 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automated Enterprise Architecture Model Mining
Aug 15, 2021
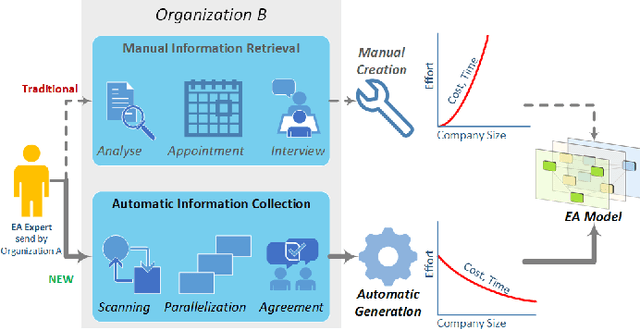
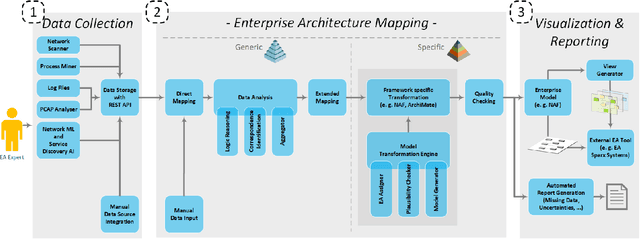

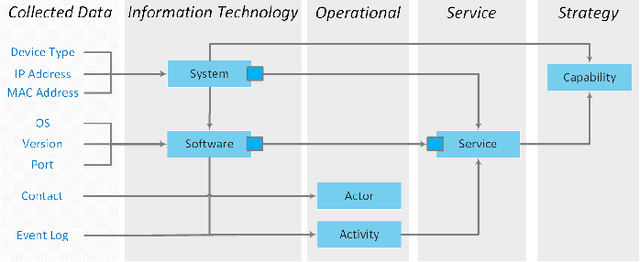
Metadata are like the steam engine of the 21st century, driving businesses and offer multiple enhancements. Nevertheless, many companies are unaware that these data can be used efficiently to improve their own operation. This is where the Enterprise Architecture Framework comes in. It empowers an organisation to get a clear view of their business, application, technical and physical layer. This modelling approach is an established method for organizations to take a deeper look into their structure and processes. The development of such models requires a great deal of effort, is carried out manually by interviewing stakeholders and requires continuous maintenance. Our new approach enables the automated mining of Enterprise Architecture models. The system uses common technologies to collect the metadata based on network traffic, log files and other information in an organisation. Based on this, the new approach generates EA models with the desired views points. Furthermore, a rule and knowledge-based reasoning is used to obtain a holistic overview. This offers a strategic decision support from business structure over process design up to planning the appropriate support technology. Therefore, it forms the base for organisations to act in an agile way. The modelling can be performed in different modelling languages, including ArchiMate and the Nato Architecture Framework (NAF). The designed approach is already evaluated on a small company with multiple services and an infrastructure with several nodes.
Structuring and presenting data for testing of automotive electronics to reduce effort during decision making
Apr 23, 2021


Automotive engineering is recognized as a combination of software and mechanical engineering due to the ever-increasing number of software-based components in vehicles. Since vehicles have become more sophisticated than before to ensure robustness, testing of automotive electronics is performed in high volume, producing immense test-related data. This study investigates how unstructured and decentralized test-related data from testing of automotive electronics creates issues in decision making during the testing and analysis process of test artifacts by performing an exploratory case-study at one of the leading automotive companies, Volvo Cars. From the findings of the exploratory study, a prototype was designed to improve the data and information structure and presentation for test analysis and diagnostics for automotive electronics. The prototype's results showed that providing better data and information structure significantly increases the efficiency and reduces the workload for testers when conducting test analysis and diagnostics. Testers showed a decrease in task load for tasks related to testing due to better information structure, presentation, correctness and accessibility. Hence, the improvements aided the testers to arrive at decisions regarding root cause analysis of failed tests efficiently. The findings of this study can assist automotive companies in systematically investigating and improving the testing process of automotive electronics in regards to managing and structuring test-related data. Keywords: Testing, Automotive Electronics, Electronic Control Unit, ECU, Unstructured Data.
