 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Feature Importance-aware Transferable Adversarial Attacks
Jul 29, 2021

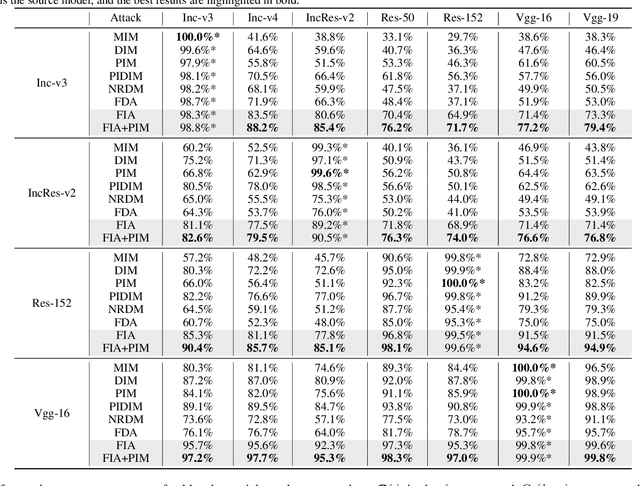
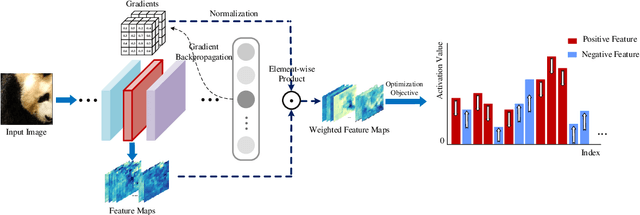
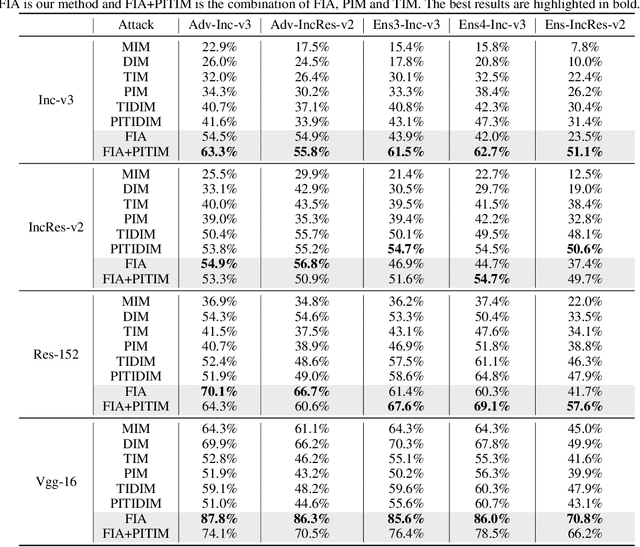
Transferability of adversarial examples is of central importance for attacking an unknown model, which facilitates adversarial attacks in more practical scenarios, e.g., blackbox attacks. Existing transferable attacks tend to craft adversarial examples by indiscriminately distorting features to degrade prediction accuracy in a source model without aware of intrinsic features of objects in the images. We argue that such brute-force degradation would introduce model-specific local optimum into adversarial examples, thus limiting the transferability. By contrast, we propose the Feature Importance-aware Attack (FIA), which disrupts important object-aware features that dominate model decisions consistently. More specifically, we obtain feature importance by introducing the aggregate gradient, which averages the gradients with respect to feature maps of the source model, computed on a batch of random transforms of the original clean image. The gradients will be highly correlated to objects of interest, and such correlation presents invariance across different models. Besides, the random transforms will preserve intrinsic features of objects and suppress model-specific information. Finally, the feature importance guides to search for adversarial examples towards disrupting critical features, achieving stronger transferability. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed FIA, i.e., improving the success rate by 8.4% against normally trained models and 11.7% against defense models as compared to the state-of-the-art transferable attacks. Code is available at: https://github.com/hcguoO0/FIA
An Intelligent Recommendation-cum-Reminder System
Aug 09, 2021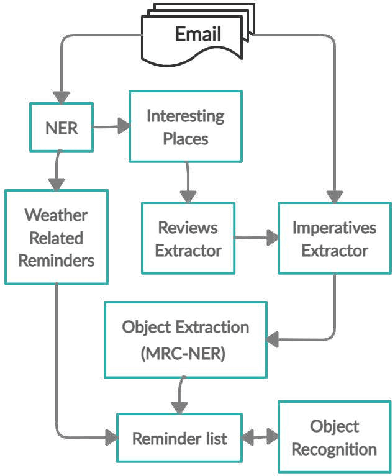

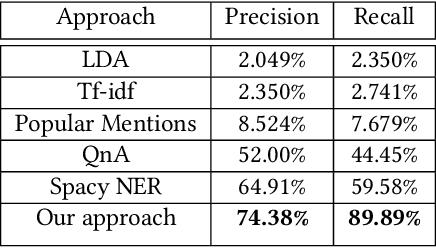
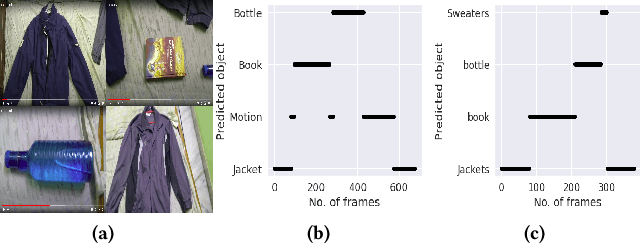
