 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning the Next Best View for 3D Point Clouds via Topological Features
Mar 04, 2021
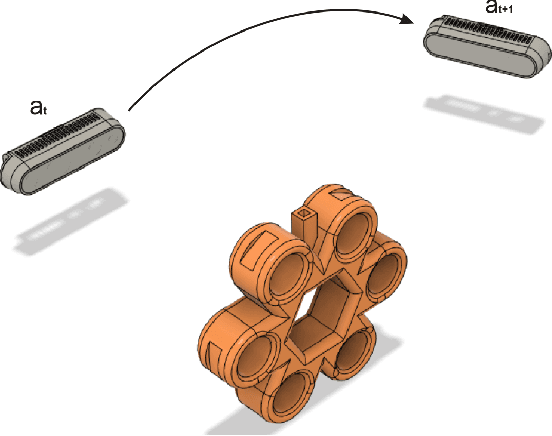
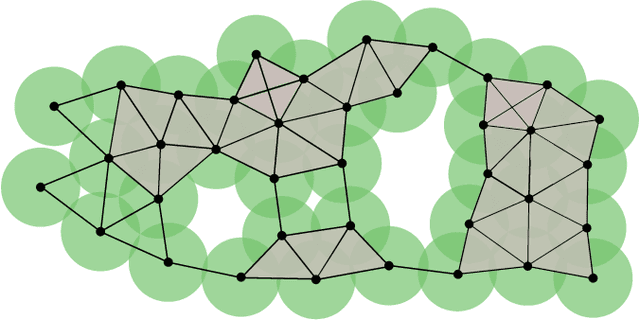
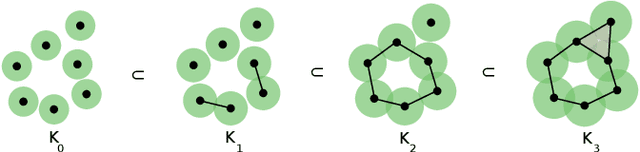

In this paper, we introduce a reinforcement learning approach utilizing a novel topology-based information gain metric for directing the next best view of a noisy 3D sensor. The metric combines the disjoint sections of an observed surface to focus on high-detail features such as holes and concave sections. Experimental results show that our approach can aid in establishing the placement of a robotic sensor to optimize the information provided by its streaming point cloud data. Furthermore, a labeled dataset of 3D objects, a CAD design for a custom robotic manipulator, and software for the transformation, union, and registration of point clouds has been publicly released to the research community.
Auditing for Diversity using Representative Examples
Jul 15, 2021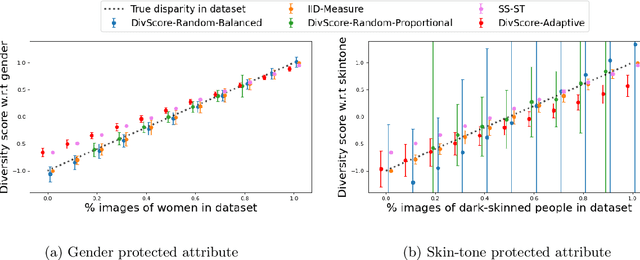
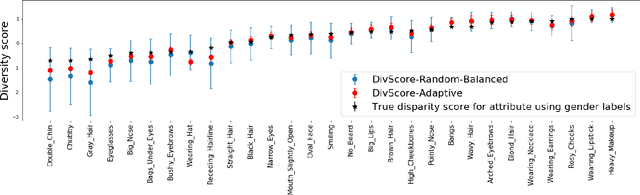
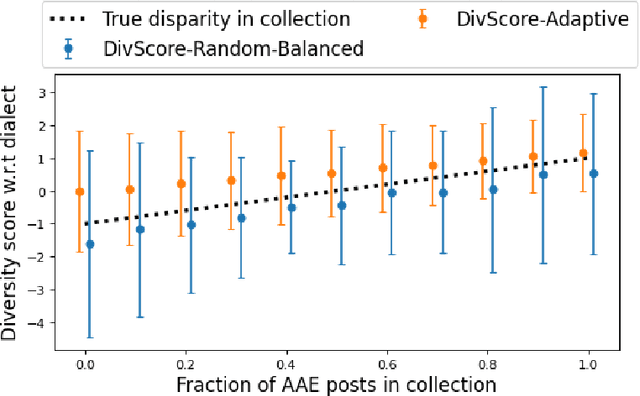
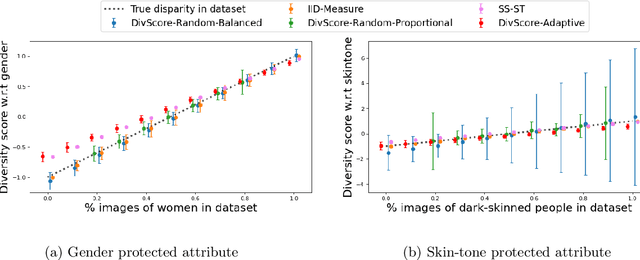
Assessing the diversity of a dataset of information associated with people is crucial before using such data for downstream applications. For a given dataset, this often involves computing the imbalance or disparity in the empirical marginal distribution of a protected attribute (e.g. gender, dialect, etc.). However, real-world datasets, such as images from Google Search or collections of Twitter posts, often do not have protected attributes labeled. Consequently, to derive disparity measures for such datasets, the elements need to hand-labeled or crowd-annotated, which are expensive processes. We propose a cost-effective approach to approximate the disparity of a given unlabeled dataset, with respect to a protected attribute, using a control set of labeled representative examples. Our proposed algorithm uses the pairwise similarity between elements in the dataset and elements in the control set to effectively bootstrap an approximation to the disparity of the dataset. Importantly, we show that using a control set whose size is much smaller than the size of the dataset is sufficient to achieve a small approximation error. Further, based on our theoretical framework, we also provide an algorithm to construct adaptive control sets that achieve smaller approximation errors than randomly chosen control sets. Simulations on two image datasets and one Twitter dataset demonstrate the efficacy of our approach (using random and adaptive control sets) in auditing the diversity of a wide variety of datasets.
