refinement, Dynamic Context Enhancement, and Mask-Aware Multi-Attention. First, Composite Feature Refinement integrates semantic information and fine details to enrich feature representation, which mitigates the adverse impact of imbalanced illumination. Then, Dynamic Context Enhancement controls different receptive fields of multi-scale features for context enhancement to handle scale variation. Finally, Mask-Aware Multi-Attention detects densely arranged and small acne by suppressing uninformative regions and highlighting probable acne regions. Experiments are performed on acne image dataset ACNE04 and natural image dataset PASCAL VOC 2007. We demonstrate how our method achieves the state-of-the-art result on ACNE04 and competitive performance with previous state-of-the-art methods on the PASCAL VOC 2007.
Convergence and Alignment of Gradient Descent with Random Back Propagation Weights
Jun 14, 2021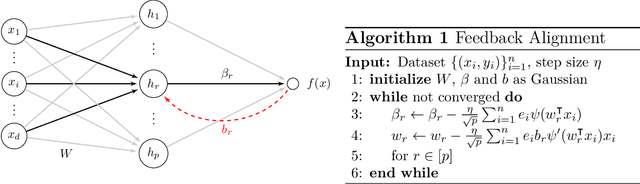
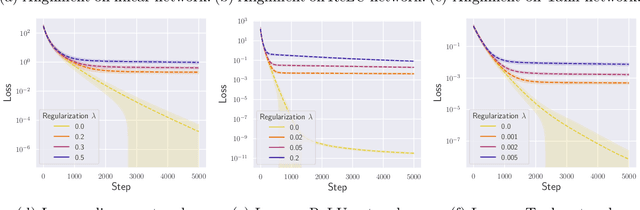
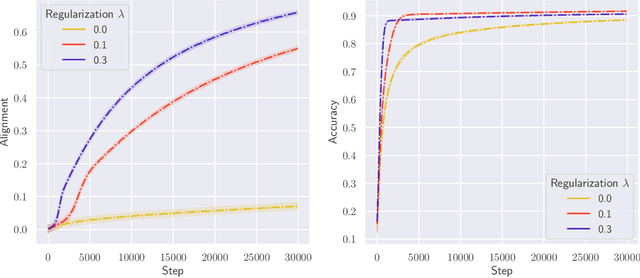
Stochastic gradient descent with backpropagation is the workhorse of artificial neural networks. It has long been recognized that backpropagation fails to be a biologically plausible algorithm. Fundamentally, it is a non-local procedure -- updating one neuron's synaptic weights requires knowledge of synaptic weights or receptive fields of downstream neurons. This limits the use of artificial neural networks as a tool for understanding the biological principles of information processing in the brain. Lillicrap et al. (2016) propose a more biologically plausible "feedback alignment" algorithm that uses random and fixed backpropagation weights, and show promising simulations. In this paper we study the mathematical properties of the feedback alignment procedure by analyzing convergence and alignment for two-layer networks under squared error loss. In the overparameterized setting, we prove that the error converges to zero exponentially fast, and also that regularization is necessary in order for the parameters to become aligned with the random backpropagation weights. Simulations are given that are consistent with this analysis and suggest further generalizations. These results contribute to our understanding of how biologically plausible algorithms might carry out weight learning in a manner different from Hebbian learning, with performance that is comparable with the full non-local backpropagation algorithm.