Intelligent recommendation and reminder systems are the need of the fast-pacing life. Current intelligent systems such as Siri, Google Assistant, Microsoft Cortona, etc., have limited capability. For example, if you want to wake up at 6 am because you have an upcoming trip, you have to set the alarm manually. Besides, these systems do not recommend or remind what else to carry, such as carrying an umbrella during a likely rain. The present work proposes a system that takes an email as input and returns a recommendation-cumreminder list. As a first step, we parse the emails, recognize the entities using named entity recognition (NER). In the second step, information retrieval over the web is done to identify nearby places, climatic conditions, etc. Imperative sentences from the reviews of all places are extracted and passed to the object extraction module. The main challenge lies in extracting the objects (items) of interest from the review. To solve it, a modified Machine Reading Comprehension-NER (MRC-NER) model is trained to tag objects of interest by formulating annotation rules as a query. The objects so found are recommended to the user one day in advance. The final reminder list of objects is pruned by our proposed model for tracking objects kept during the "packing activity." Eventually, when the user leaves for the event/trip, an alert is sent containing the reminding list items. Our approach achieves superior performance compared to several baselines by as much as 30% on recall and 10% on precision.
Self adversarial attack as an augmentation method for immunohistochemical stainings
Mar 21, 2021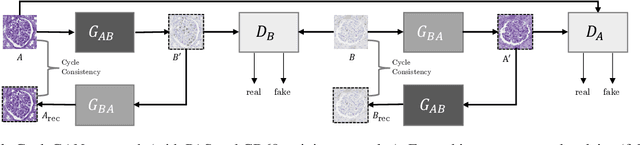
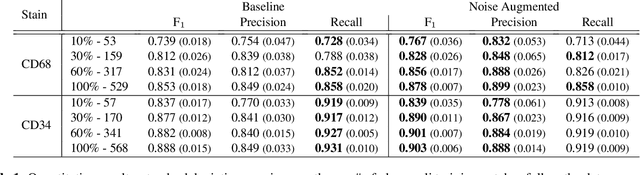
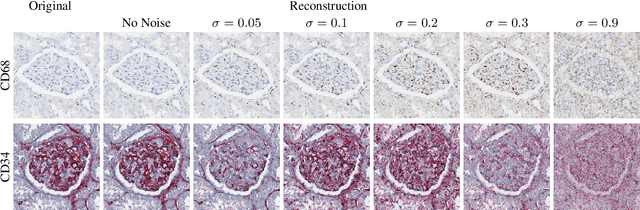
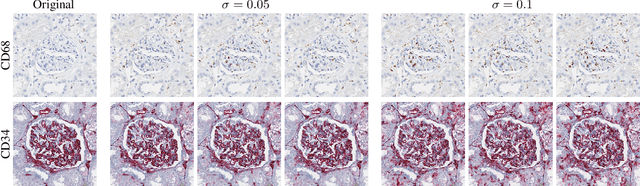
It has been shown that unpaired image-to-image translation methods constrained by cycle-consistency hide the information necessary for accurate input reconstruction as imperceptible noise. We demonstrate that, when applied to histopathology data, this hidden noise appears to be related to stain specific features and show that this is the case with two immunohistochemical stainings during translation to Periodic acid- Schiff (PAS), a histochemical staining method commonly applied in renal pathology. Moreover, by perturbing this hidden information, the translation models produce different, plausible outputs. We demonstrate that this property can be used as an augmentation method which, in a case of supervised glomeruli segmentation, leads to improved performance.
