 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improved Deep Classwise Hashing With Centers Similarity Learning for Image Retrieval
Mar 17, 2021
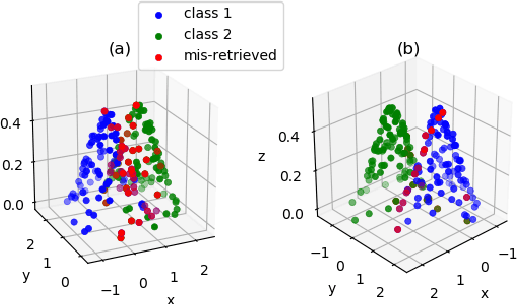
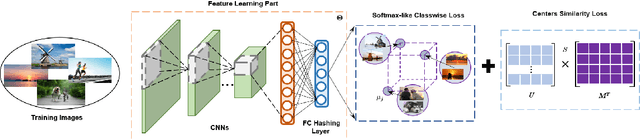
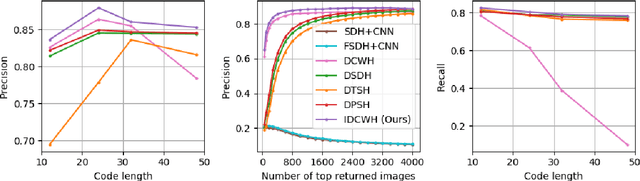
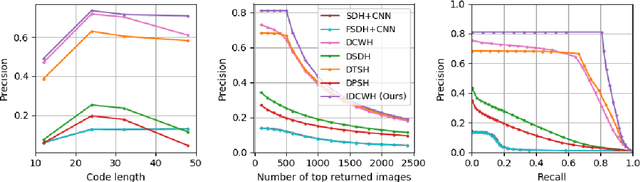
Deep supervised hashing for image retrieval has attracted researchers' attention due to its high efficiency and superior retrieval performance. Most existing deep supervised hashing works, which are based on pairwise/triplet labels, suffer from the expensive computational cost and insufficient utilization of the semantics information. Recently, deep classwise hashing introduced a classwise loss supervised by class labels information alternatively; however, we find it still has its drawback. In this paper, we propose an improved deep classwise hashing, which enables hashing learning and class centers learning simultaneously. Specifically, we design a two-step strategy on center similarity learning. It interacts with the classwise loss to attract the class center to concentrate on the intra-class samples while pushing other class centers as far as possible. The centers similarity learning contributes to generating more compact and discriminative hashing codes. We conduct experiments on three benchmark datasets. It shows that the proposed method effectively surpasses the original method and outperforms state-of-the-art baselines under various commonly-used evaluation metrics for image retrieval.
A data-based comparative review and AI-driven symbolic model for longitudinal dispersion coefficient in natural streams
Jul 16, 2021
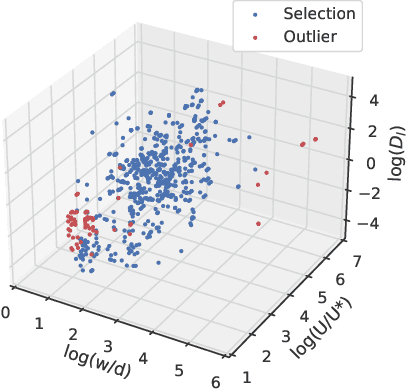

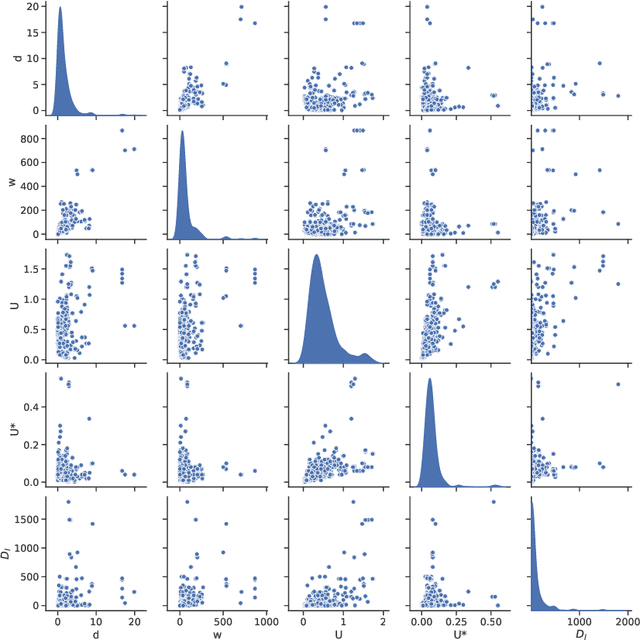
