 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-supervised Feature Enhancement: Applying Internal Pretext Task to Supervised Learning
Jun 09, 2021
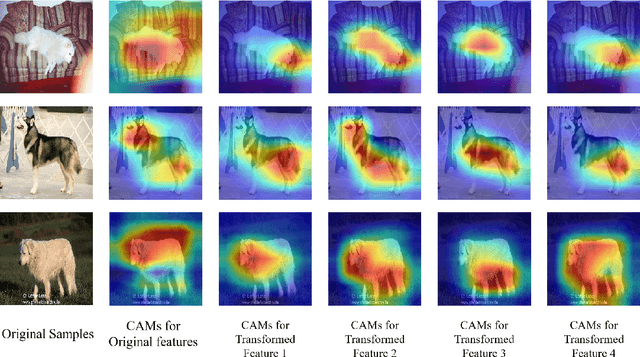
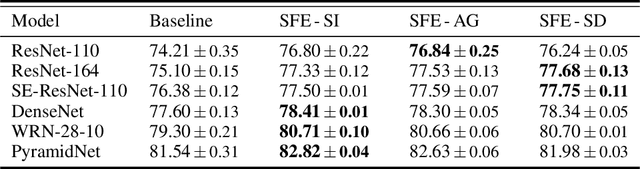
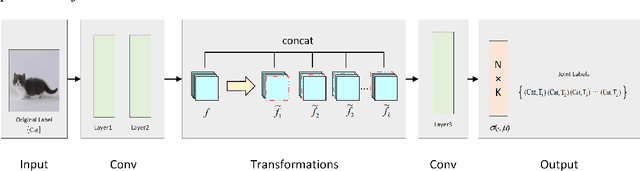

Traditional self-supervised learning requires CNNs using external pretext tasks (i.e., image- or video-based tasks) to encode high-level semantic visual representations. In this paper, we show that feature transformations within CNNs can also be regarded as supervisory signals to construct the self-supervised task, called \emph{internal pretext task}. And such a task can be applied for the enhancement of supervised learning. Specifically, we first transform the internal feature maps by discarding different channels, and then define an additional internal pretext task to identify the discarded channels. CNNs are trained to predict the joint labels generated by the combination of self-supervised labels and original labels. By doing so, we let CNNs know which channels are missing while classifying in the hope to mine richer feature information. Extensive experiments show that our approach is effective on various models and datasets. And it's worth noting that we only incur negligible computational overhead. Furthermore, our approach can also be compatible with other methods to get better results.
DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction
May 31, 2021
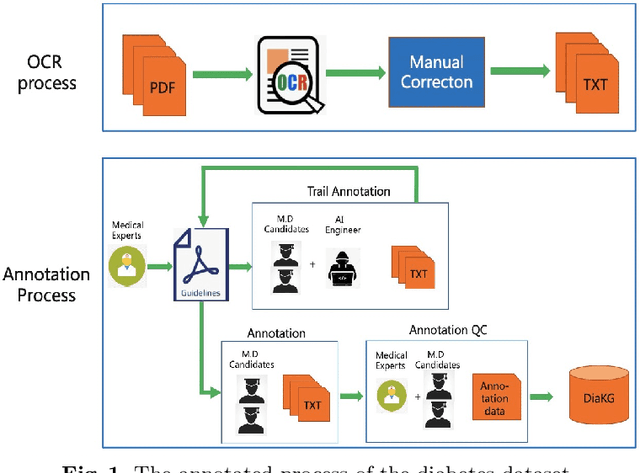

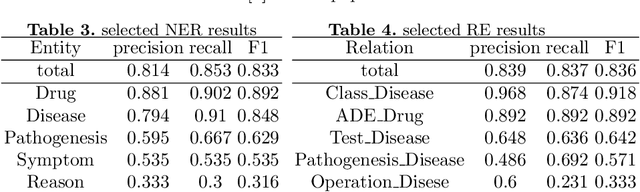
Knowledge Graph has been proven effective in modeling structured information and conceptual knowledge, especially in the medical domain. However, the lack of high-quality annotated corpora remains a crucial problem for advancing the research and applications on this task. In order to accelerate the research for domain-specific knowledge graphs in the medical domain, we introduce DiaKG, a high-quality Chinese dataset for Diabetes knowledge graph, which contains 22,050 entities and 6,890 relations in total. We implement recent typical methods for Named Entity Recognition and Relation Extraction as a benchmark to evaluate the proposed dataset thoroughly. Empirical results show that the DiaKG is challenging for most existing methods and further analysis is conducted to discuss future research direction for improvements. We hope the release of this dataset can assist the construction of diabetes knowledge graphs and facilitate AI-based applications.