HeteroMed: Heterogeneous Information Network for Medical Diagnosis
Apr 22, 2018

With the recent availability of Electronic Health Records (EHR) and great opportunities they offer for advancing medical informatics, there has been growing interest in mining EHR for improving quality of care. Disease diagnosis due to its sensitive nature, huge costs of error, and complexity has become an increasingly important focus of research in past years. Existing studies model EHR by capturing co-occurrence of clinical events to learn their latent embeddings. However, relations among clinical events carry various semantics and contribute differently to disease diagnosis which gives precedence to a more advanced modeling of heterogeneous data types and relations in EHR data than existing solutions. To address these issues, we represent how high-dimensional EHR data and its rich relationships can be suitably translated into HeteroMed, a heterogeneous information network for robust medical diagnosis. Our modeling approach allows for straightforward handling of missing values and heterogeneity of data. HeteroMed exploits metapaths to capture higher level and semantically important relations contributing to disease diagnosis. Furthermore, it employs a joint embedding framework to tailor clinical event representations to the disease diagnosis goal. To the best of our knowledge, this is the first study to use Heterogeneous Information Network for modeling clinical data and disease diagnosis. Experimental results of our study show superior performance of HeteroMed compared to prior methods in prediction of exact diagnosis codes and general disease cohorts. Moreover, HeteroMed outperforms baseline models in capturing similarities of clinical events which are examined qualitatively through case studies.
Side Information for Face Completion: a Robust PCA Approach
Jan 20, 2018
Robust principal component analysis (RPCA) is a powerful method for learning low-rank feature representation of various visual data. However, for certain types as well as significant amount of error corruption, it fails to yield satisfactory results; a drawback that can be alleviated by exploiting domain-dependent prior knowledge or information. In this paper, we propose two models for the RPCA that take into account such side information, even in the presence of missing values. We apply this framework to the task of UV completion which is widely used in pose-invariant face recognition. Moreover, we construct a generative adversarial network (GAN) to extract side information as well as subspaces. These subspaces not only assist in the recovery but also speed up the process in case of large-scale data. We quantitatively and qualitatively evaluate the proposed approaches through both synthetic data and five real-world datasets to verify their effectiveness.
SaNet: Scale-aware Neural Network for Semantic Labelling of Multiple Spatial Resolution Aerial Images
Apr 10, 2021


Assigning geospatial objects of aerial images with specific categories at the pixel level is a fundamental task in urban scene interpretation. Along with rapid developments in sensor technologies, aerial images can be captured at multiple spatial resolutions (MSR) with information content manifested at different scales. Extracting information from these MSR aerial images represents huge opportunities for enhanced feature representation and characterisation. However, MSR images suffer from two critical issues: 1) increased variation in the sizes of geospatial objects and 2) information and informative feature loss at coarse spatial resolutions. In this paper, we propose a novel scale-aware neural network (SaNet) for semantic labelling of MSR aerial images to address these two issues. SaNet deploys a densely connected feature network (DCFPN) module to capture high-quality multi-scale context, such as to address the scale variation issue and increase the quality of segmentation for both large and small objects simultaneously. A spatial feature recalibration (SFR) module is further incorporated into the network to learn complete semantic features with enhanced spatial relationships, where the effects of information and informative feature loss are addressed. The combination of DCFPN and SFR allows the proposed SaNet to learn scale-aware features from MSR aerial images. Extensive experiments undertaken on ISPRS semantic segmentation datasets demonstrated the outstanding accuracy of the proposed SaNet in cross-resolution segmentation, with an average OA of 83.4% on the Vaihingen dataset and an average F1 score of 80.4% on the Potsdam dataset, outperforming state-of-the-art deep learning approaches, including FPN (80.2% and 76.6%), PSPNet (79.8% and 76.2%) and Deeplabv3+ (80.8% and 76.1%) as well as DDCM-Net (81.7% and 77.6%) and EaNet (81.5% and 78.3%).
