 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reducing the dilution: An analysis of the information sensitiveness of capsule network with a practical solution
Mar 27, 2019

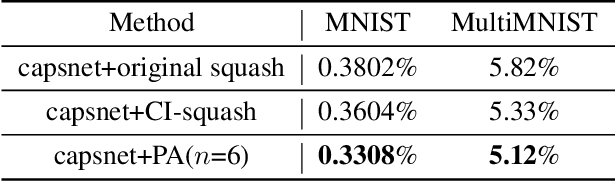

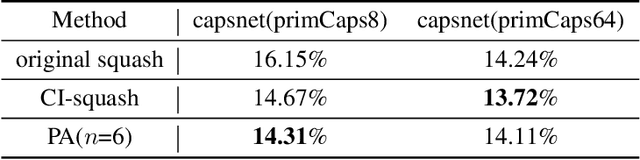
Capsule network has shown various advantages over convolutional neural network (CNN). It keeps more precise spatial information than CNN and uses equivariance instead of invariance during inference and highly potential to be a new effective tool for visual tasks. However, the current capsule networks have incompatible performance with CNN when facing datasets with background and complex target objects and are lacking in universal and efficient regularization method. We analyze the main reason of the incompatible performance as the conflict between information sensitiveness of capsule network and unreasonably higher activation value distribution of capsules in primary capsule layer. Correspondingly, we propose sparsified capsule network by sparsifying and restraining the activation value of capsules in primary capsule layer to suppress non-informative capsules and highlight discriminative capsules. In the experiments, the sparsified capsule network has achieved better performances on various mainstream datasets. In addition, the proposed sparsifying methods can be seen as a suitable, simple and efficient regularization method that can be generally used in capsule network.
Parallelizing Thompson Sampling
Jun 02, 2021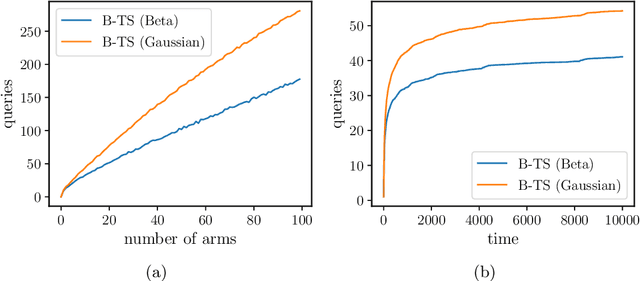
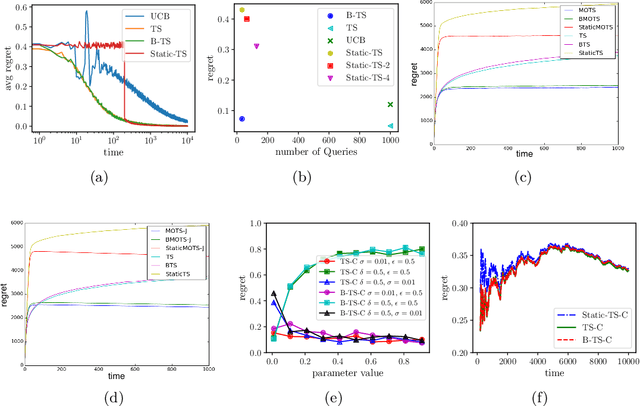
How can we make use of information parallelism in online decision making problems while efficiently balancing the exploration-exploitation trade-off? In this paper, we introduce a batch Thompson Sampling framework for two canonical online decision making problems, namely, stochastic multi-arm bandit and linear contextual bandit with finitely many arms. Over a time horizon $T$, our \textit{batch} Thompson Sampling policy achieves the same (asymptotic) regret bound of a fully sequential one while carrying out only $O(\log T)$ batch queries. To achieve this exponential reduction, i.e., reducing the number of interactions from $T$ to $O(\log T)$, our batch policy dynamically determines the duration of each batch in order to balance the exploration-exploitation trade-off. We also demonstrate experimentally that dynamic batch allocation dramatically outperforms natural baselines such as static batch allocations.
