 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHART-6: Human-Centered Evaluation of Data Visualization Understanding in Vision-Language Models
May 22, 2025Data visualizations are powerful tools for communicating patterns in quantitative data. Yet understanding any data visualization is no small feat -- succeeding requires jointly making sense of visual, numerical, and linguistic inputs arranged in a conventionalized format one has previously learned to parse. Recently developed vision-language models are, in principle, promising candidates for developing computational models of these cognitive operations. However, it is currently unclear to what degree these models emulate human behavior on tasks that involve reasoning about data visualizations. This gap reflects limitations in prior work that has evaluated data visualization understanding in artificial systems using measures that differ from those typically used to assess these abilities in humans. Here we evaluated eight vision-language models on six data visualization literacy assessments designed for humans and compared model responses to those of human participants. We found that these models performed worse than human participants on average, and this performance gap persisted even when using relatively lenient criteria to assess model performance. Moreover, while relative performance across items was somewhat correlated between models and humans, all models produced patterns of errors that were reliably distinct from those produced by human participants. Taken together, these findings suggest significant opportunities for further development of artificial systems that might serve as useful models of how humans reason about data visualizations. All code and data needed to reproduce these results are available at: https://osf.io/e25mu/?view_only=399daff5a14d4b16b09473cf19043f18.
mrCAD: Multimodal Refinement of Computer-aided Designs
Apr 28, 2025



A key feature of human collaboration is the ability to iteratively refine the concepts we have communicated. In contrast, while generative AI excels at the \textit{generation} of content, it often struggles to make specific language-guided \textit{modifications} of its prior outputs. To bridge the gap between how humans and machines perform edits, we present mrCAD, a dataset of multimodal instructions in a communication game. In each game, players created computer aided designs (CADs) and refined them over several rounds to match specific target designs. Only one player, the Designer, could see the target, and they must instruct the other player, the Maker, using text, drawing, or a combination of modalities. mrCAD consists of 6,082 communication games, 15,163 instruction-execution rounds, played between 1,092 pairs of human players. We analyze the dataset and find that generation and refinement instructions differ in their composition of drawing and text. Using the mrCAD task as a benchmark, we find that state-of-the-art VLMs are better at following generation instructions than refinement instructions. These results lay a foundation for analyzing and modeling a multimodal language of refinement that is not represented in previous datasets.
Counterfactual World Modeling for Physical Dynamics Understanding
Dec 26, 2023



The ability to understand physical dynamics is essential to learning agents acting in the world. This paper presents Counterfactual World Modeling (CWM), a candidate pure vision foundational model for physical dynamics understanding. CWM consists of three basic concepts. First, we propose a simple and powerful temporally-factored masking policy for masked prediction of video data, which encourages the model to learn disentangled representations of scene appearance and dynamics. Second, as a result of the factoring, CWM is capable of generating counterfactual next-frame predictions by manipulating a few patch embeddings to exert meaningful control over scene dynamics. Third, the counterfactual modeling capability enables the design of counterfactual queries to extract vision structures similar to keypoints, optical flows, and segmentations, which are useful for dynamics understanding. We show that zero-shot readouts of these structures extracted by the counterfactual queries attain competitive performance to prior methods on real-world datasets. Finally, we demonstrate that CWM achieves state-of-the-art performance on the challenging Physion benchmark for evaluating physical dynamics understanding.
SEVA: Leveraging sketches to evaluate alignment between human and machine visual abstraction
Dec 05, 2023



Sketching is a powerful tool for creating abstract images that are sparse but meaningful. Sketch understanding poses fundamental challenges for general-purpose vision algorithms because it requires robustness to the sparsity of sketches relative to natural visual inputs and because it demands tolerance for semantic ambiguity, as sketches can reliably evoke multiple meanings. While current vision algorithms have achieved high performance on a variety of visual tasks, it remains unclear to what extent they understand sketches in a human-like way. Here we introduce SEVA, a new benchmark dataset containing approximately 90K human-generated sketches of 128 object concepts produced under different time constraints, and thus systematically varying in sparsity. We evaluated a suite of state-of-the-art vision algorithms on their ability to correctly identify the target concept depicted in these sketches and to generate responses that are strongly aligned with human response patterns on the same sketch recognition task. We found that vision algorithms that better predicted human sketch recognition performance also better approximated human uncertainty about sketch meaning, but there remains a sizable gap between model and human response patterns. To explore the potential of models that emulate human visual abstraction in generative tasks, we conducted further evaluations of a recently developed sketch generation algorithm (Vinker et al., 2022) capable of generating sketches that vary in sparsity. We hope that public release of this dataset and evaluation protocol will catalyze progress towards algorithms with enhanced capacities for human-like visual abstraction.
