 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Learned Cost Models with Synthetic SQL Queries
Aug 27, 2025



Having access to realistic workloads for a given database instance is extremely important to enable stress and vulnerability testing, as well as to optimize for cost and performance. Recent advances in learned cost models have shown that when enough diverse SQL queries are available, one can effectively and efficiently predict the cost of running a given query against a specific database engine. In this paper, we describe our experience in exploiting modern synthetic data generation techniques, inspired by the generative AI and LLM community, to create high-quality datasets enabling the effective training of such learned cost models. Initial results show that we can improve a learned cost model's predictive accuracy by training it with 45% fewer queries than when using competitive generation approaches.
Business Entity Matching with Siamese Graph Convolutional Networks
May 08, 2021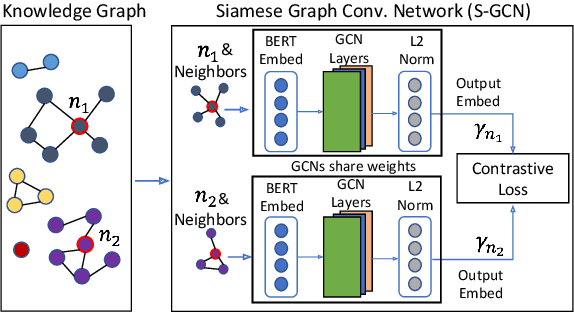

Data integration has been studied extensively for decades and approached from different angles. However, this domain still remains largely rule-driven and lacks universal automation. Recent developments in machine learning and in particular deep learning have opened the way to more general and efficient solutions to data-integration tasks. In this paper, we demonstrate an approach that allows modeling and integrating entities by leveraging their relations and contextual information. This is achieved by combining siamese and graph neural networks to effectively propagate information between connected entities and support high scalability. We evaluated our approach on the task of integrating data about business entities, demonstrating that it outperforms both traditional rule-based systems and other deep learning approaches.
Knowledge Graph Embedding using Graph Convolutional Networks with Relation-Aware Attention
Feb 14, 2021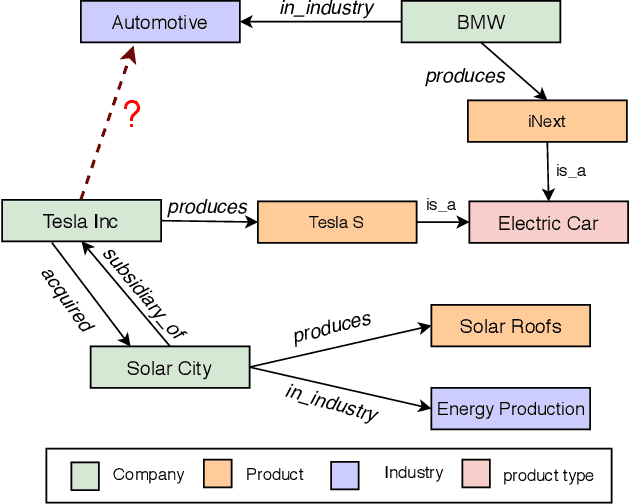
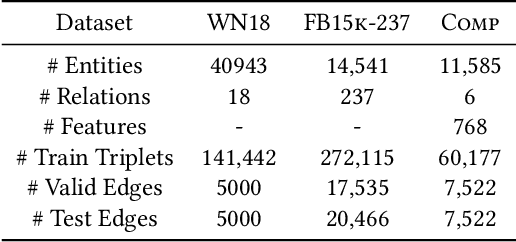
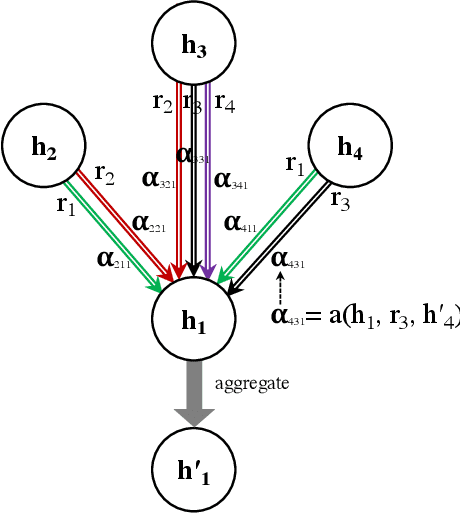
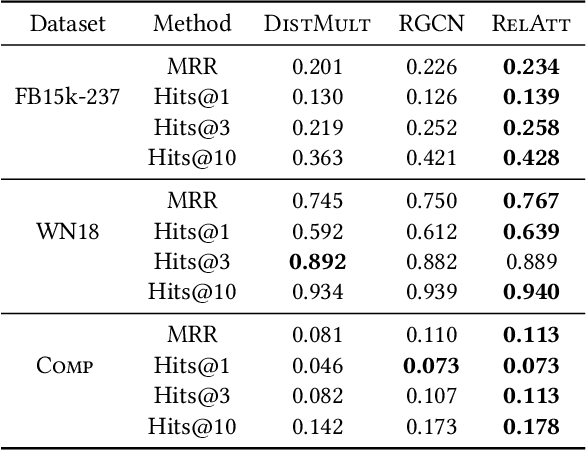
Knowledge graph embedding methods learn embeddings of entities and relations in a low dimensional space which can be used for various downstream machine learning tasks such as link prediction and entity matching. Various graph convolutional network methods have been proposed which use different types of information to learn the features of entities and relations. However, these methods assign the same weight (importance) to the neighbors when aggregating the information, ignoring the role of different relations with the neighboring entities. To this end, we propose a relation-aware graph attention model that leverages relation information to compute different weights to the neighboring nodes for learning embeddings of entities and relations. We evaluate our proposed approach on link prediction and entity matching tasks. Our experimental results on link prediction on three datasets (one proprietary and two public) and results on unsupervised entity matching on one proprietary dataset demonstrate the effectiveness of the relation-aware attention.