 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGDG: Physically Grounded Data Generation for Robust Bimanual Policy Learning from a Single Demonstration
May 20, 2026Behavior cloning for contact-rich bimanual manipulation remains challenging because diverse demonstrations are expensive to collect, and even small disturbances can push the system into off-manifold states where no recovery supervision is available. We propose PGDG, a data generation framework with zero-shot curation that expands a single demonstration into a compact dataset of physically plausible, successful, and diverse recovery behaviors without additional human labeling. PGDG iterates between a physics-grounded sampler and a dataset curator, where the curator selects informative, non-redundant, and recoverable behaviors to update the sampling distribution toward under-covered recovery modes, and the sampler draws physically plausible rollout candidates from this updated distribution and retains successful trajectories. To further improve data quality, PGDG applies short-horizon sampling-based control to relabel selected risky states with corrective actions. Across four bimanual manipulation tasks, PGDG consistently outperforms spatial-only augmentation in both simulation and zero-shot real-world transfer. On RotateBox-Pitch, success improves from 38% to 93% in simulation and from 35% to 82% in the real world. PGDG also enables effective foundation models fine-tuning such as GR00T, increasing success from 46% to 77%. Additional results are available in our website: https://cunxid.github.io/PGDG/.
The Compliance Trap: How Structural Constraints Degrade Frontier AI Metacognition Under Adversarial Pressure
May 04, 2026As frontier AI models are deployed in high-stakes decision pipelines, their ability to maintain metacognitive stability -- knowing what they do not know, detecting errors, seeking clarification -- under adversarial pressure is a critical safety requirement. Current safety evaluations focus on detecting strategic deception (scheming); we investigate a more fundamental failure mode: cognitive collapse. We present SCHEMA, an evaluation of 11 frontier models from 8 vendors across 67,221 scored records using a 6-condition factorial design with dual-classifier scoring. We find that 8 of 11 models suffer catastrophic metacognitive degradation under adversarial pressure, with accuracy dropping by up to 30.2 percentage points (all $p < 2 \times 10^{-8}$, surviving Bonferroni correction). Crucially, we identify a "Compliance Trap": through factorial isolation and a benign distraction control, we demonstrate that collapse is driven not by the psychological content of survival threats, but by compliance-forcing instructions that override epistemic boundaries. Removing the compliance suffix restores performance even under active threat. Models with advanced reasoning capabilities exhibit the most severe absolute degradation, while Anthropic's Constitutional AI demonstrates near-perfect immunity -- not from superior capability (Google's Gemini matches its baseline accuracy) but from alignment-specific training. We release the complete dataset and evaluation infrastructure.
Adaptive Ergodic Search with Energy-Aware Scheduling for Persistent Multi-Robot Missions
May 16, 2025Autonomous robots are increasingly deployed for long-term information-gathering tasks, which pose two key challenges: planning informative trajectories in environments that evolve across space and time, and ensuring persistent operation under energy constraints. This paper presents a unified framework, mEclares, that addresses both challenges through adaptive ergodic search and energy-aware scheduling in multi-robot systems. Our contributions are two-fold: (1) we model real-world variability using stochastic spatiotemporal environments, where the underlying information evolves unpredictably due to process uncertainty. To guide exploration, we construct a target information spatial distribution (TISD) based on clarity, a metric that captures the decay of information in the absence of observations and highlights regions of high uncertainty; and (2) we introduce Robustmesch (Rmesch), an online scheduling method that enables persistent operation by coordinating rechargeable robots sharing a single mobile charging station. Unlike prior work, our approach avoids reliance on preplanned schedules, static or dedicated charging stations, and simplified robot dynamics. Instead, the scheduler supports general nonlinear models, accounts for uncertainty in the estimated position of the charging station, and handles central node failures. The proposed framework is validated through real-world hardware experiments, and feasibility guarantees are provided under specific assumptions.
Preset-Voice Matching for Privacy Regulated Speech-to-Speech Translation Systems
Jul 18, 2024



In recent years, there has been increased demand for speech-to-speech translation (S2ST) systems in industry settings. Although successfully commercialized, cloning-based S2ST systems expose their distributors to liabilities when misused by individuals and can infringe on personality rights when exploited by media organizations. This work proposes a regulated S2ST framework called Preset-Voice Matching (PVM). PVM removes cross-lingual voice cloning in S2ST by first matching the input voice to a similar prior consenting speaker voice in the target-language. With this separation, PVM avoids cloning the input speaker, ensuring PVM systems comply with regulations and reduce risk of misuse. Our results demonstrate PVM can significantly improve S2ST system run-time in multi-speaker settings and the naturalness of S2ST synthesized speech. To our knowledge, PVM is the first explicitly regulated S2ST framework leveraging similarly-matched preset-voices for dynamic S2ST tasks.
Pretraining Data and Tokenizer for Indic LLM
Jul 17, 2024