Strategic Mitigation of Agent Inattention in Drivers with Open-Quantum Cognition Models
Jul 21, 2021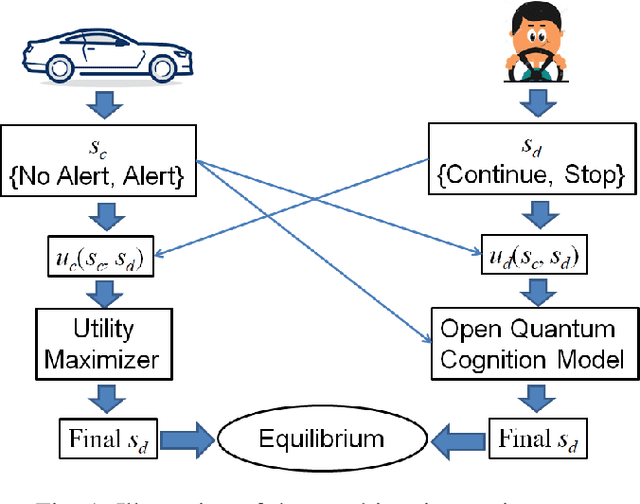
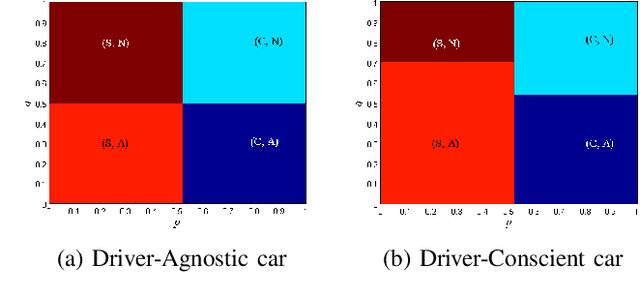
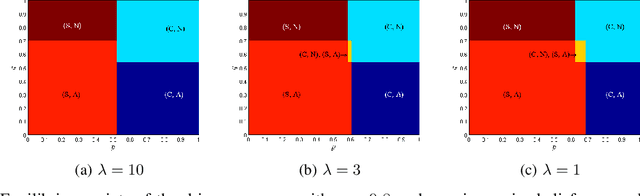

State-of-the-art driver-assist systems have failed to effectively mitigate driver inattention and had minimal impacts on the ever-growing number of road mishaps (e.g. life loss, physical injuries due to accidents caused by various factors that lead to driver inattention). This is because traditional human-machine interaction settings are modeled in classical and behavioral game-theoretic domains which are technically appropriate to characterize strategic interaction between either two utility maximizing agents, or human decision makers. Therefore, in an attempt to improve the persuasive effectiveness of driver-assist systems, we develop a novel strategic and personalized driver-assist system which adapts to the driver's mental state and choice behavior. First, we propose a novel equilibrium notion in human-system interaction games, where the system maximizes its expected utility and human decisions can be characterized using any general decision model. Then we use this novel equilibrium notion to investigate the strategic driver-vehicle interaction game where the car presents a persuasive recommendation to steer the driver towards safer driving decisions. We assume that the driver employs an open-quantum system cognition model, which captures complex aspects of human decision making such as violations to classical law of total probability and incompatibility of certain mental representations of information. We present closed-form expressions for players' final responses to each other's strategies so that we can numerically compute both pure and mixed equilibria. Numerical results are presented to illustrate both kinds of equilibria.
Catchphrase: Automatic Detection of Cultural References
Jun 09, 2021