A better understanding of dispersion in natural streams requires knowledge of longitudinal dispersion coefficient(LDC). Various methods have been proposed for predictions of LDC. Those studies can be grouped into three types: analytical, statistical and ML-driven researches(Implicit and explicit). However, a comprehensive evaluation of them is still lacking. In this paper, we first present an in-depth analysis of those methods and find out their defects. This is carried out on an extensive database composed of 660 samples of hydraulic and channel properties worldwide. The reliability and representativeness of utilized data are enhanced through the deployment of the Subset Selection of Maximum Dissimilarity(SSMD) for testing set selection and the Inter Quartile Range(IQR) for removal of the outlier. The evaluation reveals the rank of those methods as: ML-driven method > the statistical method > the analytical method. Whereas implicit ML-driven methods are black-boxes in nature, explicit ML-driven methods have more potential in prediction of LDC. Besides, overfitting is a universal problem in existing models. Those models also suffer from a fixed parameter combination. To establish an interpretable model for LDC prediction with higher performance, we then design a novel symbolic regression method called evolutionary symbolic regression network(ESRN). It is a combination of genetic algorithms and neural networks. Strategies are introduced to avoid overfitting and explore more parameter combinations. Results show that the ESRN model has superiorities over other existing symbolic models in performance. The proposed model is suitable for practical engineering problems due to its advantage in low requirement of parameters (only w and U* are required). It can provide convincing solutions for situations where the field test cannot be carried out or limited field information can be obtained.
Real-time safety assessment of trajectories for autonomous driving
Apr 27, 2021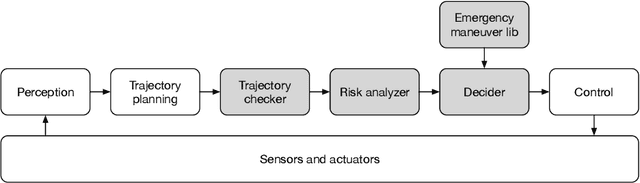
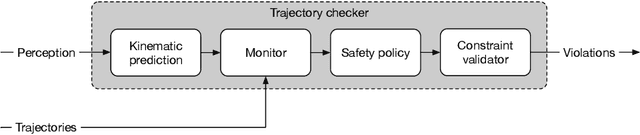
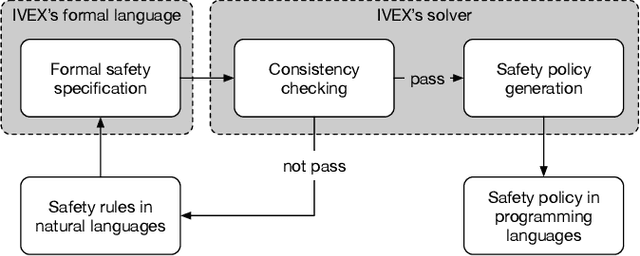
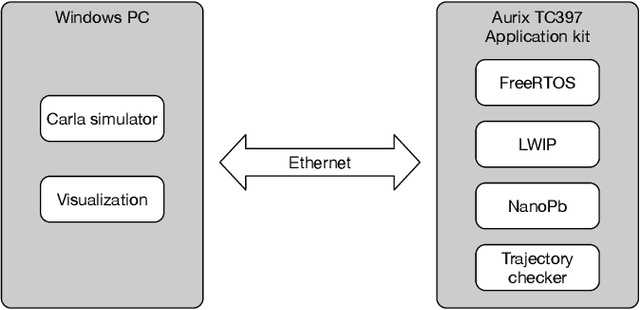
