 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective Metrics to Evaluate Residual-Echo Suppression During Double-Talk
Jul 15, 2021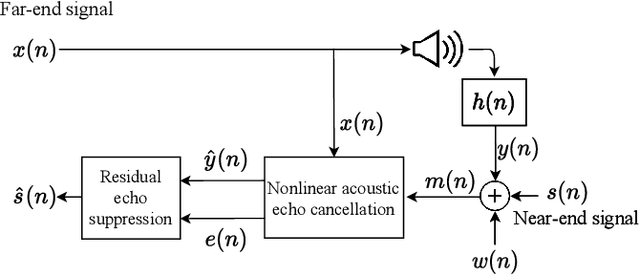
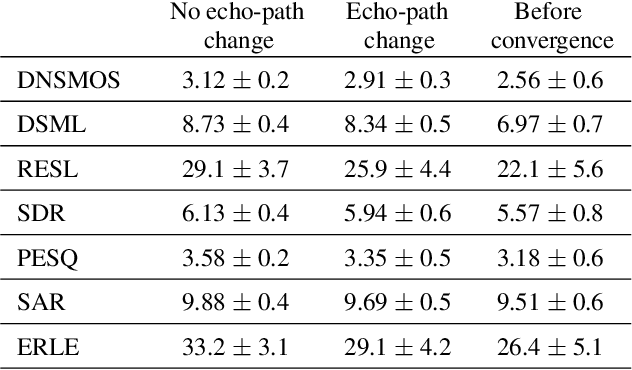
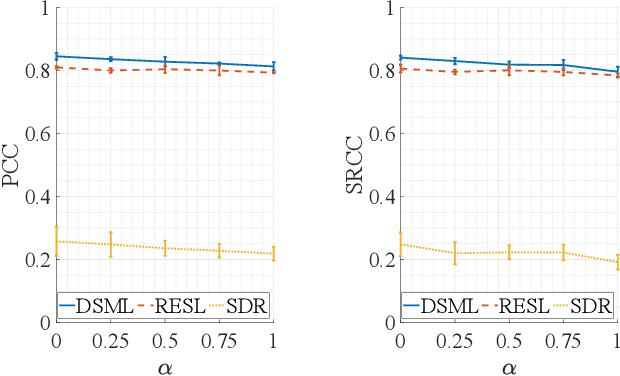
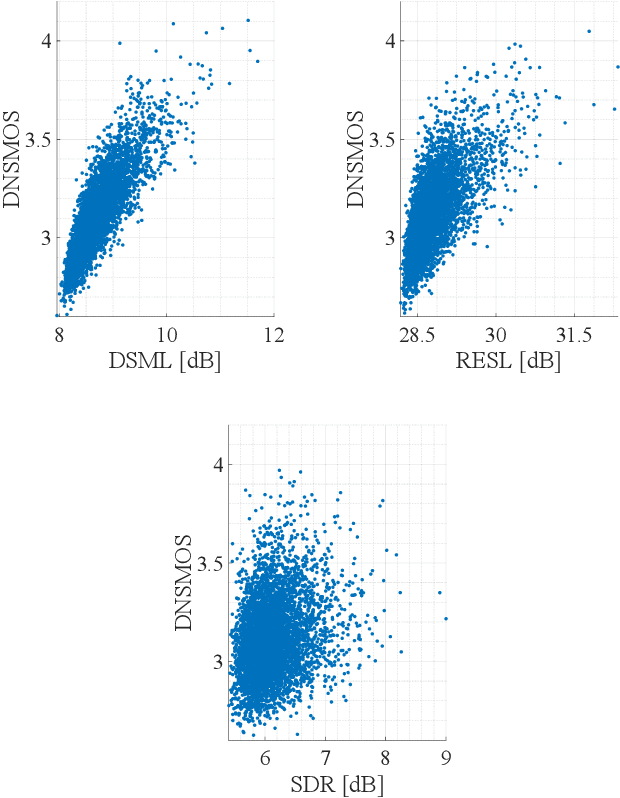
Human subjective evaluation is optimal to assess speech quality for human perception. The recently introduced deep noise suppression mean opinion score (DNSMOS) metric was shown to estimate human ratings with great accuracy. The signal-to-distortion ratio (SDR) metric is widely used to evaluate residual-echo suppression (RES) systems by estimating speech quality during double-talk. However, since the SDR is affected by both speech distortion and residual-echo presence, it does not correlate well with human ratings according to the DNSMOS. To address that, we introduce two objective metrics to separately quantify the desired-speech maintained level (DSML) and residual-echo suppression level (RESL) during double-talk. These metrics are evaluated using a deep learning-based RES-system with a tunable design parameter. Using 280 hours of real and simulated recordings, we show that the DSML and RESL correlate well with the DNSMOS with high generalization to various setups. Also, we empirically investigate the relation between tuning the RES-system design parameter and the DSML-RESL tradeoff it creates and offer a practical design scheme for dynamic system requirements.
