 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked Dense U-Nets with Dual Transformers for Robust Face Alignment
Dec 05, 2018
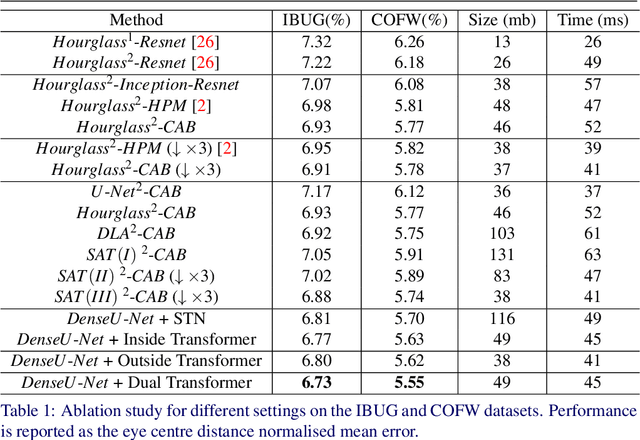
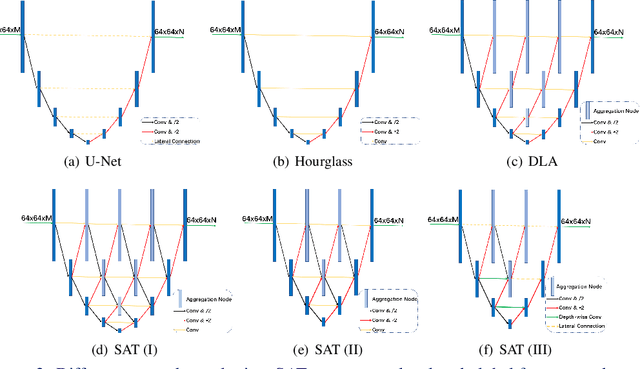

Facial landmark localisation in images captured in-the-wild is an important and challenging problem. The current state-of-the-art revolves around certain kinds of Deep Convolutional Neural Networks (DCNNs) such as stacked U-Nets and Hourglass networks. In this work, we innovatively propose stacked dense U-Nets for this task. We design a novel scale aggregation network topology structure and a channel aggregation building block to improve the model's capacity without sacrificing the computational complexity and model size. With the assistance of deformable convolutions inside the stacked dense U-Nets and coherent loss for outside data transformation, our model obtains the ability to be spatially invariant to arbitrary input face images. Extensive experiments on many in-the-wild datasets, validate the robustness of the proposed method under extreme poses, exaggerated expressions and heavy occlusions. Finally, we show that accurate 3D face alignment can assist pose-invariant face recognition where we achieve a new state-of-the-art accuracy on CFP-FP.
Side Information for Face Completion: a Robust PCA Approach
Jan 20, 2018
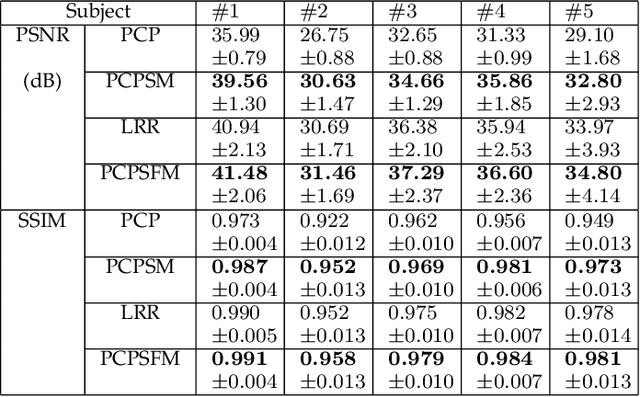
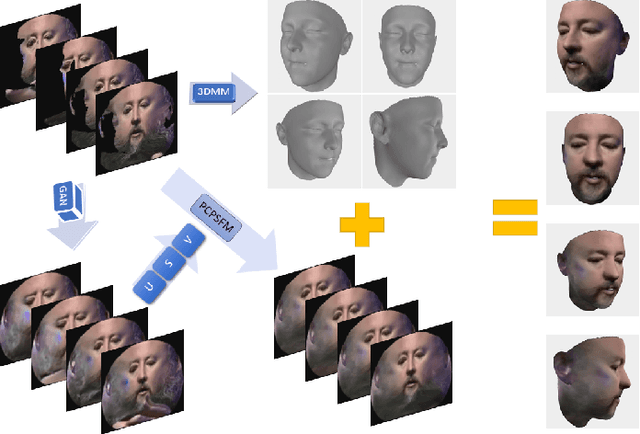
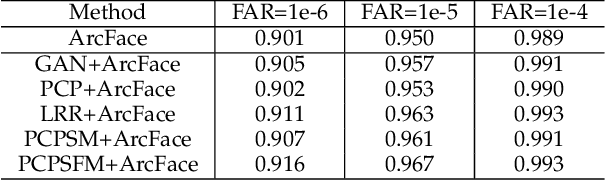
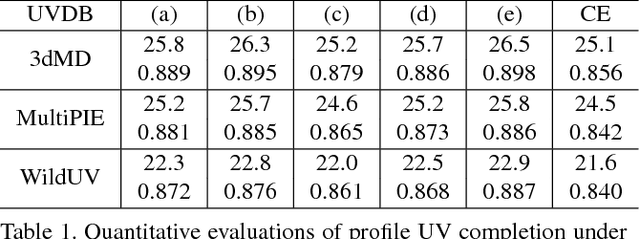
Robust principal component analysis (RPCA) is a powerful method for learning low-rank feature representation of various visual data. However, for certain types as well as significant amount of error corruption, it fails to yield satisfactory results; a drawback that can be alleviated by exploiting domain-dependent prior knowledge or information. In this paper, we propose two models for the RPCA that take into account such side information, even in the presence of missing values. We apply this framework to the task of UV completion which is widely used in pose-invariant face recognition. Moreover, we construct a generative adversarial network (GAN) to extract side information as well as subspaces. These subspaces not only assist in the recovery but also speed up the process in case of large-scale data. We quantitatively and qualitatively evaluate the proposed approaches through both synthetic data and five real-world datasets to verify their effectiveness.