3D Object Detection for Autonomous Driving: A Survey
Jun 21, 2021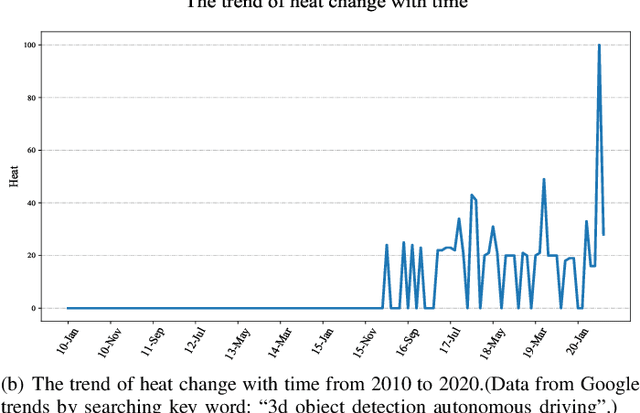
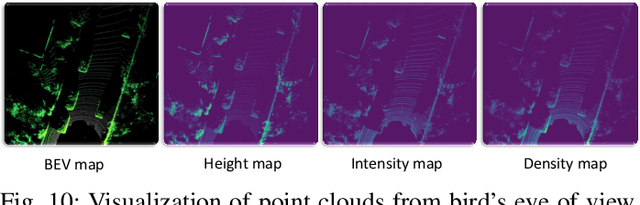
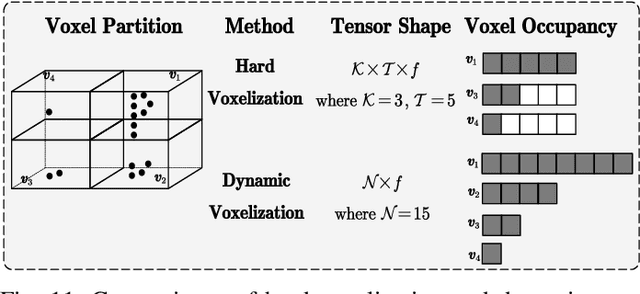
Autonomous driving is regarded as one of the most promising remedies to shield human beings from severe crashes. To this end, 3D object detection serves as the core basis of such perception system especially for the sake of path planning, motion prediction, collision avoidance, etc. Generally, stereo or monocular images with corresponding 3D point clouds are already standard layout for 3D object detection, out of which point clouds are increasingly prevalent with accurate depth information being provided. Despite existing efforts, 3D object detection on point clouds is still in its infancy due to high sparseness and irregularity of point clouds by nature, misalignment view between camera view and LiDAR bird's eye of view for modality synergies, occlusions and scale variations at long distances, etc. Recently, profound progress has been made in 3D object detection, with a large body of literature being investigated to address this vision task. As such, we present a comprehensive review of the latest progress in this field covering all the main topics including sensors, fundamentals, and the recent state-of-the-art detection methods with their pros and cons. Furthermore, we introduce metrics and provide quantitative comparisons on popular public datasets. The avenues for future work are going to be judiciously identified after an in-deep analysis of the surveyed works. Finally, we conclude this paper.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021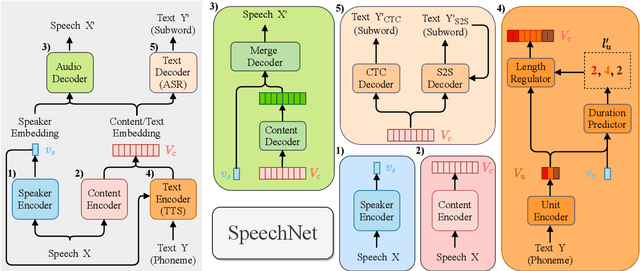
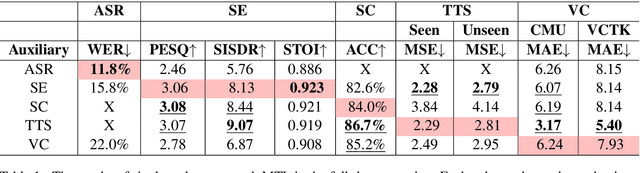
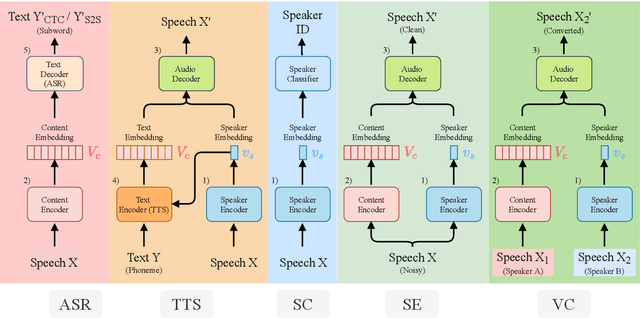
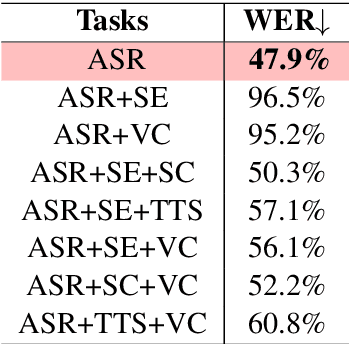
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
Chow-Liu++: Optimal Prediction-Centric Learning of Tree Ising Models
Jun 07, 2021
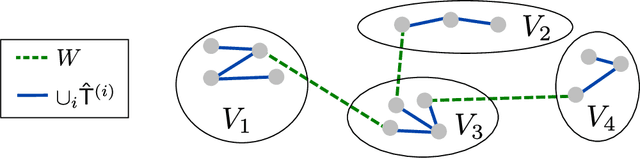
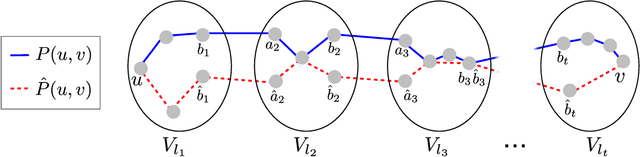