supervised adptive threshold network for instance segmentation
Jun 07, 2021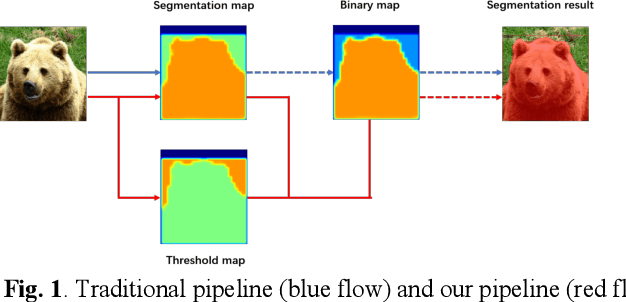
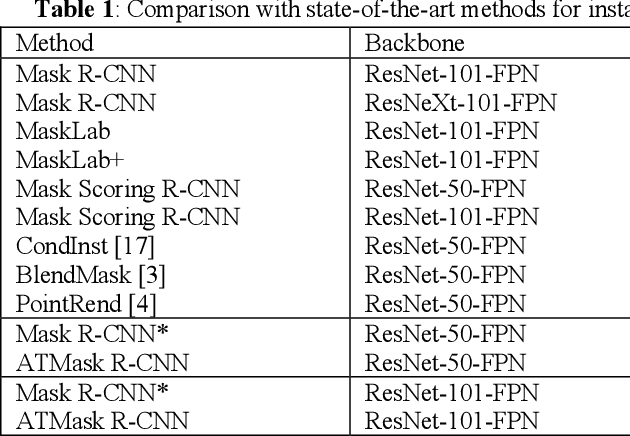

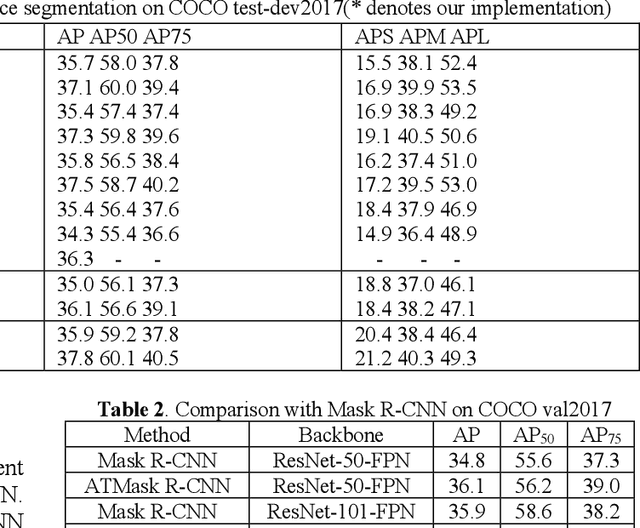
Currently, instance segmentation is attracting more and more attention in machine learning region. However, there exists some defects on the information propagation in previous Mask R-CNN and other network models. In this paper, we propose supervised adaptive threshold network for instance segmentation. Specifically, we adopt the Mask R-CNN method based on adaptive threshold, and by establishing a layered adaptive network structure, it performs adaptive binarization on the probability graph generated by Mask RCNN to obtain better segmentation effect and reduce the error rate. At the same time, an adaptive feature pool is designed to make the transmission between different layers of the network more accurate and effective, reduce the loss in the process of feature transmission, and further improve the mask method. Experiments on benchmark data sets indicate that the effectiveness of the proposed model
U-GAT: Multimodal Graph Attention Network for COVID-19 Outcome Prediction
Jul 29, 2021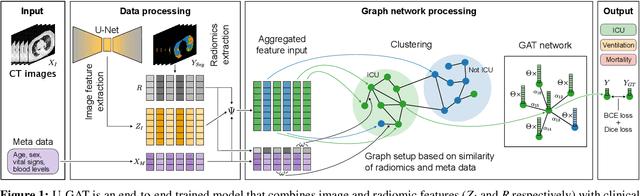
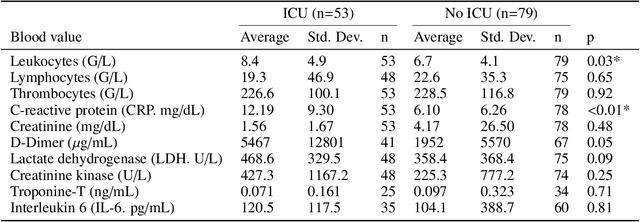
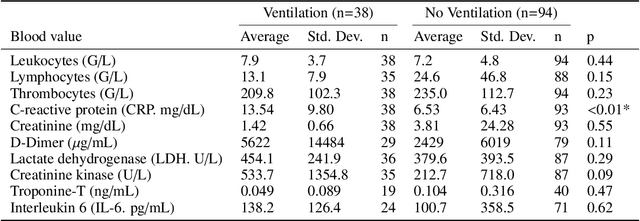
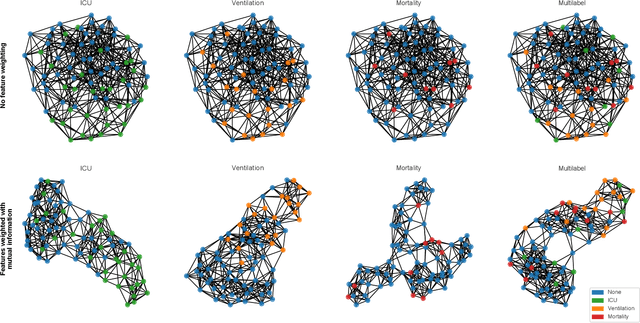
