 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SHADE: Information Based Regularization for Deep Learning
May 22, 2018
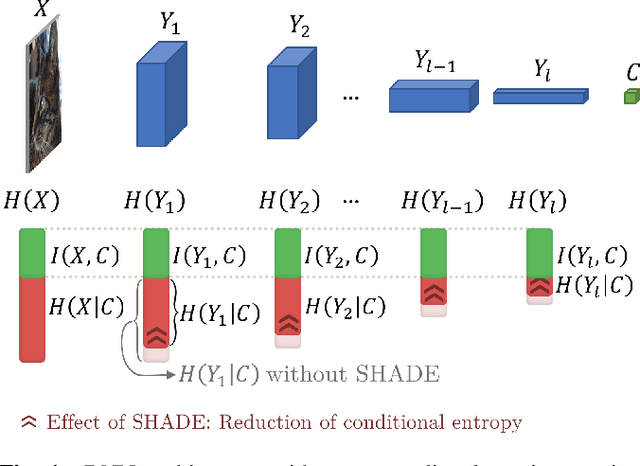
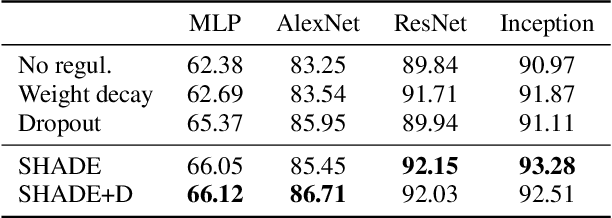
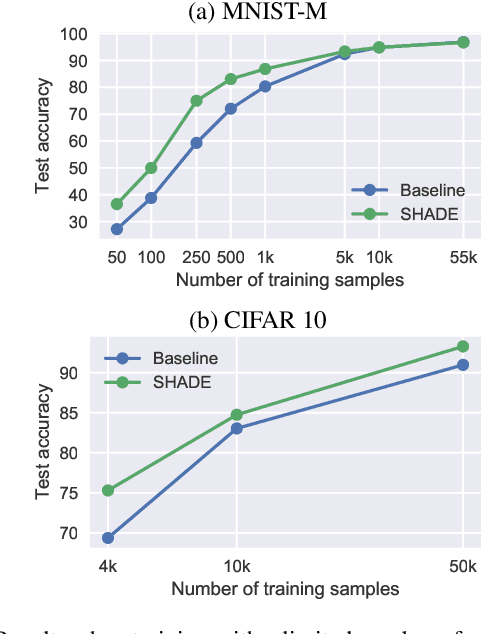

Regularization is a big issue for training deep neural networks. In this paper, we propose a new information-theory-based regularization scheme named SHADE for SHAnnon DEcay. The originality of the approach is to define a prior based on conditional entropy, which explicitly decouples the learning of invariant representations in the regularizer and the learning of correlations between inputs and labels in the data fitting term. Our second contribution is to derive a stochastic version of the regularizer compatible with deep learning, resulting in a tractable training scheme. We empirically validate the efficiency of our approach to improve classification performances compared to common regularization schemes on several standard architectures.
