 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Look at LIDAR-aided Data-driven mmWave Beam Selection
May 03, 2021
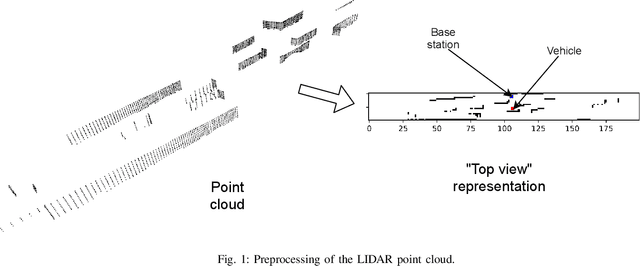
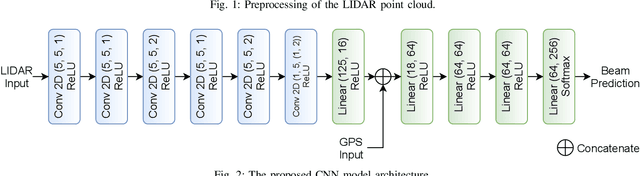
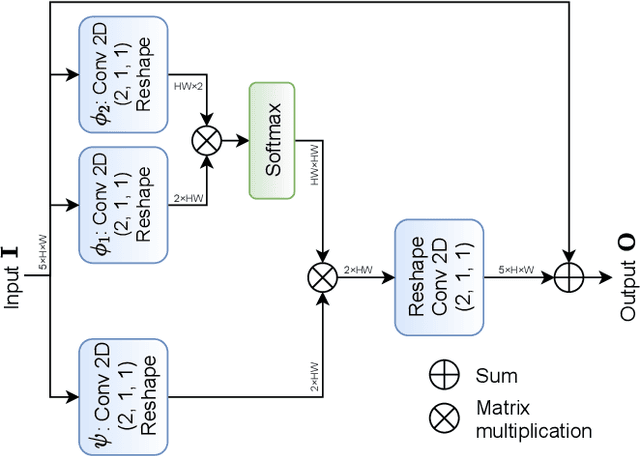
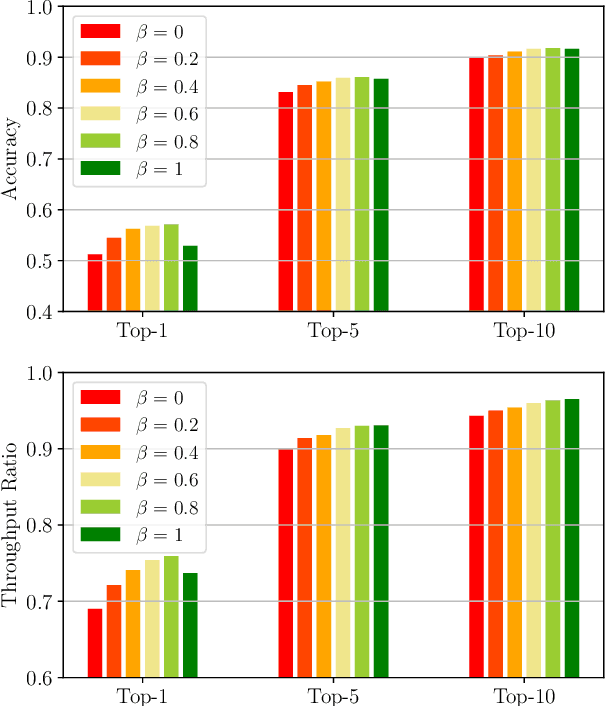
Efficient millimeter wave (mmWave) beam selection in vehicle-to-infrastructure (V2I) communication is a crucial yet challenging task due to the narrow mmWave beamwidth and high user mobility. To reduce the search overhead of iterative beam discovery procedures, contextual information from light detection and ranging (LIDAR) sensors mounted on vehicles has been leveraged by data-driven methods to produce useful side information. In this paper, we propose a lightweight neural network (NN) architecture along with the corresponding LIDAR preprocessing, which significantly outperforms previous works. Our solution comprises multiple novelties that improve both the convergence speed and the final accuracy of the model. In particular, we define a novel loss function inspired by the knowledge distillation idea, introduce a curriculum training approach exploiting line-of-sight (LOS)/non-line-of-sight (NLOS) information, and we propose a non-local attention module to improve the performance for the more challenging NLOS cases. Simulation results on benchmark datasets show that, utilizing solely LIDAR data and the receiver position, our NN-based beam selection scheme can achieve 79.9% throughput of an exhaustive beam sweeping approach without any beam search overhead and 95% by searching among as few as 6 beams.
