 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VeniBot: Towards Autonomous Venipuncture with Semi-supervised Vein Segmentation from Ultrasound Images
May 27, 2021
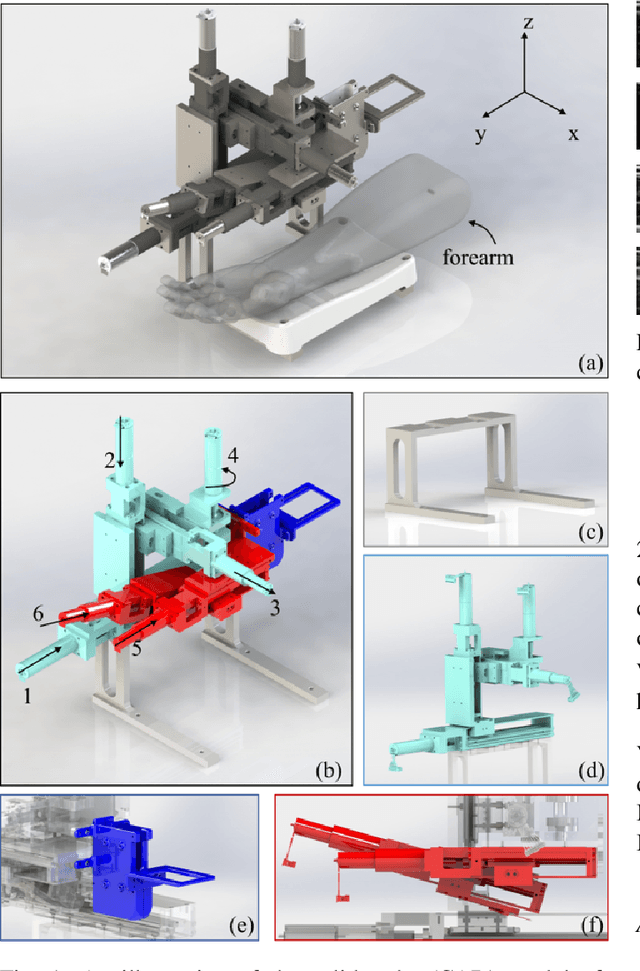
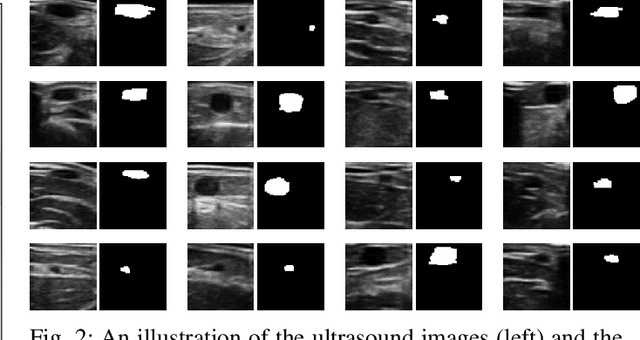
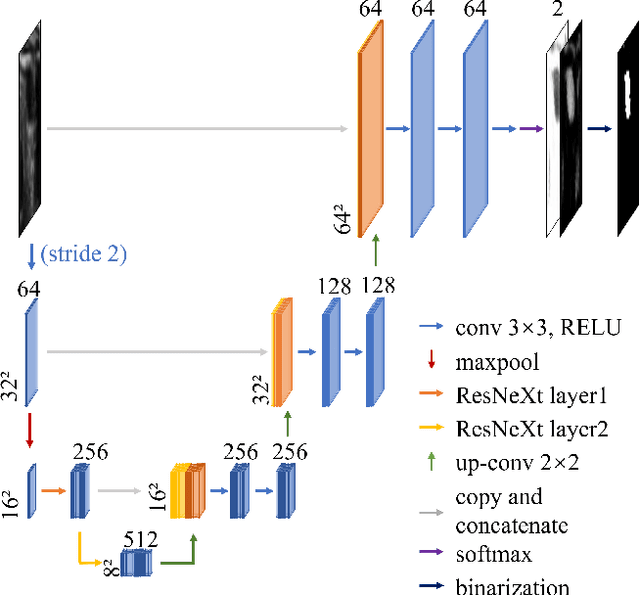

In the modern medical care, venipuncture is an indispensable procedure for both diagnosis and treatment. In this paper, unlike existing solutions that fully or partially rely on professional assistance, we propose VeniBot -- a compact robotic system solution integrating both novel hardware and software developments. For the hardware, we design a set of units to facilitate the supporting, positioning, puncturing and imaging functionalities. For the software, to move towards a full automation, we propose a novel deep learning framework -- semi-ResNeXt-Unet for semi-supervised vein segmentation from ultrasound images. From which, the depth information of vein is calculated and used to enable automated navigation for the puncturing unit. VeniBot is validated on 40 volunteers, where ultrasound images can be collected successfully. For the vein segmentation validation, the proposed semi-ResNeXt-Unet improves the dice similarity coefficient (DSC) by 5.36%, decreases the centroid error by 1.38 pixels and decreases the failure rate by 5.60%, compared to fully-supervised ResNeXt-Unet.