Voice Activity Detection for Transient Noisy Environment Based on Diffusion Nets
Jun 25, 2021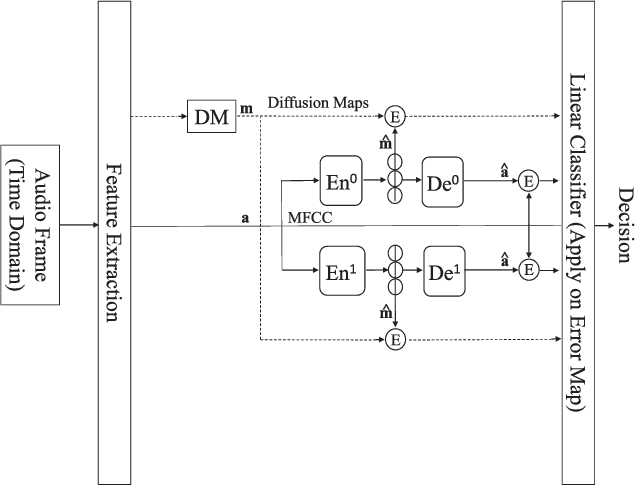
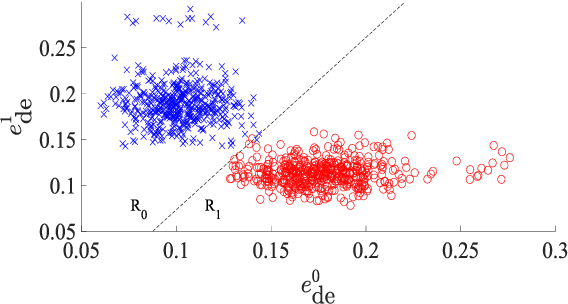
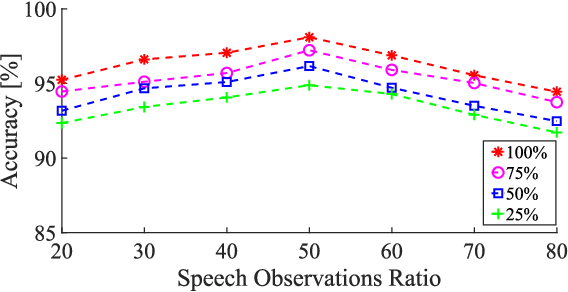
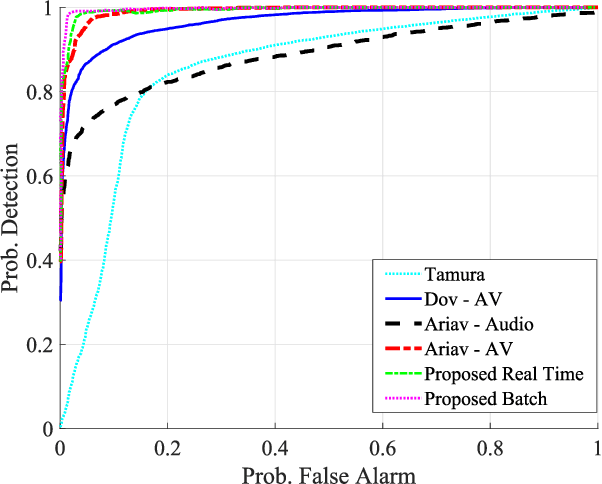
We address voice activity detection in acoustic environments of transients and stationary noises, which often occur in real life scenarios. We exploit unique spatial patterns of speech and non-speech audio frames by independently learning their underlying geometric structure. This process is done through a deep encoder-decoder based neural network architecture. This structure involves an encoder that maps spectral features with temporal information to their low-dimensional representations, which are generated by applying the diffusion maps method. The encoder feeds a decoder that maps the embedded data back into the high-dimensional space. A deep neural network, which is trained to separate speech from non-speech frames, is obtained by concatenating the decoder to the encoder, resembling the known Diffusion nets architecture. Experimental results show enhanced performance compared to competing voice activity detection methods. The improvement is achieved in both accuracy, robustness and generalization ability. Our model performs in a real-time manner and can be integrated into audio-based communication systems. We also present a batch algorithm which obtains an even higher accuracy for off-line applications.