Codebook Design and Beam Training for Extremely Large-Scale RIS: Far-Field or Near-Field?
Sep 21, 2021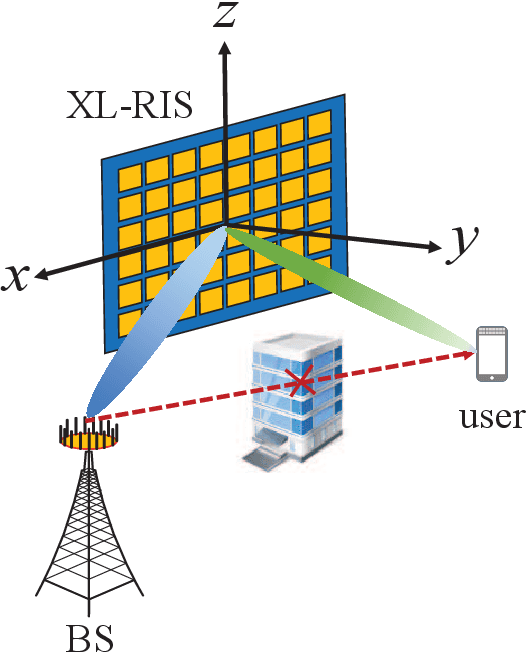
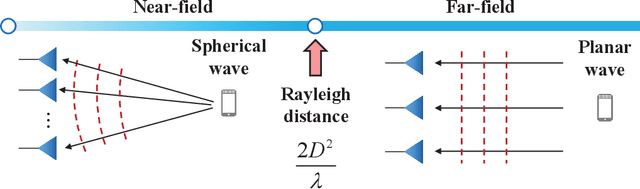
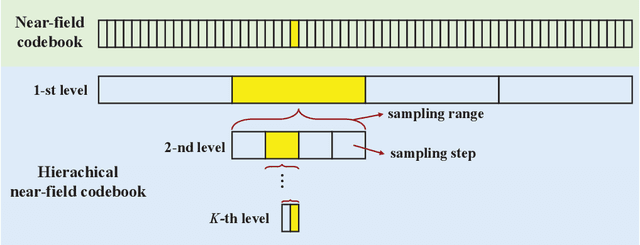
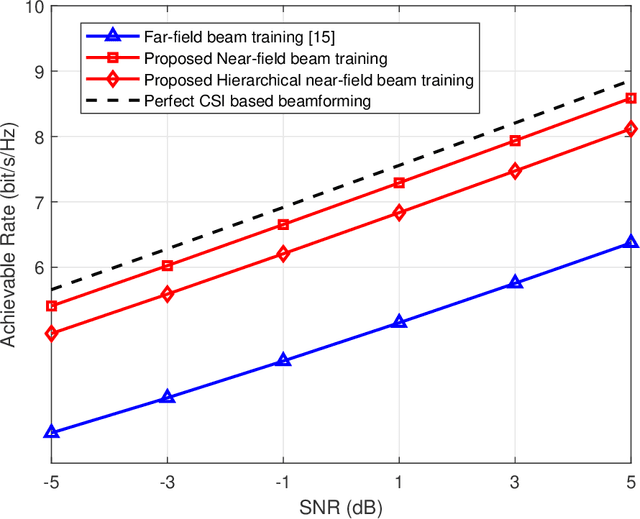
Reconfigurable intelligent surface (RIS) can improve the capacity of the wireless communication system by providing the extra link between the base station (BS) and the user. In order to resist the "multiplicative fading" effect, RIS is more likely to develop into extremely large-scale RIS (XL-RIS) for future 6G communications. Beam training is an effective way to acquire channel state information (CSI) for the XL-RIS assisted system. Existing beam training schemes rely on the far-field codebook, which is designed based on the far-field channel model. However, due to the large aperture of XL-RIS, the user is more likely to be in the near-field region of XL-RIS. The far-field codebook mismatches the near-field channel model. Thus, the existing far-field beam training scheme will cause severe performance loss in the XL-RIS assisted near-field communications. To solve this problem, we propose the efficient near-field beam training schemes by designing the near-field codebook to match the near-field channel model. Specifically, we firstly design the near-field codebook by considering the near-field cascaded array steering vector of XL-RIS. Then, the optimal codeword for XL-RIS is obtained by the exhausted training procedure between the XL-RIS and the user. In order to reduce the beam training overhead, we further design a hierarchical near-field codebook and propose the corresponding hierarchical near-field beam training scheme, where different levels of sub-codebooks are searched in turn with reduced codebook size. Simulation results show the two proposed near-field beam training schemes both perform better than the existing far-field beam training scheme. Particulary, the hierarchical near-field beam training scheme can greatly reduce the beam training overhead with acceptable performance loss.