PPT Fusion: Pyramid Patch Transformerfor a Case Study in Image Fusion
Jul 29, 2021

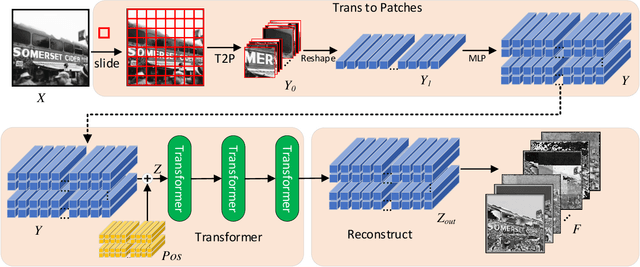
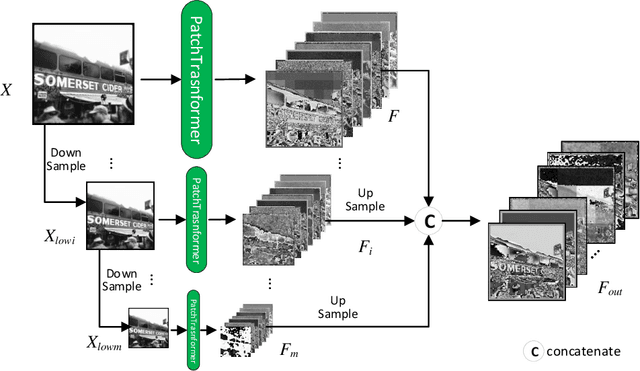
The Transformer architecture has achieved rapiddevelopment in recent years, outperforming the CNN archi-tectures in many computer vision tasks, such as the VisionTransformers (ViT) for image classification. However, existingvisual transformer models aim to extract semantic informationfor high-level tasks such as classification and detection, distortingthe spatial resolution of the input image, thus sacrificing thecapacity in reconstructing the input or generating high-resolutionimages. In this paper, therefore, we propose a Patch PyramidTransformer(PPT) to effectively address the above issues. Specif-ically, we first design a Patch Transformer to transform theimage into a sequence of patches, where transformer encodingis performed for each patch to extract local representations.In addition, we construct a Pyramid Transformer to effectivelyextract the non-local information from the entire image. Afterobtaining a set of multi-scale, multi-dimensional, and multi-anglefeatures of the original image, we design the image reconstructionnetwork to ensure that the features can be reconstructed intothe original input. To validate the effectiveness, we apply theproposed Patch Pyramid Transformer to the image fusion task.The experimental results demonstrate its superior performanceagainst the state-of-the-art fusion approaches, achieving the bestresults on several evaluation indicators. The underlying capacityof the PPT network is reflected by its universal power in featureextraction and image reconstruction, which can be directlyapplied to different image fusion tasks without redesigning orretraining the network.
