 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs versus the Halting Problem: Revisiting Program Termination Prediction
Jan 26, 2026Determining whether a program terminates is a central problem in computer science. Turing's foundational result established the Halting Problem as undecidable, showing that no algorithm can universally determine termination for all programs and inputs. Consequently, automatic verification tools approximate termination, sometimes failing to prove or disprove; these tools rely on problem-specific architectures and abstractions, and are usually tied to particular programming languages. Recent success and progress in large language models (LLMs) raises the following question: can LLMs reliably predict program termination? In this work, we evaluate LLMs on a diverse set of C programs from the Termination category of the International Competition on Software Verification (SV-Comp) 2025. Our results suggest that LLMs perform remarkably well at predicting program termination, where GPT-5 and Claude Sonnet-4.5 would rank just behind the top-ranked tool (using test-time-scaling), and Code World Model (CWM) would place just behind the second-ranked tool. While LLMs are effective at predicting program termination, they often fail to provide a valid witness as a proof. Moreover, LLMs performance drops as program length increases. We hope these insights motivate further research into program termination and the broader potential of LLMs for reasoning about undecidable problems.
Finding your MUSE: Mining Unexpected Solutions Engine
Sep 05, 2025



Innovators often exhibit cognitive fixation on existing solutions or nascent ideas, hindering the exploration of novel alternatives. This paper introduces a methodology for constructing Functional Concept Graphs (FCGs), interconnected representations of functional elements that support abstraction, problem reframing, and analogical inspiration. Our approach yields large-scale, high-quality FCGs with explicit abstraction relations, overcoming limitations of prior work. We further present MUSE, an algorithm leveraging FCGs to generate creative inspirations for a given problem. We demonstrate our method by computing an FCG on 500K patents, which we release for further research.
One Joke to Rule them All? On the (Im)possibility of Generalizing Humor
Aug 26, 2025



Humor is a broad and complex form of communication that remains challenging for machines. Despite its broadness, most existing research on computational humor traditionally focused on modeling a specific type of humor. In this work, we wish to understand whether competence on one or more specific humor tasks confers any ability to transfer to novel, unseen types; in other words, is this fragmentation inevitable? This question is especially timely as new humor types continuously emerge in online and social media contexts (e.g., memes, anti-humor, AI fails). If Large Language Models (LLMs) are to keep up with this evolving landscape, they must be able to generalize across humor types by capturing deeper, transferable mechanisms. To investigate this, we conduct a series of transfer learning experiments across four datasets, representing different humor tasks. We train LLMs under varied diversity settings (1-3 datasets in training, testing on a novel task). Experiments reveal that models are capable of some transfer, and can reach up to 75% accuracy on unseen datasets; training on diverse sources improves transferability (1.88-4.05%) with minimal-to-no drop in in-domain performance. Further analysis suggests relations between humor types, with Dad Jokes surprisingly emerging as the best enabler of transfer (but is difficult to transfer to). We release data and code.
Towards Reliable Proof Generation with LLMs: A Neuro-Symbolic Approach
May 20, 2025Large language models (LLMs) struggle with formal domains that require rigorous logical deduction and symbolic reasoning, such as mathematical proof generation. We propose a neuro-symbolic approach that combines LLMs' generative strengths with structured components to overcome this challenge. As a proof-of-concept, we focus on geometry problems. Our approach is two-fold: (1) we retrieve analogous problems and use their proofs to guide the LLM, and (2) a formal verifier evaluates the generated proofs and provides feedback, helping the model fix incorrect proofs. We demonstrate that our method significantly improves proof accuracy for OpenAI's o1 model (58%-70% improvement); both analogous problems and the verifier's feedback contribute to these gains. More broadly, shifting to LLMs that generate provably correct conclusions could dramatically improve their reliability, accuracy and consistency, unlocking complex tasks and critical real-world applications that require trustworthiness.
Cooking Up Creativity: A Cognitively-Inspired Approach for Enhancing LLM Creativity through Structured Representations
Apr 29, 2025Large Language Models (LLMs) excel at countless tasks, yet struggle with creativity. In this paper, we introduce a novel approach that couples LLMs with structured representations and cognitively inspired manipulations to generate more creative and diverse ideas. Our notion of creativity goes beyond superficial token-level variations; rather, we explicitly recombine structured representations of existing ideas, allowing our algorithm to effectively explore the more abstract landscape of ideas. We demonstrate our approach in the culinary domain with DishCOVER, a model that generates creative recipes. Experiments comparing our model's results to those of GPT-4o show greater diversity. Domain expert evaluations reveal that our outputs, which are mostly coherent and feasible culinary creations, significantly surpass GPT-4o in terms of novelty, thus outperforming it in creative generation. We hope our work inspires further research into structured creativity in AI.
Visual Editing with LLM-based Tool Chaining: An Efficient Distillation Approach for Real-Time Applications
Oct 03, 2024We present a practical distillation approach to fine-tune LLMs for invoking tools in real-time applications. We focus on visual editing tasks; specifically, we modify images and videos by interpreting user stylistic requests, specified in natural language ("golden hour"), using an LLM to select the appropriate tools and their parameters to achieve the desired visual effect. We found that proprietary LLMs such as GPT-3.5-Turbo show potential in this task, but their high cost and latency make them unsuitable for real-time applications. In our approach, we fine-tune a (smaller) student LLM with guidance from a (larger) teacher LLM and behavioral signals. We introduce offline metrics to evaluate student LLMs. Both online and offline experiments show that our student models manage to match the performance of our teacher model (GPT-3.5-Turbo), significantly reducing costs and latency. Lastly, we show that fine-tuning was improved by 25% in low-data regimes using augmentation.
ParallelPARC: A Scalable Pipeline for Generating Natural-Language Analogies
Mar 02, 2024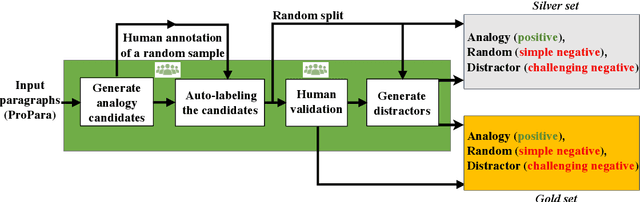