UV-GAN: Adversarial Facial UV Map Completion for Pose-invariant Face Recognition
Dec 13, 2017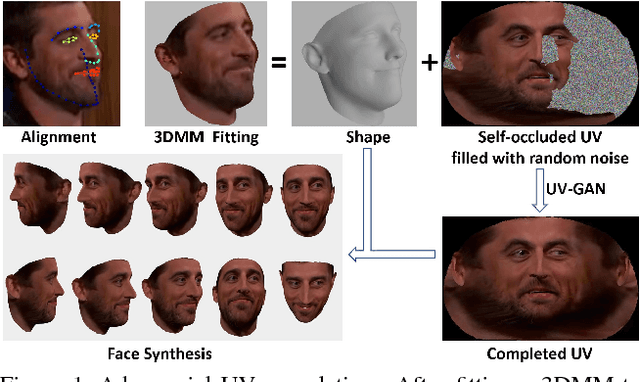

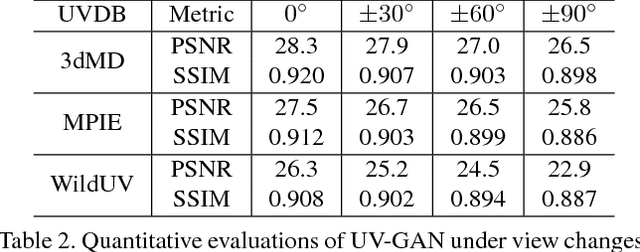
Recently proposed robust 3D face alignment methods establish either dense or sparse correspondence between a 3D face model and a 2D facial image. The use of these methods presents new challenges as well as opportunities for facial texture analysis. In particular, by sampling the image using the fitted model, a facial UV can be created. Unfortunately, due to self-occlusion, such a UV map is always incomplete. In this paper, we propose a framework for training Deep Convolutional Neural Network (DCNN) to complete the facial UV map extracted from in-the-wild images. To this end, we first gather complete UV maps by fitting a 3D Morphable Model (3DMM) to various multiview image and video datasets, as well as leveraging on a new 3D dataset with over 3,000 identities. Second, we devise a meticulously designed architecture that combines local and global adversarial DCNNs to learn an identity-preserving facial UV completion model. We demonstrate that by attaching the completed UV to the fitted mesh and generating instances of arbitrary poses, we can increase pose variations for training deep face recognition/verification models, and minimise pose discrepancy during testing, which lead to better performance. Experiments on both controlled and in-the-wild UV datasets prove the effectiveness of our adversarial UV completion model. We achieve state-of-the-art verification accuracy, $94.05\%$, under the CFP frontal-profile protocol only by combining pose augmentation during training and pose discrepancy reduction during testing. We will release the first in-the-wild UV dataset (we refer as WildUV) that comprises of complete facial UV maps from 1,892 identities for research purposes.
