 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DVMN: Dense Validity Mask Network for Depth Completion
Jul 14, 2021

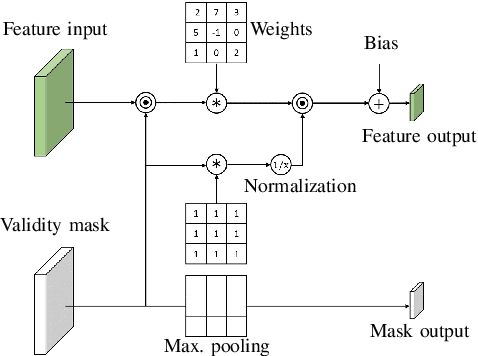
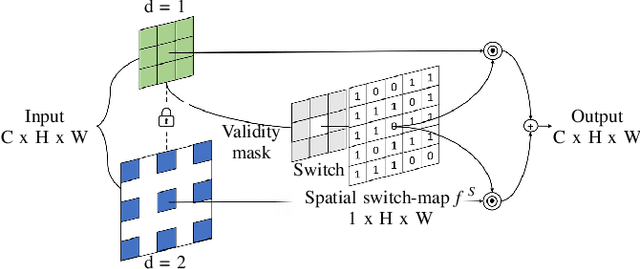
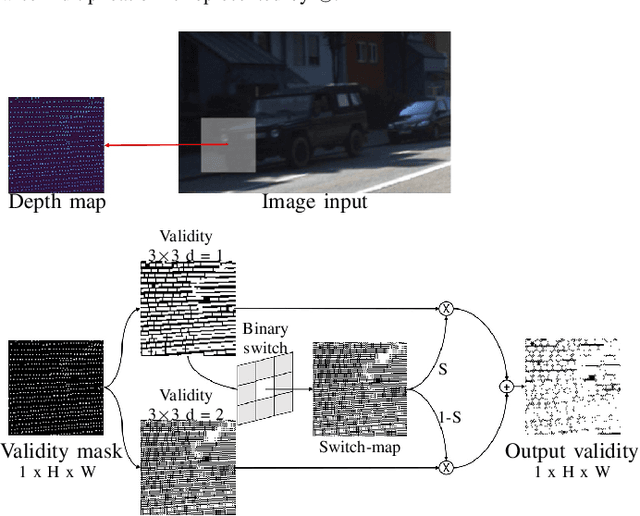
LiDAR depth maps provide environmental guidance in a variety of applications. However, such depth maps are typically sparse and insufficient for complex tasks such as autonomous navigation. State of the art methods use image guided neural networks for dense depth completion. We develop a guided convolutional neural network focusing on gathering dense and valid information from sparse depth maps. To this end, we introduce a novel layer with spatially variant and content-depended dilation to include additional data from sparse input. Furthermore, we propose a sparsity invariant residual bottleneck block. We evaluate our Dense Validity Mask Network (DVMN) on the KITTI depth completion benchmark and achieve state of the art results. At the time of submission, our network is the leading method using sparsity invariant convolution.