During the first wave of COVID-19, hospitals were overwhelmed with the high number of admitted patients. An accurate prediction of the most likely individual disease progression can improve the planning of limited resources and finding the optimal treatment for patients. However, when dealing with a newly emerging disease such as COVID-19, the impact of patient- and disease-specific factors (e.g. body weight or known co-morbidities) on the immediate course of disease is by and large unknown. In the case of COVID-19, the need for intensive care unit (ICU) admission of pneumonia patients is often determined only by acute indicators such as vital signs (e.g. breathing rate, blood oxygen levels), whereas statistical analysis and decision support systems that integrate all of the available data could enable an earlier prognosis. To this end, we propose a holistic graph-based approach combining both imaging and non-imaging information. Specifically, we introduce a multimodal similarity metric to build a population graph for clustering patients and an image-based end-to-end Graph Attention Network to process this graph and predict the COVID-19 patient outcomes: admission to ICU, need for ventilation and mortality. Additionally, the network segments chest CT images as an auxiliary task and extracts image features and radiomics for feature fusion with the available metadata. Results on a dataset collected in Klinikum rechts der Isar in Munich, Germany show that our approach outperforms single modality and non-graph baselines. Moreover, our clustering and graph attention allow for increased understanding of the patient relationships within the population graph and provide insight into the network's decision-making process.