Identifying concept libraries from language about object structure
May 11, 2022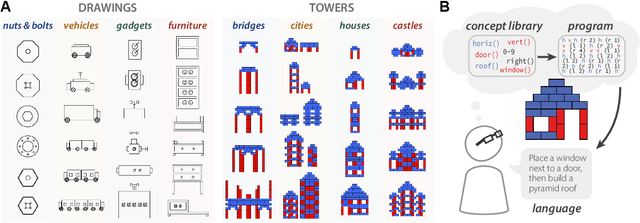
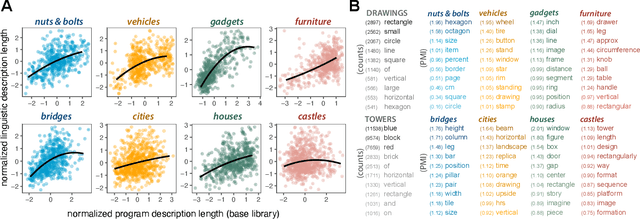
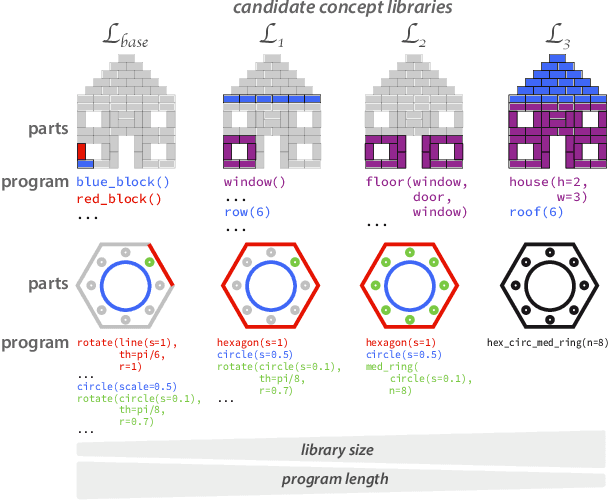
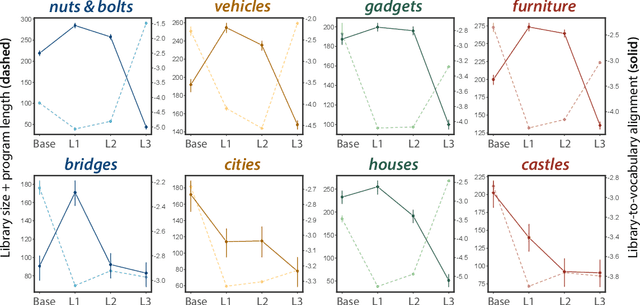
Our understanding of the visual world goes beyond naming objects, encompassing our ability to parse objects into meaningful parts, attributes, and relations. In this work, we leverage natural language descriptions for a diverse set of 2K procedurally generated objects to identify the parts people use and the principles leading these parts to be favored over others. We formalize our problem as search over a space of program libraries that contain different part concepts, using tools from machine translation to evaluate how well programs expressed in each library align to human language. By combining naturalistic language at scale with structured program representations, we discover a fundamental information-theoretic tradeoff governing the part concepts people name: people favor a lexicon that allows concise descriptions of each object, while also minimizing the size of the lexicon itself.