A distillation based approach for the diagnosis of diseases
Aug 07, 2021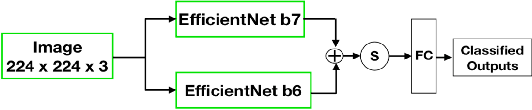
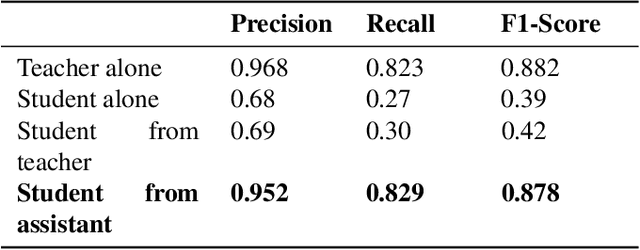
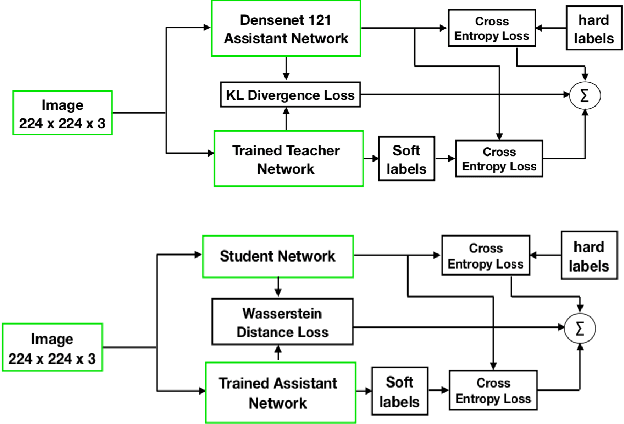
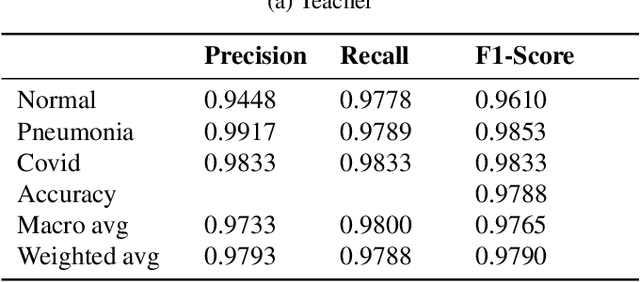
Presently, Covid-19 is a serious threat to the world at large. Efforts are being made to reduce disease screening times and in the development of a vaccine to resist this disease, even as thousands succumb to it everyday. We propose a novel method of automated screening of diseases like Covid-19 and pneumonia from Chest X-Ray images with the help of Computer Vision. Unlike computer vision classification algorithms which come with heavy computational costs, we propose a knowledge distillation based approach which allows us to bring down the model depth, while preserving the accuracy. We make use of an augmentation of the standard distillation module with an auxiliary intermediate assistant network that aids in the continuity of the flow of information. Following this approach, we are able to build an extremely light student network, consisting of just 3 convolutional blocks without any compromise on accuracy. We thus propose a method of classification of diseases which can not only lead to faster screening, but can also operate seamlessly on low-end devices.
Learning Practically Feasible Policies for Online 3D Bin Packing
Aug 31, 2021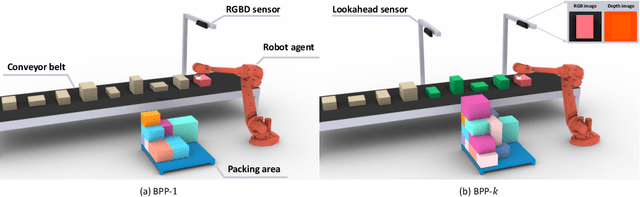
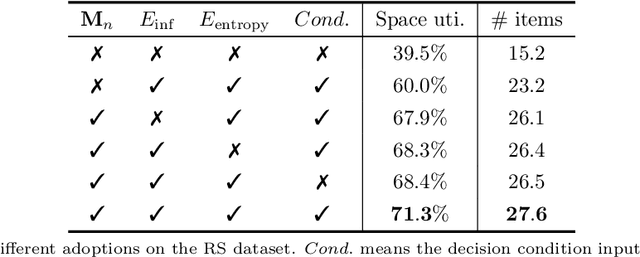
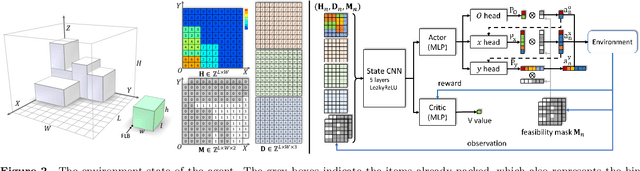
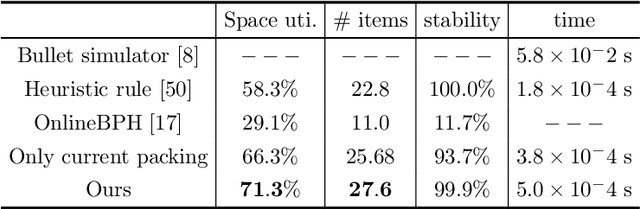
We tackle the Online 3D Bin Packing Problem, a challenging yet practically useful variant of the classical Bin Packing Problem. In this problem, the items are delivered to the agent without informing the full sequence information. Agent must directly pack these items into the target bin stably without changing their arrival order, and no further adjustment is permitted. Online 3D-BPP can be naturally formulated as Markov Decision Process (MDP). We adopt deep reinforcement learning, in particular, the on-policy actor-critic framework, to solve this MDP with constrained action space. To learn a practically feasible packing policy, we propose three critical designs. First, we propose an online analysis of packing stability based on a novel stacking tree. It attains a high analysis accuracy while reducing the computational complexity from $O(N^2)$ to $O(N \log N)$, making it especially suited for RL training. Second, we propose a decoupled packing policy learning for different dimensions of placement which enables high-resolution spatial discretization and hence high packing precision. Third, we introduce a reward function that dictates the robot to place items in a far-to-near order and therefore simplifies the collision avoidance in movement planning of the robotic arm. Furthermore, we provide a comprehensive discussion on several key implemental issues. The extensive evaluation demonstrates that our learned policy outperforms the state-of-the-art methods significantly and is practically usable for real-world applications.