A Survey on Dialogue Summarization: Recent Advances and New Frontiers
Jul 07, 2021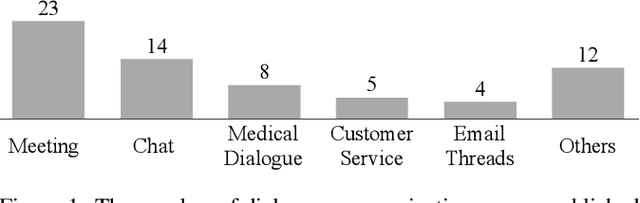
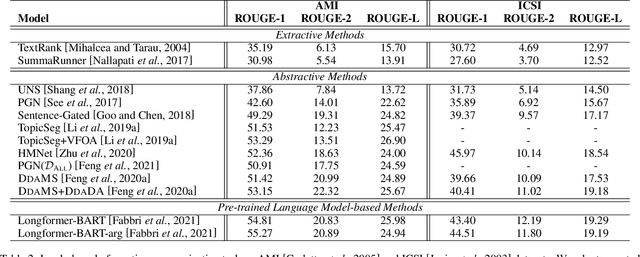

With the development of dialogue systems and natural language generation techniques, the resurgence of dialogue summarization has attracted significant research attentions, which aims to condense the original dialogue into a shorter version covering salient information. However, there remains a lack of comprehensive survey for this task. To this end, we take the first step and present a thorough review of this research field. In detail, we provide an overview of publicly available research datasets, summarize existing works according to the domain of input dialogue as well as organize leaderboards under unified metrics. Furthermore, we discuss some future directions and give our thoughts. We hope that this first survey of dialogue summarization can provide the community with a quick access and a general picture to this task and motivate future researches.
DeepWalking Backwards: From Embeddings Back to Graphs
Feb 17, 2021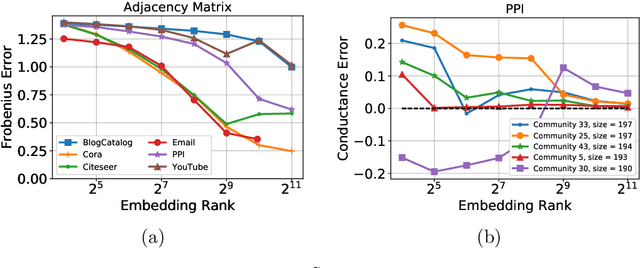
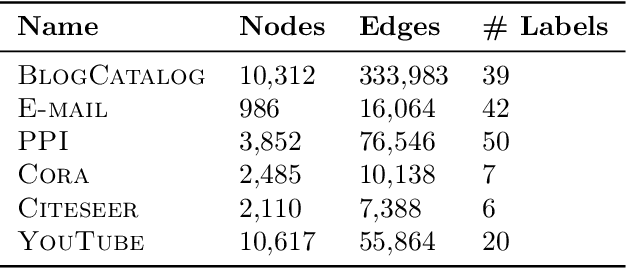
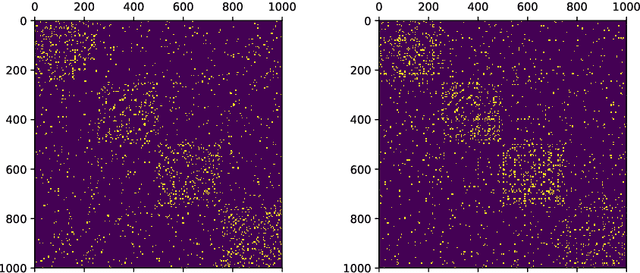
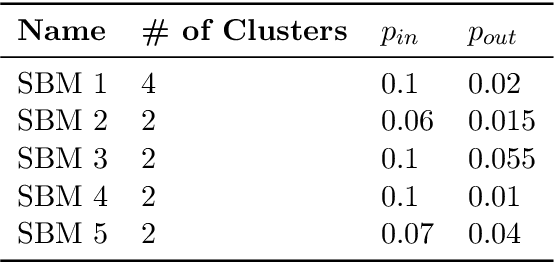
Low-dimensional node embeddings play a key role in analyzing graph datasets. However, little work studies exactly what information is encoded by popular embedding methods, and how this information correlates with performance in downstream machine learning tasks. We tackle this question by studying whether embeddings can be inverted to (approximately) recover the graph used to generate them. Focusing on a variant of the popular DeepWalk method (Perozzi et al., 2014; Qiu et al., 2018), we present algorithms for accurate embedding inversion - i.e., from the low-dimensional embedding of a graph G, we can find a graph H with a very similar embedding. We perform numerous experiments on real-world networks, observing that significant information about G, such as specific edges and bulk properties like triangle density, is often lost in H. However, community structure is often preserved or even enhanced. Our findings are a step towards a more rigorous understanding of exactly what information embeddings encode about the input graph, and why this information is useful for learning tasks.