Adversarial Graph Augmentation to Improve Graph Contrastive Learning
Jun 11, 2021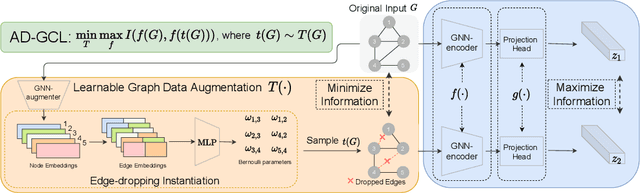
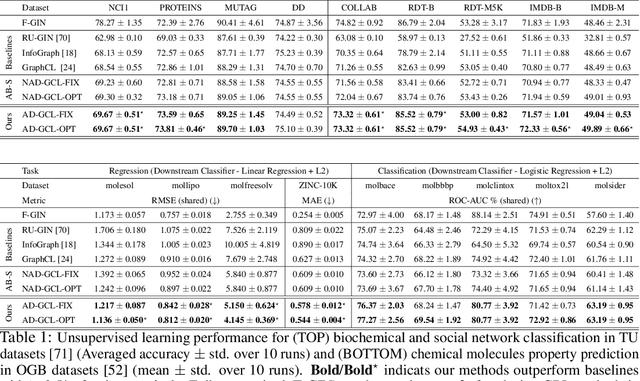
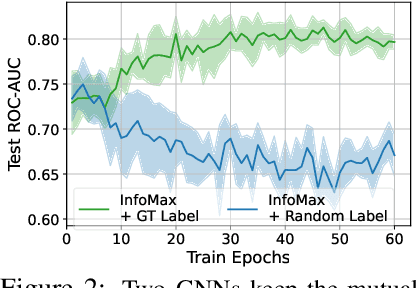
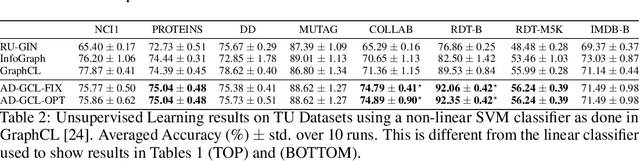
Self-supervised learning of graph neural networks (GNN) is in great need because of the widespread label scarcity issue in real-world graph/network data. Graph contrastive learning (GCL), by training GNNs to maximize the correspondence between the representations of the same graph in its different augmented forms, may yield robust and transferable GNNs even without using labels. However, GNNs trained by traditional GCL often risk capturing redundant graph features and thus may be brittle and provide sub-par performance in downstream tasks. Here, we propose a novel principle, termed adversarial-GCL (AD-GCL), which enables GNNs to avoid capturing redundant information during the training by optimizing adversarial graph augmentation strategies used in GCL. We pair AD-GCL with theoretical explanations and design a practical instantiation based on trainable edge-dropping graph augmentation. We experimentally validate AD-GCL by comparing with the state-of-the-art GCL methods and achieve performance gains of up-to $14\%$ in unsupervised, $6\%$ in transfer, and $3\%$ in semi-supervised learning settings overall with 18 different benchmark datasets for the tasks of molecule property regression and classification, and social network classification.
