 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Alignment Rests on Linear Structure
May 22, 2026We investigate the Platonic Representation Hypothesis (PRH) through a tripartite statistical framework of representations: signal, bias, and noise. {1) Signal:} We propose that Platonic alignment arises from the universal relationship between objects and attributes, which is encoded linearly in representations according to the Linear Representation Hypothesis (LRH). We provide evidence that LRH helps explain PRH by extracting linear object-attribute features with sparse autoencoders and showing that these sparse representations often exhibit stronger cross-modal alignment than their dense counterparts. {2) Bias:} Models have different implicit biases due to the diverse architectures and training procedures used. We show that this difference can be partially mitigated. Centering and normalization consistently improve cross-model alignment. {3) Noise:} Finite-sample training leads to noise in representations. We provide evidence that representational noise is driven by data scarcity by revealing a strong and consistent positive correlation between word frequency and alignment in LLMs and text embedding models. Synthesizing signal, bias, and noise, we propose a statistical model that refines the Linear Representation Hypothesis and explains further phenomena related to the alignment of representations emerging from diverse modern AI architectures.
Is Dimensionality a Barrier for Retrieval Models?
May 22, 2026Why does the low dimensionality of representations, typically $d\approx 1000$, not prevent modern embedding-based retrieval models from scaling to billions, or even trillions, of data points? To answer this question, we study maximal-margin embeddings in the following retrieval model, classically studied in communication complexity [PS86] and more recently in embedding-based retrieval [WBNL26]. Let $A\in \{0,1\}^{N\times n}$ be a matrix indicating whether each of $N$ queries is relevant to each of $n$ documents. We are interested in the largest margin $m>0,$ denoted by $\mathsf{m}^{\mathsf{rd}}(d, A),$ for which there exist unit norm embeddings of the queries and documents $\{U_j\}_{j = 1}^N, \{V_i\}_{i = 1}^n$ with the following property. $\langle U_j, V_i\rangle \ge m$ whenever $A_{ji} = 1$ and $\langle U_j, V_i\rangle \le -m$ otherwise. A large margin is a key proxy for representation quality: it controls both robustness to perturbations and compositional generalization across queries. Our main theorem establishes that the best possible margin without a restriction on the dimension, $\mathsf{m}^{\mathsf{rd}}(+\infty, A),$ can be nearly achieved in dimension $d = O(\mathsf{m}^{\mathsf{rd}}(+\infty, A)^{-2}\log n)$ which improves a theorem of [BDES02]. Together with a matching lower bound in Theorem 1.5, we conclude that when $A\in \{0,1\}^{\binom{n}{k}\times n}$ is the matrix containing all possible $k$-sparse rows once, dimension $d = O(k\log (n/k))$ is necessary and sufficient for the maximal possible margin $\mathsf{m}^{\mathsf{rd}}(+\infty, A) = Θ(k^{-1/2})$ in this setting. This fully resolves the setup of [WBNL26]. We also give several constructions for large margins when $d = o(k\log (n/k)).$ Finally, we empirically test the InfoNCE and sigmoid losses for producing large margin embeddings and demonstrate a clear advantage of the sigmoid loss.
Efficient reductions from a Gaussian source with applications to statistical-computational tradeoffs
Oct 08, 2025Given a single observation from a Gaussian distribution with unknown mean $\theta$, we design computationally efficient procedures that can approximately generate an observation from a different target distribution $Q_{\theta}$ uniformly for all $\theta$ in a parameter set. We leverage our technique to establish reduction-based computational lower bounds for several canonical high-dimensional statistical models under widely-believed conjectures in average-case complexity. In particular, we cover cases in which: 1. $Q_{\theta}$ is a general location model with non-Gaussian distribution, including both light-tailed examples (e.g., generalized normal distributions) and heavy-tailed ones (e.g., Student's $t$-distributions). As a consequence, we show that computational lower bounds proved for spiked tensor PCA with Gaussian noise are universal, in that they extend to other non-Gaussian noise distributions within our class. 2. $Q_{\theta}$ is a normal distribution with mean $f(\theta)$ for a general, smooth, and nonlinear link function $f:\mathbb{R} \rightarrow \mathbb{R}$. Using this reduction, we construct a reduction from symmetric mixtures of linear regressions to generalized linear models with link function $f$, and establish computational lower bounds for solving the $k$-sparse generalized linear model when $f$ is an even function. This result constitutes the first reduction-based confirmation of a $k$-to-$k^2$ statistical-to-computational gap in $k$-sparse phase retrieval, resolving a conjecture posed by Cai et al. (2016). As a second application, we construct a reduction from the sparse rank-1 submatrix model to the planted submatrix model, establishing a pointwise correspondence between the phase diagrams of the two models that faithfully preserves regions of computational hardness and tractability.