Visual resemblance and communicative context constrain the emergence of graphical conventions
Sep 17, 2021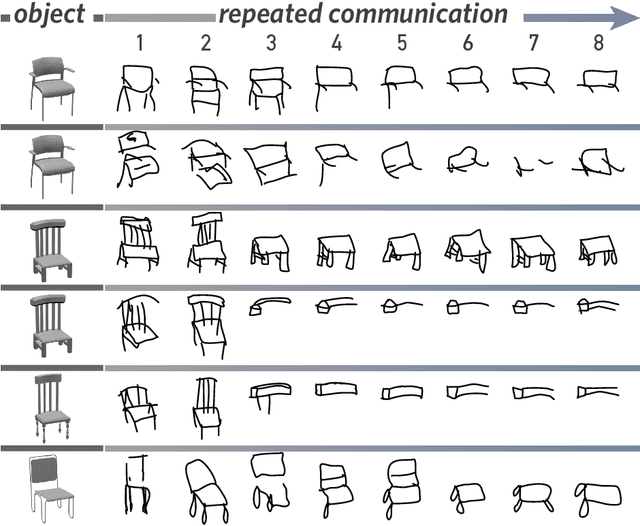
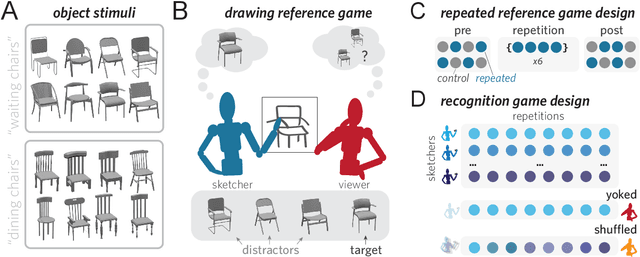
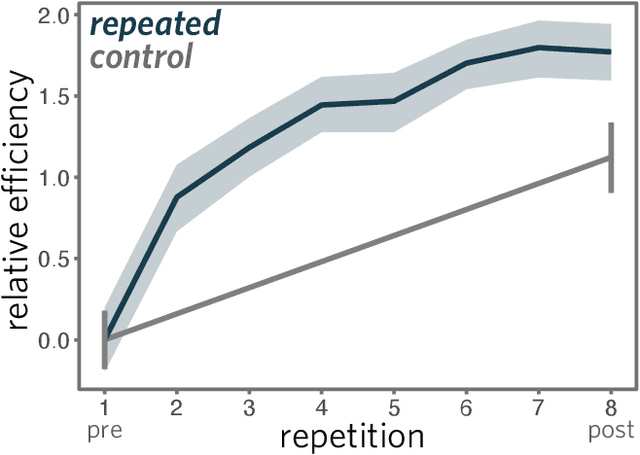
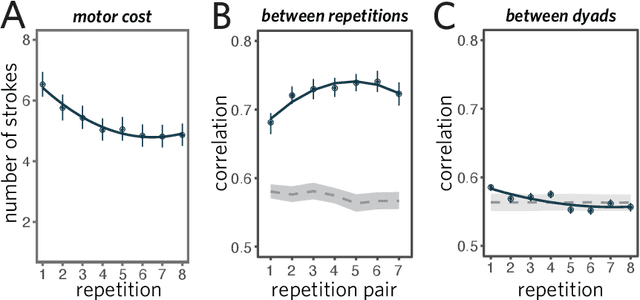
From photorealistic sketches to schematic diagrams, drawing provides a versatile medium for communicating about the visual world. How do images spanning such a broad range of appearances reliably convey meaning? Do viewers understand drawings based solely on their ability to resemble the entities they refer to (i.e., as images), or do they understand drawings based on shared but arbitrary associations with these entities (i.e., as symbols)? In this paper, we provide evidence for a cognitive account of pictorial meaning in which both visual and social information is integrated to support effective visual communication. To evaluate this account, we used a communication task where pairs of participants used drawings to repeatedly communicate the identity of a target object among multiple distractor objects. We manipulated social cues across three experiments and a full internal replication, finding pairs of participants develop referent-specific and interaction-specific strategies for communicating more efficiently over time, going beyond what could be explained by either task practice or a pure resemblance-based account alone. Using a combination of model-based image analyses and crowdsourced sketch annotations, we further determined that drawings did not drift toward arbitrariness, as predicted by a pure convention-based account, but systematically preserved those visual features that were most distinctive of the target object. Taken together, these findings advance theories of pictorial meaning and have implications for how successful graphical conventions emerge via complex interactions between visual perception, communicative experience, and social context.