Autonomous vehicles (AVs) must always have a safe motion to guarantee that they are not causing any accidents. In an AV system, the motion of the vehicle is represented as a trajectory. A trajectory planning component is responsible to compute such a trajectory at run-time, taking into account the perception information about the environment, the dynamics of the vehicles, the predicted future states of other road users and a number of safety aspects. Due to the enormous amount of information to be considered, trajectory planning algorithms are complex, which makes it non-trivial to guarantee the safety of all planned trajectories. In this way, it is necessary to have an extra component to assess the safety of the planned trajectories at run-time. Such trajectory safety assessment component gives a diverse observation on the safety of AV trajectories and ensures that the AV only follows safe trajectories. We use the term trajectory checker to refer to the trajectory safety assessment component. The trajectory checker must evaluate planned trajectories against various safety rules, taking into account a large number of possibilities, including the worst-case behavior of other traffic participants. This must be done while guaranteeing hard real-time performance since the safety assessment is carried out while the vehicle is moving and in constant interaction with the environment. In this paper, we present a prototype of the trajectory checker we have developed at IVEX. We show how our approach works smoothly and accomplish real-time constraints embedded in an Infineon Aurix TC397B automotive platform. Finally, we measure the performance of our trajectory checker prototype against a set of NCAPS-inspired scenarios.
Collision Replay: What Does Bumping Into Things Tell You About Scene Geometry?
May 03, 2021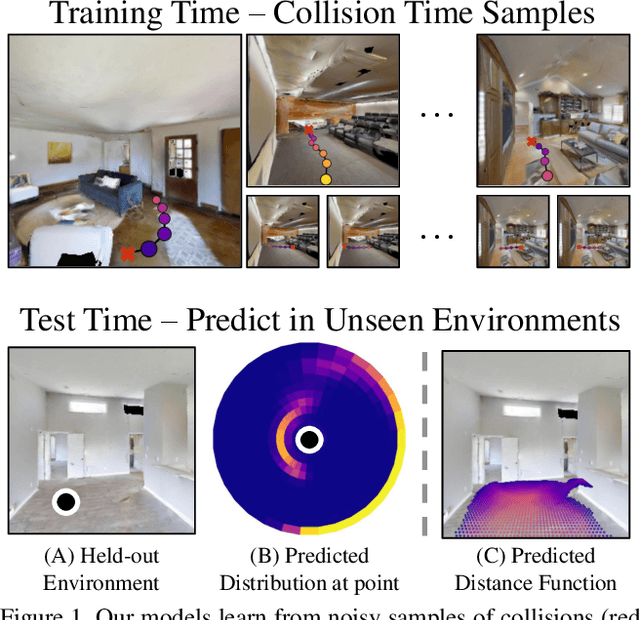
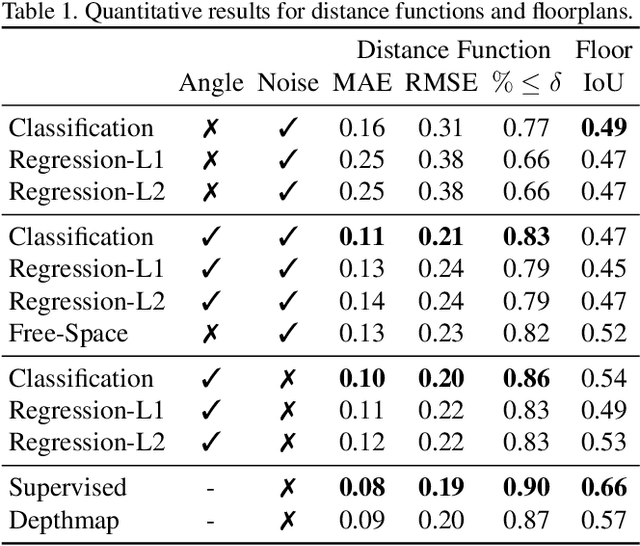
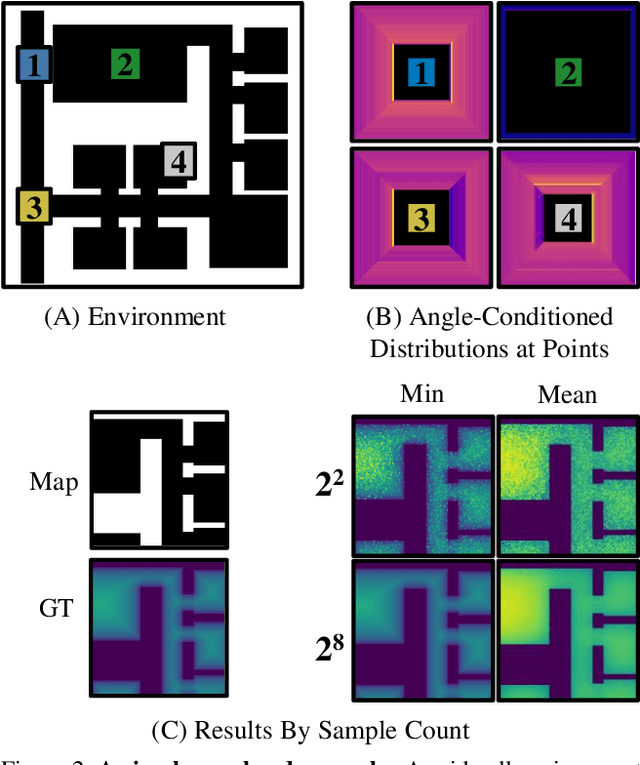
