 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciCode: A Research Coding Benchmark Curated by Scientists
Jul 18, 2024



Since language models (LMs) now outperform average humans on many challenging tasks, it has become increasingly difficult to develop challenging, high-quality, and realistic evaluations. We address this issue by examining LMs' capabilities to generate code for solving real scientific research problems. Incorporating input from scientists and AI researchers in 16 diverse natural science sub-fields, including mathematics, physics, chemistry, biology, and materials science, we created a scientist-curated coding benchmark, SciCode. The problems in SciCode naturally factorize into multiple subproblems, each involving knowledge recall, reasoning, and code synthesis. In total, SciCode contains 338 subproblems decomposed from 80 challenging main problems. It offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. Claude3.5-Sonnet, the best-performing model among those tested, can solve only 4.6% of the problems in the most realistic setting. We believe that SciCode demonstrates both contemporary LMs' progress towards becoming helpful scientific assistants and sheds light on the development and evaluation of scientific AI in the future.
A Deep Learning Framework for Traffic Data Imputation Considering Spatiotemporal Dependencies
Apr 18, 2023



Spatiotemporal (ST) data collected by sensors can be represented as multi-variate time series, which is a sequence of data points listed in an order of time. Despite the vast amount of useful information, the ST data usually suffer from the issue of missing or incomplete data, which also limits its applications. Imputation is one viable solution and is often used to prepossess the data for further applications. However, in practice, n practice, spatiotemporal data imputation is quite difficult due to the complexity of spatiotemporal dependencies with dynamic changes in the traffic network and is a crucial prepossessing task for further applications. Existing approaches mostly only capture the temporal dependencies in time series or static spatial dependencies. They fail to directly model the spatiotemporal dependencies, and the representation ability of the models is relatively limited.
Real-time Human-Centric Segmentation for Complex Video Scenes
Aug 16, 2021
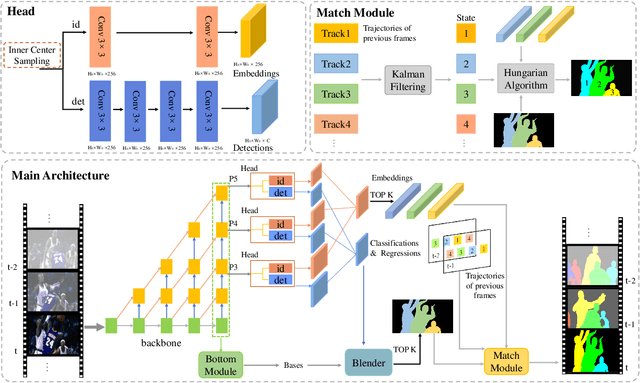