* Accepted to IEEE journal of selected topics in signal processing 2019
Nonlinear Acoustic Echo Cancellation with Deep Learning
Jun 25, 2021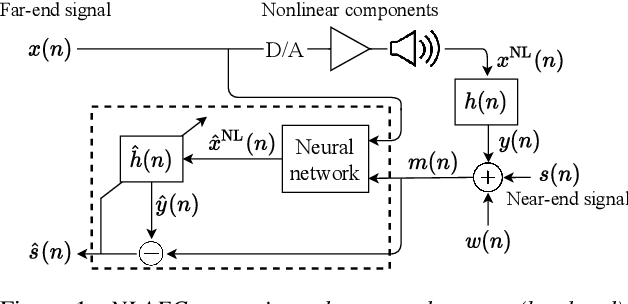

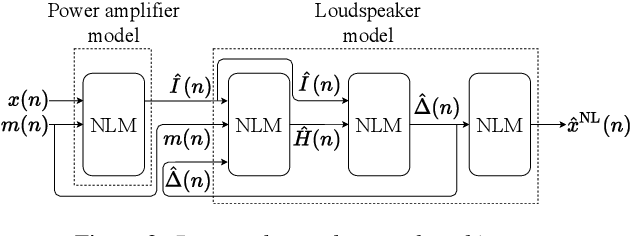

We propose a nonlinear acoustic echo cancellation system, which aims to model the echo path from the far-end signal to the near-end microphone in two parts. Inspired by the physical behavior of modern hands-free devices, we first introduce a novel neural network architecture that is specifically designed to model the nonlinear distortions these devices induce between receiving and playing the far-end signal. To account for variations between devices, we construct this network with trainable memory length and nonlinear activation functions that are not parameterized in advance, but are rather optimized during the training stage using the training data. Second, the network is succeeded by a standard adaptive linear filter that constantly tracks the echo path between the loudspeaker output and the microphone. During training, the network and filter are jointly optimized to learn the network parameters. This system requires 17 thousand parameters that consume 500 Million floating-point operations per second and 40 Kilo-bytes of memory. It also satisfies hands-free communication timing requirements on a standard neural processor, which renders it adequate for embedding on hands-free communication devices. Using 280 hours of real and synthetic data, experiments show advantageous performance compared to competing methods.