End-To-End Real-Time Visual Perception Framework for Construction Automation
Jul 27, 2021
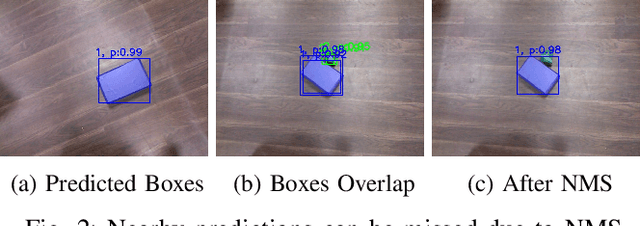

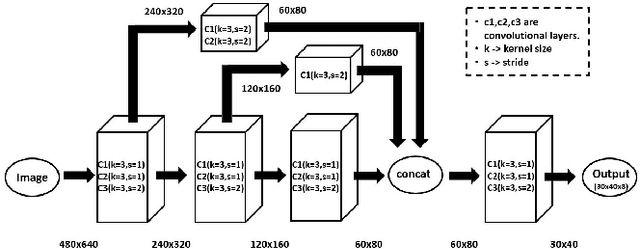
In this work, we present a robotic solution to automate the task of wall construction. To that end, we present an end-to-end visual perception framework that can quickly detect and localize bricks in a clutter. Further, we present a light computational method of brick pose estimation that incorporates the above information. The proposed detection network predicts a rotated box compared to YOLO and SSD, thereby maximizing the object's region in the predicted box regions. In addition, precision P, recall R, and mean-average-precision (mAP) scores are reported to evaluate the proposed framework. We observed that for our task, the proposed scheme outperforms the upright bounding box detectors. Further, we deploy the proposed visual perception framework on a robotic system endowed with a UR5 robot manipulator and demonstrate that the system can successfully replicate a simplified version of the wall-building task in an autonomous mode.
Dynamic and Static Object Detection Considering Fusion Regions and Point-wise Features
Jul 27, 2021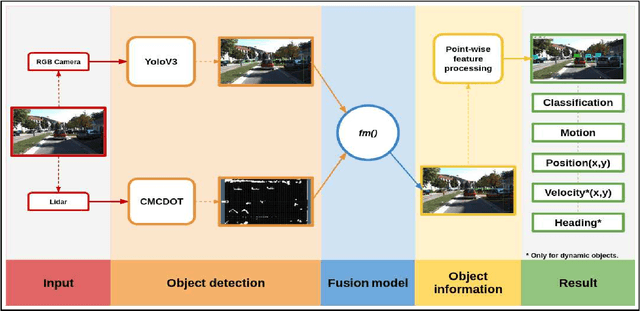
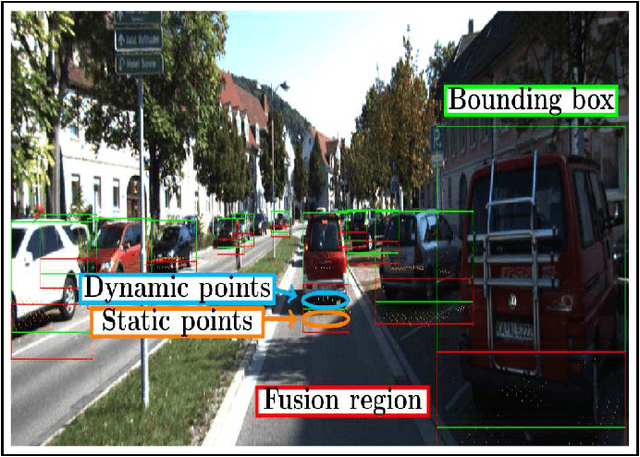
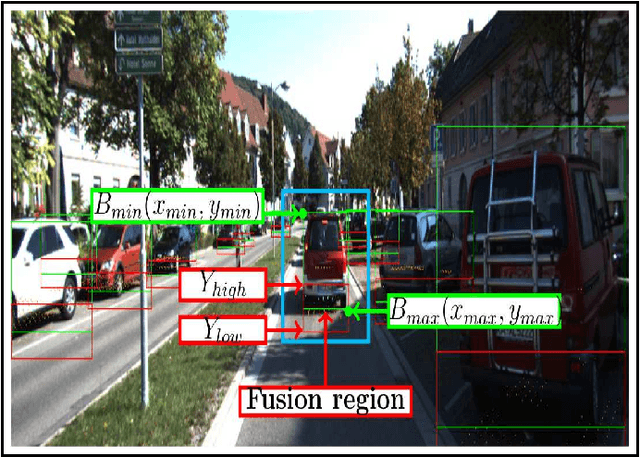
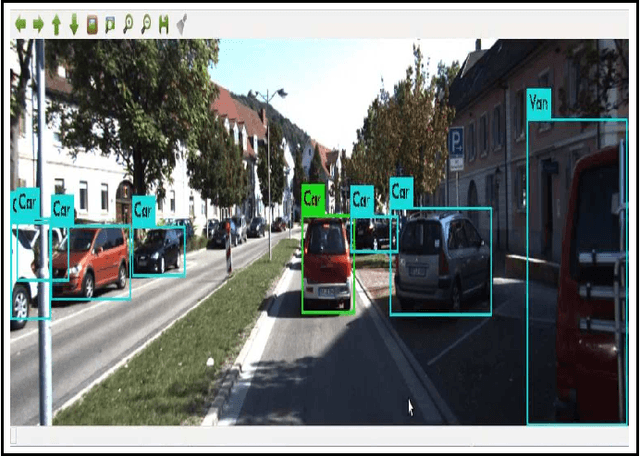