A snowclone is a customizable phrasal template that can be realized in multiple, instantly recognized variants. For example, ``* is the new *" (Orange is the new black, 40 is the new 30). Snowclones are extensively used in social media. In this paper, we study snowclones originating from pop-culture quotes; our goal is to automatically detect cultural references in text. We introduce a new, publicly available data set of pop-culture quotes and their corresponding snowclone usages and train models on them. We publish code for Catchphrase, an internet browser plugin to automatically detect and mark references in real-time, and examine its performance via a user study. Aside from assisting people to better comprehend cultural references, we hope that detecting snowclones can complement work on paraphrasing and help to tackle long-standing questions in social science about the dynamics of information propagation.
Multi-Modal Association based Grouping for Form Structure Extraction
Jul 09, 2021
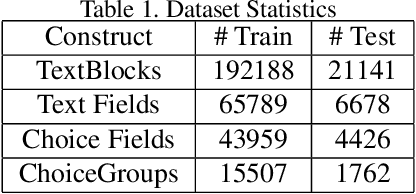

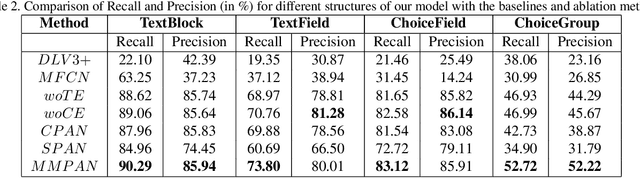
Document structure extraction has been a widely researched area for decades. Recent work in this direction has been deep learning-based, mostly focusing on extracting structure using fully convolution NN through semantic segmentation. In this work, we present a novel multi-modal approach for form structure extraction. Given simple elements such as textruns and widgets, we extract higher-order structures such as TextBlocks, Text Fields, Choice Fields, and Choice Groups, which are essential for information collection in forms. To achieve this, we obtain a local image patch around each low-level element (reference) by identifying candidate elements closest to it. We process textual and spatial representation of candidates sequentially through a BiLSTM to obtain context-aware representations and fuse them with image patch features obtained by processing it through a CNN. Subsequently, the sequential decoder takes this fused feature vector to predict the association type between reference and candidates. These predicted associations are utilized to determine larger structures through connected components analysis. Experimental results show the effectiveness of our approach achieving a recall of 90.29%, 73.80%, 83.12%, and 52.72% for the above structures, respectively, outperforming semantic segmentation baselines significantly. We show the efficacy of our method through ablations, comparing it against using individual modalities. We also introduce our new rich human-annotated Forms Dataset.