Model Uncertainty and Correctability for Directed Graphical Models
Jul 17, 2021
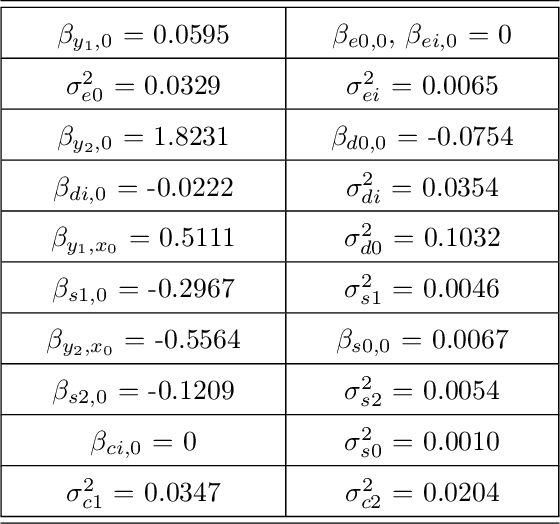


Probabilistic graphical models are a fundamental tool in probabilistic modeling, machine learning and artificial intelligence. They allow us to integrate in a natural way expert knowledge, physical modeling, heterogeneous and correlated data and quantities of interest. For exactly this reason, multiple sources of model uncertainty are inherent within the modular structure of the graphical model. In this paper we develop information-theoretic, robust uncertainty quantification methods and non-parametric stress tests for directed graphical models to assess the effect and the propagation through the graph of multi-sourced model uncertainties to quantities of interest. These methods allow us to rank the different sources of uncertainty and correct the graphical model by targeting its most impactful components with respect to the quantities of interest. Thus, from a machine learning perspective, we provide a mathematically rigorous approach to correctability that guarantees a systematic selection for improvement of components of a graphical model while controlling potential new errors created in the process in other parts of the model. We demonstrate our methods in two physico-chemical examples, namely quantum scale-informed chemical kinetics and materials screening to improve the efficiency of fuel cells.
Adaptive Event Detection for Representative Load Signature Extraction
Jul 23, 2021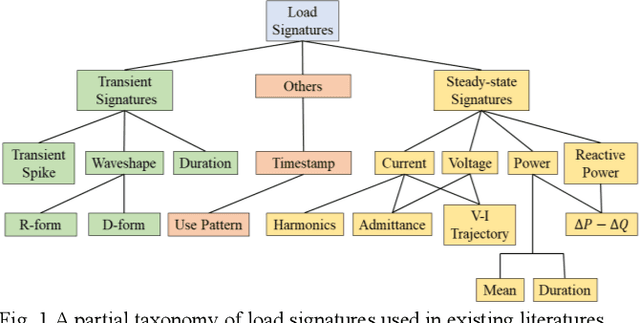
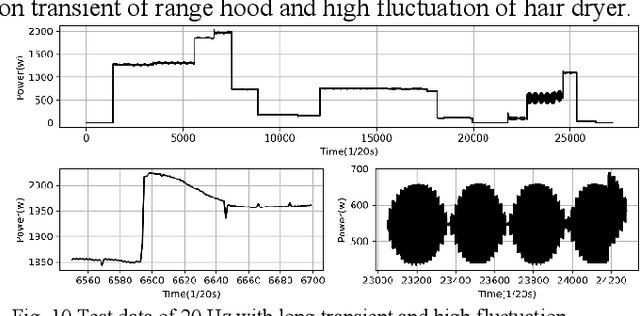
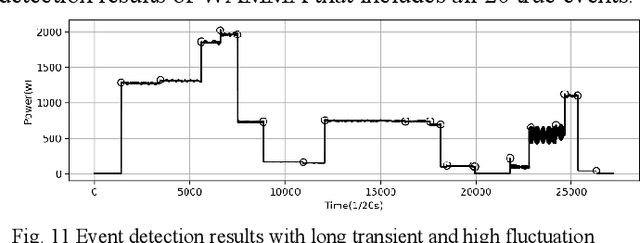
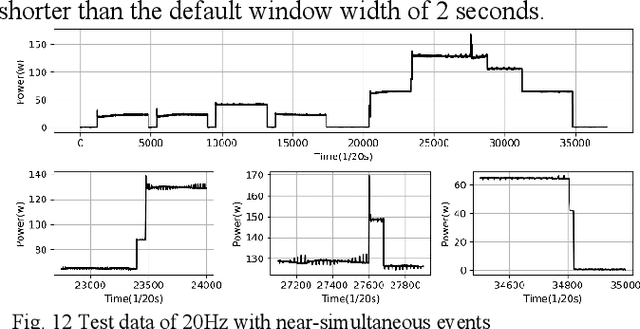
Event detection is the first step in event-based non-intrusive load monitoring (NILM) and it can provide useful transient information to identify appliances. However, existing event detection methods with fixed parameters may fail in case of unpredictable and complicated residential load changes such as high fluctuation, long transition, and near simultaneity. This paper proposes a dynamic time-window approach to deal with these highly complex load variations. Specifically, a window with adaptive margins, multi-timescale window screening, and adaptive threshold (WAMMA) method is proposed to detect events in aggregated home appliance load data with high sampling rate (>1Hz). The proposed method accurately captures the transient process by adaptively tuning parameters including window width, margin width, and change threshold. Furthermore, representative transient and steady-state load signatures are extracted and, for the first time, quantified from transient and steady periods segmented by detected events. Case studies on a 20Hz dataset, the 50Hz LIFTED dataset, and the 60Hz BLUED dataset show that the proposed method can robustly outperform other state-of-art event detection methods. This paper also shows that the extracted load signatures can improve NILM accuracy and help develop other applications such as load reconstruction to generate realistic load data for NILM research.