Object detection is a critical problem for the safe interaction between autonomous vehicles and road users. Deep-learning methodologies allowed the development of object detection approaches with better performance. However, there is still the challenge to obtain more characteristics from the objects detected in real-time. The main reason is that more information from the environment's objects can improve the autonomous vehicle capacity to face different urban situations. This paper proposes a new approach to detect static and dynamic objects in front of an autonomous vehicle. Our approach can also get other characteristics from the objects detected, like their position, velocity, and heading. We develop our proposal fusing results of the environment's interpretations achieved of YoloV3 and a Bayesian filter. To demonstrate our proposal's performance, we asses it through a benchmark dataset and real-world data obtained from an autonomous platform. We compared the results achieved with another approach.
Stereo Waterdrop Removal with Row-wise Dilated Attention
Aug 07, 2021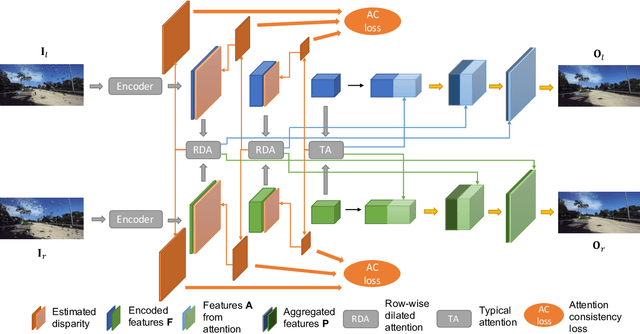
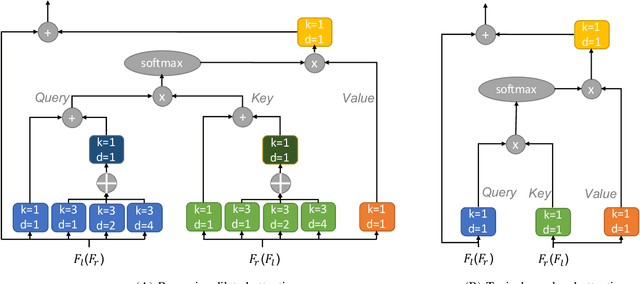


Existing vision systems for autonomous driving or robots are sensitive to waterdrops adhered to windows or camera lenses. Most recent waterdrop removal approaches take a single image as input and often fail to recover the missing content behind waterdrops faithfully. Thus, we propose a learning-based model for waterdrop removal with stereo images. To better detect and remove waterdrops from stereo images, we propose a novel row-wise dilated attention module to enlarge attention's receptive field