Standardized Max Logits: A Simple yet Effective Approach for Identifying Unexpected Road Obstacles in Urban-Scene Segmentation
Aug 12, 2021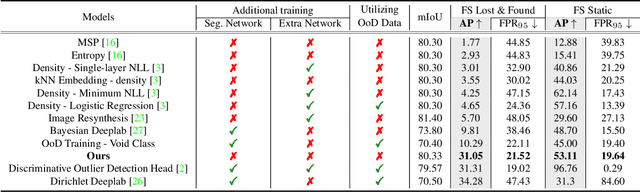
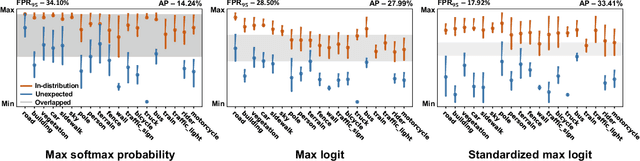


Identifying unexpected objects on roads in semantic segmentation (e.g., identifying dogs on roads) is crucial in safety-critical applications. Existing approaches use images of unexpected objects from external datasets or require additional training (e.g., retraining segmentation networks or training an extra network), which necessitate a non-trivial amount of labor intensity or lengthy inference time. One possible alternative is to use prediction scores of a pre-trained network such as the max logits (i.e., maximum values among classes before the final softmax layer) for detecting such objects. However, the distribution of max logits of each predicted class is significantly different from each other, which degrades the performance of identifying unexpected objects in urban-scene segmentation. To address this issue, we propose a simple yet effective approach that standardizes the max logits in order to align the different distributions and reflect the relative meanings of max logits within each predicted class. Moreover, we consider the local regions from two different perspectives based on the intuition that neighboring pixels share similar semantic information. In contrast to previous approaches, our method does not utilize any external datasets or require additional training, which makes our method widely applicable to existing pre-trained segmentation models. Such a straightforward approach achieves a new state-of-the-art performance on the publicly available Fishyscapes Lost & Found leaderboard with a large margin.
Neural Response Interpretation through the Lens of Critical Pathways
Mar 31, 2021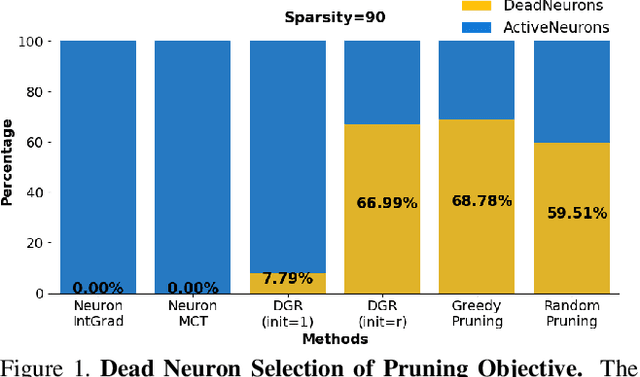
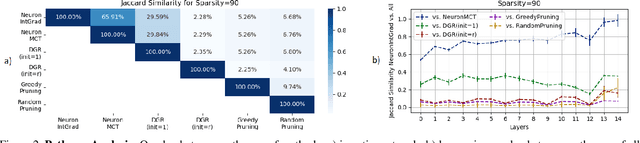
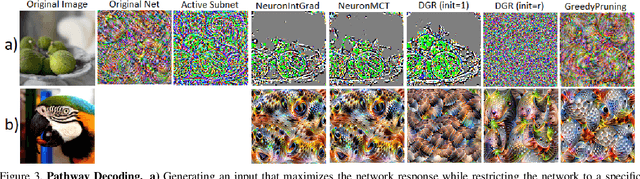

Is critical input information encoded in specific sparse pathways within the neural network? In this work, we discuss the problem of identifying these critical pathways and subsequently leverage them for interpreting the network's response to an input. The pruning objective -- selecting the smallest group of neurons for which the response remains equivalent to the original network -- has been previously proposed for identifying critical pathways. We demonstrate that sparse pathways derived from pruning do not necessarily encode critical input information. To ensure sparse pathways include critical fragments of the encoded input information, we propose pathway selection via neurons' contribution to the response. We proceed to explain how critical pathways can reveal critical input features. We prove that pathways selected via neuron contribution are locally linear (in an L2-ball), a property that we use for proposing a feature attribution method: "pathway gradient". We validate our interpretation method using mainstream evaluation experiments. The validation of pathway gradient interpretation method further confirms that selected pathways using neuron contributions correspond to critical input features. The code is publicly available.