Visual communication of object concepts at different levels of abstraction
Jun 05, 2021

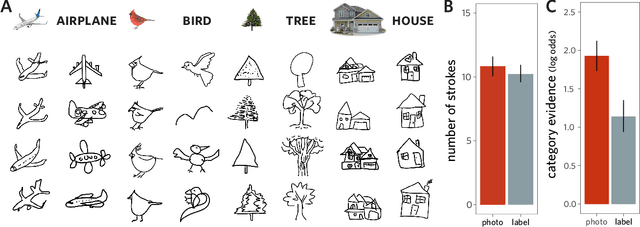
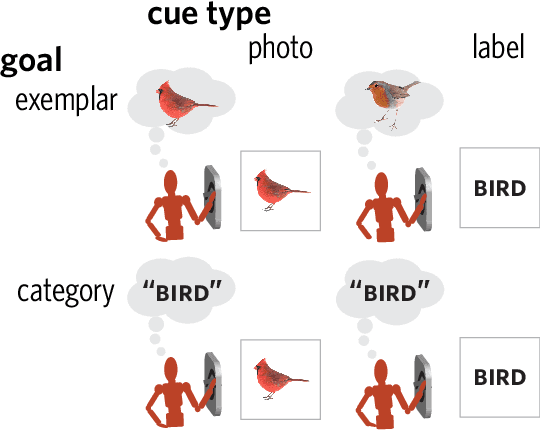
People can produce drawings of specific entities (e.g., Garfield), as well as general categories (e.g., "cat"). What explains this ability to produce such varied drawings of even highly familiar object concepts? We hypothesized that drawing objects at different levels of abstraction depends on both sensory information and representational goals, such that drawings intended to portray a recently seen object preserve more detail than those intended to represent a category. Participants drew objects cued either with a photo or a category label. For each cue type, half the participants aimed to draw a specific exemplar; the other half aimed to draw the category. We found that label-cued category drawings were the most recognizable at the basic level, whereas photo-cued exemplar drawings were the least recognizable. Together, these findings highlight the importance of task context for explaining how people use drawings to communicate visual concepts in different ways.
A method for estimating the entropy of time series using artificial neural network
Jul 18, 2021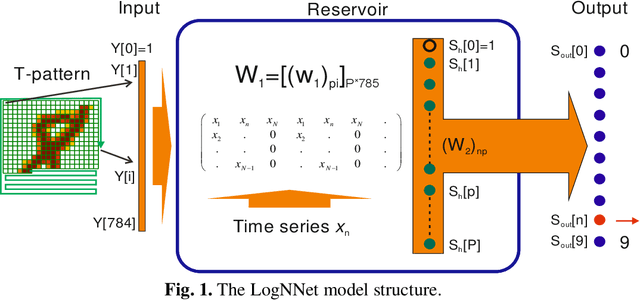
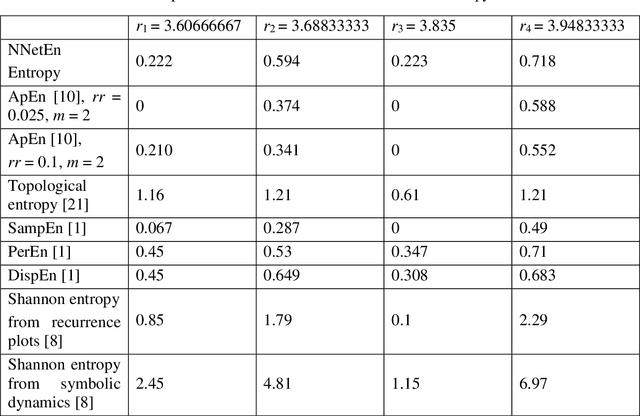
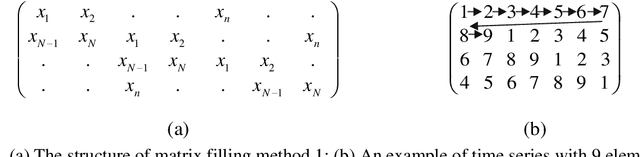
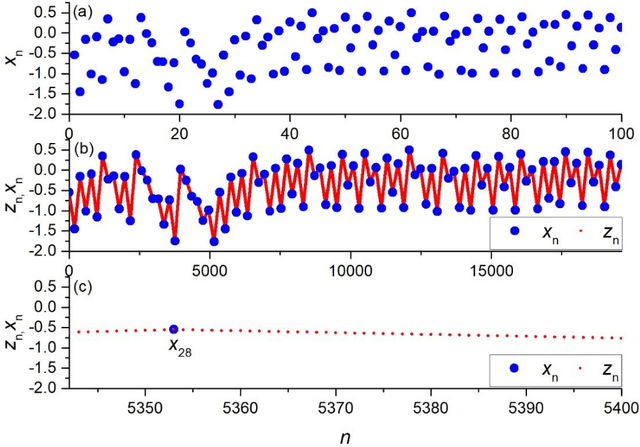
Measuring the predictability and complexity of time series is an essential tool in designing and controlling the nonlinear system. There exist different entropy measures in the literature to analyze the predictability and complexity of time series. However, these measures have some drawbacks especially in short time series. To overcome the difficulties, this paper proposes a new method for estimating the entropy of a time series using the LogNNet 784:25:10 neural network model. The LogNNet reservoir matrix consists of 19625 elements which is filled with the time series elements. After that, the network is trained