Optimal Sequential Recommendations: Exploiting User and Item Structure
Apr 28, 2025We consider an online model for recommendation systems, with each user being recommended an item at each time-step and providing 'like' or 'dislike' feedback. A latent variable model specifies the user preferences: both users and items are clustered into types. The model captures structure in both the item and user spaces, as used by item-item and user-user collaborative filtering algorithms. We study the situation in which the type preference matrix has i.i.d. entries. Our main contribution is an algorithm that simultaneously uses both item and user structures, proved to be near-optimal via corresponding information-theoretic lower bounds. In particular, our analysis highlights the sub-optimality of using only one of item or user structure (as is done in most collaborative filtering algorithms).
Efficient reductions between some statistical models
Feb 12, 2024We study the problem of approximately transforming a sample from a source statistical model to a sample from a target statistical model without knowing the parameters of the source model, and construct several computationally efficient such reductions between statistical experiments. In particular, we provide computationally efficient procedures that approximately reduce uniform, Erlang, and Laplace location models to general target families. We illustrate our methodology by establishing nonasymptotic reductions between some canonical high-dimensional problems, spanning mixtures of experts, phase retrieval, and signal denoising. Notably, the reductions are structure preserving and can accommodate missing data. We also point to a possible application in transforming one differentially private mechanism to another.
The staircase property: How hierarchical structure can guide deep learning
Aug 24, 2021



This paper identifies a structural property of data distributions that enables deep neural networks to learn hierarchically. We define the "staircase" property for functions over the Boolean hypercube, which posits that high-order Fourier coefficients are reachable from lower-order Fourier coefficients along increasing chains. We prove that functions satisfying this property can be learned in polynomial time using layerwise stochastic coordinate descent on regular neural networks -- a class of network architectures and initializations that have homogeneity properties. Our analysis shows that for such staircase functions and neural networks, the gradient-based algorithm learns high-level features by greedily combining lower-level features along the depth of the network. We further back our theoretical results with experiments showing that staircase functions are also learnable by more standard ResNet architectures with stochastic gradient descent. Both the theoretical and experimental results support the fact that staircase properties have a role to play in understanding the capabilities of gradient-based learning on regular networks, in contrast to general polynomial-size networks that can emulate any SQ or PAC algorithms as recently shown.
The Algorithmic Phase Transition of Random $k$-SAT for Low Degree Polynomials
Jun 17, 2021
Let $\Phi$ be a uniformly random $k$-SAT formula with $n$ variables and $m$ clauses. We study the algorithmic task of finding a satisfying assignment of $\Phi$. It is known that a satisfying assignment exists with high probability at clause density $m/n < 2^k \log 2 - \frac{1}{2} (\log 2 + 1) + o_k(1)$, while the best polynomial-time algorithm known, the Fix algorithm of Coja-Oghlan, finds a satisfying assignment at the much lower clause density $(1 - o_k(1)) 2^k \log k / k$. This prompts the question: is it possible to efficiently find a satisfying assignment at higher clause densities? To understand the algorithmic threshold of random $k$-SAT, we study low degree polynomial algorithms, which are a powerful class of algorithms including Fix, Survey Propagation guided decimation (with bounded or mildly growing number of message passing rounds), and paradigms such as message passing and local graph algorithms. We show that low degree polynomial algorithms can find a satisfying assignment at clause density $(1 - o_k(1)) 2^k \log k / k$, matching Fix, and not at clause density $(1 + o_k(1)) \kappa^* 2^k \log k / k$, where $\kappa^* \approx 4.911$. This shows the first sharp (up to constant factor) computational phase transition of random $k$-SAT for a class of algorithms. Our proof establishes and leverages a new many-way overlap gap property tailored to random $k$-SAT.