Semantic Concentration for Domain Adaptation
Aug 12, 2021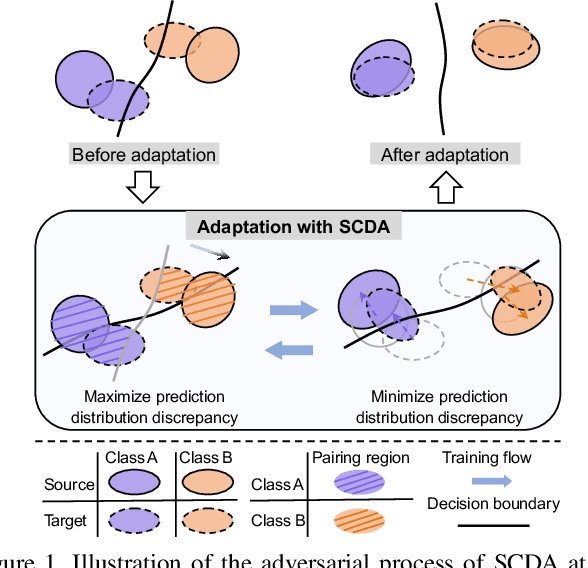
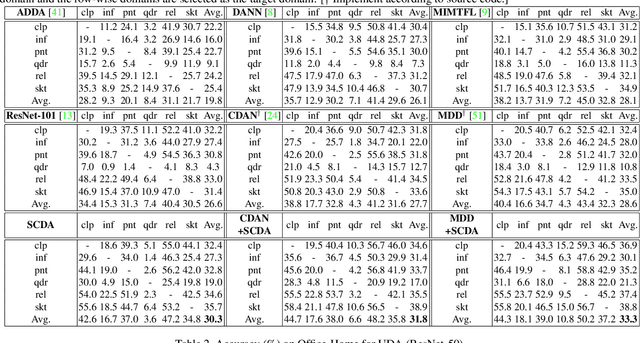
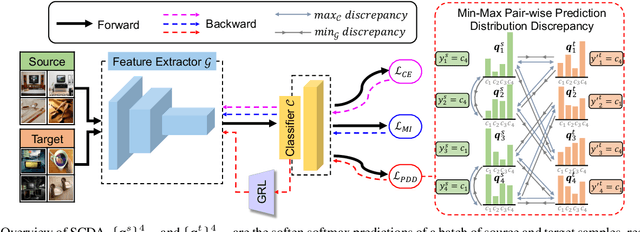
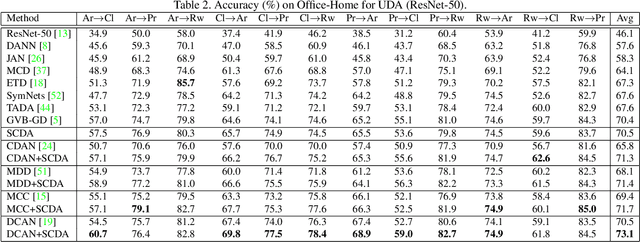
Domain adaptation (DA) paves the way for label annotation and dataset bias issues by the knowledge transfer from a label-rich source domain to a related but unlabeled target domain. A mainstream of DA methods is to align the feature distributions of the two domains. However, the majority of them focus on the entire image features where irrelevant semantic information, e.g., the messy background, is inevitably embedded. Enforcing feature alignments in such case will negatively influence the correct matching of objects and consequently lead to the semantically negative transfer due to the confusion of irrelevant semantics. To tackle this issue, we propose Semantic Concentration for Domain Adaptation (SCDA), which encourages the model to concentrate on the most principal features via the pair-wise adversarial alignment of prediction distributions. Specifically, we train the classifier to class-wisely maximize the prediction distribution divergence of each sample pair, which enables the model to find the region with large differences among the same class of samples. Meanwhile, the feature extractor attempts to minimize that discrepancy, which suppresses the features of dissimilar regions among the same class of samples and accentuates the features of principal parts. As a general method, SCDA can be easily integrated into various DA methods as a regularizer to further boost their performance. Extensive experiments on the cross-domain benchmarks show the efficacy of SCDA.