Semantic-embedded Unsupervised Spectral Reconstruction from Single RGB Images in the Wild
Aug 15, 2021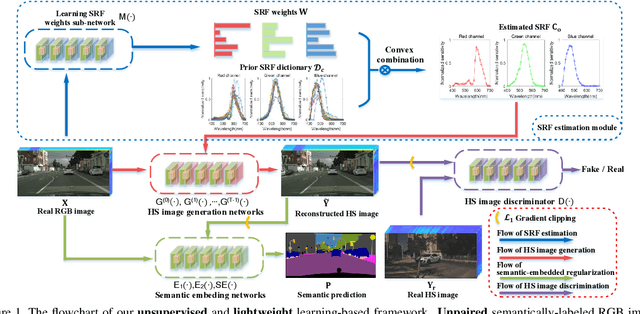
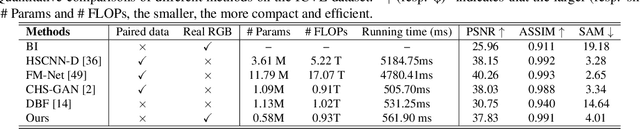

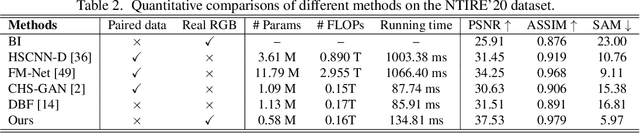
This paper investigates the problem of reconstructing hyperspectral (HS) images from single RGB images captured by commercial cameras, \textbf{without} using paired HS and RGB images during training. To tackle this challenge, we propose a new lightweight and end-to-end learning-based framework. Specifically, on the basis of the intrinsic imaging degradation model of RGB images from HS images, we progressively spread the differences between input RGB images and re-projected RGB images from recovered HS images via effective unsupervised camera spectral response function estimation. To enable the learning without paired ground-truth HS images as supervision, we adopt the adversarial learning manner and boost it with a simple yet effective $\mathcal{L}_1$ gradient clipping scheme. Besides, we embed the semantic information of input RGB images to locally regularize the unsupervised learning, which is expected to promote pixels with identical semantics to have consistent spectral signatures. In addition to conducting quantitative experiments over two widely-used datasets for HS image reconstruction from synthetic RGB images, we also evaluate our method by applying recovered HS images from real RGB images to HS-based visual tracking. Extensive results show that our method significantly outperforms state-of-the-art unsupervised methods and even exceeds the latest supervised method under some settings. The source code is public available at https://github.com/zbzhzhy/Unsupervised-Spectral-Reconstruction.
Assessing the Effectiveness of Syntactic Structure to Learn Code Edit Representations
Jun 11, 2021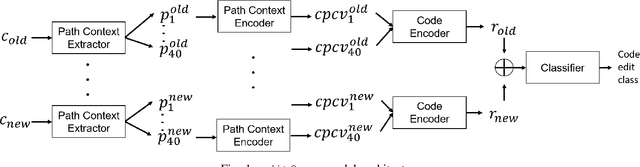
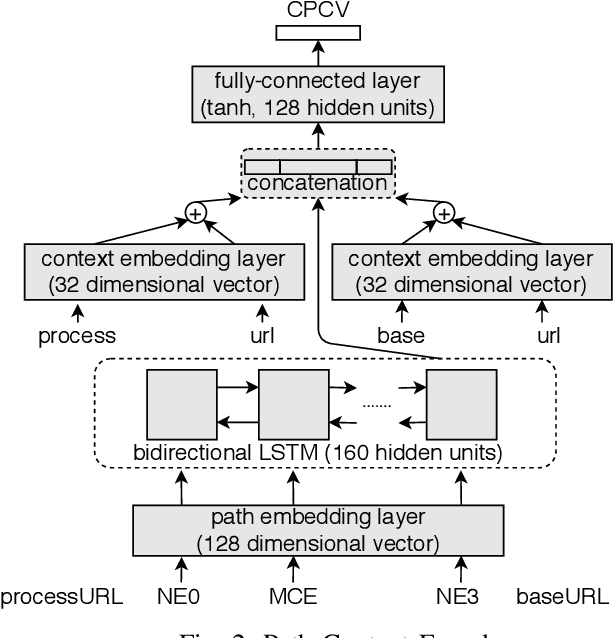
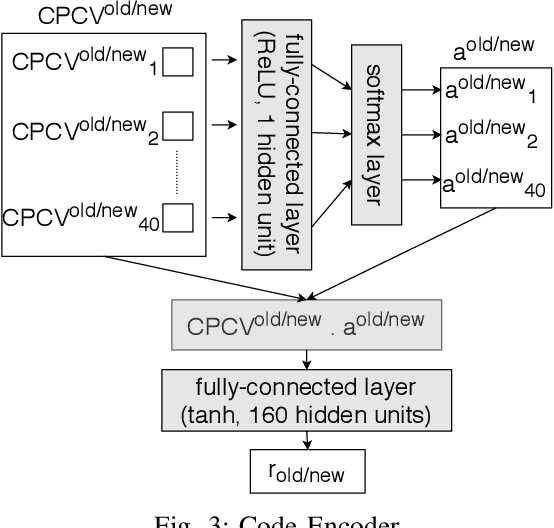
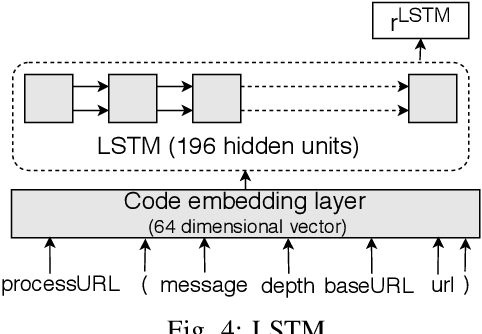
In recent times, it has been shown that one can use code as data to aid various applications such as automatic commit message generation, automatic generation of pull request descriptions and automatic program repair. Take for instance the problem of commit message generation. Treating source code as a sequence of tokens, state of the art techniques generate commit messages using neural machine translation models. However, they tend to ignore the syntactic structure of programming