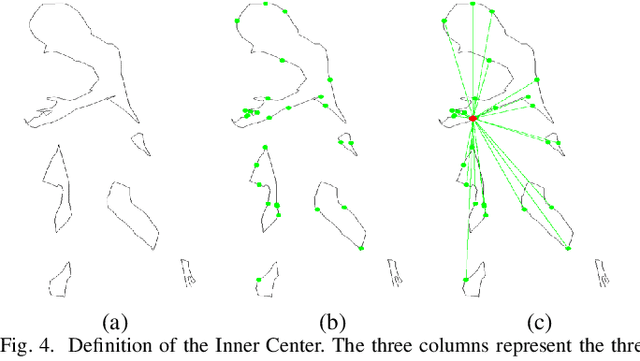
Most existing video tasks related to "human" focus on the segmentation of salient humans, ignoring the unspecified others in the video. Few studies have focused on segmenting and tracking all humans in a complex video, including pedestrians and humans of other states (e.g., seated, riding, or occluded). In this paper, we propose a novel framework, abbreviated as HVISNet, that segments and tracks all presented people in given videos based on a one-stage detector. To better evaluate complex scenes, we offer a new benchmark called HVIS (Human Video Instance Segmentation), which comprises 1447 human instance masks in 805 high-resolution videos in diverse scenes. Extensive experiments show that our proposed HVISNet outperforms the state-of-the-art methods in terms of accuracy at a real-time inference speed (30 FPS), especially on complex video scenes. We also notice that using the center of the bounding box to distinguish different individuals severely deteriorates the segmentation accuracy, especially in heavily occluded conditions. This common phenomenon is referred to as the ambiguous positive samples problem. To alleviate this problem, we propose a mechanism named Inner Center Sampling to improve the accuracy of instance segmentation. Such a plug-and-play inner center sampling mechanism can be incorporated in any instance segmentation models based on a one-stage detector to improve the performance. In particular, it gains 4.1 mAP improvement on the state-of-the-art method in the case of occluded humans. Code and data are available at https://github.com/IIGROUP/HVISNet.
PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
Jul 27, 2021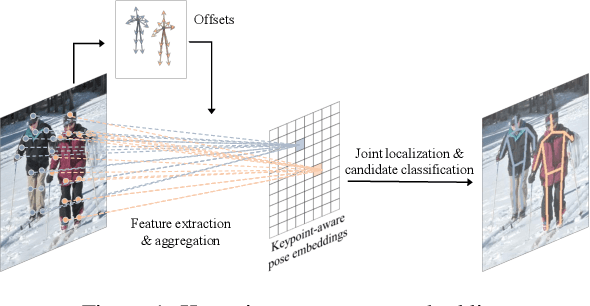
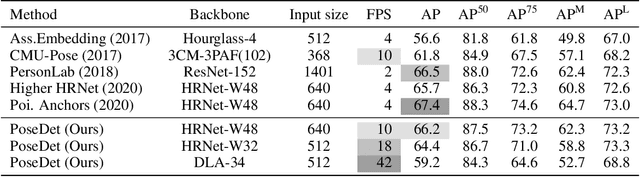
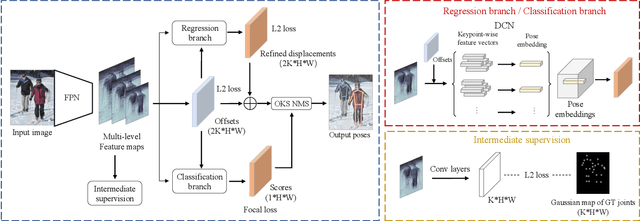
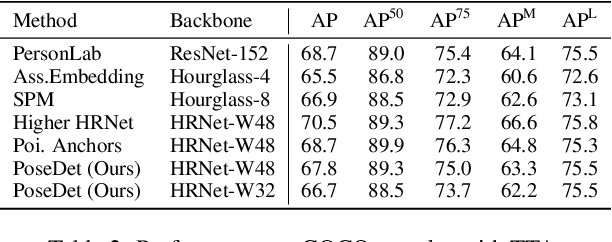
Current methods of multi-person pose estimation typically treat the localization and the association of body joints separately. It is convenient but inefficient, leading to additional computation and a waste of time. This paper, however, presents a novel framework PoseDet (Estimating Pose by Detection) to localize and associate body joints simultaneously at higher inference speed. Moreover, we propose the keypoint-aware pose embedding to represent an object in terms of the locations of its keypoints. The proposed pose embedding contains semantic and geometric information, allowing us to access discriminative and informative features efficiently. It is utilized for candidate classification and body joint localization in PoseDet, leading to robust predictions of various poses. This simple framework achieves an unprecedented speed and a competitive accuracy on the COCO benchmark compared with state-of-the-art methods. Extensive experiments on the CrowdPose benchmark show the robustness in the crowd scenes. Source code is available.
Learning Large-scale Location Embedding From Human Mobility Trajectories with Graphs
Feb 23, 2021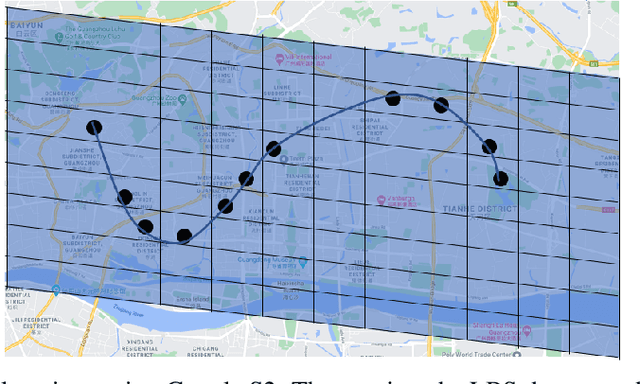
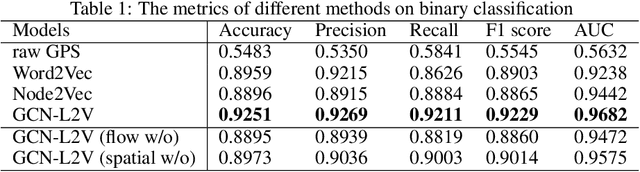
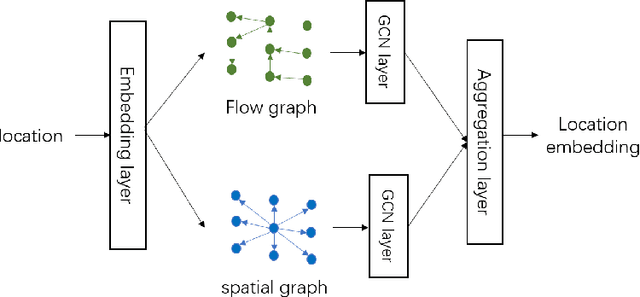
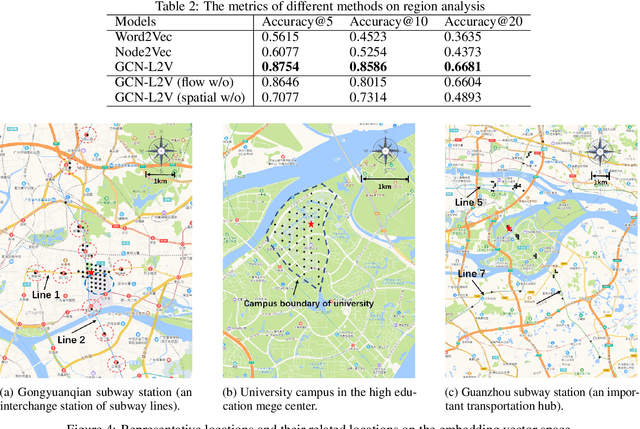
GPS coordinates and other location indicators are fine-grained location indicators that are difficult to be effectively utilized by machine learning models in Geo-aware applications. Previous location embedding methods are mostly tailored for specific problems that are taken place within areas of interest. When it comes to the scale of the entire cities, existing approaches always suffer from extensive computational cost and signigicant information loss. An increasing amount of location-based service (LBS) data are being accumulated and released to the public and enables us to study urban dynamics and human mobility. This study learns vector representations for locations using the large-scale LBS data. Different from existing studies, we propose to consider both spatial connection and human mobility, and jointly learn the representations from a flow graph and a spatial graph through a GCN-aided skip-gram model named GCN-L2V. This model embeds context information in human mobility and spatial information. By doing so, GCN-L2V is able to capture relationships among locations and provide a better notion of semantic similarity in a spatial environment. Across quantitative experiments and case studies, we empirically demonstrate that the representations learned by GCN-L2V are effective. GCN-L2V can be applied in a complementary manner to other place embedding methods and down-streaming Geo-aware applications.