Deep Motion Prior for Weakly-Supervised Temporal Action Localization
Aug 12, 2021
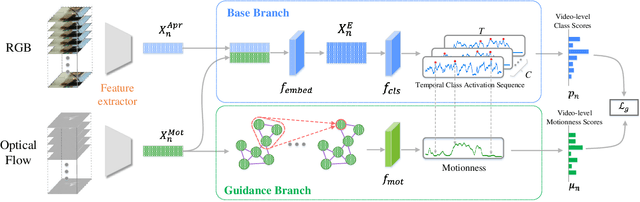
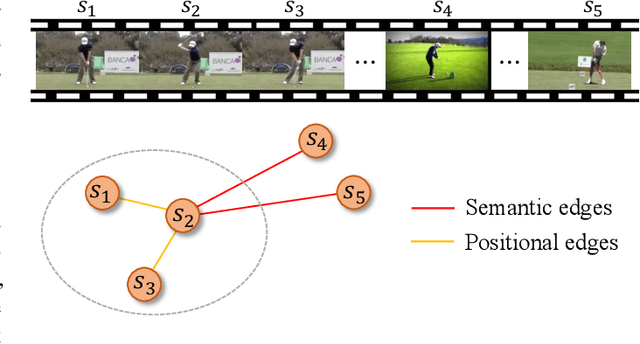
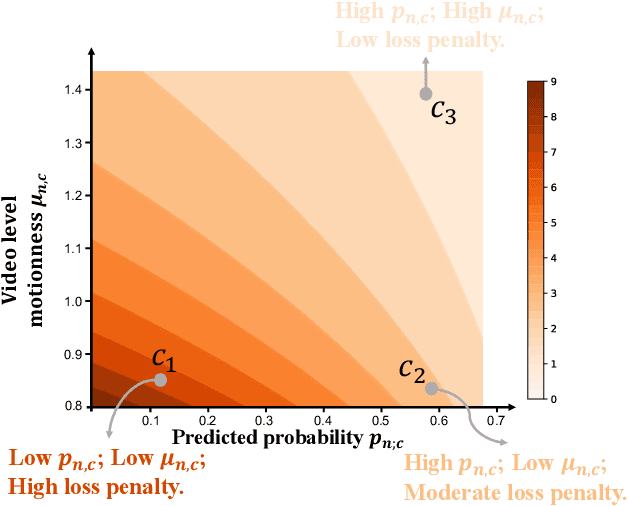
Weakly-Supervised Temporal Action Localization (WSTAL) aims to localize actions in untrimmed videos with only video-level labels. Currently, most state-of-the-art WSTAL methods follow a Multi-Instance Learning (MIL) pipeline: producing snippet-level predictions first and then aggregating to the video-level prediction. However, we argue that existing methods have overlooked two important drawbacks: 1) inadequate use of motion information and 2) the incompatibility of prevailing cross-entropy training loss. In this paper, we analyze that the motion cues behind the optical flow features are complementary informative. Inspired by this, we propose to build a context-dependent motion prior, termed as motionness. Specifically, a motion graph is introduced to model motionness based on the local motion carrier (e.g., optical flow). In addition, to highlight more informative video snippets, a motion-guided loss is proposed to modulate the network training conditioned on motionness scores. Extensive ablation studies confirm that motionness efficaciously models action-of-interest, and the motion-guided loss leads to more accurate results. Besides, our motion-guided loss is a plug-and-play loss function and is applicable with existing WSTAL methods. Without loss of generality, based on the standard MIL pipeline, our method achieves new state-of-the-art performance on three challenging benchmarks, including THUMOS'14, ActivityNet v1.2 and v1.3.