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer
Mar 07, 2021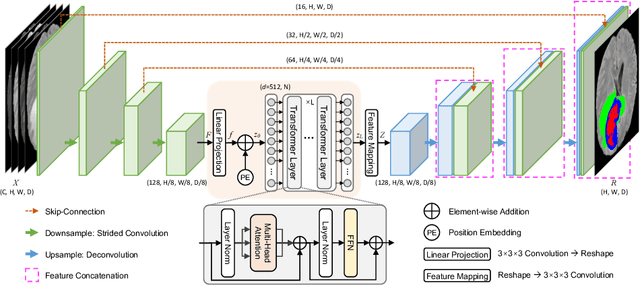
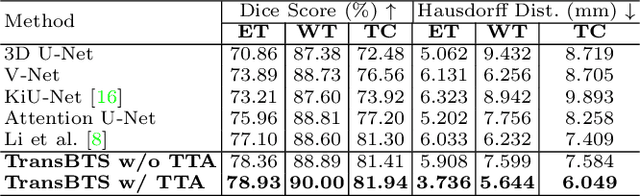
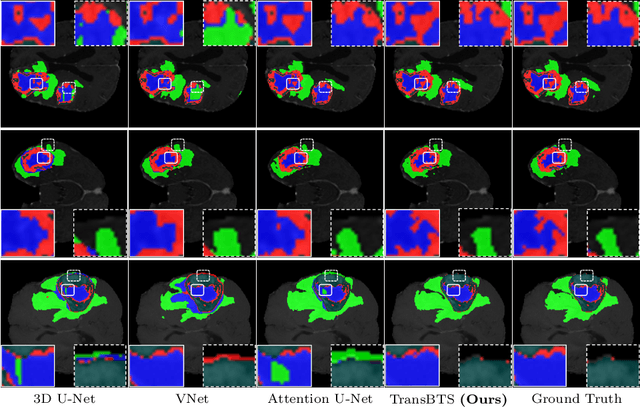
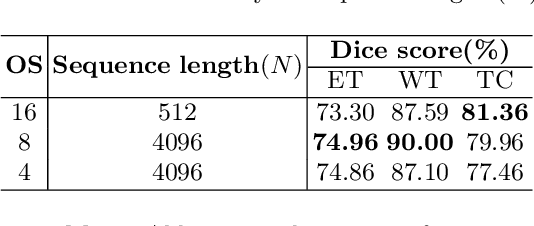
Transformer, which can benefit from global (long-range) information modeling using self-attention mechanisms, has been successful in natural language processing and 2D image classification recently. However, both local and global features are crucial for dense prediction tasks, especially for 3D medical image segmentation. In this paper, we for the first time exploit Transformer in 3D CNN for MRI Brain Tumor Segmentation and propose a novel network named TransBTS based on the encoder-decoder structure. To capture the local 3D context information, the encoder first utilizes 3D CNN to extract the volumetric spatial feature maps. Meanwhile, the feature maps are reformed elaborately for tokens that are fed into Transformer for global feature modeling. The decoder leverages the features embedded by Transformer and performs progressive upsampling to predict the detailed segmentation map. Experimental results on the BraTS 2019 dataset show that TransBTS outperforms state-of-the-art methods for brain tumor segmentation on 3D MRI scans. Code is available at https://github.com/Wenxuan-1119/TransBTS
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution
Jun 04, 2021
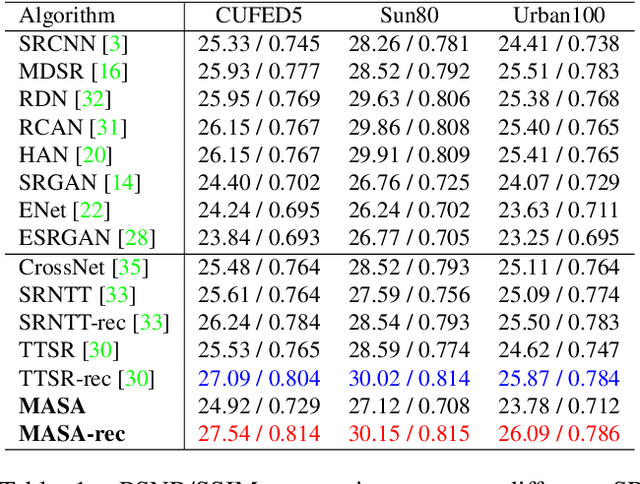
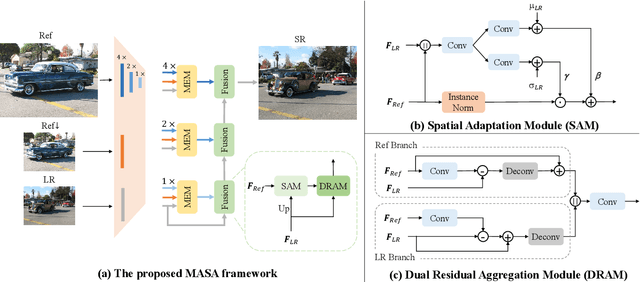