for effective information propagation between the two stereo images. In addition, we propose an attention consistency loss between the ground-truth disparity map and attention scores to enhance the left-right consistency in stereo images. Because of related datasets' unavailability, we collect a real-world dataset that contains stereo images with and without waterdrops. Extensive experiments on our dataset suggest that our model outperforms state-of-the-art methods both quantitatively and qualitatively. Our source code and the stereo waterdrop dataset are available at \href{https://github.com/VivianSZF/Stereo-Waterdrop-Removal}{https://github.com/VivianSZF/Stereo-Waterdrop-Removal}
Predicting the Success of Domain Adaptation in Text Similarity
Jun 23, 2021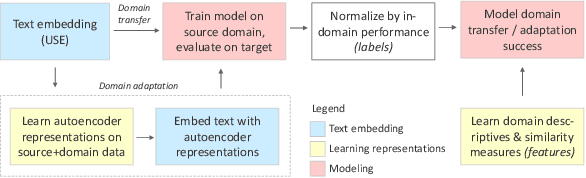
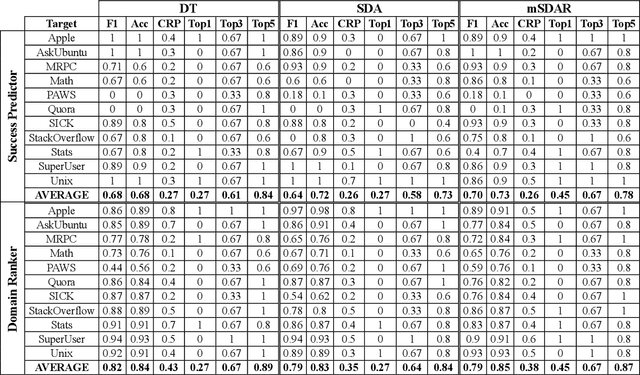
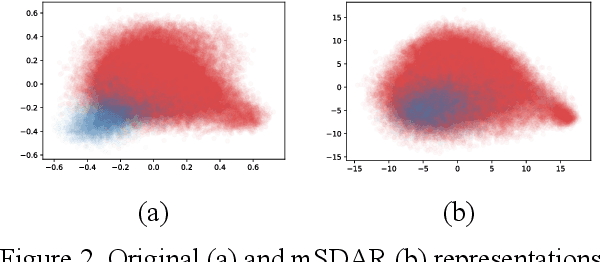
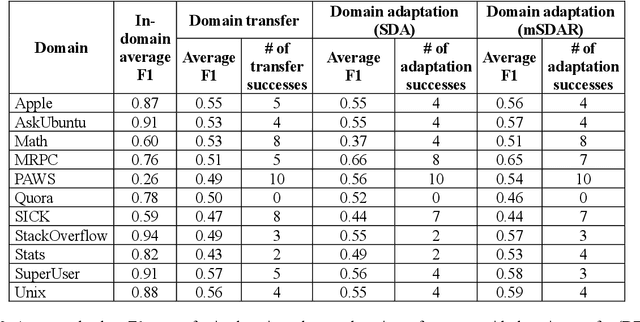
Transfer learning methods, and in particular domain adaptation, help exploit labeled data in one domain to improve the performance of a certain task in another domain. However, it is still not clear what factors affect the success of domain adaptation. This paper models adaptation success and selection of the most suitable source domains among several candidates in text similarity. We use descriptive domain information and cross-domain similarity metrics as predictive features. While mostly positive, the results also point to some domains where adaptation success was difficult to predict.