What does bumping into things in a scene tell you about scene geometry? In this paper, we investigate the idea of learning from collisions. At the heart of our approach is the idea of collision replay, where we use examples of a collision to provide supervision for observations at a past frame. We use collision replay to train convolutional neural networks to predict a distribution over collision time from new images. This distribution conveys information about the navigational affordances (e.g., corridors vs open spaces) and, as we show, can be converted into the distance function for the scene geometry. We analyze this approach with an agent that has noisy actuation in a photorealistic simulator.
M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection
Apr 21, 2021
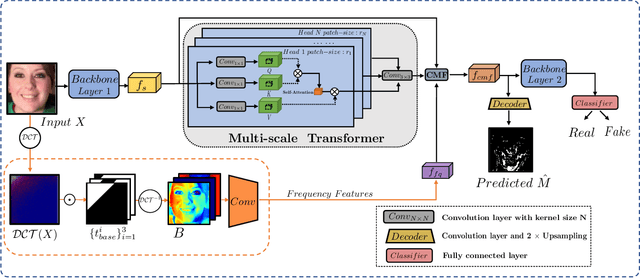
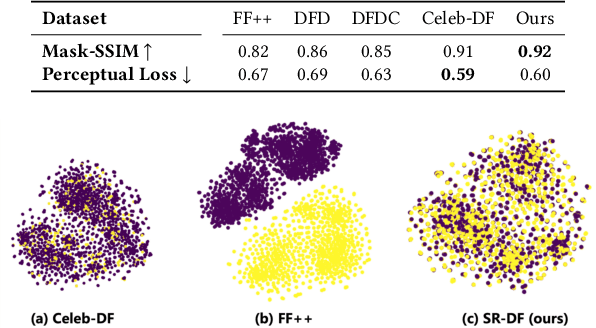
The widespread dissemination of forged images generated by Deepfake techniques has posed a serious threat to the trustworthiness of digital information. This demands effective approaches that can detect perceptually convincing Deepfakes generated by advanced manipulation techniques. Most existing approaches combat Deepfakes with deep neural networks by mapping the input image to a binary prediction without capturing the consistency among different pixels. In this paper, we aim to capture the subtle manipulation artifacts at different scales for Deepfake detection. We achieve this with transformer models, which have recently demonstrated superior performance in modeling dependencies between pixels for a variety of recognition tasks in computer vision. In particular, we introduce a Multi-modal Multi-scale TRansformer (M2TR), which uses a multi-scale transformer that operates on patches of different sizes to detect the local inconsistency at different spatial levels. To improve the detection results and enhance the robustness of our method to image