Reference-based image super-resolution (RefSR) has shown promising success in recovering high-frequency details by utilizing an external reference image (Ref). In this task, texture details are transferred from the Ref image to the low-resolution (LR) image according to their point- or patch-wise correspondence. Therefore, high-quality correspondence matching is critical. It is also desired to be computationally efficient. Besides, existing RefSR methods tend to ignore the potential large disparity in distributions between the LR and Ref images, which hurts the effectiveness of the information utilization. In this paper, we propose the MASA network for RefSR, where two novel modules are designed to address these problems. The proposed Match & Extraction Module significantly reduces the computational cost by a coarse-to-fine correspondence matching scheme. The Spatial Adaptation Module learns the difference of distribution between the LR and Ref images, and remaps the distribution of Ref features to that of LR features in a spatially adaptive way. This scheme makes the network robust to handle different reference images. Extensive quantitative and qualitative experiments validate the effectiveness of our proposed model.
Maximum mutual information regularized classification
Sep 27, 2014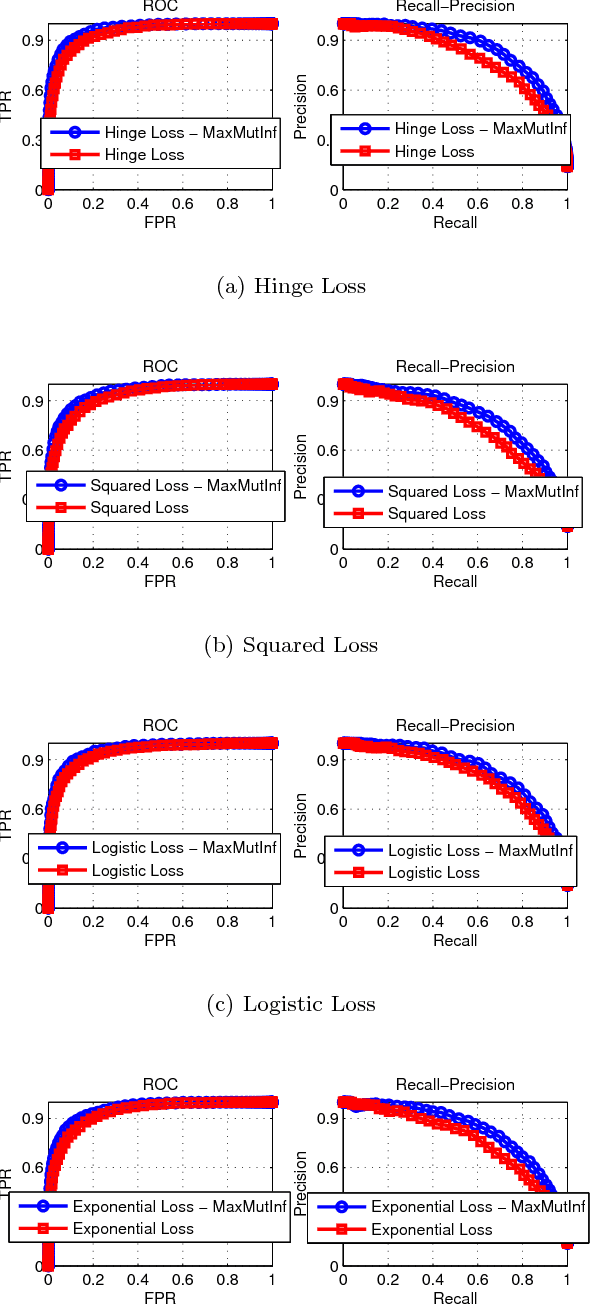
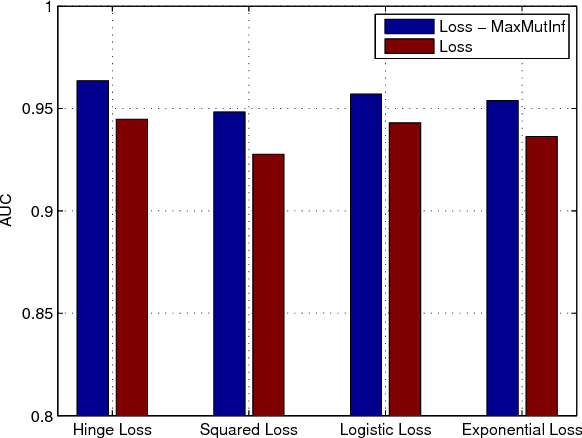
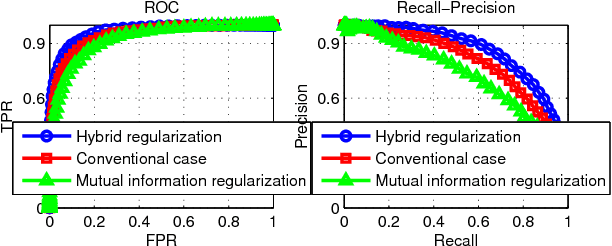
In this paper, a novel pattern classification approach is proposed by regularizing the classifier learning to maximize mutual information between the classification response and the true class label. We argue that, with the learned classifier, the uncertainty of the true class label of a data sample should be reduced by knowing its classification response as much as possible. The reduced uncertainty is measured by the mutual information between the classification response and the true class label. To this end, when learning a