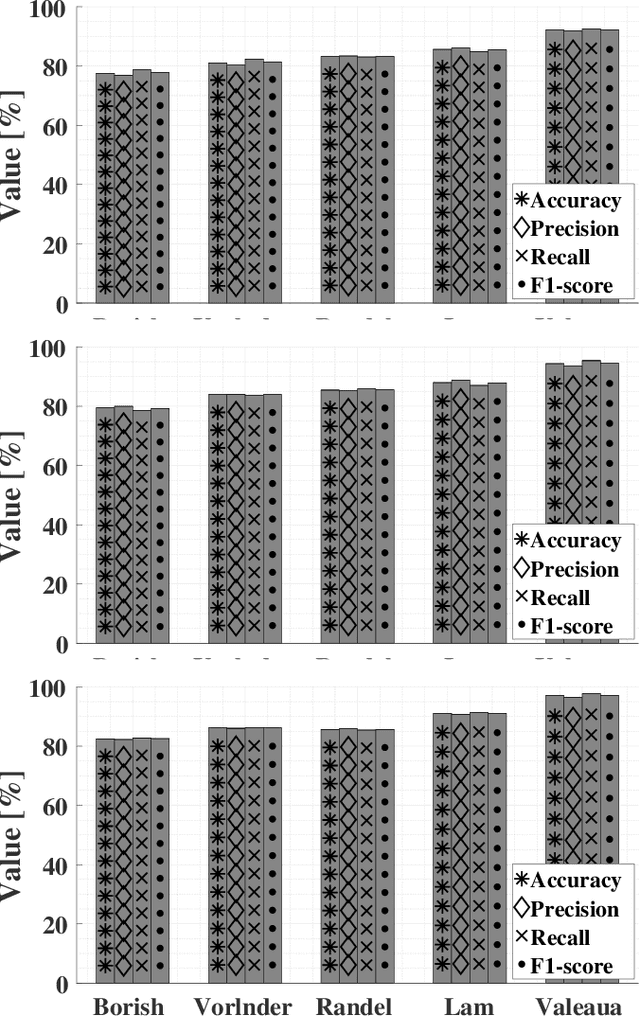
Deep Residual Echo Suppression with A Tunable Tradeoff Between Signal Distortion and Echo Suppression
Jun 25, 2021

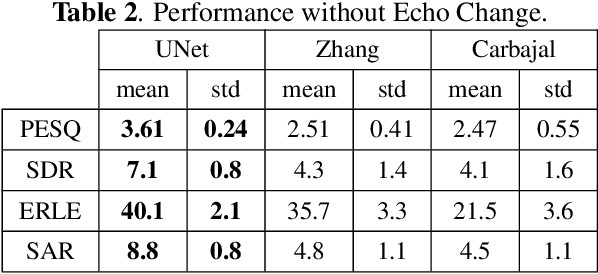
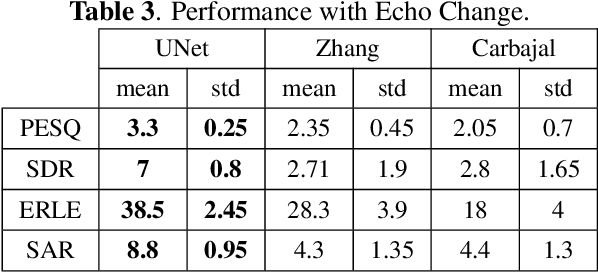
In this paper, we propose a residual echo suppression method using a UNet neural network that directly maps the outputs of a linear acoustic echo canceler to the desired signal in the spectral domain. This system embeds a design parameter that allows a tunable tradeoff between the desired-signal distortion and residual echo suppression in double-talk scenarios. The system employs 136 thousand parameters, and requires 1.6 Giga floating-point operations per second and 10 Mega-bytes of memory. The implementation satisfies both the timing requirements of the AEC challenge and the computational and memory limitations of on-device applications. Experiments are conducted with 161~h of data from the AEC challenge database and from real independent recordings. We demonstrate the performance of the proposed system in real-life conditions and compare it with two competing methods regarding echo suppression and desired-signal distortion, generalization to various environments, and robustness to high echo levels.