Monte Carlo Information Geometry: The dually flat case
Mar 20, 2018
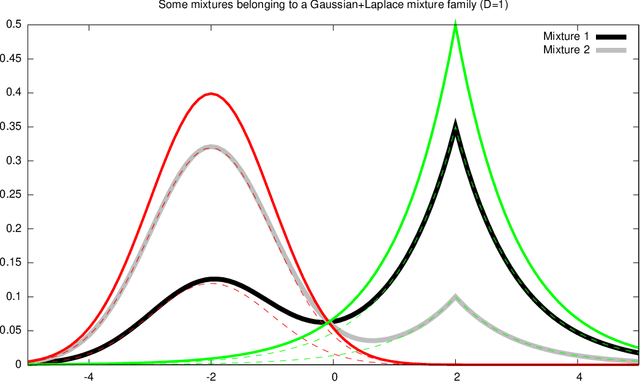
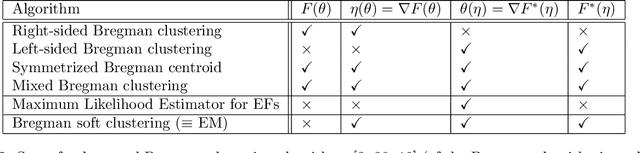
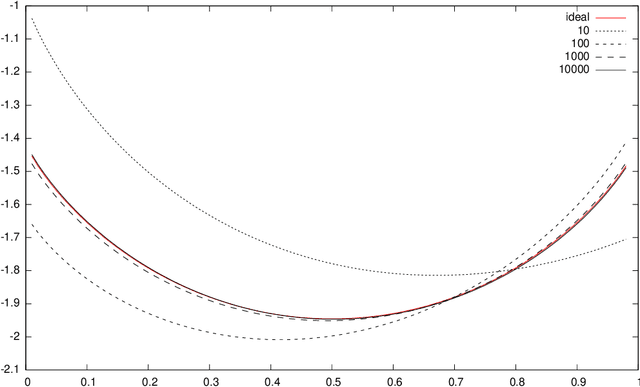
Exponential families and mixture families are parametric probability models that can be geometrically studied as smooth statistical manifolds with respect to any statistical divergence like the Kullback-Leibler (KL) divergence or the Hellinger divergence. When equipping a statistical manifold with the KL divergence, the induced manifold structure is dually flat, and the KL divergence between distributions amounts to an equivalent Bregman divergence on their corresponding parameters. In practice, the corresponding Bregman generators of mixture/exponential families require to perform definite integral calculus that can either be too time-consuming (for exponentially large discrete support case) or even do not admit closed-form formula (for continuous support case). In these cases, the dually flat construction remains theoretical and cannot be used by information-geometric algorithms. To bypass this problem, we consider performing stochastic Monte Carlo (MC) estimation of those integral-based mixture/exponential family Bregman generators. We show that, under natural assumptions, these MC generators are almost surely Bregman generators. We define a series of dually flat information geometries, termed Monte Carlo Information Geometries, that increasingly-finely approximate the untractable geometry. The advantage of this MCIG is that it allows a practical use of the Bregman algorithmic toolbox on a wide range of probability distribution families. We demonstrate our approach with a clustering task on a mixture family manifold.
AGSFCOS: Based on attention mechanism and Scale-Equalizing pyramid network of object detection
May 20, 2021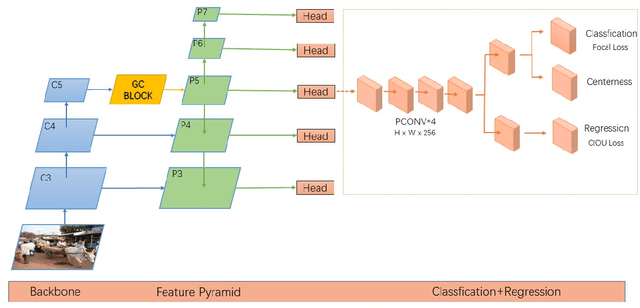

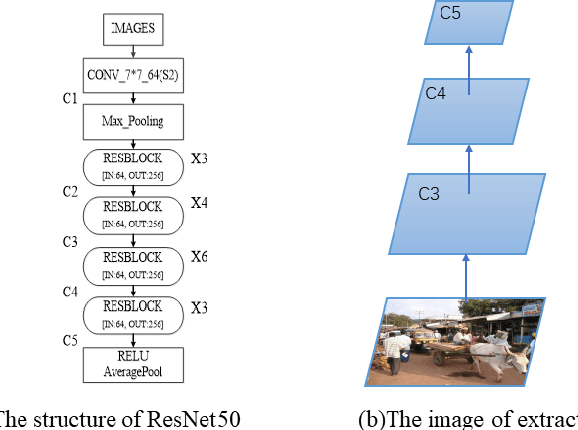
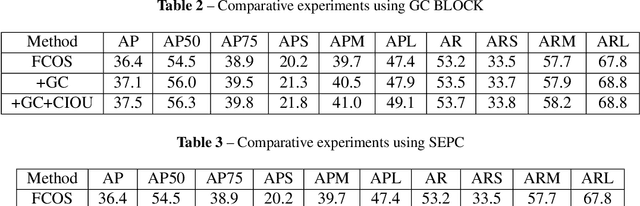