linear classifier, we propose to maximize the mutual information between classification responses and true class labels of training samples, besides minimizing the classification error and reduc- ing the classifier complexity. An objective function is constructed by modeling mutual information with entropy estimation, and it is optimized by a gradi- ent descend method in an iterative algorithm. Experiments on two real world pattern classification problems show the significant improvements achieved by maximum mutual information regularization.
Temporally-Aware Feature Pooling for Action Spotting in Soccer Broadcasts
Apr 14, 2021

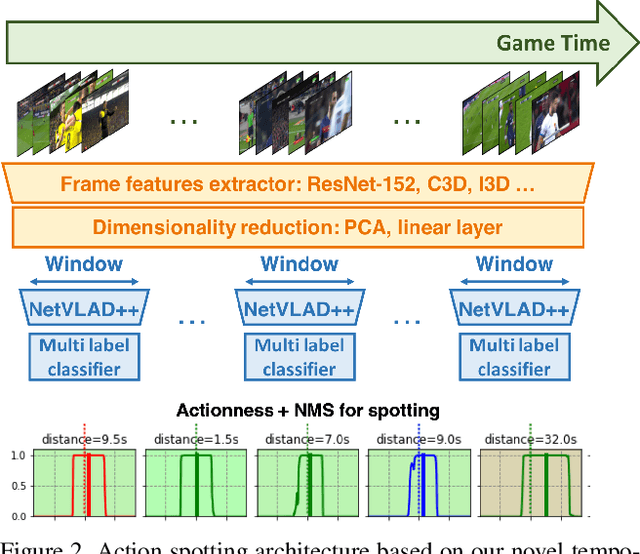
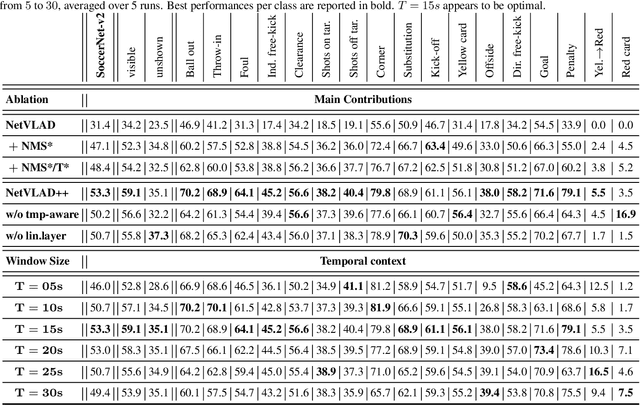
Toward the goal of automatic production for sports broadcasts, a paramount task consists in understanding the high-level semantic information of the game in play. For instance, recognizing and localizing the main actions of the game would allow producers to adapt and automatize the broadcast production, focusing on the important details of the game and maximizing the spectator engagement. In this paper, we focus our analysis on action spotting in soccer broadcast, which consists in temporally localizing the main actions in a soccer game. To that end, we propose a novel feature pooling method based on NetVLAD, dubbed NetVLAD++, that embeds temporally-aware knowledge. Different from previous pooling methods that consider the temporal context as a single set to pool from, we split the context before and after an action occurs. We argue that considering the contextual information around the action spot as a single entity leads to a sub-optimal learning for the pooling module. With NetVLAD++, we