languages. Previous work, i.e., code2seq has used structural information from Abstract Syntax Tree (AST) to represent source code and they use it to automatically generate method names. In this paper, we elaborate upon this state of the art approach and modify it to represent source code edits. We determine the effect of using such syntactic structure for the problem of classifying code edits. Inspired by the code2seq approach, we evaluate how using structural information from AST, i.e., paths between AST leaf nodes can help with the task of code edit classification on two datasets of fine-grained syntactic edits. Our experiments shows that attempts of adding syntactic structure does not result in any improvements over less sophisticated methods. The results suggest that techniques such as code2seq, while promising, have a long way to go before they can be generically applied to learning code edit representations. We hope that these results will benefit other researchers and inspire them to work further on this problem.
FA-GAN: Fused Attentive Generative Adversarial Networks for MRI Image Super-Resolution
Aug 09, 2021


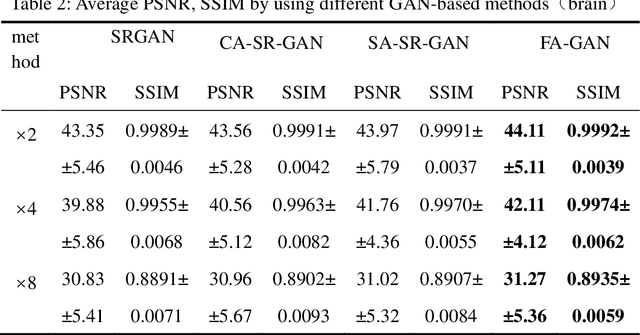
High-resolution magnetic resonance images can provide fine-grained anatomical information, but acquiring such data requires a long scanning time. In this paper, a framework called the Fused Attentive Generative Adversarial Networks(FA-GAN) is proposed to generate the super-resolution MR image from low-resolution magnetic resonance images, which can reduce the scanning time effectively but with high resolution MR images. In the framework of the FA-GAN, the local fusion feature block, consisting of different three-pass networks by using different convolution kernels, is proposed to extract image features at different scales. And the global feature fusion module, including the channel attention module, the self-attention module, and the fusion operation, is designed to enhance the important features of the MR image. Moreover, the spectral normalization process is introduced to make the discriminator network stable. 40 sets of 3D magnetic resonance images (each set of images contains 256 slices) are used to train the network, and 10 sets of images are used to test the proposed method. The experimental results show that the PSNR and SSIM values of the super-resolution magnetic resonance image generated by the proposed FA-GAN method are higher than the state-of-the-art reconstruction methods.