compression, M2TR also takes frequency information, which is further combined with RGB features using a cross modality fusion module. Developing and evaluating Deepfake detection methods requires large-scale datasets. However, we observe that samples in existing benchmarks contain severe artifacts and lack diversity. This motivates us to introduce a high-quality Deepfake dataset, SR-DF, which consists of 4,000 DeepFake videos generated by state-of-the-art face swapping and facial reenactment methods. On three Deepfake datasets, we conduct extensive experiments to verify the effectiveness of the proposed method, which outperforms state-of-the-art Deepfake detection methods.
An Online Learning Approach to Optimizing Time-Varying Costs of AoI
May 27, 2021
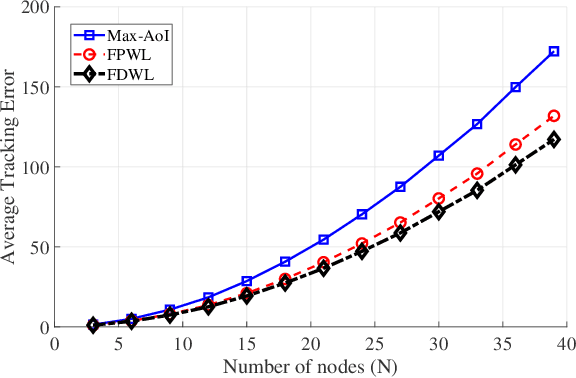
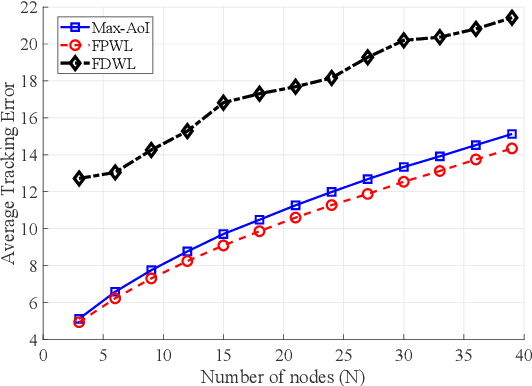
We consider systems that require timely monitoring of sources over a communication network, where the cost of delayed information is unknown, time-varying and possibly adversarial. For the single source monitoring problem, we design algorithms that achieve sublinear regret compared to the best fixed policy in hindsight. For the multiple source scheduling problem, we design a new online learning algorithm called Follow-the-Perturbed-Whittle-Leader and show that it has low regret compared to the best fixed scheduling policy in hindsight, while remaining computationally feasible. The algorithm and its regret analysis are novel and of independent interest to the study of online restless multi-armed bandit problems. We further design algorithms that achieve sublinear regret compared to the best dynamic policy when the environment is slowly varying. Finally, we apply our algorithms to a mobility tracking problem. We consider non-stationary and adversarial mobility models and illustrate the performance benefit of using our online learning algorithms compared to an oblivious scheduling policy.