disentangle the context from the past and future frames and learn specific vocabularies of semantics for each subsets, avoiding to blend and blur such vocabulary in time. Injecting such prior knowledge creates more informative pooling modules and more discriminative pooled features, leading into a better understanding of the actions. We train and evaluate our methodology on the recent large-scale dataset SoccerNet-v2, reaching 53.4% Average-mAP for action spotting, a +12.7% improvement w.r.t the current state-of-the-art.
Next-item Recommendations in Short Sessions
Jul 15, 2021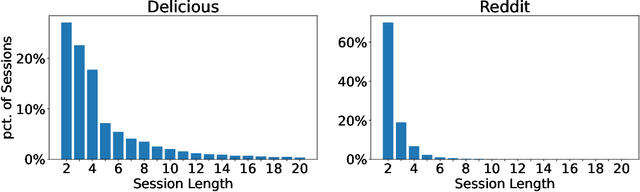
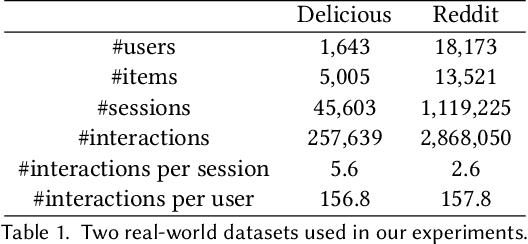
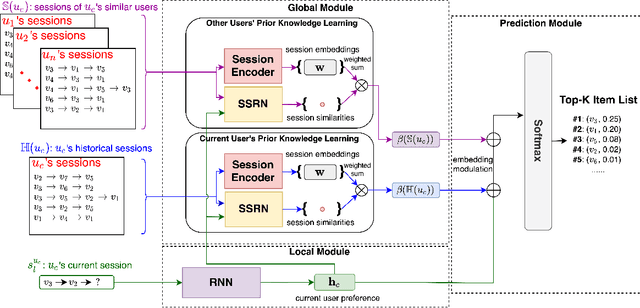
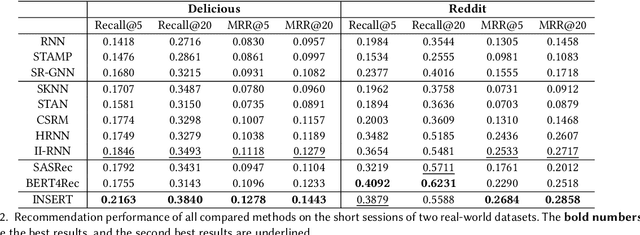
The changing preferences of users towards items trigger the emergence of session-based recommender systems (SBRSs), which aim to model the dynamic preferences of users for next-item recommendations. However, most of the existing studies on SBRSs are based on long sessions only for recommendations, ignoring short sessions, though short sessions, in fact, account for a large proportion in most of the real-world datasets. As a result, the applicability of existing SBRSs solutions is greatly reduced. In a short session, quite limited contextual information is available, making the next-item recommendation very challenging. To this end, in this paper, inspired by the success of few-shot learning (FSL) in effectively learning a model with limited instances, we formulate the next-item recommendation as an FSL problem. Accordingly, following the basic idea of a representative approach for FSL, i.e., meta-learning, we devise an effective SBRS called INter-SEssion collaborative