We consider the problem of learning a tree-structured Ising model from data, such that subsequent predictions computed using the model are accurate. Concretely, we aim to learn a model such that posteriors $P(X_i|X_S)$ for small sets of variables $S$ are accurate. Since its introduction more than 50 years ago, the Chow-Liu algorithm, which efficiently computes the maximum likelihood tree, has been the benchmark algorithm for learning tree-structured graphical models. A bound on the sample complexity of the Chow-Liu algorithm with respect to the prediction-centric local total variation loss was shown in [BK19]. While those results demonstrated that it is possible to learn a useful model even when recovering the true underlying graph is impossible, their bound depends on the maximum strength of interactions and thus does not achieve the information-theoretic optimum. In this paper, we introduce a new algorithm that carefully combines elements of the Chow-Liu algorithm with tree metric reconstruction methods to efficiently and optimally learn tree Ising models under a prediction-centric loss. Our algorithm is robust to model misspecification and adversarial corruptions. In contrast, we show that the celebrated Chow-Liu algorithm can be arbitrarily suboptimal.
Bounded logit attention: Learning to explain image classifiers
May 31, 2021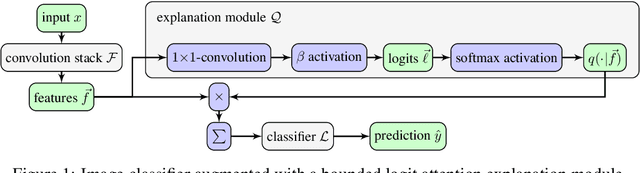
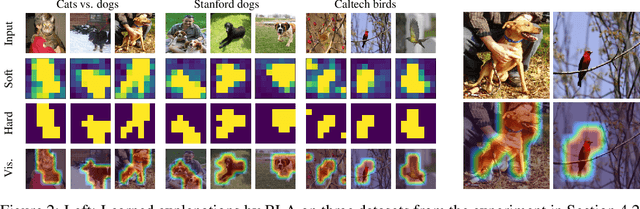
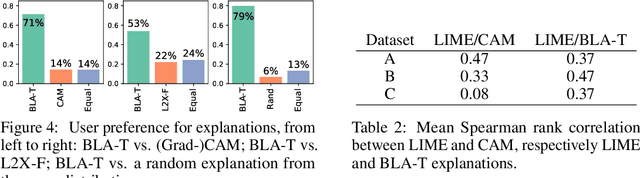
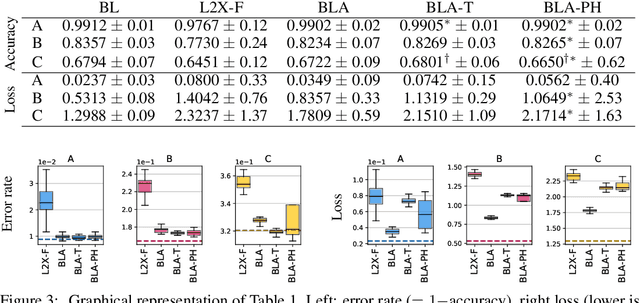
Explainable artificial intelligence is the attempt to elucidate the workings of systems too complex to be directly accessible to human cognition through suitable side-information referred to as "explanations". We present a trainable explanation module for convolutional image classifiers we call bounded logit attention (BLA). The BLA module learns to select a subset of the convolutional feature map for each input instance, which then serves as an explanation for the classifier's prediction. BLA overcomes several limitations of the instancewise feature selection method "learning to explain" (L2X) introduced by Chen et al. (2018): 1) BLA scales to real-world sized image classification problems, and 2) BLA offers a canonical way to learn explanations of variable size. Due to its modularity BLA lends itself to transfer learning setups and can also be employed as a post-hoc add-on to trained classifiers. Beyond explainability, BLA may serve as a general purpose method for differentiable approximation of subset selection. In a user study we find that BLA explanations are preferred over explanations generated by the popular (Grad-)CAM method.