Perception Framework through Real-Time Semantic Segmentation and Scene Recognition on a Wearable System for the Visually Impaired
Mar 06, 2021

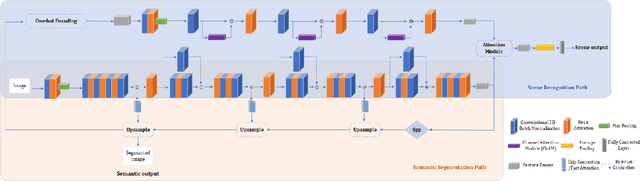
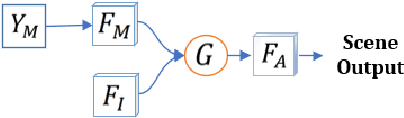
As the scene information, including objectness and scene type, are important for people with visual impairment, in this work we present a multi-task efficient perception system for the scene parsing and recognition tasks. Building on the compact ResNet backbone, our designed network architecture has two paths with shared parameters. In the structure, the semantic segmentation path integrates fast attention, with the aim of harvesting long-range contextual information in an efficient manner. Simultaneously, the scene recognition path attains the scene type inference by passing the semantic features into semantic-driven attention networks and combining the semantic extracted representations with the RGB extracted representations through a gated attention module. In the experiments, we have verified the systems' accuracy and efficiency on both public datasets and real-world scenes. This system runs on a wearable belt with an Intel RealSense LiDAR camera and an Nvidia Jetson AGX Xavier processor, which can accompany visually impaired people and provide assistive scene information in their navigation tasks.
Secure Dual-Functional Radar-Communication Transmission: Exploiting Interference for Resilience Against Target Eavesdropping
Jul 10, 2021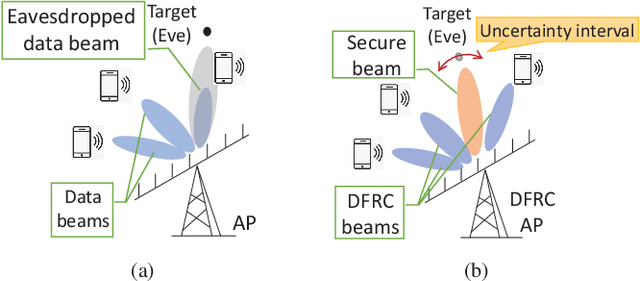
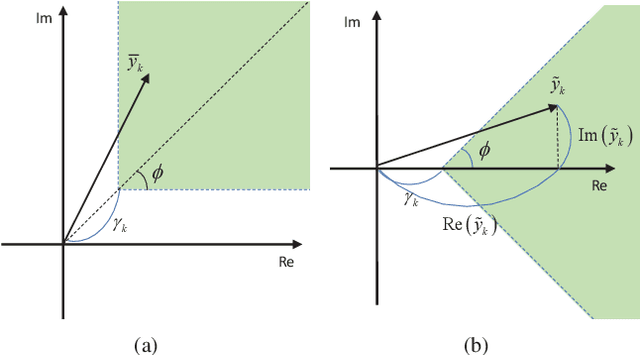
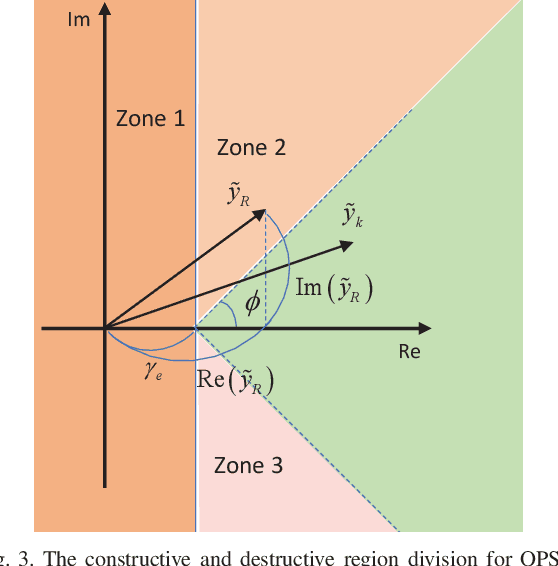
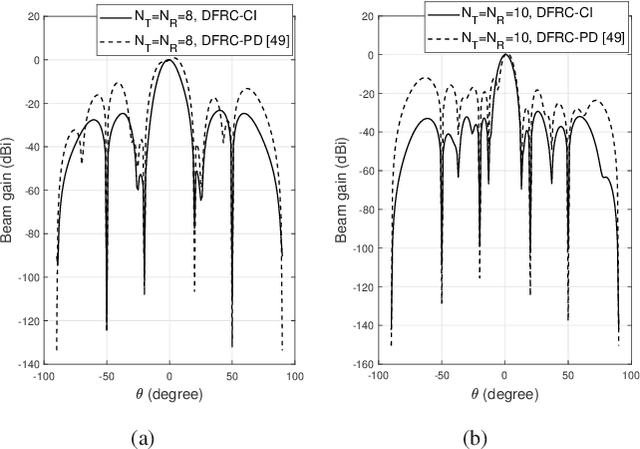