Learning to communicate about shared procedural abstractions
Jun 30, 2021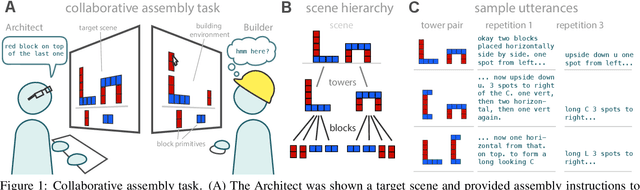
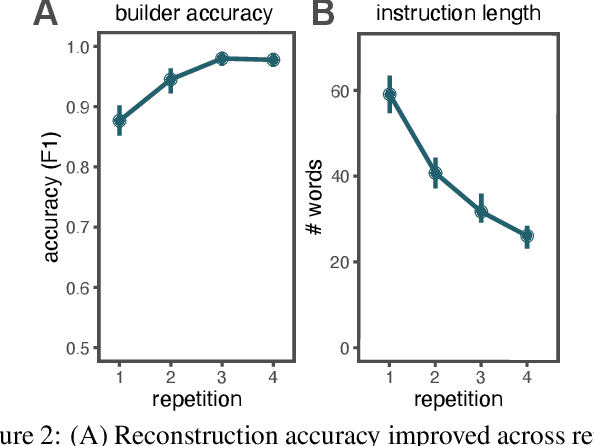
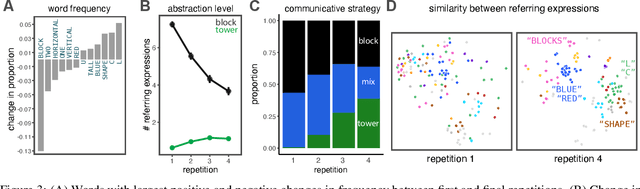
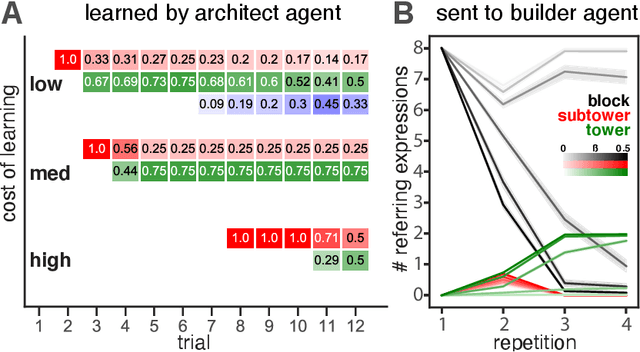
Many real-world tasks require agents to coordinate their behavior to achieve shared goals. Successful collaboration requires not only adopting the same communicative conventions, but also grounding these conventions in the same task-appropriate conceptual abstractions. We investigate how humans use natural language to collaboratively solve physical assembly problems more effectively over time. Human participants were paired up in an online environment to reconstruct scenes containing two block towers. One participant could see the target towers, and sent assembly instructions for the other participant to reconstruct. Participants provided increasingly concise instructions across repeated attempts on each pair of towers, using higher-level referring expressions that captured each scene's hierarchical structure. To explain these findings, we extend recent probabilistic models of ad-hoc convention formation with an explicit perceptual learning mechanism. These results shed light on the inductive biases that enable intelligent agents to coordinate upon shared procedural abstractions.
