 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRG at TREC 2020: Document Ranking with XLNet-Based Models
Paper and Code
Mar 06, 2021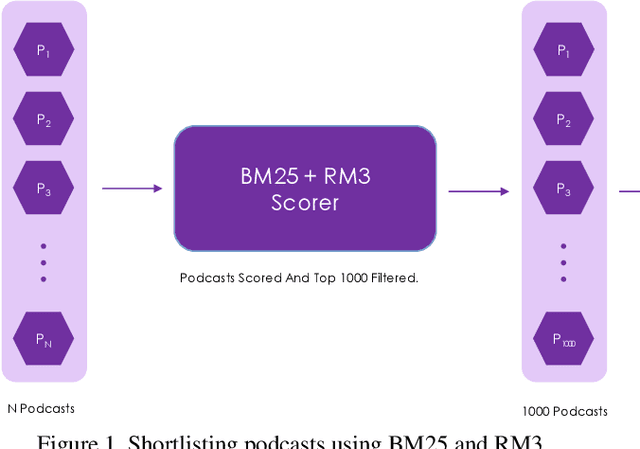

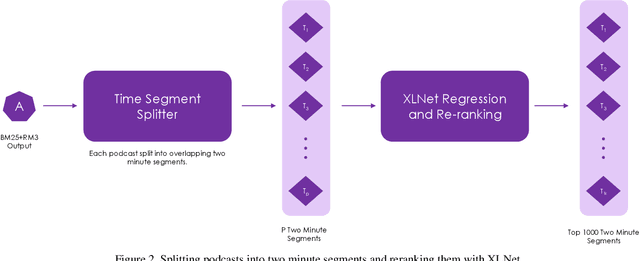
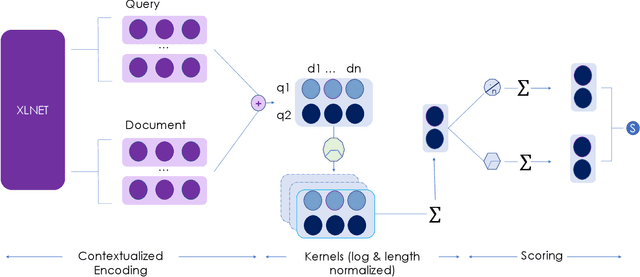
Establishing a good information retrieval system in popular mediums of entertainment is a quickly growing area of investigation for companies and researchers alike. We delve into the domain of information retrieval for podcasts. In Spotify's Podcast Challenge, we are given a user's query with a description to find the most relevant short segment from the given dataset having all the podcasts. Previous techniques that include solely classical Information Retrieval (IR) techniques, perform poorly when descriptive queries are presented. On the other hand, models which exclusively rely on large neural networks tend to perform better. The downside to this technique is that a considerable amount of time and computing power are required to infer the result. We experiment with two hybrid models which first filter out the best podcasts based on user's query with a classical IR technique, and then perform re-ranking on the shortlisted documents based on the detailed description using a transformer-based model.