on MNIST-10 dataset and the classification accuracy is calculated. The accuracy is considered as the entropy measure and denoted by NNetEn. A more complex transformation of the input information by the time series in the reservoir leads to higher NNetEn values. Many practical time series data have less than 19625 elements. Some duplicating or stretching methods are investigated to overcome this difficulty and the most successful method is identified for practical applications. The epochs number in the training process of LogNNet is considered as the input parameter. A new time series characteristic called time series learning inertia is introduced to investigate the effect of epochs number in the efficiency of neural network. To show the robustness and efficiency of the proposed method, it is applied on some chaotic, periodic, random, binary and constant time series. The NNetEn is compared with some existing entropy measures. The results show that the proposed method is more robust and accurate than existing methods.
GraphGen-Redux: a Fast and Lightweight Recurrent Model for labeled Graph Generation
Jul 18, 2021
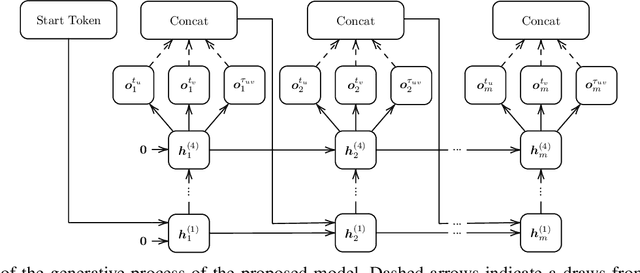
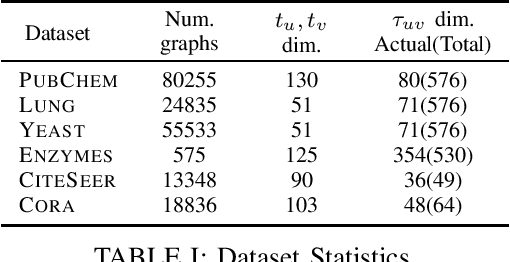
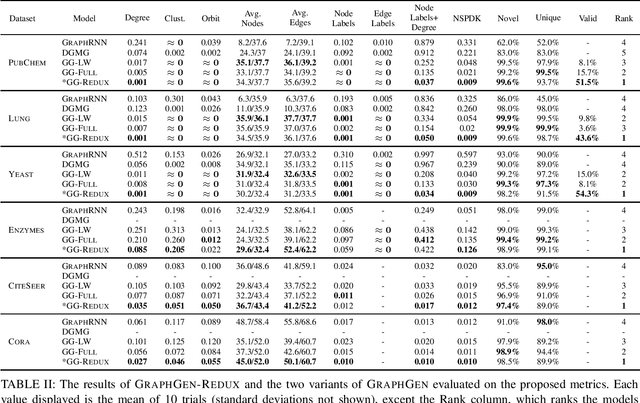
The problem of labeled graph generation is gaining attention in the Deep Learning community. The task is challenging due to the sparse and discrete nature of graph spaces. Several approaches have been proposed in the literature, most of which require to transform the graphs into sequences that encode their structure and labels and to learn the distribution of such sequences through an auto-regressive generative model. Among this family of approaches, we focus on the GraphGen model. The preprocessing phase of GraphGen transforms graphs into unique edge sequences called Depth-First Search (DFS) codes, such that two isomorphic graphs are assigned the same DFS code. Each element of a DFS code is associated with a graph edge: specifically, it is a quintuple comprising