Informed Non-convex Robust Principal Component Analysis with Features
Sep 14, 2017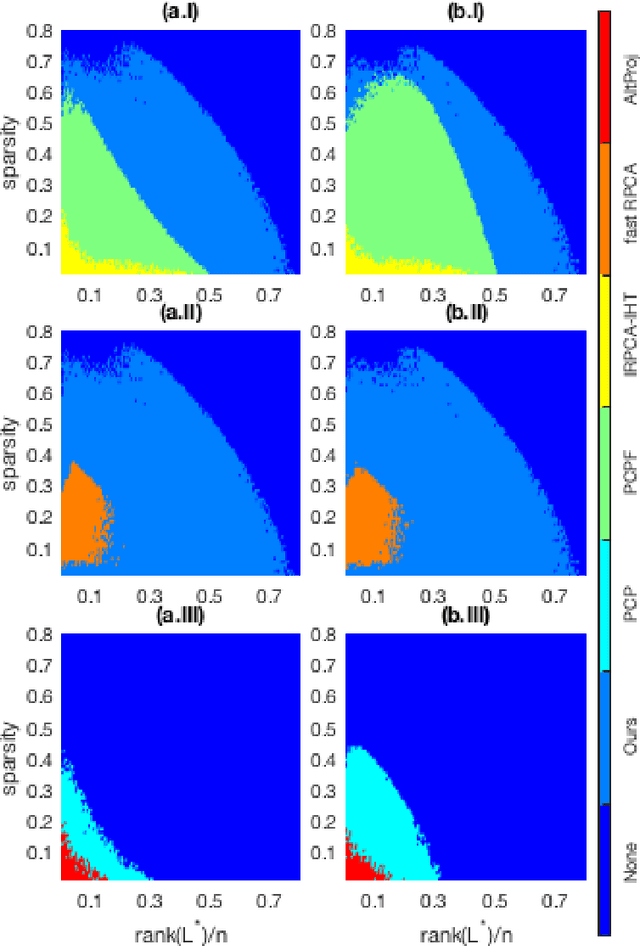
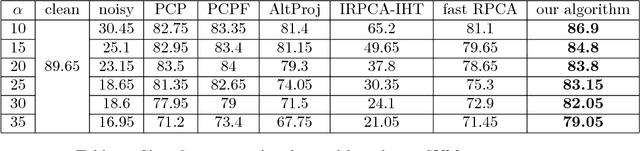
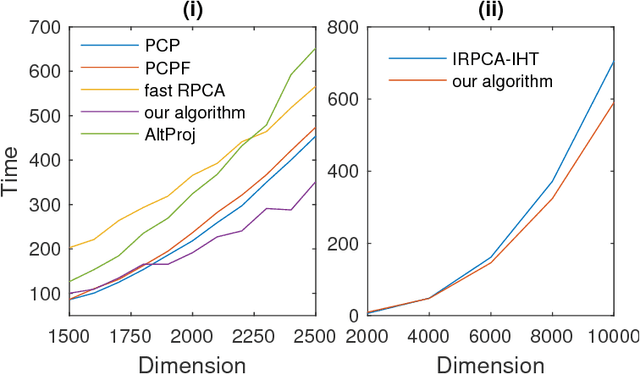
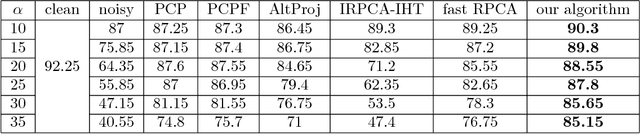
We revisit the problem of robust principal component analysis with features acting as prior side information. To this aim, a novel, elegant, non-convex optimization approach is proposed to decompose a given observation matrix into a low-rank core and the corresponding sparse residual. Rigorous theoretical analysis of the proposed algorithm results in exact recovery guarantees with low computational complexity. Aptly designed synthetic experiments demonstrate that our method is the first to wholly harness the power of non-convexity over convexity in terms of both recoverability and speed. That is, the proposed non-convex approach is more accurate and faster compared to the best available algorithms for the problem under study. Two real-world applications, namely image classification and face denoising further exemplify the practical superiority of the proposed method.
Side Information in Robust Principal Component Analysis: Algorithms and Applications