Recommender netTwork (INSERT) for next-item recommendations in short sessions. With the carefully devised local module and global module, INSERT is able to learn an optimal preference representation of the current user in a given short session. In particular, in the global module, a similar session retrieval network (SSRN) is designed to find out the sessions similar to the current short session from the historical sessions of both the current user and other users, respectively. The obtained similar sessions are then utilized to complement and optimize the preference representation learned from the current short session by the local module for more accurate next-item recommendations in this short session. Extensive experiments conducted on two real-world datasets demonstrate the superiority of our proposed INSERT over the state-of-the-art SBRSs when making next-item recommendations in short sessions.
Practical Defences Against Model Inversion Attacks for Split Neural Networks
Apr 21, 2021
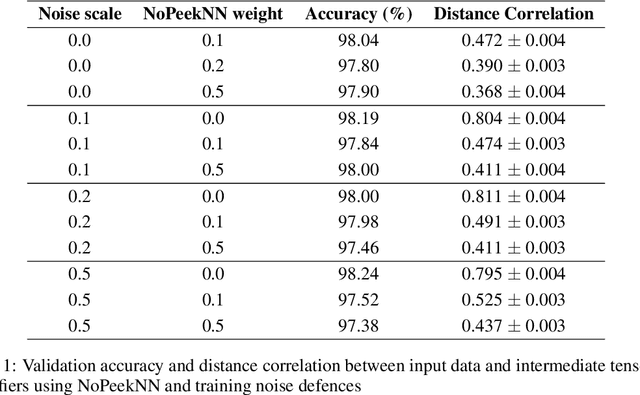


We describe a threat model under which a split network-based federated learning system is susceptible to a model inversion attack by a malicious computational server. We demonstrate that the attack can be successfully performed with limited knowledge of the data distribution by the attacker. We propose a simple additive noise method to defend against model inversion, finding that the method can significantly reduce attack efficacy at an acceptable accuracy trade-off on MNIST. Furthermore, we show that NoPeekNN, an existing defensive method, protects different information from exposure, suggesting that a combined defence is necessary to fully protect private user data.