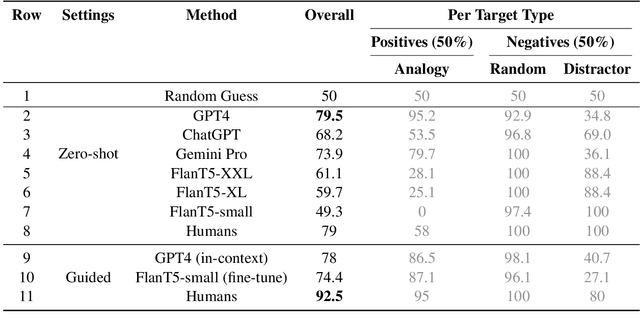
Analogy-making is central to human cognition, allowing us to adapt to novel situations -- an ability that current AI systems still lack. Most analogy datasets today focus on simple analogies (e.g., word analogies); datasets including complex types of analogies are typically manually curated and very small. We believe that this holds back progress in computational analogy. In this work, we design a data generation pipeline, ParallelPARC (Parallel Paragraph Creator) leveraging state-of-the-art Large Language Models (LLMs) to create complex, paragraph-based analogies, as well as distractors, both simple and challenging. We demonstrate our pipeline and create ProPara-Logy, a dataset of analogies between scientific processes. We publish a gold-set, validated by humans, and a silver-set, generated automatically. We test LLMs' and humans' analogy recognition in binary and multiple-choice settings, and found that humans outperform the best models (~13% gap) after a light supervision. We demonstrate that our silver-set is useful for training models. Lastly, we show challenging distractors confuse LLMs, but not humans. We hope our pipeline will encourage research in this emerging field.
State of What Art? A Call for Multi-Prompt LLM Evaluation
Dec 31, 2023Recent advances in large language models (LLMs) have led to the development of various evaluation benchmarks. These benchmarks typically rely on a single instruction template for evaluating all LLMs on a specific task. In this paper, we comprehensively analyze the brittleness of results obtained via single-prompt evaluations across 6.5M instances, involving 20 different LLMs and 39 tasks from 3 benchmarks. To improve robustness of the analysis, we propose to evaluate LLMs with a set of diverse prompts instead. We discuss tailored evaluation metrics for specific use cases (e.g., LLM developers vs. developers interested in a specific downstream task), ensuring a more reliable and meaningful assessment of LLM capabilities. We then implement these criteria and conduct evaluations of multiple models, providing insights into the true strengths and limitations of current LLMs.
Imitation of Life: A Search Engine for Biologically Inspired Design
Dec 20, 2023Biologically Inspired Design (BID), or Biomimicry, is a problem-solving methodology that applies analogies from nature to solve engineering challenges. For example, Speedo engineers designed swimsuits based on shark skin. Finding relevant biological solutions for real-world problems poses significant challenges, both due to the limited biological knowledge engineers and designers typically possess and to the limited BID resources. Existing BID datasets are hand-curated and small, and scaling them up requires costly human annotations. In this paper, we introduce BARcode (Biological Analogy Retriever), a search engine for automatically mining bio-inspirations from the web at scale. Using advances in natural language understanding and data programming, BARcode identifies potential inspirations for engineering challenges. Our experiments demonstrate that BARcode can retrieve inspirations that are valuable to engineers and designers tackling real-world problems, as well as recover famous historical BID examples. We release data and code; we view BARcode as a step towards addressing the challenges that have historically hindered the practical application of BID to engineering innovation.
Towards Concept-Aware Large Language Models
Nov 03, 2023



Concepts play a pivotal role in various human cognitive functions, including learning, reasoning and communication. However, there is very little work on endowing machines with the ability to form and reason with concepts. In particular, state-of-the-art large language models (LLMs) work at the level of tokens, not concepts. In this work, we analyze how well contemporary LLMs capture human concepts and their structure. We then discuss ways to develop concept-aware LLMs, taking place at different stages of the pipeline. We sketch a method for pretraining LLMs using concepts, and also explore the simpler approach that uses the output of existing LLMs. Despite its simplicity, our proof-of-concept is shown to better match human intuition, as well as improve the robustness of predictions. These preliminary results underscore the promise of concept-aware LLMs.