 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenTSE: Enhancing Target Speaker Extraction via a Coarse-to-Fine Generative Language Model
Dec 24, 2025Language Model (LM)-based generative modeling has emerged as a promising direction for TSE, offering potential for improved generalization and high-fidelity speech. We present GenTSE, a two-stage decoder-only generative LM approach for TSE: Stage-1 predicts coarse semantic tokens, and Stage-2 generates fine acoustic tokens. Separating semantics and acoustics stabilizes decoding and yields more faithful, content-aligned target speech. Both stages use continuous SSL or codec embeddings, offering richer context than discretized-prompt methods. To reduce exposure bias, we employ a Frozen-LM Conditioning training strategy that conditions the LMs on predicted tokens from earlier checkpoints to reduce the gap between teacher-forcing training and autoregressive inference. We further employ DPO to better align outputs with human perceptual preferences. Experiments on Libri2Mix show that GenTSE surpasses previous LM-based systems in speech quality, intelligibility, and speaker consistency.
FB-MSTCN: A Full-Band Single-Channel Speech Enhancement Method Based on Multi-Scale Temporal Convolutional Network
Mar 15, 2022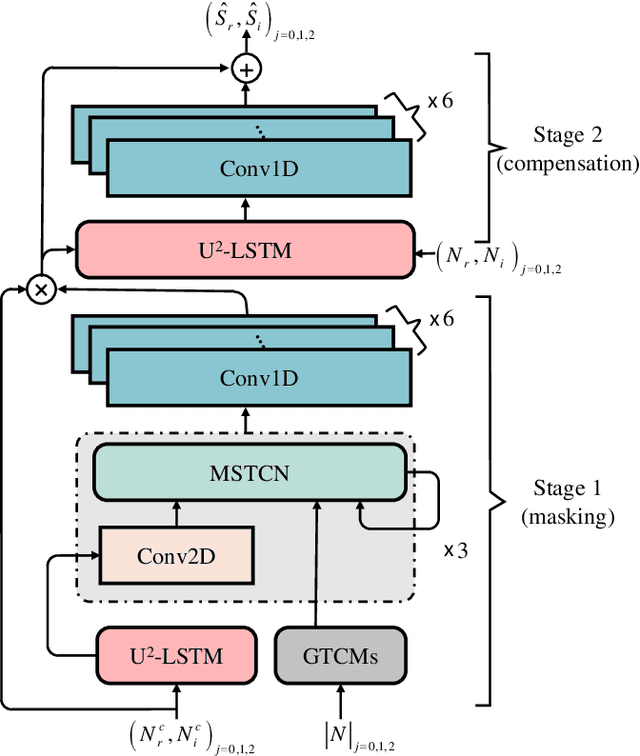
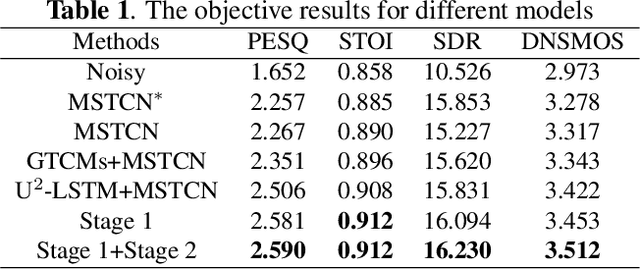
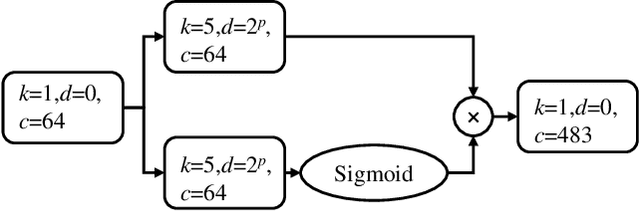
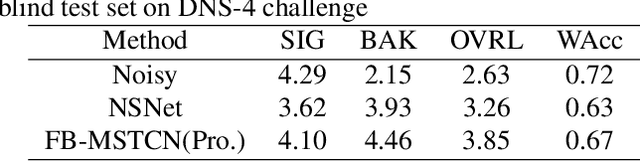
In recent years, deep learning-based approaches have significantly improved the performance of single-channel speech enhancement. However, due to the limitation of training data and computational complexity, real-time enhancement of full-band (48 kHz) speech signals is still very challenging. Because of the low energy of spectral information in the high-frequency part, it is more difficult to directly model and enhance the full-band spectrum using neural networks. To solve this problem, this paper proposes a two-stage real-time speech enhancement model with extraction-interpolation mechanism for a full-band signal. The 48 kHz full-band time-domain signal is divided into three sub-channels by extracting, and a two-stage processing scheme of `masking + compensation' is proposed to enhance the signal in the complex domain. After the two-stage enhancement, the enhanced full-band speech signal is restored by interval interpolation. In the subjective listening and word accuracy test, our proposed model achieves superior performance and outperforms the baseline model overall by 0.59 MOS and 4.0% WAcc for the non-personalized speech denoising task.