Predicting Flight Delay with Spatio-Temporal Trajectory Convolutional Network and Airport Situational Awareness Map
May 19, 2021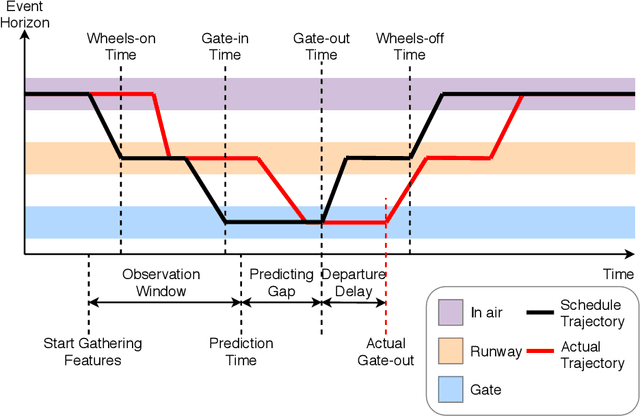
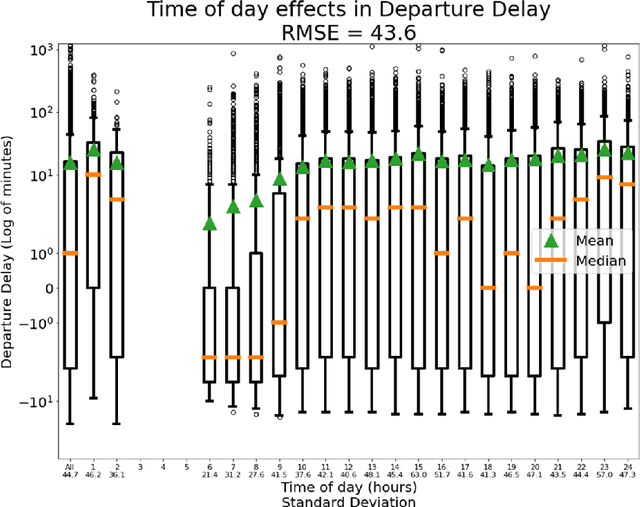
To model and forecast flight delays accurately, it is crucial to harness various vehicle trajectory and contextual sensor data on airport tarmac areas. These heterogeneous sensor data, if modelled correctly, can be used to generate a situational awareness map. Existing techniques apply traditional supervised learning methods onto historical data, contextual features and route information among different airports to predict flight delay are inaccurate and only predict arrival delay but not departure delay, which is essential to airlines. In this paper, we propose a vision-based solution to achieve a high forecasting accuracy, applicable to the airport. Our solution leverages a snapshot of the airport situational awareness map, which contains various trajectories of aircraft and contextual features such as weather and airline schedules. We propose an end-to-end deep learning architecture, TrajCNN, which captures both the spatial and temporal information from the situational awareness map. Additionally, we reveal that the situational awareness map of the airport has a vital impact on estimating flight departure delay. Our proposed framework obtained a good result (around 18 minutes error) for predicting flight departure delay at Los Angeles International Airport.