Knowledge Graph Embedding using Graph Convolutional Networks with Relation-Aware Attention
Feb 14, 2021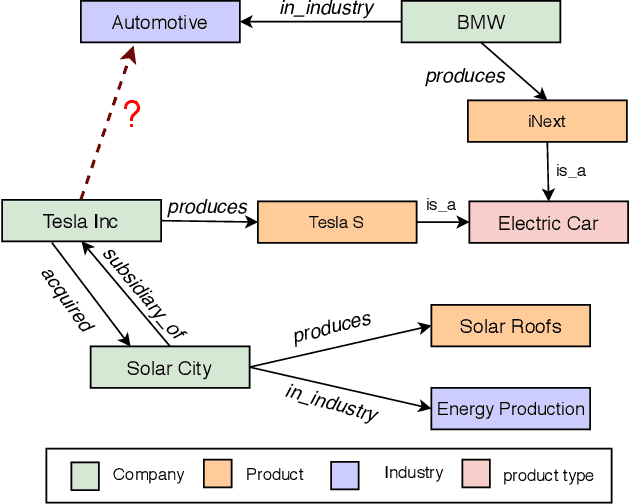
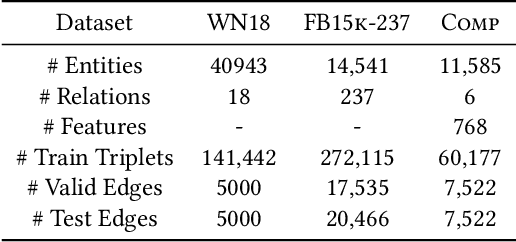
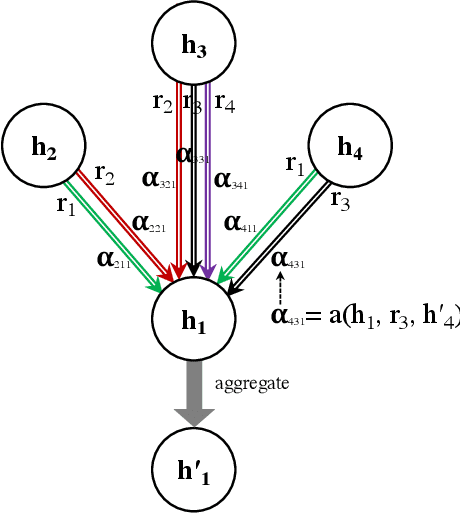
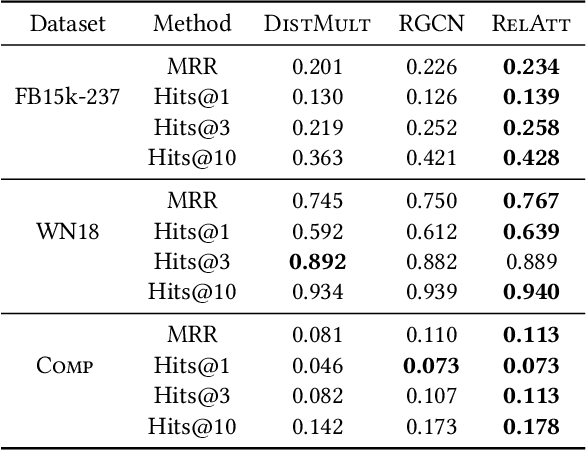
Knowledge graph embedding methods learn embeddings of entities and relations in a low dimensional space which can be used for various downstream machine learning tasks such as link prediction and entity matching. Various graph convolutional network methods have been proposed which use different types of information to learn the features of entities and relations. However, these methods assign the same weight (importance) to the neighbors when aggregating the information, ignoring the role of different relations with the neighboring entities. To this end, we propose a relation-aware graph attention model that leverages relation information to compute different weights to the neighboring nodes for learning embeddings of entities and relations. We evaluate our proposed approach on link prediction and entity matching tasks. Our experimental results on link prediction on three datasets (one proprietary and two public) and results on unsupervised entity matching on one proprietary dataset demonstrate the effectiveness of the relation-aware attention.
VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis
Jul 07, 2021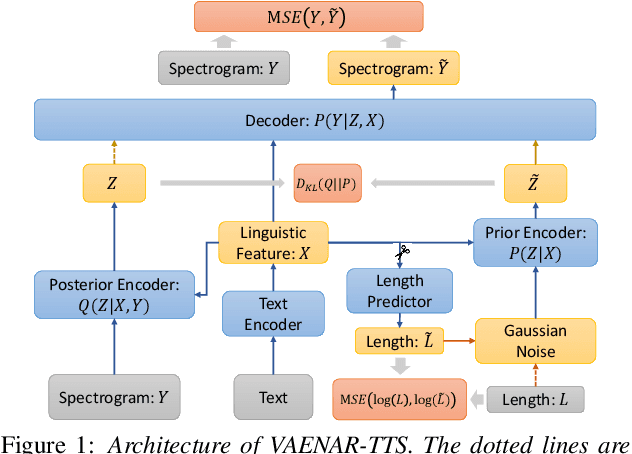
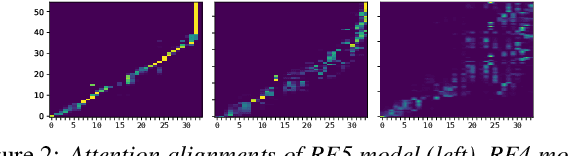
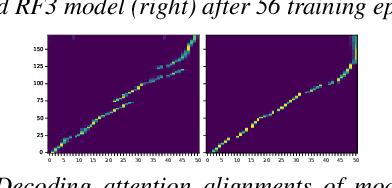
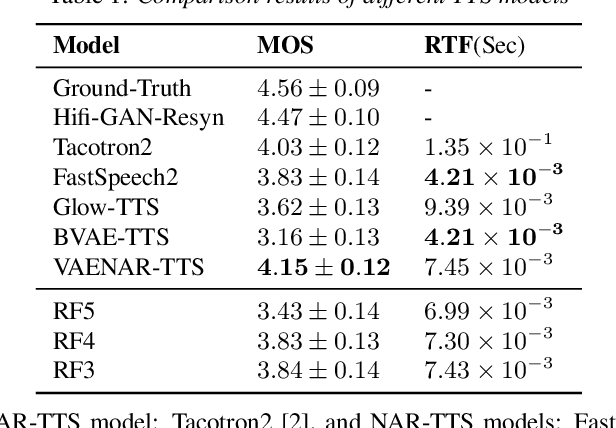
This paper describes a variational auto-encoder based non-autoregressive text-to-speech (VAENAR-TTS) model. The autoregressive TTS (AR-TTS) models based on the sequence-to-sequence architecture can generate high-quality speech, but their sequential decoding process can be time-consuming. Recently, non-autoregressive TTS (NAR-TTS) models have been shown to be more efficient with the parallel decoding process. However, these NAR-TTS models rely on phoneme-level durations to generate a hard alignment between the text and the spectrogram. Obtaining duration labels, either through forced alignment or knowledge distillation, is cumbersome. Furthermore, hard alignment based on phoneme expansion can degrade the naturalness of the synthesized speech. In contrast, the proposed model of VAENAR-TTS is an end-to-end approach that does not require phoneme-level durations. The VAENAR-TTS model does not contain recurrent structures and is completely non-autoregressive in both the training and inference phases. Based on the VAE architecture, the alignment information is encoded in the latent variable, and attention-based soft alignment between the text and the latent variable is used in the decoder to reconstruct the spectrogram. Experiments show that VAENAR-TTS achieves state-of-the-art synthesis quality, while the synthesis speed is comparable with other NAR-TTS models.
Fundamental Limits of Reinforcement Learning in Environment with Endogeneous and Exogeneous Uncertainty
Jun 15, 2021Online reinforcement learning (RL) has been widely applied in information processing scenarios, which usually exhibit much uncertainty due to the intrinsic randomness of channels and service demands. In this paper, we consider an un-discounted RL in general Markov decision processes (MDPs) with both endogeneous and exogeneous uncertainty, where both the rewards and state transition probability are unknown to the RL agent and evolve with the time as long as their respective variations do not exceed certain dynamic budget (i.e., upper bound). We first develop a variation-aware Bernstein-based upper confidence reinforcement learning (VB-UCRL), which we allow to restart according to a schedule dependent on the variations. We successfully overcome the challenges due to the exogeneous uncertainty and establish a regret bound of saving at most $\sqrt{S}$ or $S^{\frac{1}{6}}T^{\frac{1}{12}}$ compared with the latest results in the literature, where $S$ denotes the state size of the MDP and $T$ indicates the iteration index of learning steps.