Incorporating Multi-Target in Multi-Stage Speech Enhancement Model for Better Generalization
Jul 09, 2021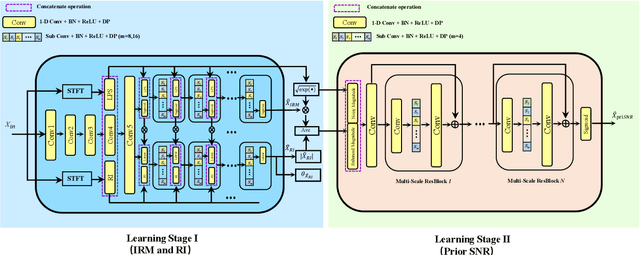
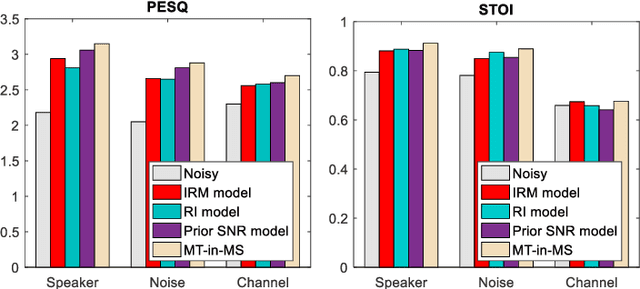
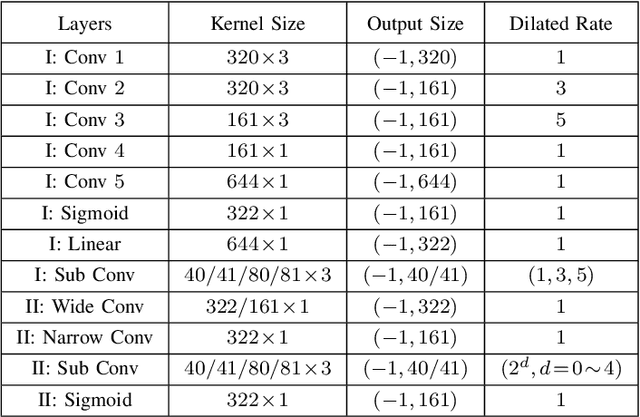
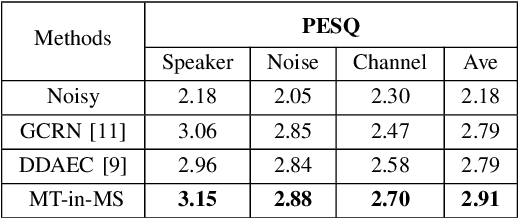
Recent single-channel speech enhancement methods based on deep neural networks (DNNs) have achieved remarkable results, but there are still generalization problems in real scenes. Like other data-driven methods, DNN-based speech enhancement models produce significant performance degradation on untrained data. In this study, we make full use of the contribution of multi-target joint learning to the model generalization capability, and propose a lightweight and low-computing dilated convolutional network (DCN) model for a more robust speech denoising task. Our goal is to integrate the masking target, the mapping target, and the parameters of the traditional speech enhancement estimator into a DCN model to maximize their complementary advantages. To do this, we build a multi-stage learning framework to deal with multiple targets in stages to achieve their joint learning, namely `MT-in-MS'. Our experimental results show that compared with the state-of-the-art time domain and time-frequency domain models, this proposed low-cost DCN model can achieve better generalization performance in speaker, noise, and channel mismatch cases.
Deep Interaction between Masking and Mapping Targets for Single-Channel Speech Enhancement
Jun 09, 2021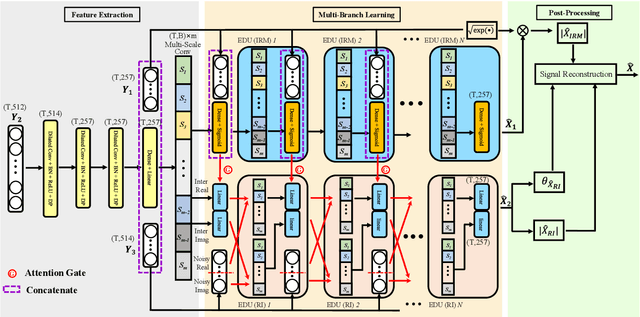
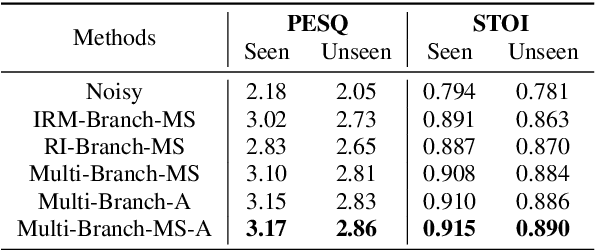
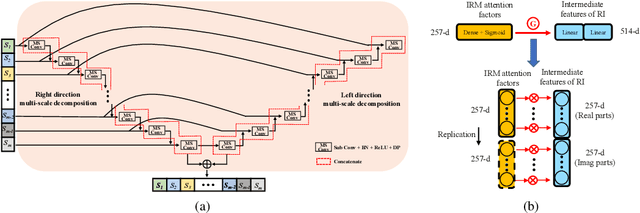
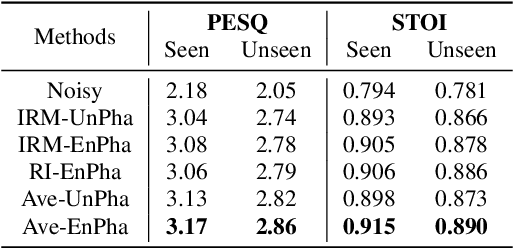
The most recent deep neural network (DNN) models exhibit impressive denoising performance in the time-frequency (T-F) magnitude domain. However, the phase is also a critical component of the speech signal that is easily overlooked. In this paper, we propose a multi-branch dilated convolutional network (DCN) to simultaneously enhance the magnitude and phase of noisy speech. A causal and robust monaural speech enhancement system is achieved based on the multi-objective learning framework of the complex spectrum and the ideal ratio mask (IRM) targets. In the process of joint learning, the intermediate estimation of IRM targets is used as a way of generating feature attention factors to realize the information interaction between the two targets. Moreover, the proposed multi-scale dilated convolution enables the DCN model to have a more efficient temporal modeling capability. Experimental results show that compared with other state-of-the-art models, this model achieves better speech quality and intelligibility with less computation.