Multiple scattering ambisonics: three-dimensional sound foeld estimation using interacting spheres
Jun 14, 2021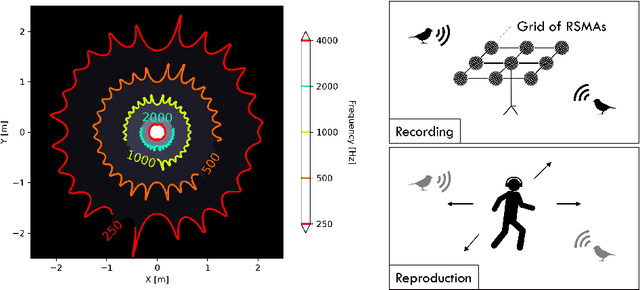

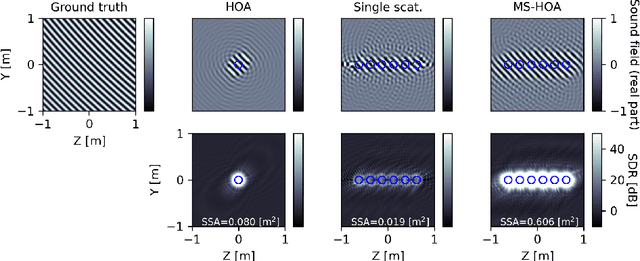
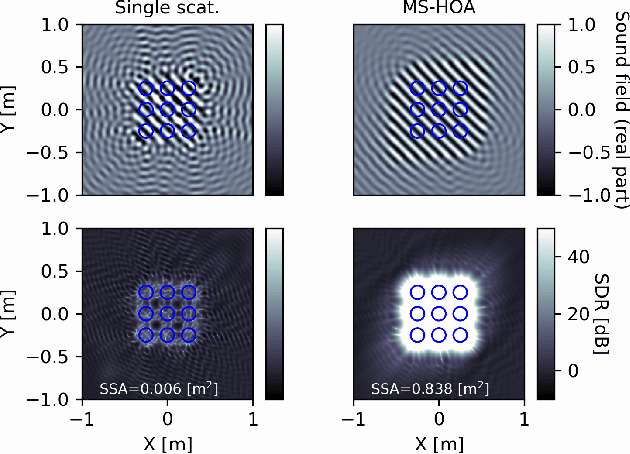
Rigid spherical microphone arrays (RSMAs) have been widely used in ambisonics sound field recording. While it is desired to combine the information captured by a grid of densely arranged RSMAs for expanding the area of accurate reconstruction, or sweet-spots, this is not trivial due to inter-array interference. Here we propose multiple scattering ambisonics, a method for three-dimensional ambisonics sound field recording using multiple acoustically interacting RSMAs. Numerical experiments demonstrate the sweet-spot expansion realized by the proposed method. The proposed method can be used with existing RSMAs as building blocks and opens possibilities including higher degrees-of-freedom spatial audio.
The Law of Large Documents: Understanding the Structure of Legal Contracts Using Visual Cues
Jul 16, 2021
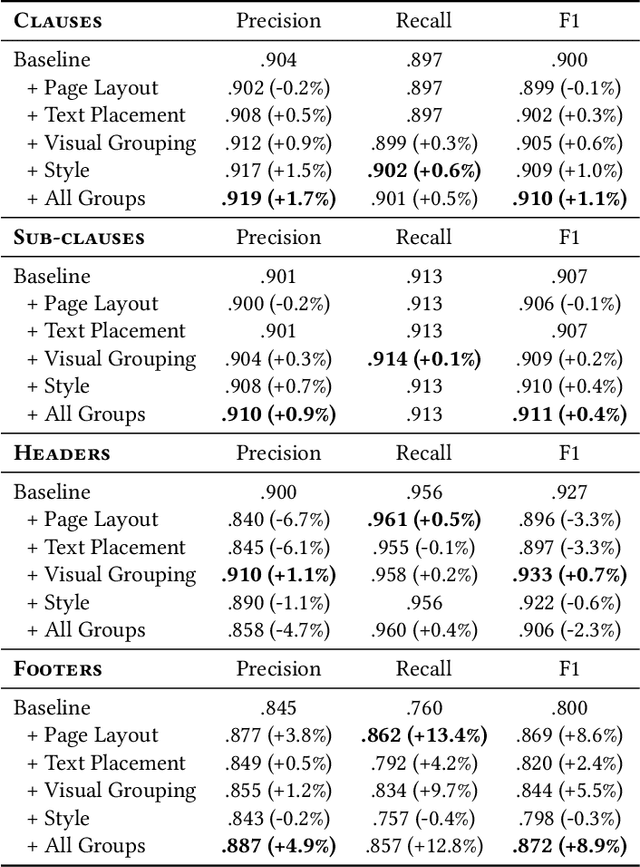
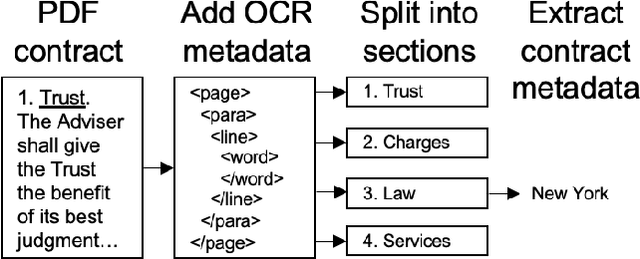
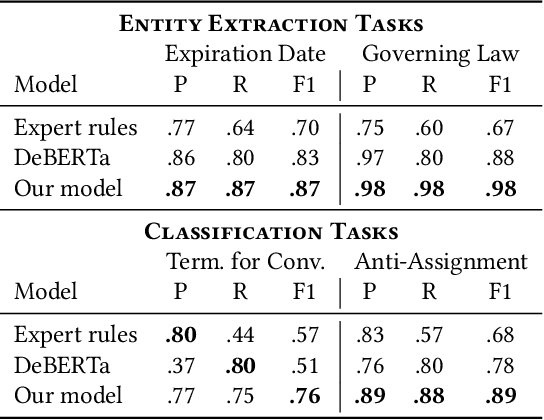
Large, pre-trained transformer models like BERT have achieved state-of-the-art results on document understanding tasks, but most implementations can only consider 512 tokens at a time. For many real-world applications, documents can be much longer, and the segmentation strategies typically used on longer documents miss out on document structure and contextual information, hurting their results on downstream tasks. In our work on legal agreements, we find that visual cues such as