one node identifier for each of the two endpoints, their node labels, and the edge label. GraphGen learns to generate such sequences auto-regressively and models the probability of each component of the quintuple independently. While effective, the independence assumption made by the model is too loose to capture the complex label dependencies of real-world graphs precisely. By introducing a novel graph preprocessing approach, we are able to process the labeling information of both nodes and edges jointly. The corresponding model, which we term GraphGen-Redux, improves upon the generative performances of GraphGen in a wide range of datasets of chemical and social graphs. In addition, it uses approximately 78% fewer parameters than the vanilla variant and requires 50% fewer epochs of training on average.
Interaction-Grounded Learning
Jun 09, 2021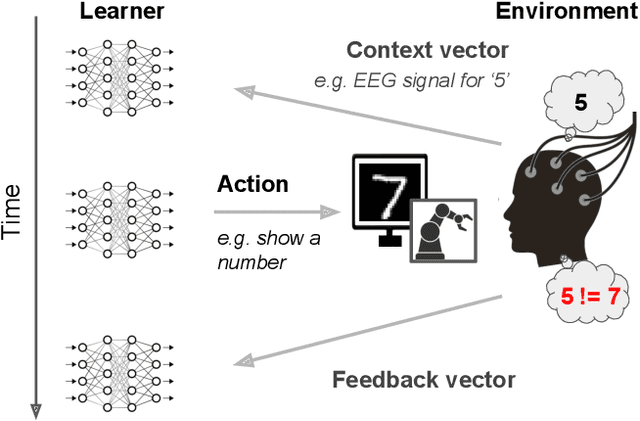
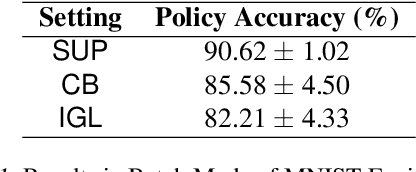

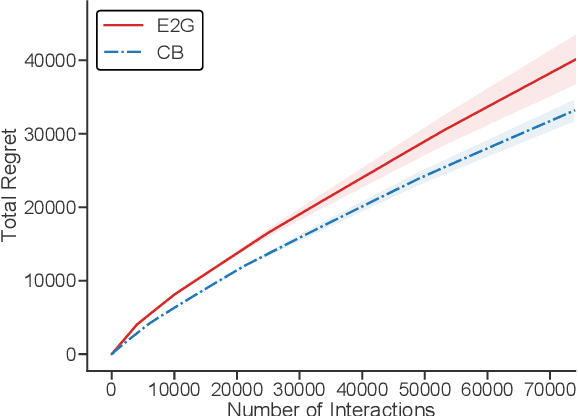
Consider a prosthetic arm, learning to adapt to its user's control signals. We propose Interaction-Grounded Learning for this novel setting, in which a learner's goal is to interact with the environment with no grounding or explicit reward to optimize its policies. Such a problem evades common RL solutions which require an explicit reward. The learning agent observes a multidimensional context vector, takes an action, and then observes a multidimensional feedback vector. This multidimensional feedback vector has no explicit reward information. In order to succeed, the algorithm must learn how to evaluate the feedback vector to discover a latent reward signal, with which it can ground its policies without supervision. We show that in an Interaction-Grounded Learning setting, with certain natural assumptions, a learner can discover the latent reward and ground its policy for successful interaction. We provide theoretical guarantees and a proof-of-concept empirical evaluation to demonstrate the effectiveness of our proposed approach.