We study security solutions for dual-functional radar communication (DFRC) systems, which detect the radar target and communicate with downlink cellular users in millimeter-wave (mmWave) wireless networks simultaneously. Uniquely for such scenarios, the radar target is regarded as a potential eavesdropper which might surveil the information sent from the base station (BS) to communication users (CUs), that is carried by the radar probing signal. Transmit waveform and receive beamforming are jointly designed to maximize the signal-to-interference-plus-noise ratio (SINR) of the radar under the security and power budget constraints. We apply a Directional Modulation (DM) approach to exploit constructive interference (CI), where the known multiuser interference (MUI) can be exploited as a source of useful signal. Moreover, to further deteriorate the eavesdropping signal at the radar target, we utilize destructive interference (DI) by pushing the received symbols at the target towards the destructive region of the signal constellation. Our numerical results verify the effectiveness of the proposed design showing a secure transmission with enhanced performance against benchmark DFRC techniques.
LRG at TREC 2020: Document Ranking with XLNet-Based Models
Mar 06, 2021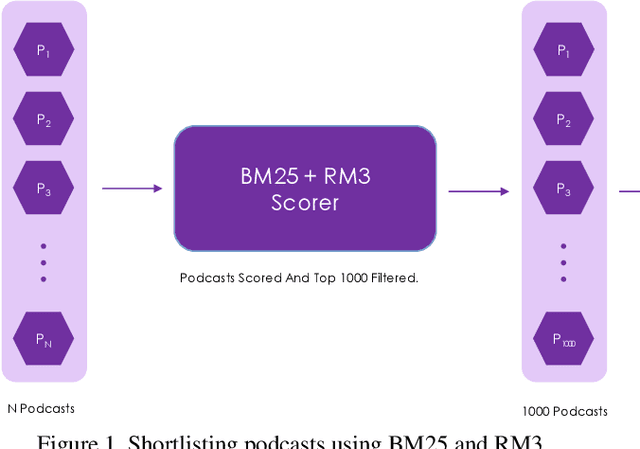

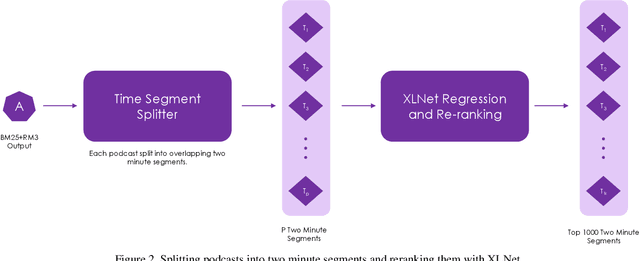
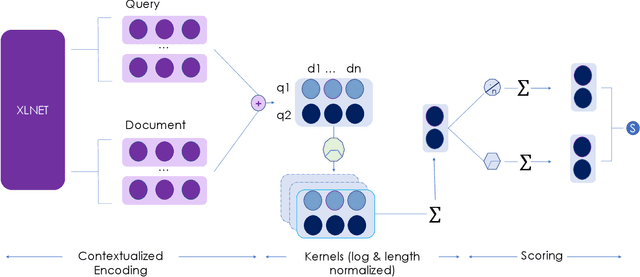
Establishing a good information retrieval system in popular mediums of entertainment is a quickly growing area of investigation for companies and researchers alike. We delve into the domain of information retrieval for podcasts. In Spotify's Podcast Challenge, we are given a user's query with a description to find the most relevant short segment from the given dataset having all the podcasts. Previous techniques that include solely classical Information Retrieval (IR) techniques, perform poorly when descriptive queries are presented. On the other hand, models which exclusively rely on large neural networks tend to perform better. The downside to this technique is that a considerable amount of time and computing power are required to infer the result. We experiment with two hybrid models which first filter out the best podcasts based on user's query with a classical IR technique, and then perform re-ranking on the shortlisted documents based on the detailed description using a transformer-based model.