Voice Activity Detection for Transient Noisy Environment Based on Diffusion Nets
Jun 25, 2021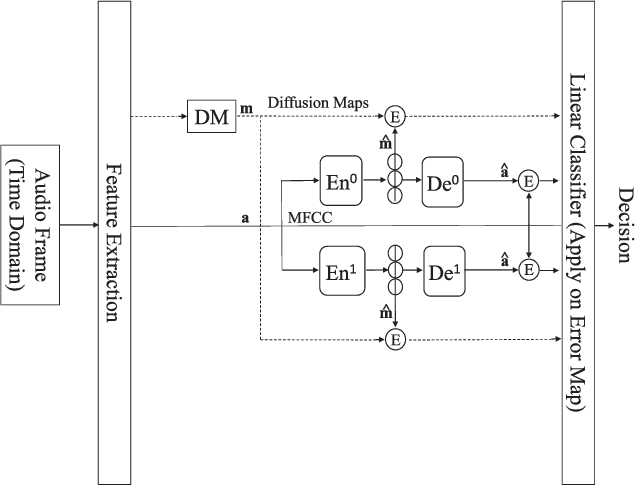
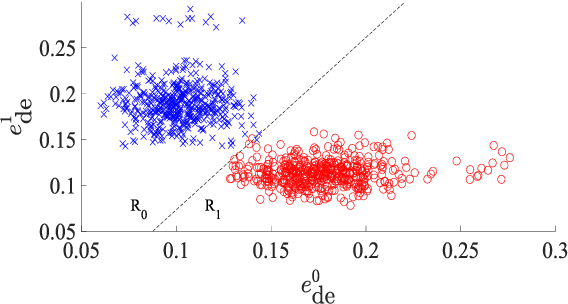
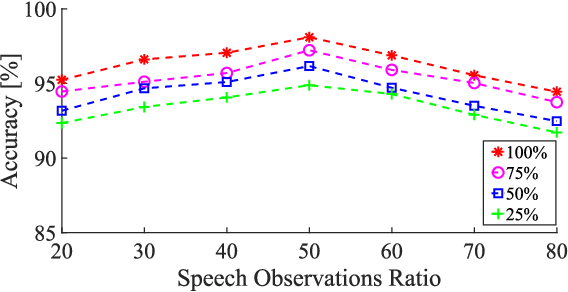
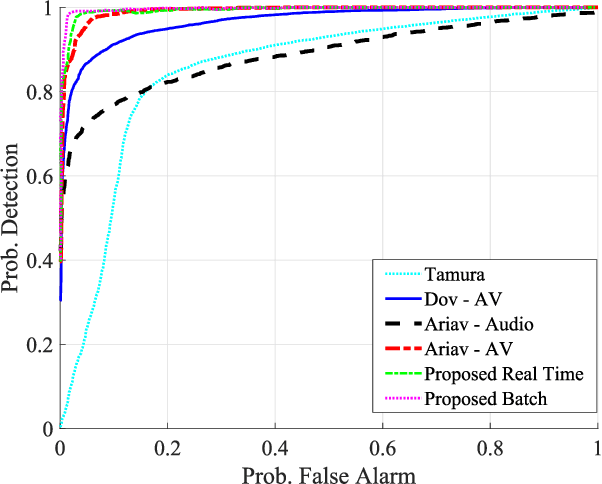
We address voice activity detection in acoustic environments of transients and stationary noises, which often occur in real life scenarios. We exploit unique spatial patterns of speech and non-speech audio frames by independently learning their underlying geometric structure. This process is done through a deep encoder-decoder based neural network architecture. This structure involves an encoder that maps spectral features with temporal information to their low-dimensional representations, which are generated by applying the diffusion maps method. The encoder feeds a decoder that maps the embedded data back into the high-dimensional space. A deep neural network, which is trained to separate speech from non-speech frames, is obtained by concatenating the decoder to the encoder, resembling the known Diffusion nets architecture. Experimental results show enhanced performance compared to competing voice activity detection methods. The improvement is achieved in both accuracy, robustness and generalization ability. Our model performs in a real-time manner and can be integrated into audio-based communication systems. We also present a batch algorithm which obtains an even higher accuracy for off-line applications.