Multi-target DoA Estimation with an Audio-visual Fusion Mechanism
May 13, 2021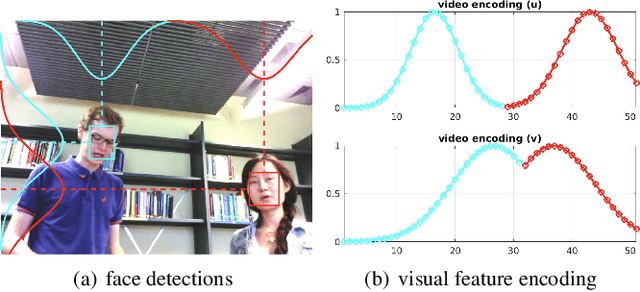
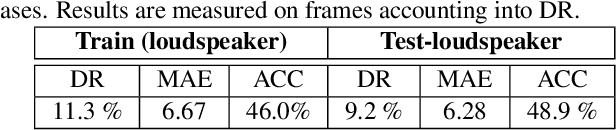
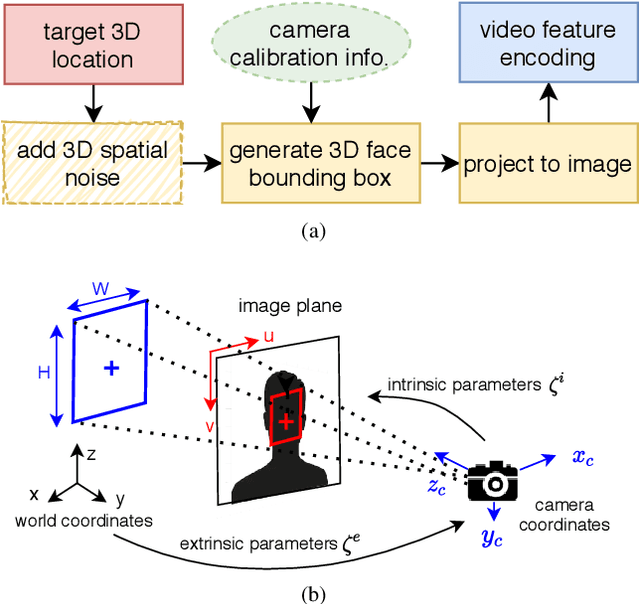

Most of the prior studies in the spatial \ac{DoA} domain focus on a single modality. However, humans use auditory and visual senses to detect the presence of sound sources. With this motivation, we propose to use neural networks with audio and visual signals for multi-speaker localization. The use of heterogeneous sensors can provide complementary information to overcome uni-modal challenges, such as noise, reverberation, illumination variations, and occlusions. We attempt to address these issues by introducing an adaptive weighting mechanism for audio-visual fusion. We also propose a novel video simulation method that generates visual features from noisy target 3D annotations that are synchronized with acoustic features. Experimental results confirm that audio-visual fusion consistently improves the performance of speaker DoA estimation, while the adaptive weighting mechanism shows clear benefits.
A Mutual Reference Shape for Segmentation Fusion and Evaluation
Feb 05, 2021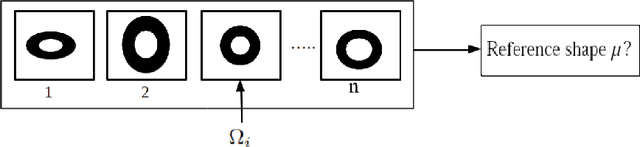

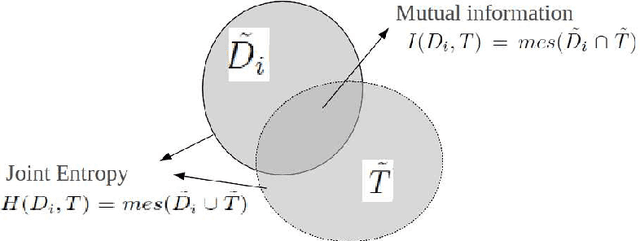
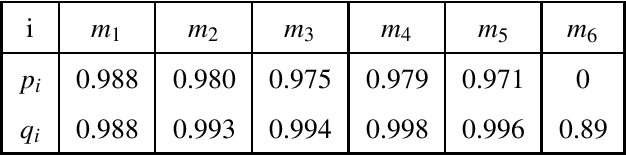
This paper proposes the estimation of a mutual shape from a set of different segmentation results using both active contours and information theory. The mutual shape is here defined as a consensus shape estimated from a set of different segmentations of the same object. In an original manner, such a shape is defined as the minimum of a criterion that benefits from both the mutual information and the joint entropy of the input segmentations. This energy criterion is justified using similarities between information theory quantities and area measures, and presented in a continuous variational framework. In order to solve this shape optimization problem, shape derivatives are computed for each term of the criterion and interpreted as an evolution equation of an active contour. A mutual shape is then estimated together with the sensitivity and specificity of each segmentation. Some synthetic examples allow us to cast the light on the difference between the mutual shape and an average shape. The applicability of our framework has also been tested for segmentation evaluation and fusion of different types of real images (natural color images, old manuscripts, medical images).