* Accepted to ICASSP 2021
Evaluation of Deep-Learning-Based Voice Activity Detectors and Room Impulse Response Models in Reverberant Environments
Jun 25, 2021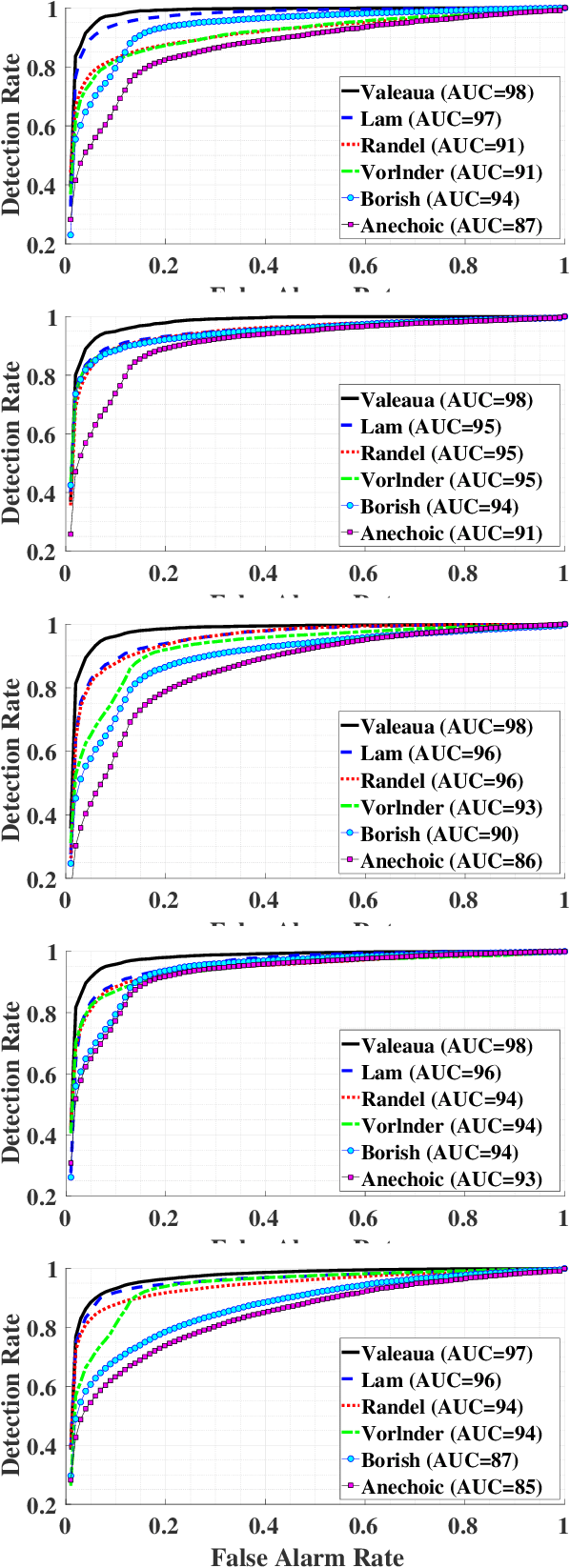
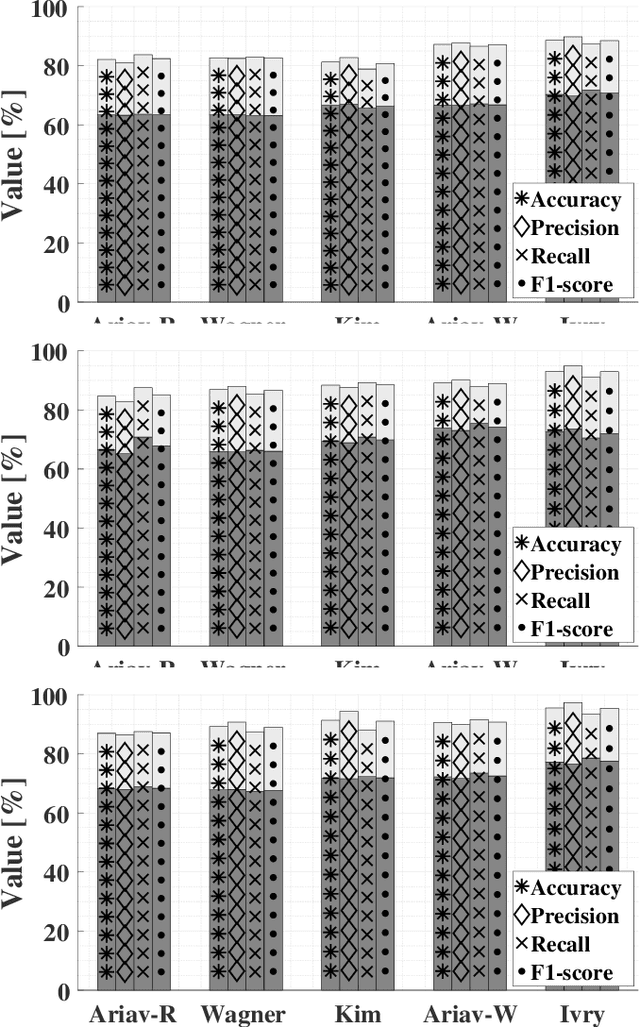
State-of-the-art deep-learning-based voice activity detectors (VADs) are often trained with anechoic data. However, real acoustic environments are generally reverberant, which causes the performance to significantly deteriorate. To mitigate this mismatch between training data and real data, we simulate an augmented training set that contains nearly five million utterances. This extension comprises of anechoic utterances and their reverberant modifications, generated by convolutions of the anechoic utterances with a variety of room impulse responses (RIRs). We consider five different models to generate RIRs, and five different VADs that are trained with the augmented training set. We test all trained systems in three different real reverberant environments. Experimental results show $20\%$ increase on average in accuracy, precision and recall for all detectors and response models, compared to anechoic training. Furthermore, one of the RIR models consistently yields better performance than the other models, for all the tested VADs. Additionally, one of the VADs consistently outperformed the other VADs in all experiments.