 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
PoAct: Policy and Action Dual-Control Agent for Generalized Applications
Jan 13, 2025



Based on their superior comprehension and reasoning capabilities, Large Language Model (LLM) driven agent frameworks have achieved significant success in numerous complex reasoning tasks. ReAct-like agents can solve various intricate problems step-by-step through progressive planning and tool calls, iteratively optimizing new steps based on environmental feedback. However, as the planning capabilities of LLMs improve, the actions invoked by tool calls in ReAct-like frameworks often misalign with complex planning and challenging data organization. Code Action addresses these issues while also introducing the challenges of a more complex action space and more difficult action organization. To leverage Code Action and tackle the challenges of its complexity, this paper proposes Policy and Action Dual-Control Agent (PoAct) for generalized applications. The aim is to achieve higher-quality code actions and more accurate reasoning paths by dynamically switching reasoning policies and modifying the action space. Experimental results on the Agent Benchmark for both legal and generic scenarios demonstrate the superior reasoning capabilities and reduced token consumption of our approach in complex tasks. On the LegalAgentBench, our method shows a 20 percent improvement over the baseline while requiring fewer tokens. We conducted experiments and analyses on the GPT-4o and GLM-4 series models, demonstrating the significant potential and scalability of our approach to solve complex problems.
Self-supervision of Feature Transformation for Further Improving Supervised Learning
Jun 09, 2021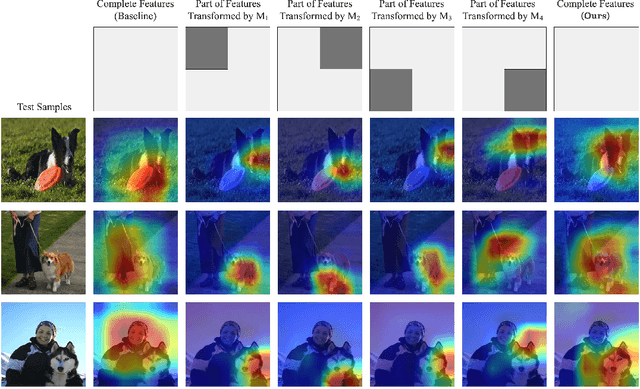

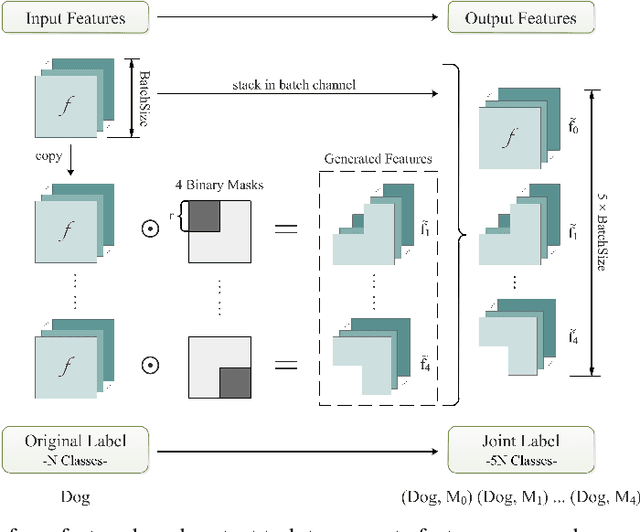

Self-supervised learning, which benefits from automatically constructing labels through pre-designed pretext task, has recently been applied for strengthen supervised learning. Since previous self-supervised pretext tasks are based on input, they may incur huge additional training overhead. In this paper we find that features in CNNs can be also used for self-supervision. Thus we creatively design the \emph{feature-based pretext task} which requires only a small amount of additional training overhead. In our task we discard different particular regions of features, and then train the model to distinguish these different features. In order to fully apply our feature-based pretext task in supervised learning, we also propose a novel learning framework containing multi-classifiers for further improvement. Original labels will be expanded to joint labels via self-supervision of feature transformations. With more semantic information provided by our self-supervised tasks, this approach can train CNNs more effectively. Extensive experiments on various supervised learning tasks demonstrate the accuracy improvement and wide applicability of our method.
Self-supervised Feature Enhancement: Applying Internal Pretext Task to Supervised Learning
Jun 09, 2021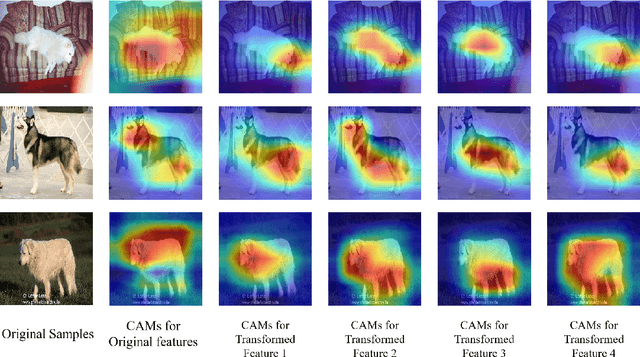
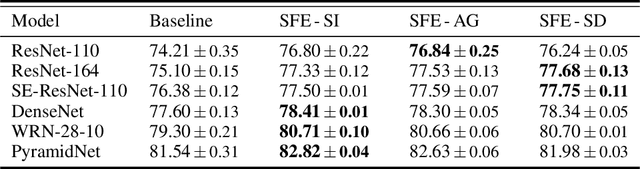
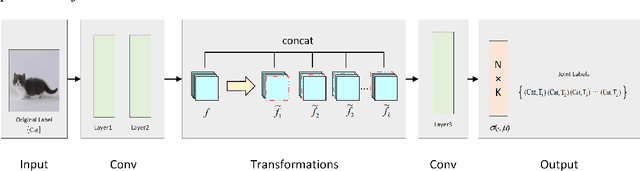

Traditional self-supervised learning requires CNNs using external pretext tasks (i.e., image- or video-based tasks) to encode high-level semantic visual representations. In this paper, we show that feature transformations within CNNs can also be regarded as supervisory signals to construct the self-supervised task, called \emph{internal pretext task}. And such a task can be applied for the enhancement of supervised learning. Specifically, we first transform the internal feature maps by discarding different channels, and then define an additional internal pretext task to identify the discarded channels. CNNs are trained to predict the joint labels generated by the combination of self-supervised labels and original labels. By doing so, we let CNNs know which channels are missing while classifying in the hope to mine richer feature information. Extensive experiments show that our approach is effective on various models and datasets. And it's worth noting that we only incur negligible computational overhead. Furthermore, our approach can also be compatible with other methods to get better results.