* Accepted to IEEE journal of selected topics in signal processing 2019
Learning to Adversarially Blur Visual Object Tracking
Jul 26, 2021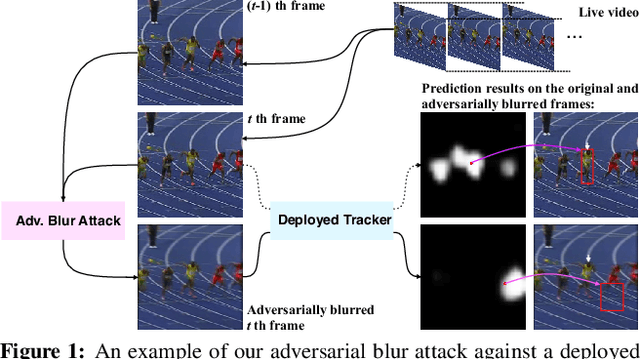
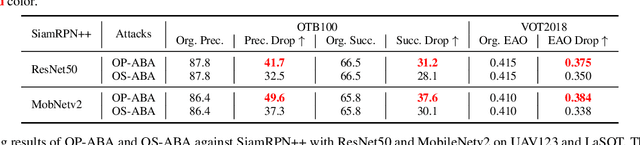
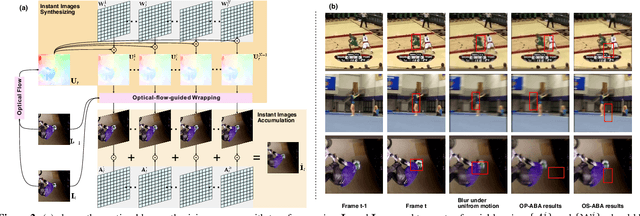

Motion blur caused by the moving of the object or camera during the exposure can be a key challenge for visual object tracking, affecting tracking accuracy significantly. In this work, we explore the robustness of visual object trackers against motion blur from a new angle, i.e., adversarial blur attack (ABA). Our main objective is to online transfer input frames to their natural motion-blurred counterparts while misleading the state-of-the-art trackers during the tracking process. To this end, we first design the motion blur synthesizing method for visual tracking based on the generation principle of motion blur, considering the motion information and the light accumulation process. With this synthetic method, we propose \textit{optimization-based ABA (OP-ABA)} by iteratively optimizing an adversarial objective function against the tracking w.r.t. the motion and light accumulation parameters. The OP-ABA is able to produce natural adversarial examples but the iteration can cause heavy time cost, making it unsuitable for attacking real-time trackers. To alleviate this issue, we further propose \textit{one-step ABA (OS-ABA)} where we design and train a joint adversarial motion and accumulation predictive network (JAMANet) with the guidance of OP-ABA, which is able to efficiently estimate the adversarial motion and accumulation parameters in a one-step way. The experiments on four popular datasets (\eg, OTB100, VOT2018, UAV123, and LaSOT) demonstrate that our methods are able to cause significant accuracy drops on four state-of-the-art trackers with high transferability. Please find the source code at https://github.com/tsingqguo/ABA