Chow-Liu++: Optimal Prediction-Centric Learning of Tree Ising Models
Jun 16, 2021
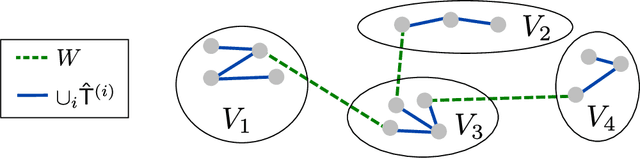
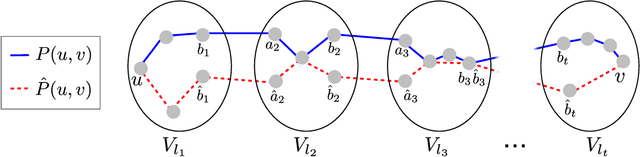
We consider the problem of learning a tree-structured Ising model from data, such that subsequent predictions computed using the model are accurate. Concretely, we aim to learn a model such that posteriors $P(X_i|X_S)$ for small sets of variables $S$ are accurate. Since its introduction more than 50 years ago, the Chow-Liu algorithm, which efficiently computes the maximum likelihood tree, has been the benchmark algorithm for learning tree-structured graphical models. A bound on the sample complexity of the Chow-Liu algorithm with respect to the prediction-centric local total variation loss was shown in [BK19]. While those results demonstrated that it is possible to learn a useful model even when recovering the true underlying graph is impossible, their bound depends on the maximum strength of interactions and thus does not achieve the information-theoretic optimum. In this paper, we introduce a new algorithm that carefully combines elements of the Chow-Liu algorithm with tree metric reconstruction methods to efficiently and optimally learn tree Ising models under a prediction-centric loss. Our algorithm is robust to model misspecification and adversarial corruptions. In contrast, we show that the celebrated Chow-Liu algorithm can be arbitrarily suboptimal.
The EM Algorithm is Adaptively-Optimal for Unbalanced Symmetric Gaussian Mixtures
Mar 29, 2021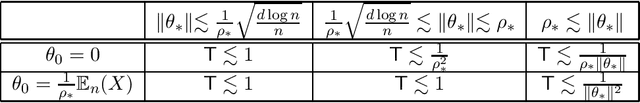
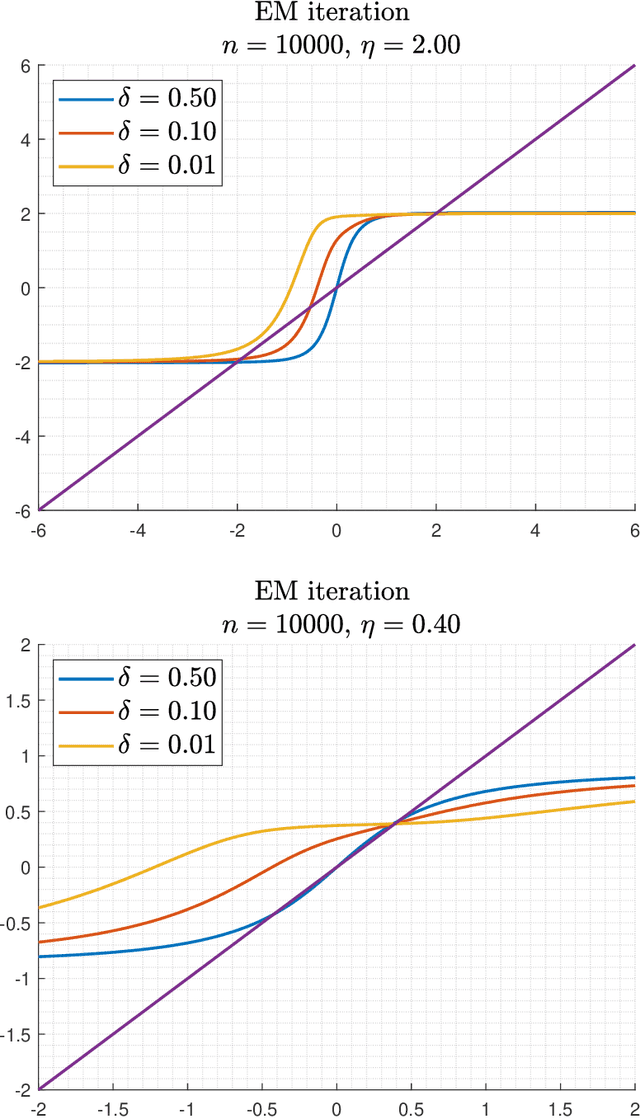
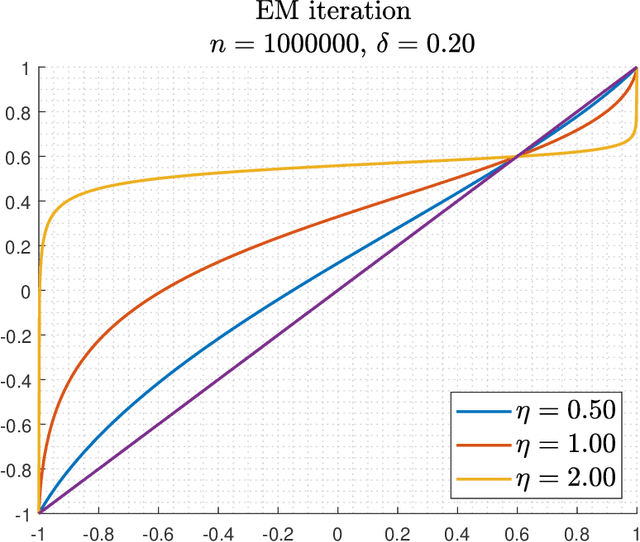
This paper studies the problem of estimating the means $\pm\theta_{*}\in\mathbb{R}^{d}$ of a symmetric two-component Gaussian mixture $\delta_{*}\cdot N(\theta_{*},I)+(1-\delta_{*})\cdot N(-\theta_{*},I)$ where the weights $\delta_{*}$ and $1-\delta_{*}$ are unequal. Assuming that $\delta_{*}$ is known, we show that the population version of the EM algorithm globally converges if the initial