 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA: Accurate and Scalable ANNS-based Training of Extreme Classifiers
Sep 30, 2024`Extreme Classification'' (or XC) is the task of annotating data points (queries) with relevant labels (documents), from an extremely large set of $L$ possible labels, arising in search and recommendations. The most successful deep learning paradigm that has emerged over the last decade or so for XC is to embed the queries (and labels) using a deep encoder (e.g. DistilBERT), and use linear classifiers on top of the query embeddings. This architecture is of appeal because it enables millisecond-time inference using approximate nearest neighbor search (ANNS). The key question is how do we design training algorithms that are accurate as well as scale to $O(100M)$ labels on a limited number of GPUs. State-of-the-art XC techniques that demonstrate high accuracies (e.g., DEXML, Ren\'ee, DEXA) on standard datasets have per-epoch training time that scales as $O(L)$ or employ expensive negative sampling strategies, which are prohibitive in XC scenarios. In this work, we develop an accurate and scalable XC algorithm ASTRA with two key observations: (a) building ANNS index on the classifier vectors and retrieving hard negatives using the classifiers aligns the negative sampling strategy to the loss function optimized; (b) keeping the ANNS indices current as the classifiers change through the epochs is prohibitively expensive while using stale negatives (refreshed periodically) results in poor accuracy; to remedy this, we propose a negative sampling strategy that uses a mixture of importance sampling and uniform sampling. By extensive evaluation on standard XC as well as proprietary datasets with 120M labels, we demonstrate that ASTRA achieves SOTA precision, while reducing training time by 4x-15x relative to the second best.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022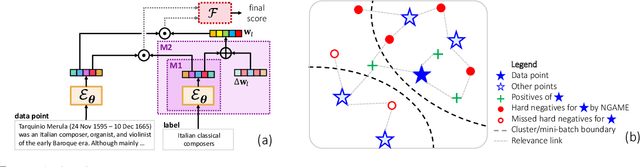