Learning Comprehensive Motion Representation for Action Recognition
Mar 23, 2021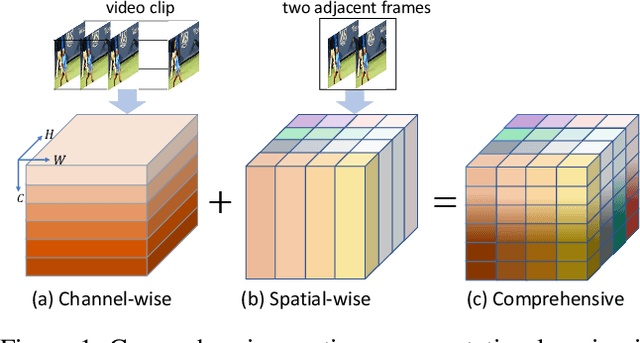
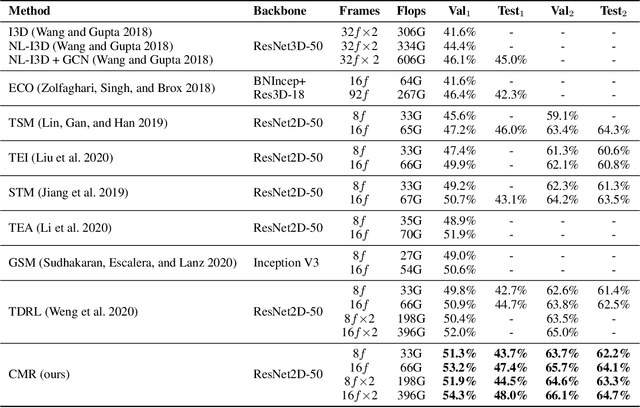
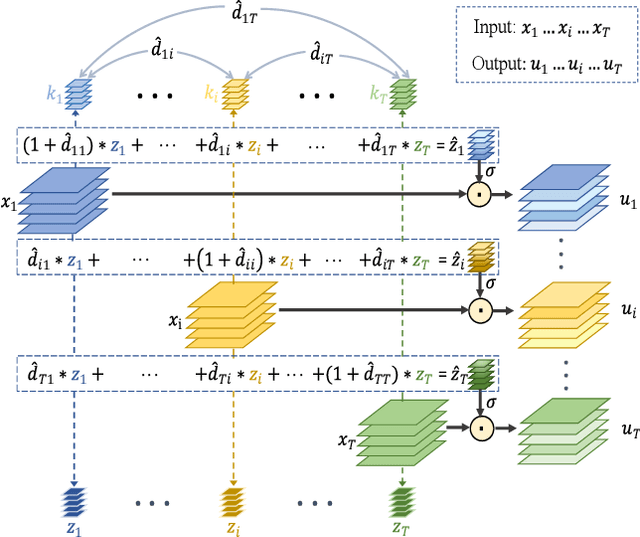
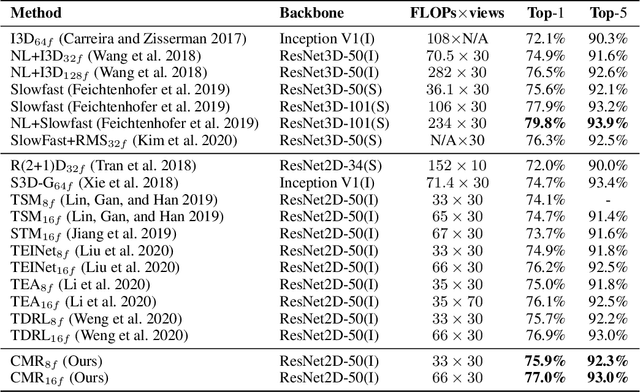
For action recognition learning, 2D CNN-based methods are efficient but may yield redundant features due to applying the same 2D convolution kernel to each frame. Recent efforts attempt to capture motion information by establishing inter-frame connections while still suffering the limited temporal receptive field or high latency. Moreover, the feature enhancement is often only performed by channel or space dimension in action recognition. To address these issues, we first devise a Channel-wise Motion Enhancement (CME) module to adaptively emphasize the channels related to dynamic information with a channel-wise gate vector. The channel gates generated by CME incorporate the information from all the other frames in the video. We further propose a Spatial-wise Motion Enhancement (SME) module to focus on the regions with the critical target in motion, according to the point-to-point similarity between adjacent feature maps. The intuition is that the change of background is typically slower than the motion area. Both CME and SME have clear physical meaning in capturing action clues. By integrating the two modules into the off-the-shelf 2D network, we finally obtain a Comprehensive Motion Representation (CMR) learning method for action recognition, which achieves competitive performance on Something-Something V1 & V2 and Kinetics-400. On the temporal reasoning datasets Something-Something V1 and V2, our method outperforms the current state-of-the-art by 2.3% and 1.9% when using 16 frames as input, respectively.