layout, style, and placement of text in a document are strong features that are crucial to achieving an acceptable level of accuracy on long documents. We measure the impact of incorporating such visual cues, obtained via computer vision methods, on the accuracy of document understanding tasks including document segmentation, entity extraction, and attribute classification. Our method of segmenting documents based on structural metadata out-performs existing methods on four long-document understanding tasks as measured on the Contract Understanding Atticus Dataset.
Robust End-to-End Offline Chinese Handwriting Text Page Spotter with Text Kernel
Jul 04, 2021
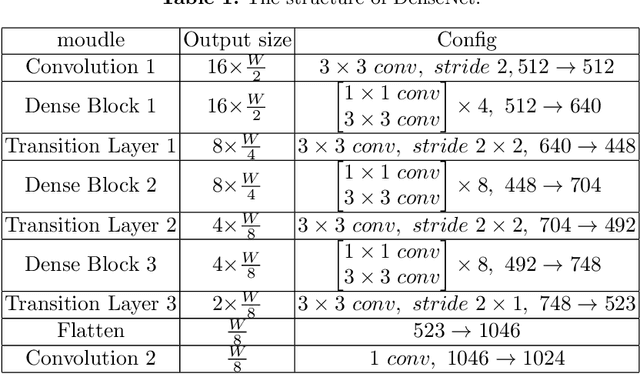
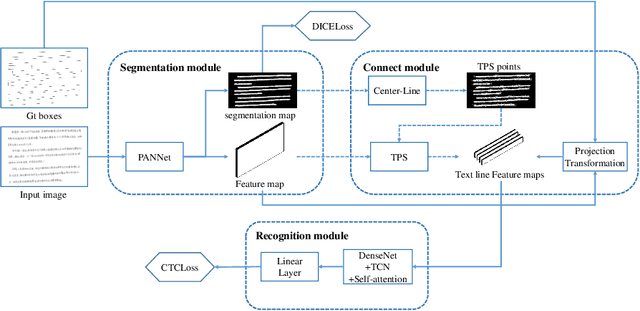
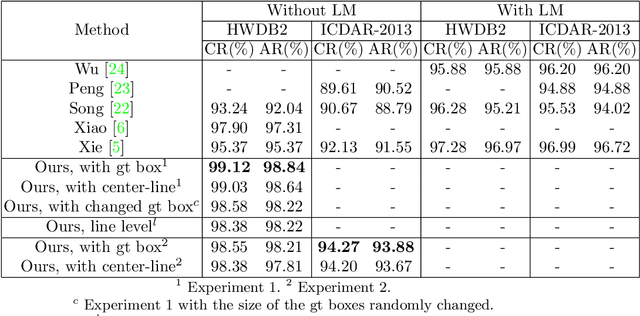
Offline Chinese handwriting text recognition is a long-standing research topic in the field of pattern recognition. In previous studies, text detection and recognition are separated, which leads to the fact that text recognition is highly dependent on the detection results. In this paper, we propose a robust end-to-end Chinese text page spotter framework. It unifies text detection and text recognition with text kernel that integrates global text feature information to optimize the recognition from multiple scales, which reduces the dependence of detection and improves the robustness of the system. Our method achieves state-of-the-art results on the CASIA-HWDB2.0-2.2 dataset and ICDAR-2013 competition dataset. Without any language model, the correct rates are 99.12% and 94.27% for line-level recognition, and 99.03% and 94.20% for page-level recognition, respectively.