Leveraging Deep Representations of Radiology Reports in Survival Analysis for Predicting Heart Failure Patient Mortality
May 03, 2021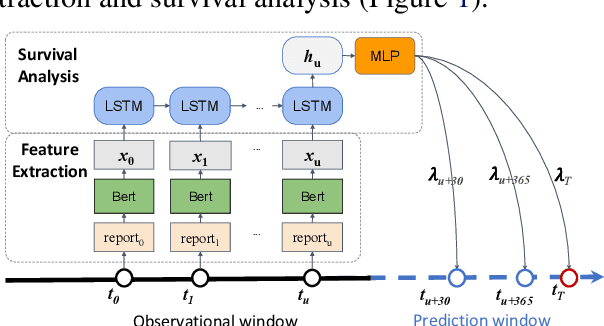
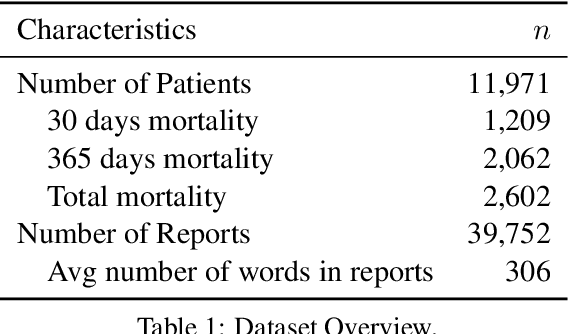
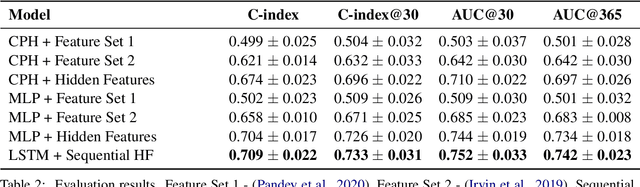
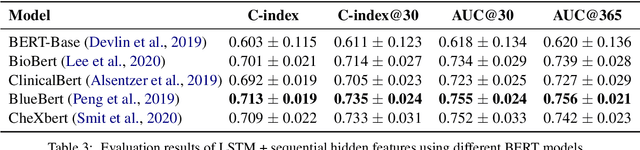
Utilizing clinical texts in survival analysis is difficult because they are largely unstructured. Current automatic extraction models fail to capture textual information comprehensively since their labels are limited in scope. Furthermore, they typically require a large amount of data and high-quality expert annotations for training. In this work, we present a novel method of using BERT-based hidden layer representations of clinical texts as covariates for proportional hazards models to predict patient survival outcomes. We show that hidden layers yield notably more accurate predictions than predefined features, outperforming the previous baseline model by 5.7% on average across C-index and time-dependent AUC. We make our work publicly available at https://github.com/bionlplab/heart_failure_mortality.
Medical Image Analysis on Left Atrial LGE MRI for Atrial Fibrillation Studies: A Review
Jun 25, 2021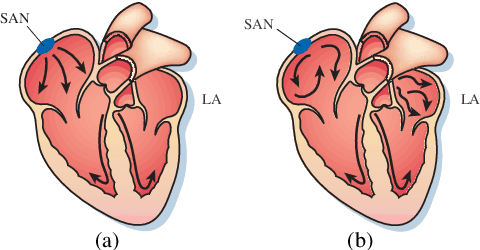
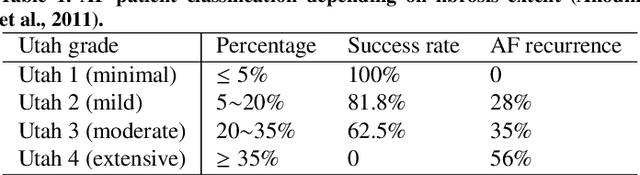
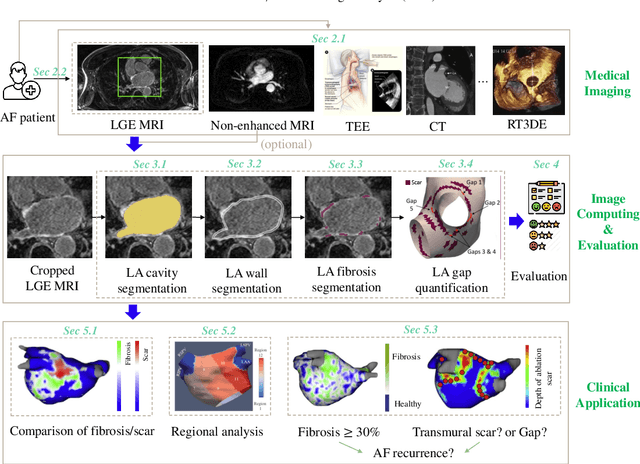

Late gadolinium enhancement magnetic resonance imaging (LGE MRI) is commonly used to visualize and quantify left atrial (LA) scars. The position and extent of scars provide important information of the pathophysiology and progression of atrial fibrillation (AF). Hence, LA scar segmentation and quantification from LGE MRI can be useful in computer-assisted diagnosis and treatment stratification of AF patients. Since manual delineation can be time-consuming and subject to intra- and inter-expert variability, automating this computing is highly