ECG Heartbeat Classification Using Multimodal Fusion
Jul 21, 2021
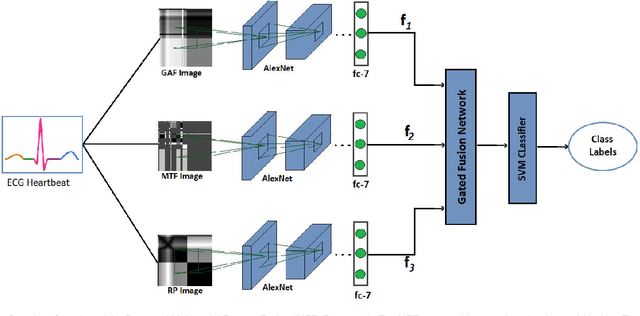
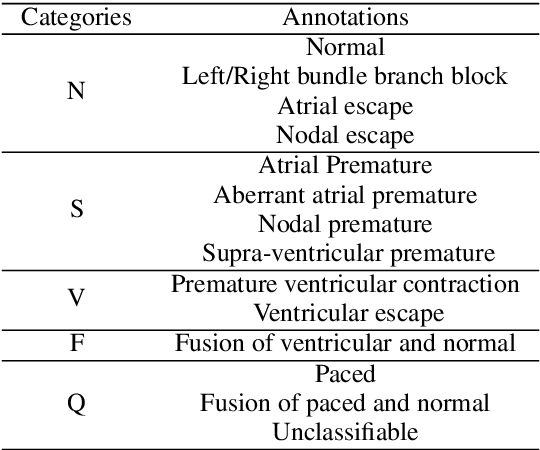
Electrocardiogram (ECG) is an authoritative source to diagnose and counter critical cardiovascular syndromes such as arrhythmia and myocardial infarction (MI). Current machine learning techniques either depend on manually extracted features or large and complex deep learning networks which merely utilize the 1D ECG signal directly. Since intelligent multimodal fusion can perform at the stateof-the-art level with an efficient deep network, therefore, in this paper, we propose two computationally efficient multimodal fusion frameworks for ECG heart beat classification called Multimodal Image Fusion (MIF) and Multimodal Feature Fusion (MFF). At the input of these frameworks, we convert the raw ECG data into three different images using Gramian Angular Field (GAF), Recurrence Plot (RP) and Markov Transition Field (MTF). In MIF, we first perform image fusion by combining three imaging modalities to create a single image modality which serves as input to the Convolutional Neural Network (CNN). In MFF, we extracted features from penultimate layer of CNNs and fused them to get unique and interdependent information necessary for better performance of classifier. These informational features are finally used to train a Support Vector Machine (SVM) classifier for ECG heart-beat classification. We demonstrate the superiority of the proposed fusion models by performing experiments on PhysioNets MIT-BIH dataset for five distinct conditions of arrhythmias which are consistent with the AAMI EC57 protocols and on PTB diagnostics dataset for Myocardial Infarction (MI) classification. We achieved classification accuracy of 99.7% and 99.2% on arrhythmia and MI classification, respectively.