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
Jul 12, 2021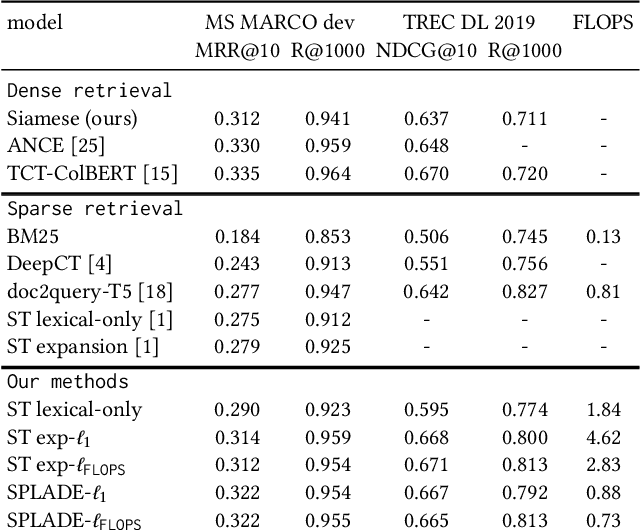
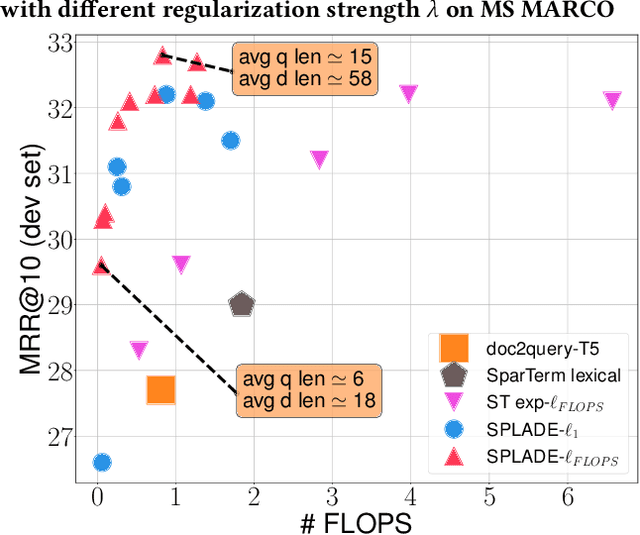

In neural Information Retrieval, ongoing research is directed towards improving the first retriever in ranking pipelines. Learning dense embeddings to conduct retrieval using efficient approximate nearest neighbors methods has proven to work well. Meanwhile, there has been a growing interest in learning sparse representations for documents and queries, that could inherit from the desirable properties of bag-of-words models such as the exact matching of terms and the efficiency of inverted indexes. In this work, we present a new first-stage ranker based on explicit sparsity regularization and a log-saturation effect on term weights, leading to highly sparse representations and competitive results with respect to state-of-the-art dense and sparse methods. Our approach is simple, trained end-to-end in a single stage. We also explore the trade-off between effectiveness and efficiency, by controlling the contribution of the sparsity regularization.