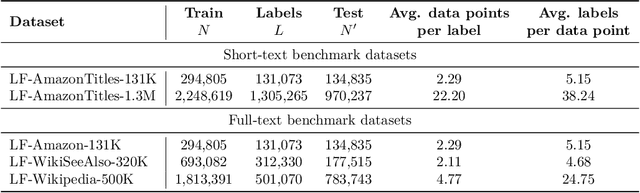
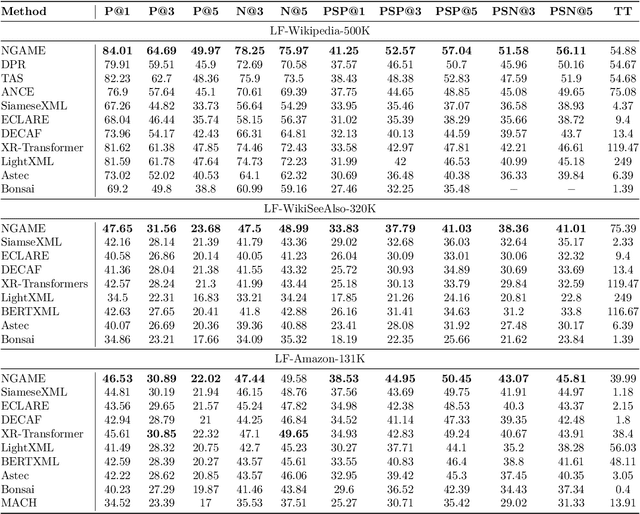
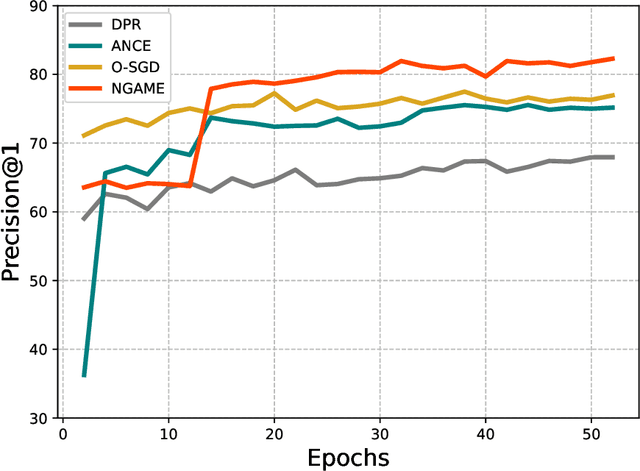
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
Assessing the Effectiveness of Syntactic Structure to Learn Code Edit Representations
Jun 11, 2021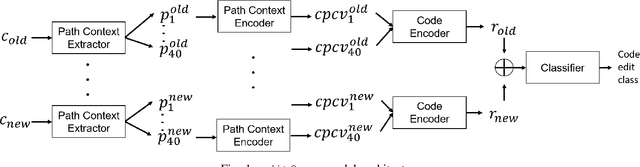
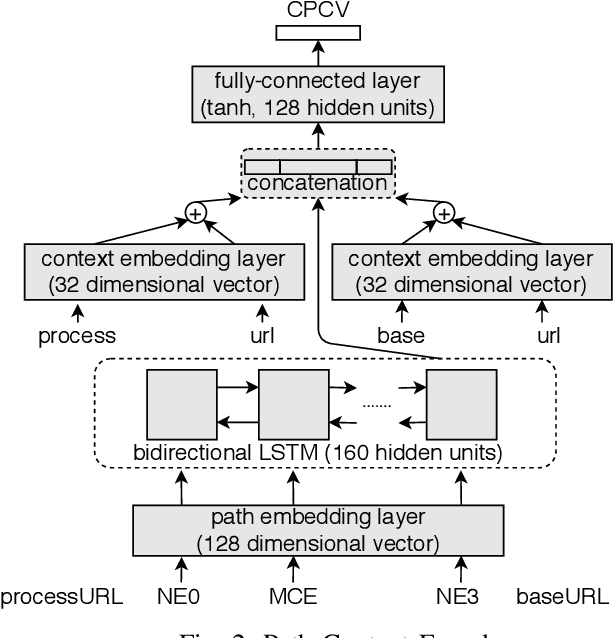
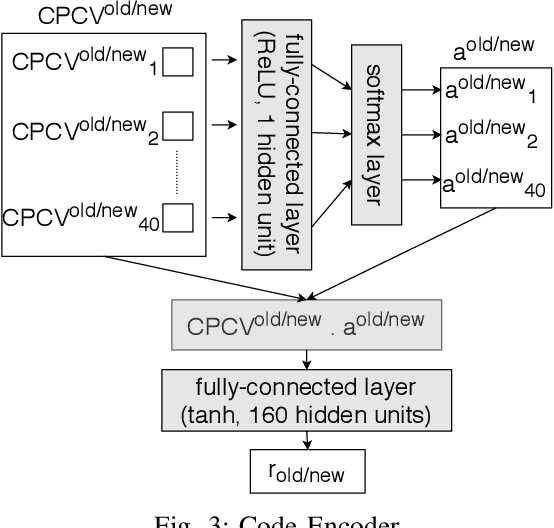
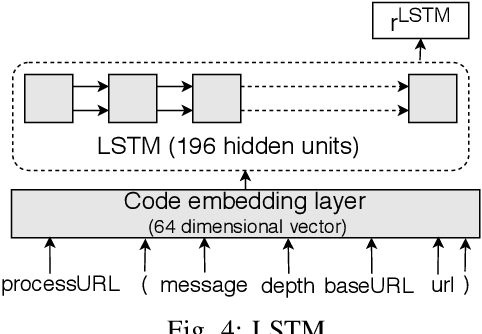
In recent times, it has been shown that one can use code as data to aid various applications such as automatic commit message generation, automatic generation of pull request descriptions and automatic program repair. Take for instance the problem of commit message generation. Treating source code as a sequence of tokens, state of the art techniques generate commit messages using neural machine translation models. However, they tend to ignore the syntactic structure of programming languages. Previous work, i.e., code2seq has used structural information from Abstract Syntax Tree (AST) to represent source code and they use it to automatically generate method names. In this paper, we elaborate upon this state of the art approach and modify it to represent source code edits. We determine the effect of using such syntactic structure for the problem of classifying code edits. Inspired by the code2seq approach, we evaluate how using structural information from AST, i.e., paths between AST leaf nodes can help with the task of code edit classification on two datasets of fine-grained syntactic edits. Our experiments shows that attempts of adding syntactic structure does not result in any improvements over less sophisticated methods. The results suggest that techniques such as code2seq, while promising, have a long way to go before they can be generically applied to learning code edit representations. We hope that these results will benefit other researchers and inspire them to work further on this problem.