Multiple feature fusion-based video face tracking for IoT big data
Apr 15, 2021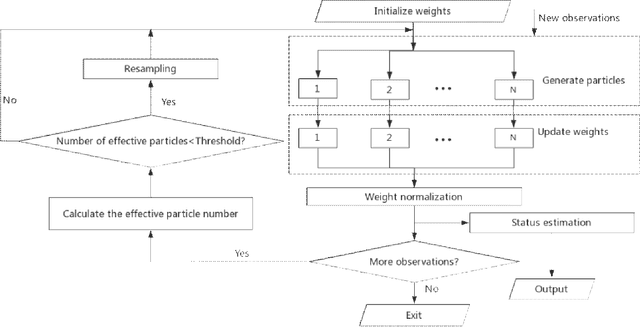

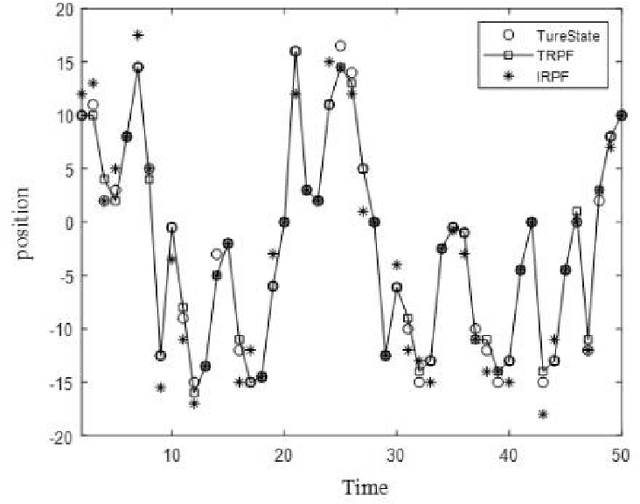

With the advancement of IoT and artificial intelligence technologies, and the need for rapid application growth in fields such as security entrance control and financial business trade, facial information processing has become an important means for achieving identity authentication and information security. In this paper, we propose a multi-feature fusion algorithm based on integral histograms and a real-time update tracking particle filtering module. First, edge and colour features are extracted, weighting methods are used to weight the colour histogram and edge features to describe facial features, and fusion of colour and edge features is made adaptive by using fusion coefficients to improve face tracking reliability. Then, the integral histogram is integrated into the particle filtering algorithm to simplify the calculation steps of complex particles. Finally, the tracking window size is adjusted in real time according to the change in the average distance from the particle centre to the edge of the current model and the initial model to reduce the drift problem and achieve stable tracking with significant changes in the target dimension. The results show that the algorithm improves video tracking accuracy, simplifies particle operation complexity, improves the speed, and has good anti-interference ability and robustness.