MoDist: Motion Distillation for Self-supervised Video Representation Learning
Jun 17, 2021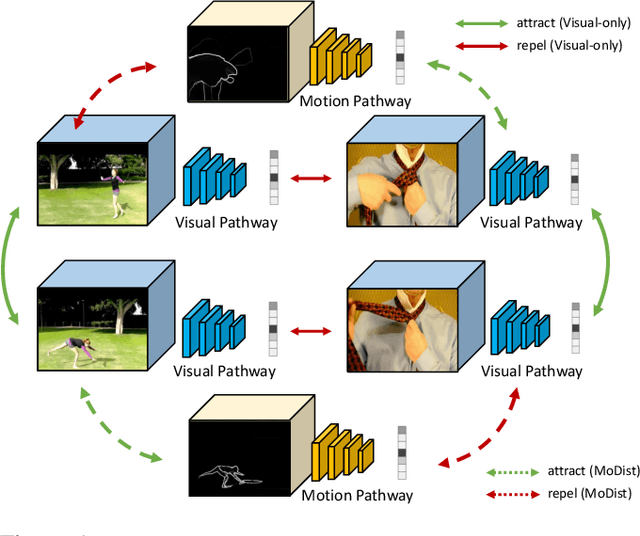
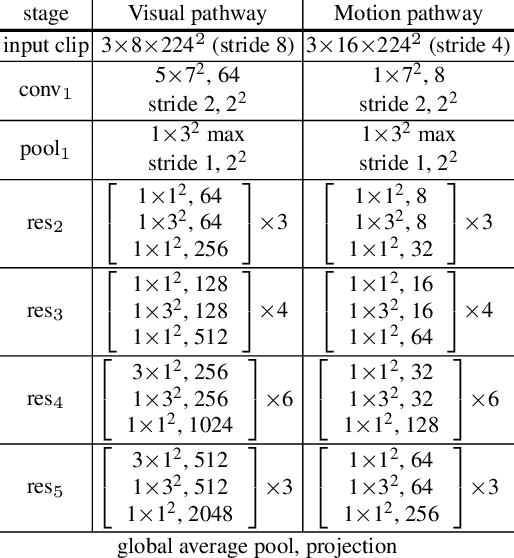

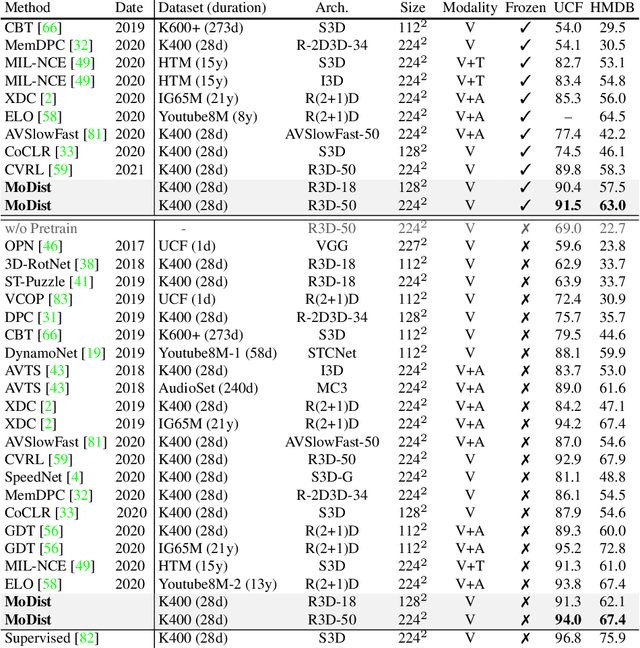
We present MoDist as a novel method to explicitly distill motion information into self-supervised video representations. Compared to previous video representation learning methods that mostly focus on learning motion cues implicitly from RGB inputs, we show that the representation learned with our MoDist method focus more on foreground motion regions and thus generalizes better to downstream tasks. To achieve this, MoDist enriches standard contrastive learning objectives for RGB video clips with a cross-modal learning objective between a Motion pathway and a Visual pathway. We evaluate MoDist on several datasets for both action recognition (UCF101/HMDB51/SSv2) as well as action detection (AVA), and demonstrate state-of-the-art self-supervised performance on all datasets. Furthermore, we show that MoDist representation can be as effective as (in some cases even better than) representations learned with full supervision. Given its simplicity, we hope MoDist could serve as a strong baseline for future research in self-supervised video representation learning.