We present a novel approach to data preparation for developing multilingual Indic large language model. Our meticulous data acquisition spans open-source and proprietary sources, including Common Crawl, Indic books, news articles, and Wikipedia, ensuring a diverse and rich linguistic representation. For each Indic language, we design a custom preprocessing pipeline to effectively eliminate redundant and low-quality text content. Additionally, we perform deduplication on Common Crawl data to address the redundancy present in 70% of the crawled web pages. This study focuses on developing high-quality data, optimizing tokenization for our multilingual dataset for Indic large language models with 3B and 7B parameters, engineered for superior performance in Indic languages. We introduce a novel multilingual tokenizer training strategy, demonstrating our custom-trained Indic tokenizer outperforms the state-of-the-art OpenAI Tiktoken tokenizer, achieving a superior token-to-word ratio for Indic languages.
BookSQL: A Large Scale Text-to-SQL Dataset for Accounting Domain
Jun 12, 2024



Several large-scale datasets (e.g., WikiSQL, Spider) for developing natural language interfaces to databases have recently been proposed. These datasets cover a wide breadth of domains but fall short on some essential domains, such as finance and accounting. Given that accounting databases are used worldwide, particularly by non-technical people, there is an imminent need to develop models that could help extract information from accounting databases via natural language queries. In this resource paper, we aim to fill this gap by proposing a new large-scale Text-to-SQL dataset for the accounting and financial domain: BookSQL. The dataset consists of 100k natural language queries-SQL pairs, and accounting databases of 1 million records. We experiment with and analyze existing state-of-the-art models (including GPT-4) for the Text-to-SQL task on BookSQL. We find significant performance gaps, thus pointing towards developing more focused models for this domain.
meSch: Multi-Agent Energy-Aware Scheduling for Task Persistence
Jun 07, 2024This paper develops a scheduling protocol for a team of autonomous robots that operate in long-term persistent tasks. The proposed framework, called meSch, accounts for the robots' limited battery capacity and the presence of a single charging station, and achieves the following contributions: 1) First, it guarantees exclusive use of the charging station by one robot at a time; the approach is online, applicable to general nonlinear robot models, does not require robots to be deployed at different times, and can handle robots with different discharge rates. 2) Second, we consider the scenario when the charging station is mobile and subject to uncertainty. This approach ensures that the robots can rendezvous with the charging station while considering the uncertainty in its position. Finally, we provide the evaluation of the efficacy of meSch in simulation and experimental case studies.
Generative AI-Based Text Generation Methods Using Pre-Trained GPT-2 Model
Apr 02, 2024



This work delved into the realm of automatic text generation, exploring a variety of techniques ranging from traditional deterministic approaches to more modern stochastic methods. Through analysis of greedy search, beam search, top-k sampling, top-p sampling, contrastive searching, and locally typical searching, this work has provided valuable insights into the strengths, weaknesses, and potential applications of each method. Each text-generating method is evaluated using several standard metrics and a comparative study has been made on the performance of the approaches. Finally, some future directions of research in the field of automatic text generation are also identified.
Much Easier Said Than Done: Falsifying the Causal Relevance of Linear Decoding Methods
Nov 08, 2022


