 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatellite-Free Training for Drone-View Geo-Localization
Apr 02, 2026Drone-view geo-localization (DVGL) aims to determine the location of drones in GPS-denied environments by retrieving the corresponding geotagged satellite tile from a reference gallery given UAV observations of a location. In many existing formulations, these observations are represented by a single oblique UAV image. In contrast, our satellite-free setting is designed for multi-view UAV sequences, which are used to construct a geometry-normalized UAV-side location representation before cross-view retrieval. Existing approaches rely on satellite imagery during training, either through paired supervision or unsupervised alignment, which limits practical deployment when satellite data are unavailable or restricted. In this paper, we propose a satellite-free training (SFT) framework that converts drone imagery into cross-view compatible representations through three main stages: drone-side 3D scene reconstruction, geometry-based pseudo-orthophoto generation, and satellite-free feature aggregation for retrieval. Specifically, we first reconstruct dense 3D scenes from multi-view drone images using 3D Gaussian splatting and project the reconstructed geometry into pseudo-orthophotos via PCA-guided orthographic projection. This rendering stage operates directly on reconstructed scene geometry without requiring camera parameters at rendering time. Next, we refine these orthophotos with lightweight geometry-guided inpainting to obtain texture-complete drone-side views. Finally, we extract DINOv3 patch features from the generated orthophotos, learn a Fisher vector aggregation model solely from drone data, and reuse it at test time to encode satellite tiles for cross-view retrieval. Experimental results on University-1652 and SUES-200 show that our SFT framework substantially outperforms satellite-free generalization baselines and narrows the gap to methods trained with satellite imagery.
A Novel Driver Distraction Behavior Detection Based on Self-Supervised Learning Framework with Masked Image Modeling
Jun 13, 2023



Driver distraction causes a significant number of traffic accidents every year, resulting in economic losses and casualties. Currently, the level of automation in commercial vehicles is far from completely unmanned, and drivers still play an important role in operating and controlling the vehicle. Therefore, driver distraction behavior detection is crucial for road safety. At present, driver distraction detection primarily relies on traditional Convolutional Neural Networks (CNN) and supervised learning methods. However, there are still challenges such as the high cost of labeled datasets, limited ability to capture high-level semantic information, and weak generalization performance. In order to solve these problems, this paper proposes a new self-supervised learning method based on masked image modeling for driver distraction behavior detection. Firstly, a self-supervised learning framework for masked image modeling (MIM) is introduced to solve the serious human and material consumption issues caused by dataset labeling. Secondly, the Swin Transformer is employed as an encoder. Performance is enhanced by reconfiguring the Swin Transformer block and adjusting the distribution of the number of window multi-head self-attention (W-MSA) and shifted window multi-head self-attention (SW-MSA) detection heads across all stages, which leads to model more lightening. Finally, various data augmentation strategies are used along with the best random masking strategy to strengthen the model's recognition and generalization ability. Test results on a large-scale driver distraction behavior dataset show that the self-supervised learning method proposed in this paper achieves an accuracy of 99.60%, approximating the excellent performance of advanced supervised learning methods.
Perception Framework through Real-Time Semantic Segmentation and Scene Recognition on a Wearable System for the Visually Impaired
Mar 06, 2021

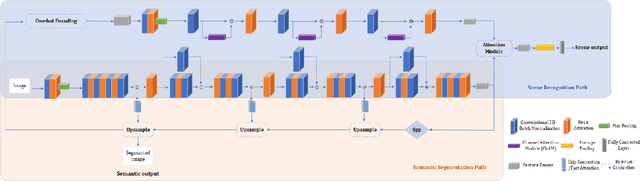
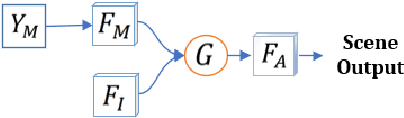
As the scene information, including objectness and scene type, are important for people with visual impairment, in this work we present a multi-task efficient perception system for the scene parsing and recognition tasks. Building on the compact ResNet backbone, our designed network architecture has two paths with shared parameters. In the structure, the semantic segmentation path integrates fast attention, with the aim of harvesting long-range contextual information in an efficient manner. Simultaneously, the scene recognition path attains the scene type inference by passing the semantic features into semantic-driven attention networks and combining the semantic extracted representations with the RGB extracted representations through a gated attention module. In the experiments, we have verified the systems' accuracy and efficiency on both public datasets and real-world scenes. This system runs on a wearable belt with an Intel RealSense LiDAR camera and an Nvidia Jetson AGX Xavier processor, which can accompany visually impaired people and provide assistive scene information in their navigation tasks.