Physion: Evaluating Physical Prediction from Vision in Humans and Machines
Jun 17, 2021
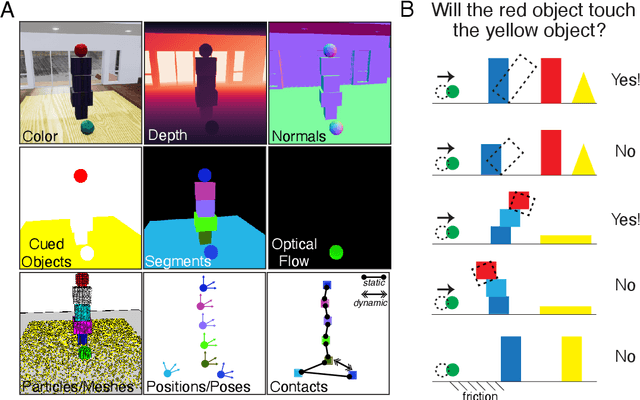
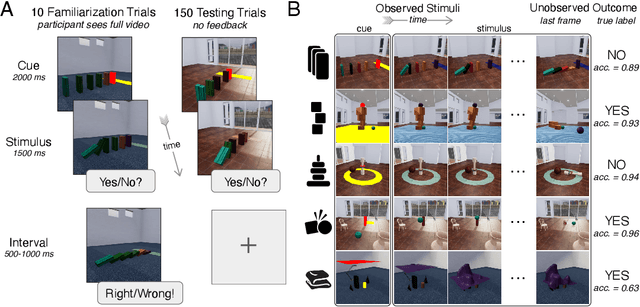
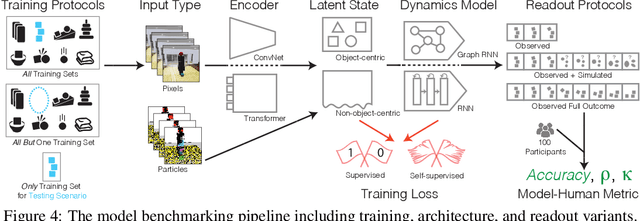
While machine learning algorithms excel at many challenging visual tasks, it is unclear that they can make predictions about commonplace real world physical events. Here, we present a visual and physical prediction benchmark that precisely measures this capability. In realistically simulating a wide variety of physical phenomena -- rigid and soft-body collisions, stable multi-object configurations, rolling and sliding, projectile motion -- our dataset presents a more comprehensive challenge than existing benchmarks. Moreover, we have collected human responses for our stimuli so that model predictions can be directly compared to human judgments. We compare an array of algorithms -- varying in their architecture, learning objective, input-output structure, and training data -- on their ability to make diverse physical predictions. We find that graph neural networks with access to the physical state best capture human behavior, whereas among models that receive only visual input, those with object-centric representations or pretraining do best but fall far short of human accuracy. This suggests that extracting physically meaningful representations of scenes is the main bottleneck to achieving human-like visual prediction. We thus demonstrate how our benchmark can identify areas for improvement and measure progress on this key aspect of physical understanding.
Visual communication of object concepts at different levels of abstraction
Jun 05, 2021

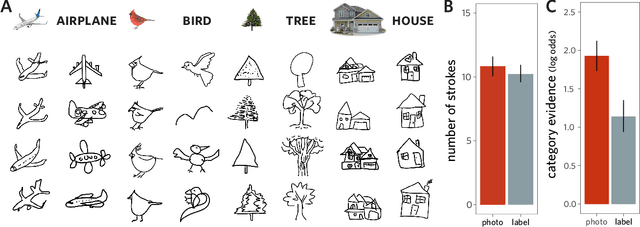
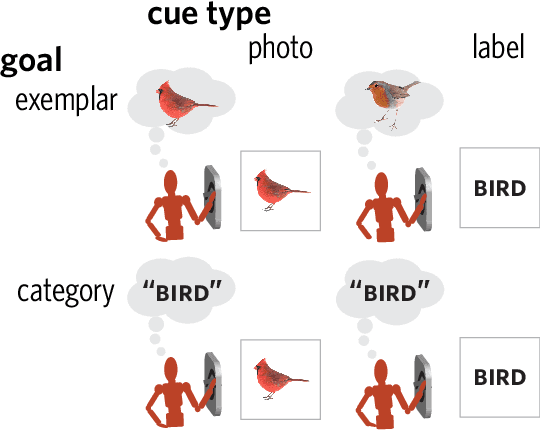
People can produce drawings of specific entities (e.g., Garfield), as well as general categories (e.g., "cat"). What explains this ability to produce such varied drawings of even highly familiar object concepts? We hypothesized that drawing objects at different levels of abstraction depends on both sensory information and representational goals, such that drawings intended to portray a recently seen object preserve more detail than those intended to represent a category. Participants drew objects cued either with a photo or a category label. For each cue type, half the participants aimed to draw a specific exemplar; the other half aimed to draw the category. We found that label-cued category drawings were the most recognizable at the basic level, whereas photo-cued exemplar drawings were the least recognizable. Together, these findings highlight the importance of task context for explaining how people use drawings to communicate visual concepts in different ways.