Deep Interaction between Masking and Mapping Targets for Single-Channel Speech Enhancement
Jun 09, 2021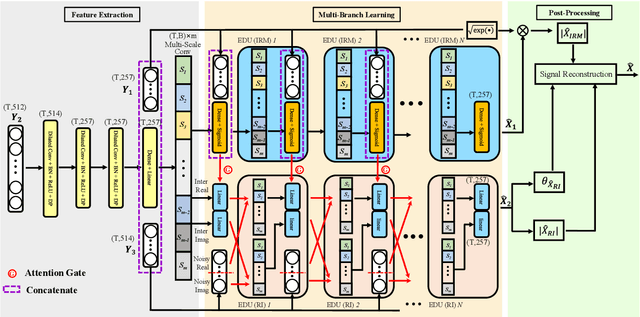
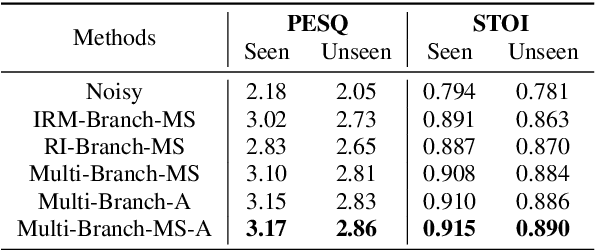
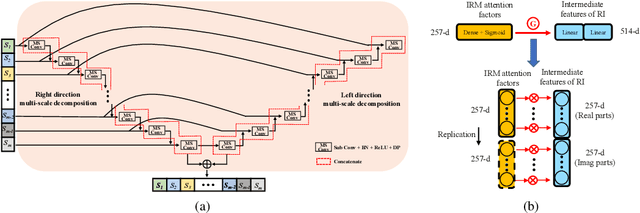
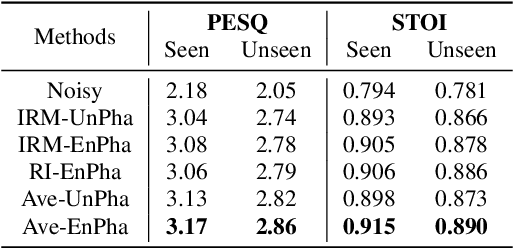
The most recent deep neural network (DNN) models exhibit impressive denoising performance in the time-frequency (T-F) magnitude domain. However, the phase is also a critical component of the speech signal that is easily overlooked. In this paper, we propose a multi-branch dilated convolutional network (DCN) to simultaneously enhance the magnitude and phase of noisy speech. A causal and robust monaural speech enhancement system is achieved based on the multi-objective learning framework of the complex spectrum and the ideal ratio mask (IRM) targets. In the process of joint learning, the intermediate estimation of IRM targets is used as a way of generating feature attention factors to realize the information interaction between the two targets. Moreover, the proposed multi-scale dilated convolution enables the DCN model to have a more efficient temporal modeling capability. Experimental results show that compared with other state-of-the-art models, this model achieves better speech quality and intelligibility with less computation.
Integrating Deep Learning and Augmented Reality to Enhance Situational Awareness in Firefighting Environments
Jul 23, 2021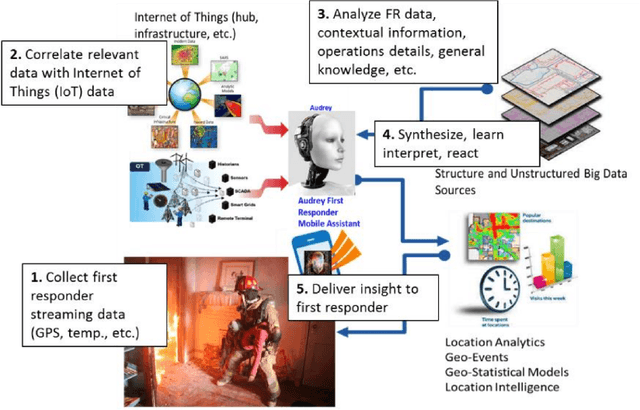
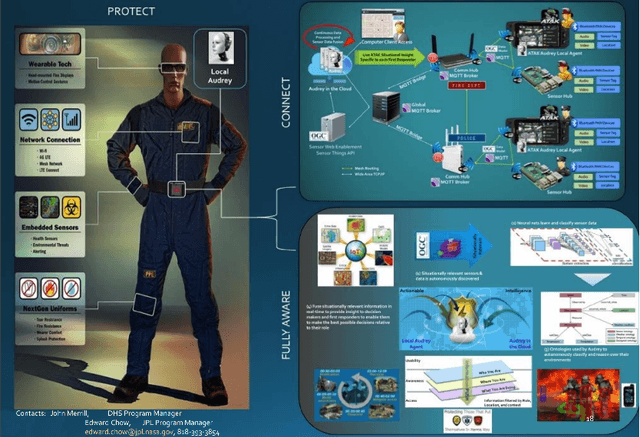
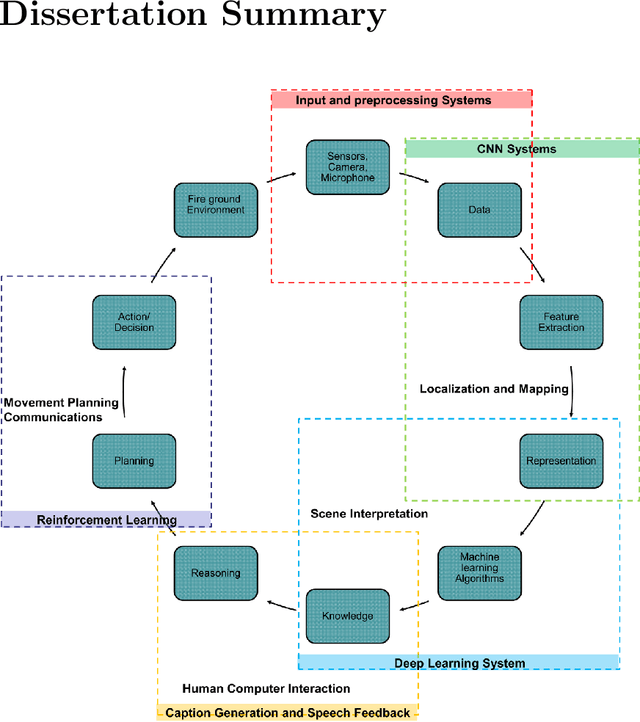