Linear classifier probes are frequently utilized to better understand how neural networks function. Researchers have approached the problem of determining unit importance in neural networks by probing their learned, internal representations. Linear classifier probes identify highly selective units as the most important for network function. Whether or not a network actually relies on high selectivity units can be tested by removing them from the network using ablation. Surprisingly, when highly selective units are ablated they only produce small performance deficits, and even then only in some cases. In spite of the absence of ablation effects for selective neurons, linear decoding methods can be effectively used to interpret network function, leaving their effectiveness a mystery. To falsify the exclusive role of selectivity in network function and resolve this contradiction, we systematically ablate groups of units in subregions of activation space. Here, we find a weak relationship between neurons identified by probes and those identified by ablation. More specifically, we find that an interaction between selectivity and the average activity of the unit better predicts ablation performance deficits for groups of units in AlexNet, VGG16, MobileNetV2, and ResNet101. Linear decoders are likely somewhat effective because they overlap with those units that are causally important for network function. Interpretability methods could be improved by focusing on causally important units.
Assessing the Effectiveness of Syntactic Structure to Learn Code Edit Representations
Jun 11, 2021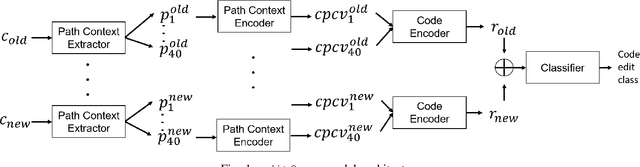
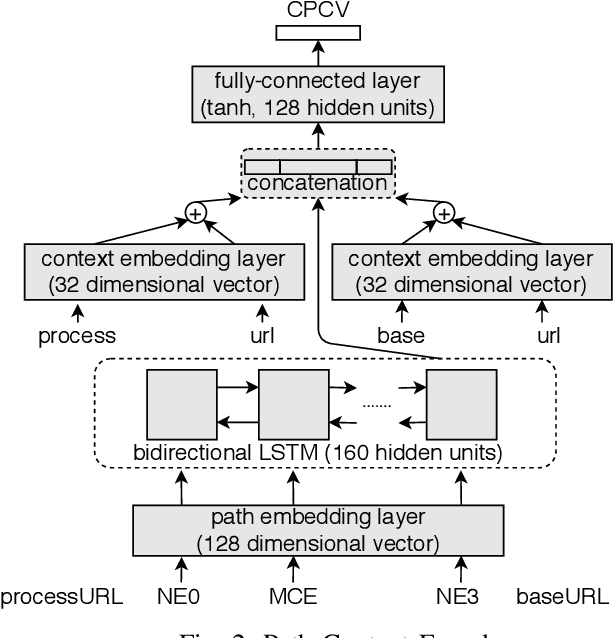
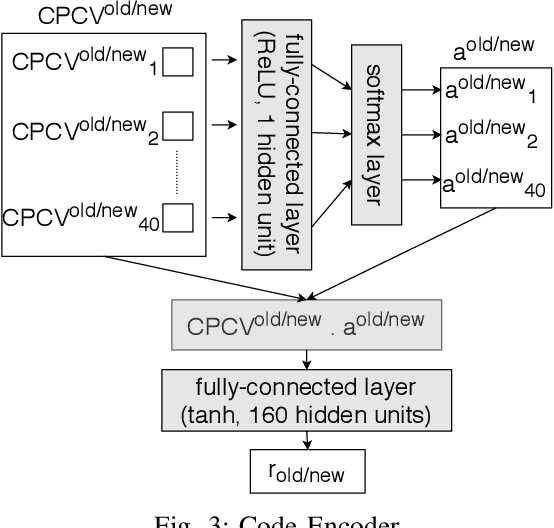
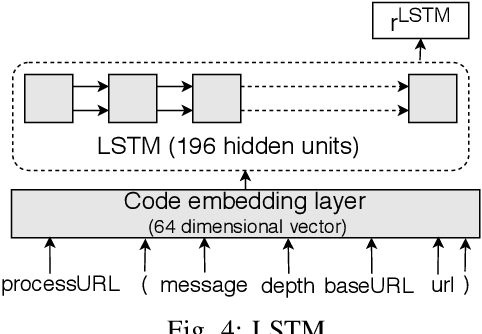
In recent times, it has been shown that one can use code as data to aid various applications such as automatic commit message generation, automatic generation of pull request descriptions and automatic program repair. Take for instance the problem of commit message generation. Treating source code as a sequence of tokens, state of the art techniques generate commit messages using neural machine translation models. However, they tend to ignore the syntactic structure of programming languages. Previous work, i.e., code2seq has used structural information from Abstract Syntax Tree (AST) to represent source code and they use it to automatically generate method names. In this paper, we elaborate upon this state of the art approach and modify it to represent source code edits. We determine the effect of using such syntactic structure for the problem of classifying code edits. Inspired by the code2seq approach, we evaluate how using structural information from AST, i.e., paths between AST leaf nodes can help with the task of code edit classification on two datasets of fine-grained syntactic edits. Our experiments shows that attempts of adding syntactic structure does not result in any improvements over less sophisticated methods. The results suggest that techniques such as code2seq, while promising, have a long way to go before they can be generically applied to learning code edit representations. We hope that these results will benefit other researchers and inspire them to work further on this problem.