estimate has non-negative inner product with the mean of the larger weight component. This can be achieved by the trivial initialization $\theta_{0}=0$. For the empirical iteration based on $n$ samples, we show that when initialized at $\theta_{0}=0$, the EM algorithm adaptively achieves the minimax error rate $\tilde{O}\Big(\min\Big\{\frac{1}{(1-2\delta_{*})}\sqrt{\frac{d}{n}},\frac{1}{\|\theta_{*}\|}\sqrt{\frac{d}{n}},\left(\frac{d}{n}\right)^{1/4}\Big\}\Big)$ in no more than $O\Big(\frac{1}{\|\theta_{*}\|(1-2\delta_{*})}\Big)$ iterations (with high probability). We also consider the EM iteration for estimating the weight $\delta_{*}$, assuming a fixed mean $\theta$ (which is possibly mismatched to $\theta_{*}$). For the empirical iteration of $n$ samples, we show that the minimax error rate $\tilde{O}\Big(\frac{1}{\|\theta_{*}\|}\sqrt{\frac{d}{n}}\Big)$ is achieved in no more than $O\Big(\frac{1}{\|\theta_{*}\|^{2}}\Big)$ iterations. These results robustify and complement recent results of Wu and Zhou obtained for the equal weights case $\delta_{*}=1/2$.
Statistical Query Algorithms and Low-Degree Tests Are Almost Equivalent
Sep 13, 2020Researchers currently use a number of approaches to predict and substantiate information-computation gaps in high-dimensional statistical estimation problems. A prominent approach is to characterize the limits of restricted models of computation, which on the one hand yields strong computational lower bounds for powerful classes of algorithms and on the other hand helps guide the development of efficient algorithms. In this paper, we study two of the most popular restricted computational models, the statistical query framework and low-degree polynomials, in the context of high-dimensional hypothesis testing. Our main result is that under mild conditions on the testing problem, the two classes of algorithms are essentially equivalent in power. As corollaries, we obtain new statistical query lower bounds for sparse PCA, tensor PCA and several variants of the planted clique problem.