We present a new four-pronged approach to build firefighter's situational awareness for the first time in the literature. We construct a series of deep learning frameworks built on top of one another to enhance the safety, efficiency, and successful completion of rescue missions conducted by firefighters in emergency first response settings. First, we used a deep Convolutional Neural Network (CNN) system to classify and identify objects of interest from thermal imagery in real-time. Next, we extended this CNN framework for object detection, tracking, segmentation with a Mask RCNN framework, and scene description with a multimodal natural language processing(NLP) framework. Third, we built a deep Q-learning-based agent, immune to stress-induced disorientation and anxiety, capable of making clear navigation decisions based on the observed and stored facts in live-fire environments. Finally, we used a low computational unsupervised learning technique called tensor decomposition to perform meaningful feature extraction for anomaly detection in real-time. With these ad-hoc deep learning structures, we built the artificial intelligence system's backbone for firefighters' situational awareness. To bring the designed system into usage by firefighters, we designed a physical structure where the processed results are used as inputs in the creation of an augmented reality capable of advising firefighters of their location and key features around them, which are vital to the rescue operation at hand, as well as a path planning feature that acts as a virtual guide to assist disoriented first responders in getting back to safety. When combined, these four approaches present a novel approach to information understanding, transfer, and synthesis that could dramatically improve firefighter response and efficacy and reduce life loss.