Interventional Video Grounding with Dual Contrastive Learning
Jul 07, 2021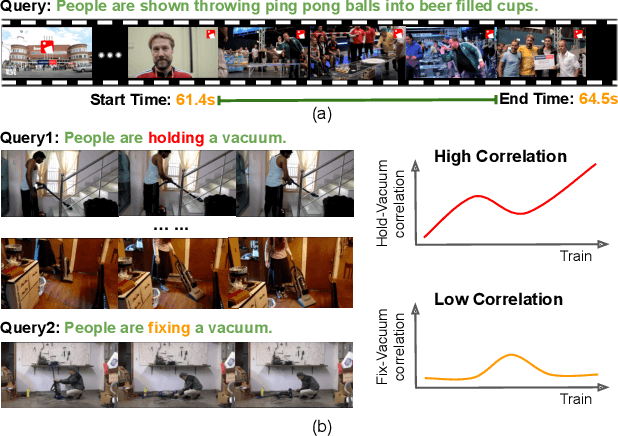
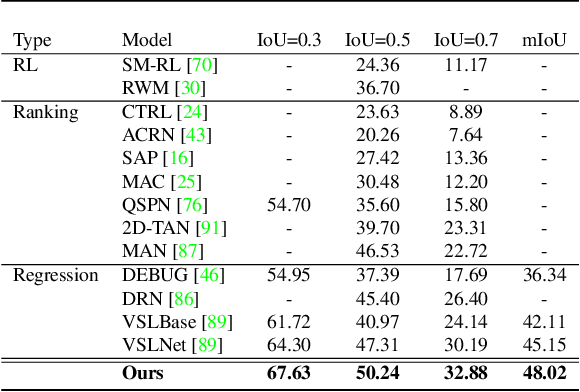
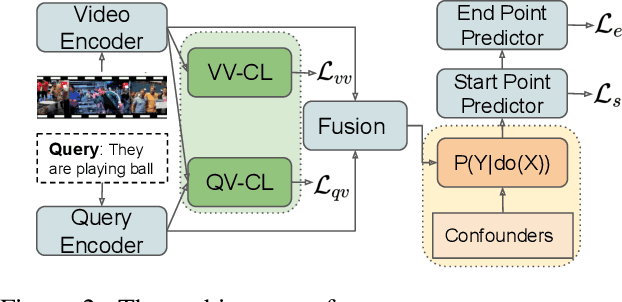
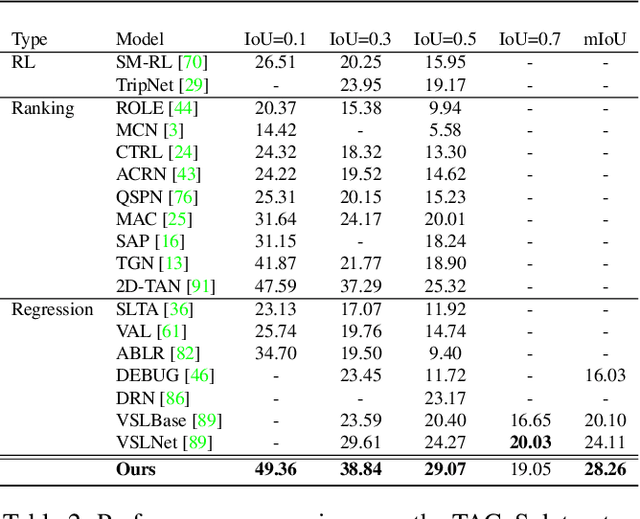
Video grounding aims to localize a moment from an untrimmed video for a given textual query. Existing approaches focus more on the alignment of visual and language stimuli with various likelihood-based matching or regression strategies, i.e., P(Y|X). Consequently, these models may suffer from spurious correlations between the language and video features due to the selection bias of the dataset. 1) To uncover the causality behind the model and data, we first propose a novel paradigm from the perspective of the causal inference, i.e., interventional video grounding (IVG) that leverages backdoor adjustment to deconfound the selection bias based on structured causal model (SCM) and do-calculus P(Y|do(X)). Then, we present a simple yet effective method to approximate the unobserved confounder as it cannot be directly sampled from the dataset. 2) Meanwhile, we introduce a dual contrastive learning approach (DCL) to better align the text and video by maximizing the mutual information (MI) between query and video clips, and the MI between start/end frames of a target moment and the others within a video to learn more informative visual representations. Experiments on three standard benchmarks show the effectiveness of our approaches. Our code is available on GitHub: https://github.com/nanguoshun/IVG.