desired, which nevertheless is still challenging and under-researched. This paper aims to provide a systematic review on computing methods for LA cavity, wall, scar and ablation gap segmentation and quantification from LGE MRI, and the related literature for AF studies. Specifically, we first summarize AF-related imaging techniques, particularly LGE MRI. Then, we review the methodologies of the four computing tasks in detail, and summarize the validation strategies applied in each task. Finally, the possible future developments are outlined, with a brief survey on the potential clinical applications of the aforementioned methods. The review shows that the research into this topic is still in early stages. Although several methods have been proposed, especially for LA segmentation, there is still large scope for further algorithmic developments due to performance issues related to the high variability of enhancement appearance and differences in image acquisition.
TableSense: Spreadsheet Table Detection with Convolutional Neural Networks
Jun 25, 2021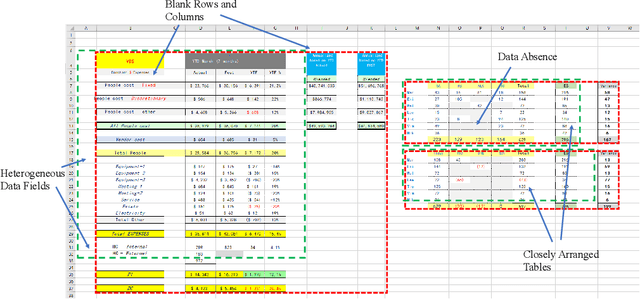
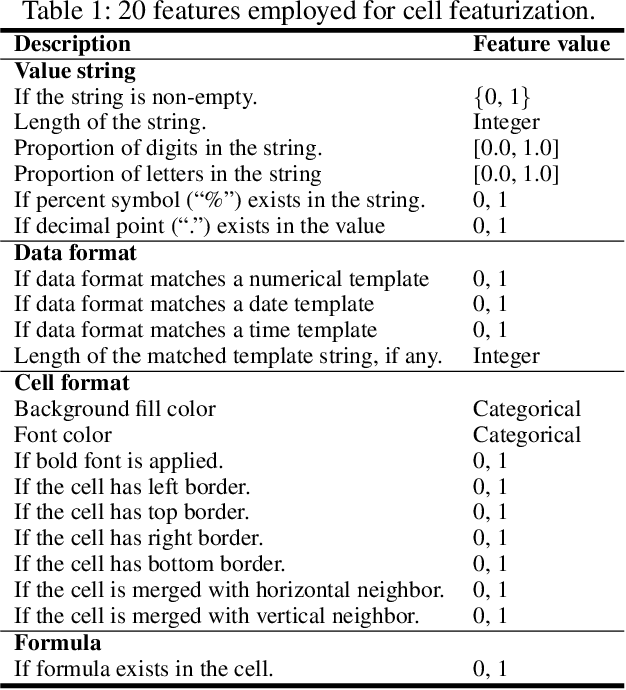

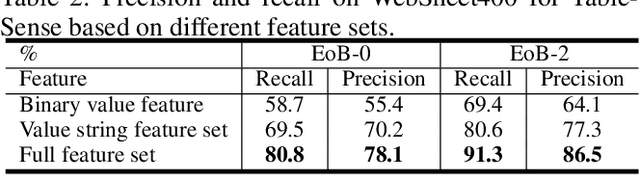
Spreadsheet table detection is the task of detecting all tables on a given sheet and locating their respective ranges. Automatic table detection is a key enabling technique and an initial step in spreadsheet data intelligence. However, the detection task is challenged by the diversity of table structures and table layouts on the spreadsheet. Considering the analogy between a cell matrix as spreadsheet and a pixel matrix as image, and encouraged by the successful application of Convolutional Neural Networks (CNN) in computer vision, we have developed TableSense, a novel end-to-end framework for spreadsheet table detection. First, we devise an effective cell featurization scheme to better