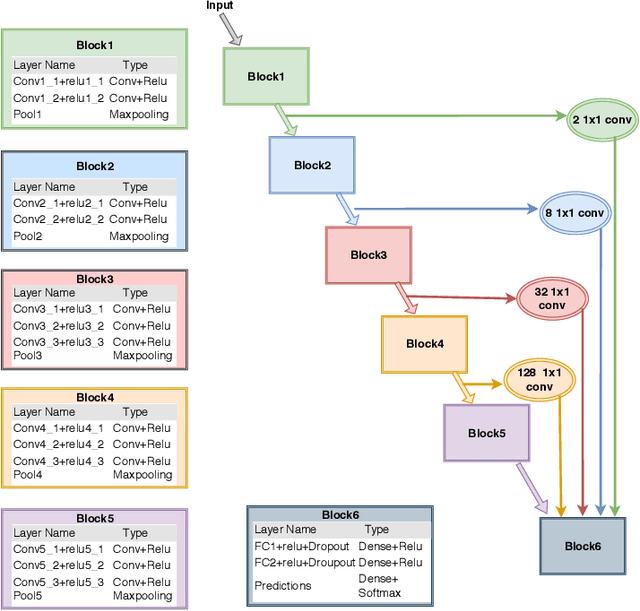
Efficient Human Pose Estimation by Learning Deeply Aggregated Representations
Dec 15, 2020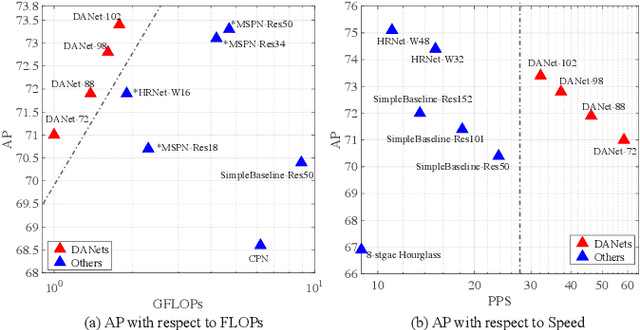
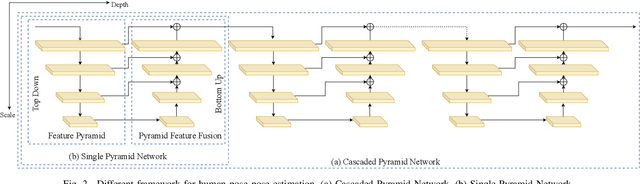
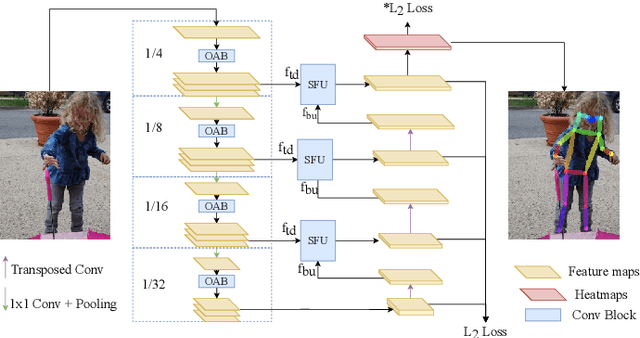
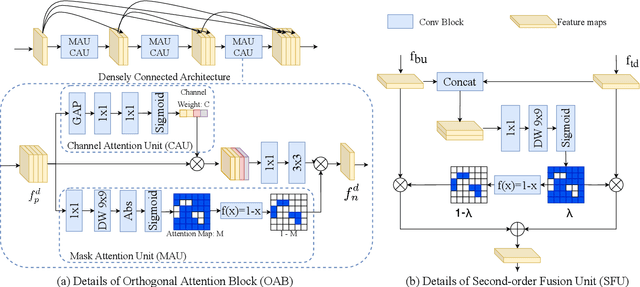
In this paper, we propose an efficient human pose estimation network (DANet) by learning deeply aggregated representations. Most existing models explore multi-scale information mainly from features with different spatial sizes. Powerful multi-scale representations usually rely on the cascaded pyramid framework. This framework largely boosts the performance but in the meanwhile makes networks very deep and complex. Instead, we focus on exploiting multi-scale information from layers with different receptive-field sizes and then making full of use this information by improving the fusion method. Specifically, we propose an orthogonal attention block (OAB) and a second-order fusion unit (SFU). The OAB learns multi-scale information from different layers and enhances them by encouraging them to be diverse. The SFU adaptively selects and fuses diverse multi-scale information and suppress the redundant ones. This could maximize the effective information in final fused representations. With the help of OAB and SFU, our single pyramid network may be able to generate deeply aggregated representations that contain even richer multi-scale information and have a larger representing capacity than that of cascaded networks. Thus, our networks could achieve comparable or even better accuracy with much smaller model complexity. Specifically, our \mbox{DANet-72} achieves $70.5$ in AP score on COCO test-dev set with only $1.0G$ FLOPs. Its speed on a CPU platform achieves $58$ Persons-Per-Second~(PPS).