Rate and Power Adaptation for Multihop Regenerative Relaying Systems
Jun 15, 2021
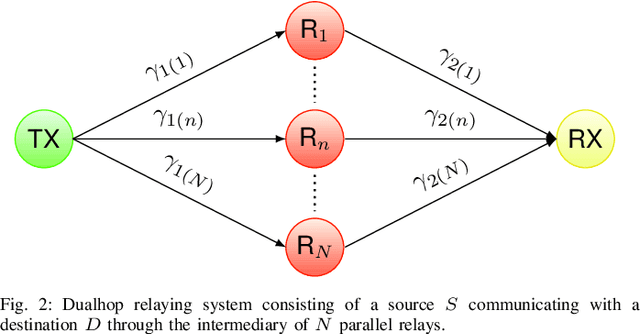
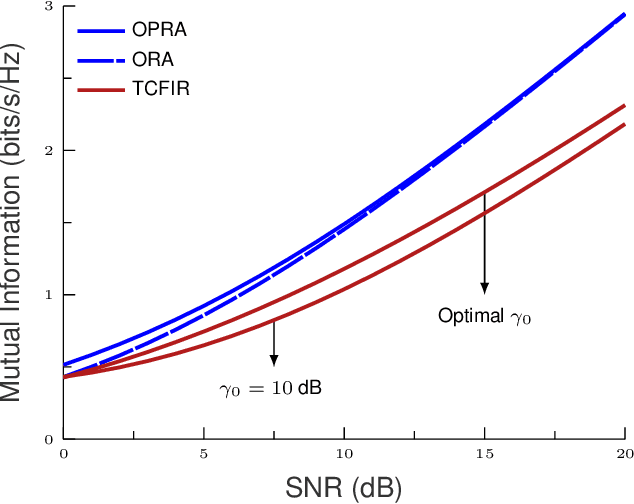
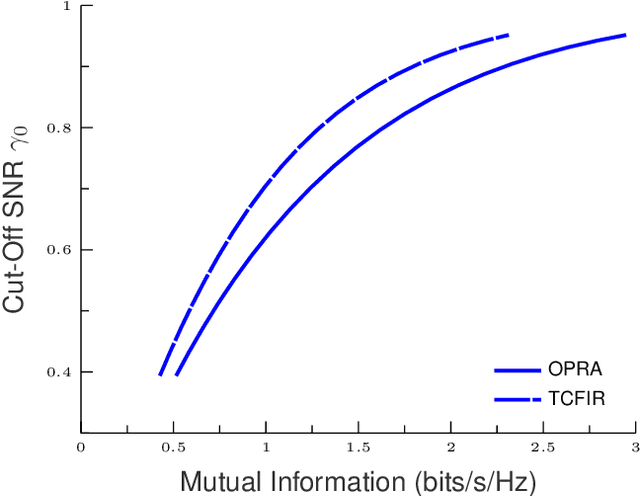
In this work, we provide a global framework analysis of a multi-hop relaying systems wherein the transmitter (TX) communicates with the receiver (RX) through a set of intermediary relays deployed either in series or in parallel. Regenerative based relaying scheme is assumed such as the repetition-coded decoded-and-forward (DF) wherein the decoding is threshold-based. To reflect a wide range of fading, we introduce the generalized $H$-function (also termed as Fox-$H$ function) distribution model which enables the modeling of radio-frequency (RF) fading like Weibull and Gamma, as well as the free-space optic (FSO) such as the Double Generalized Gamma and M\'alaga fading. In this context, we introduce various power and rate adaptation policies based on the channel state information (CSI) availability at TX and RX. Finally, we address the effects of relaying topology, number of relays and fading model, etc, on the performance reliability of each link adaptation policy.