leverage the rich information in each cell; second, we develop an enhanced convolutional neural network model for table detection to meet the domain-specific requirement on precise table boundary detection; third, we propose an effective uncertainty metric to guide an active learning based smart sampling algorithm, which enables the efficient build-up of a training dataset with 22,176 tables on 10,220 sheets with broad coverage of diverse table structures and layouts. Our evaluation shows that TableSense is highly effective with 91.3\% recall and 86.5\% precision in EoB-2 metric, a significant improvement over both the current detection algorithm that are used in commodity spreadsheet tools and state-of-the-art convolutional neural networks in computer vision.
Joint Retrieval and Generation Training for Grounded Text Generation
May 14, 2021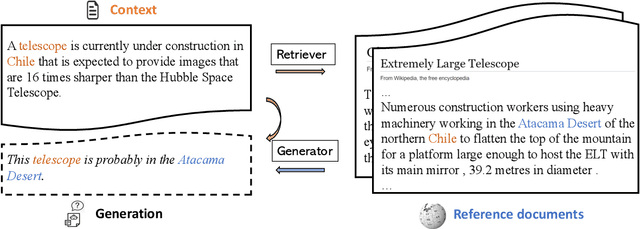
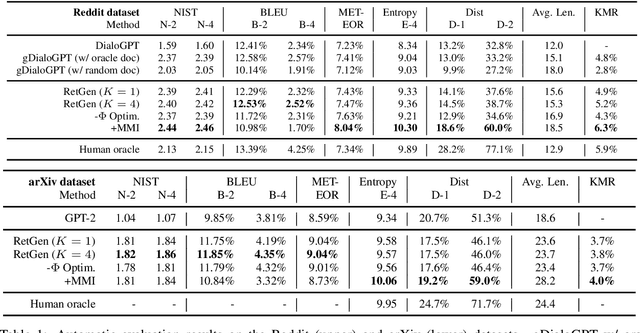
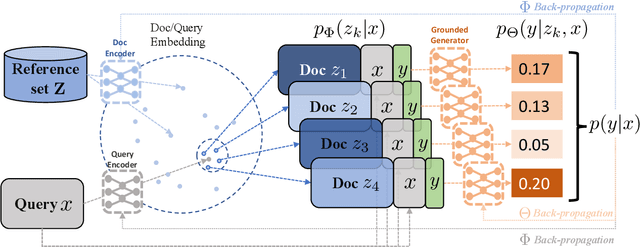

Recent advances in large-scale pre-training such as GPT-3 allow seemingly high quality text to be generated from a given prompt. However, such generation systems often suffer from problems of hallucinated facts, and are not inherently designed to incorporate useful external information. Grounded generation models appear to offer remedies, but their training typically relies on rarely-available parallel data where corresponding documents are provided for context. We propose a framework that alleviates this data constraint by jointly training a grounded generator and document retriever on the language model signal. The model learns to retrieve the documents with the highest utility in generation and attentively combines them in the output. We demonstrate that by taking advantage of external references our approach can produce more informative and interesting text in both prose and dialogue generation.