Do End-to-End Speech Recognition Models Care About Context?
Feb 17, 2021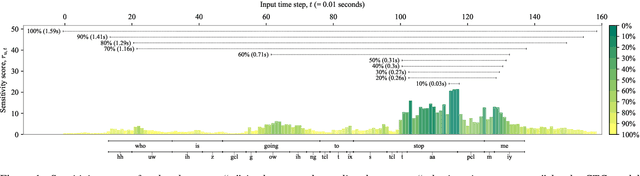
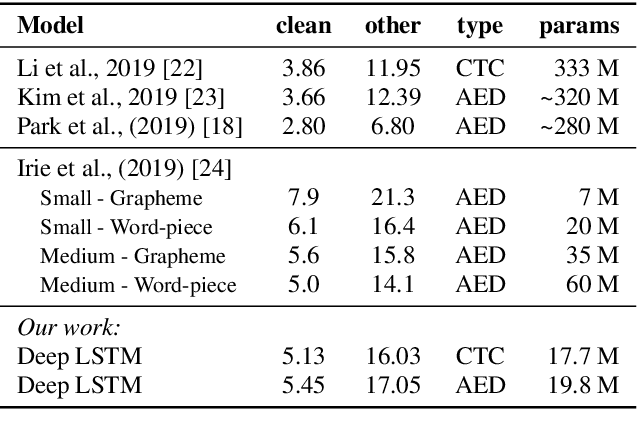
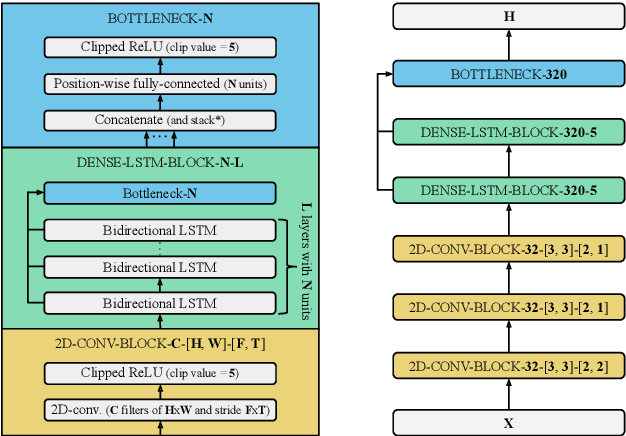
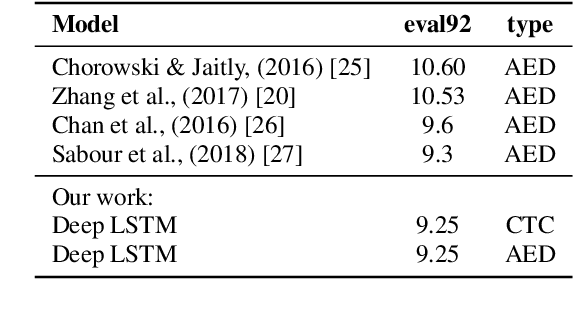
The two most common paradigms for end-to-end speech recognition are connectionist temporal classification (CTC) and attention-based encoder-decoder (AED) models. It has been argued that the latter is better suited for learning an implicit language model. We test this hypothesis by measuring temporal context sensitivity and evaluate how the models perform when we constrain the amount of contextual information in the audio input. We find that the AED model is indeed more context sensitive, but that the gap can be closed by adding self-attention to the CTC model. Furthermore, the two models perform similarly when contextual information is constrained. Finally, in contrast to previous research, our results show that the CTC model is highly competitive on WSJ and LibriSpeech without the help of an external language model.