Recently, the anchor-free object detection model has shown great potential for accuracy and speed to exceed anchor-based object detection. Therefore, two issues are mainly studied in this article: (1) How to let the backbone network in the anchor-free object detection model learn feature extraction? (2) How to make better use of the feature pyramid network? In order to solve the above problems, Experiments show that our model has a certain improvement in accuracy compared with the current popular detection models on the COCO dataset, the designed attention mechanism module can capture contextual information well, improve detection accuracy, and use sepc network to help balance abstract and detailed information, and reduce the problem of semantic gap in the feature pyramid network. Whether it is anchor-based network model YOLOv3, Faster RCNN, or anchor-free network model Foveabox, FSAF, FCOS. Our optimal model can get 39.5% COCO AP under the background of ResNet50.
PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
Jul 27, 2021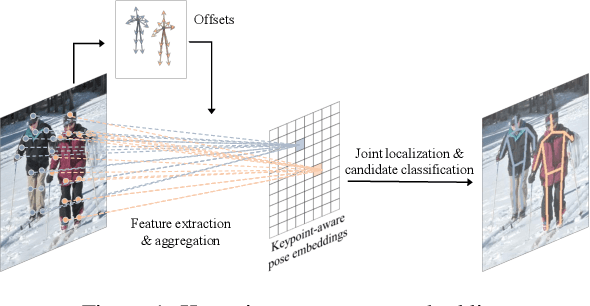
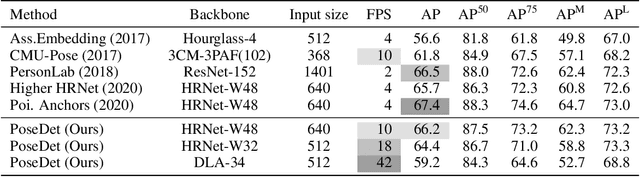
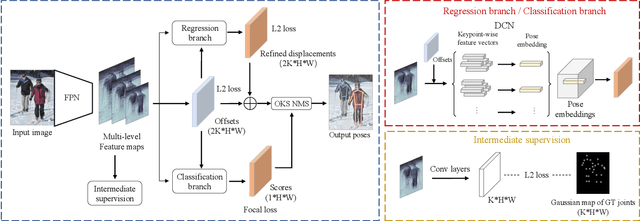
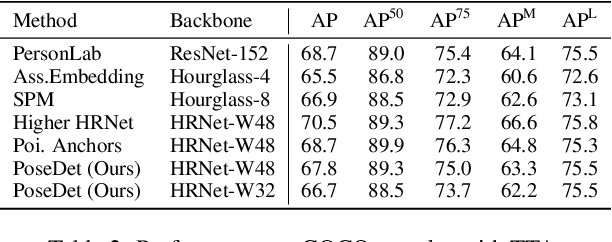
Current methods of multi-person pose estimation typically treat the localization and the association of body joints separately. It is convenient but inefficient, leading to additional computation and a waste of time. This paper, however, presents a novel framework PoseDet (Estimating Pose by Detection) to localize and associate body joints simultaneously at higher inference speed. Moreover, we propose the keypoint-aware pose embedding to represent an object in terms of the locations of its keypoints. The proposed pose embedding contains semantic and geometric information, allowing us to access discriminative and informative features efficiently. It is utilized for candidate classification and body joint localization in PoseDet, leading to robust predictions of various poses. This simple framework achieves an unprecedented speed and a competitive accuracy on the COCO benchmark compared with state-of-the-art methods. Extensive experiments on the CrowdPose benchmark show the robustness in the crowd scenes. Source code is available.