* Published at TREC 2020
SmartHand: Towards Embedded Smart Hands for Prosthetic and Robotic Applications
Jul 23, 2021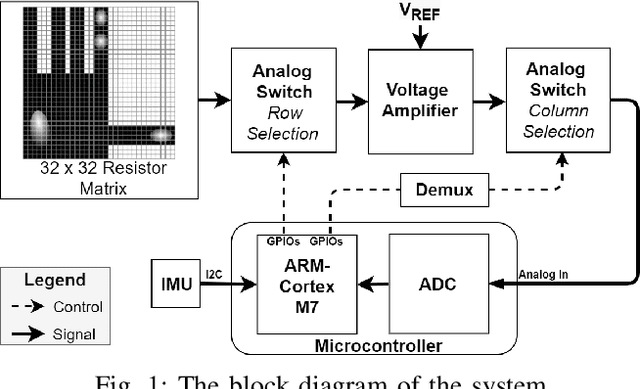
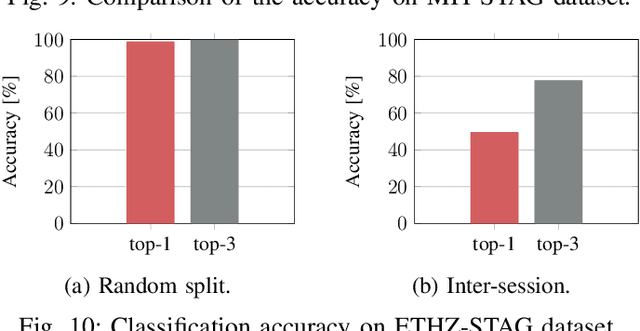


The sophisticated sense of touch of the human hand significantly contributes to our ability to safely, efficiently, and dexterously manipulate arbitrary objects in our environment. Robotic and prosthetic devices lack refined, tactile feedback from their end-effectors, leading to counterintuitive and complex control strategies. To address this lack, tactile sensors have been designed and developed, but they often offer an insufficient spatial and temporal resolution. This paper focuses on overcoming these issues by designing a smart embedded system, called SmartHand, enabling the acquisition and real-time processing of high-resolution tactile information from a hand-shaped multi-sensor array for prosthetic and robotic applications. We acquire a new tactile dataset consisting of 340,000 frames while interacting with 16 everyday objects and the empty hand, i.e., a total of 17 classes. The design of the embedded system minimizes response latency in classification, by deploying a small yet accurate convolutional neural network on a high-performance ARM Cortex-M7 microcontroller. Compared to related work, our model requires one order of magnitude less memory and 15.6x fewer computations while achieving similar inter-session accuracy and up to 98.86% and 99.83% top-1 and top-3 cross-validation accuracy, respectively. Experimental results show a total power consumption of 505mW and a latency of only 100ms.