Keyframe-Focused Visual Imitation Learning
Jun 11, 2021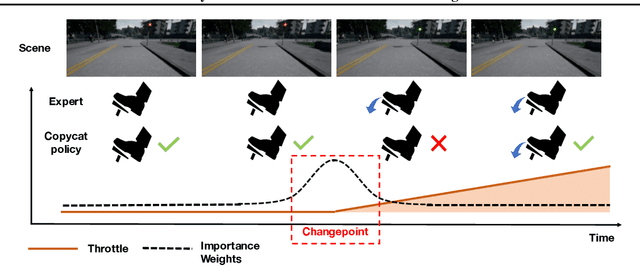
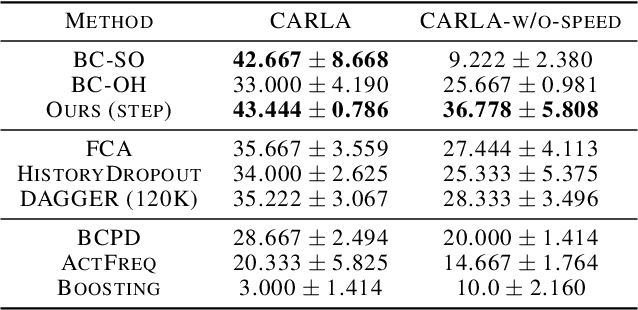
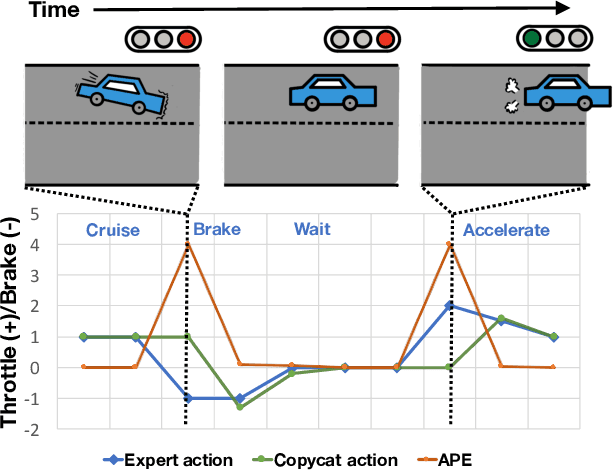

Imitation learning trains control policies by mimicking pre-recorded expert demonstrations. In partially observable settings, imitation policies must rely on observation histories, but many seemingly paradoxical results show better performance for policies that only access the most recent observation. Recent solutions ranging from causal graph learning to deep information bottlenecks have shown promising results, but failed to scale to realistic settings such as visual imitation. We propose a solution that outperforms these prior approaches by upweighting demonstration keyframes corresponding to expert action changepoints. This simple approach easily scales to complex visual imitation settings. Our experimental results demonstrate consistent performance improvements over all baselines on image-based Gym MuJoCo continuous control tasks. Finally, on the CARLA photorealistic vision-based urban driving simulator, we resolve a long-standing issue in behavioral cloning for driving by demonstrating effective imitation from observation histories. Supplementary materials and code at: \url{https://tinyurl.com/imitation-keyframes}.