Mar 28, 2017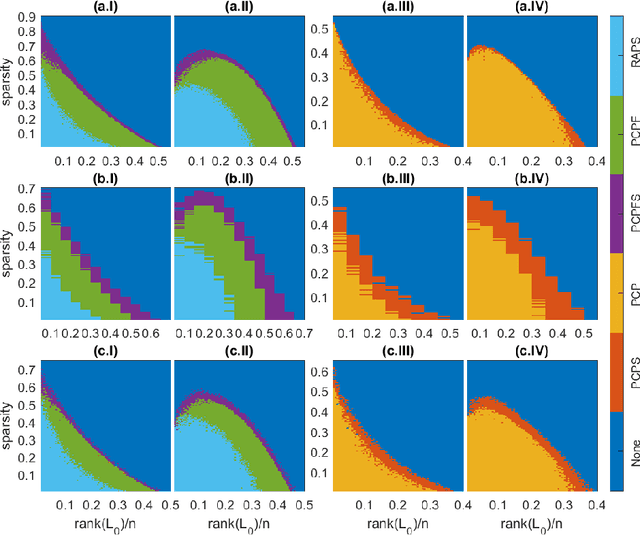
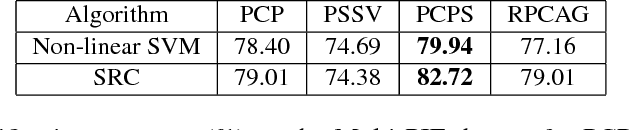
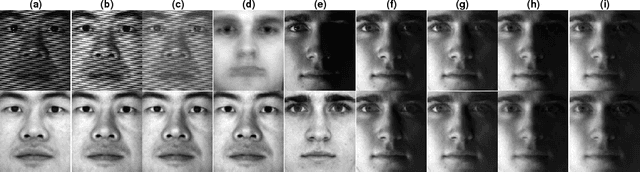

Robust Principal Component Analysis (RPCA) aims at recovering a low-rank subspace from grossly corrupted high-dimensional (often visual) data and is a cornerstone in many machine learning and computer vision applications. Even though RPCA has been shown to be very successful in solving many rank minimisation problems, there are still cases where degenerate or suboptimal solutions are obtained. This is likely to be remedied by taking into account of domain-dependent prior knowledge. In this paper, we propose two models for the RPCA problem with the aid of side information on the low-rank structure of the data. The versatility of the proposed methods is demonstrated by applying them to four applications, namely background subtraction, facial image denoising, face and facial expression recognition. Experimental results on synthetic and five real world datasets indicate the robustness and effectiveness of the proposed methods on these application domains, largely outperforming six previous approaches.