StarVQA: Space-Time Attention for Video Quality Assessment
Aug 22, 2021
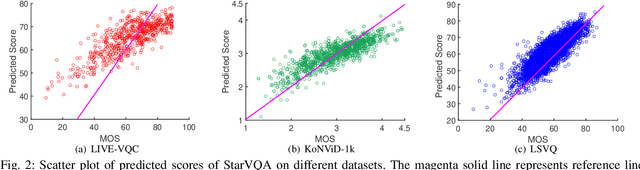
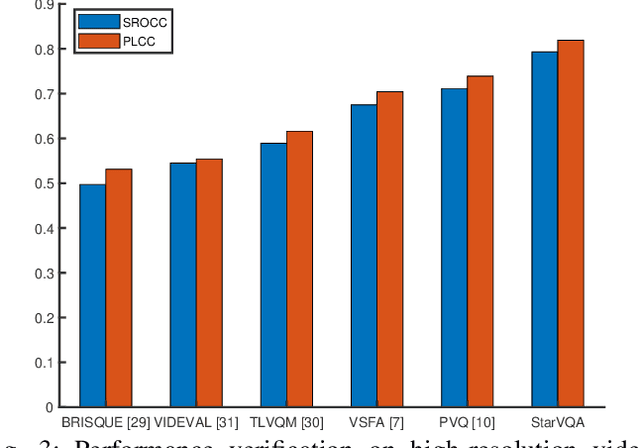
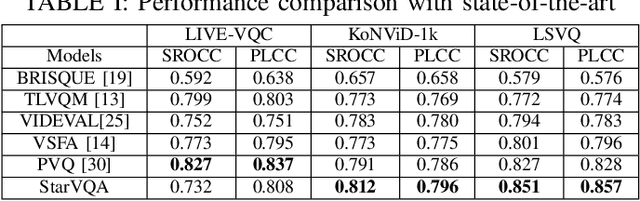
The attention mechanism is blooming in computer vision nowadays. However, its application to video quality assessment (VQA) has not been reported. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a novel \underline{s}pace-\underline{t}ime \underline{a}ttention network fo\underline{r} the \underline{VQA} problem, named StarVQA. StarVQA builds a Transformer by alternately concatenating the divided space-time attention. To adapt the Transformer architecture for training, StarVQA designs a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special vectorized label token as the learnable variable. To capture the long-range spatiotemporal dependencies of a video sequence, StarVQA encodes the space-time position information of each patch to the input of the Transformer. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-VQC, KoNViD-1k, LSVQ, and LSVQ-1080p. Experimental results demonstrate the superiority of the proposed StarVQA over the state-of-the-art. Code and model will be available at: https://github.com/DVL/StarVQA.
Signature Verification using Geometrical Features and Artificial Neural Network Classifier
Aug 04, 2021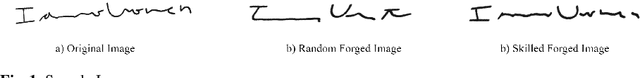
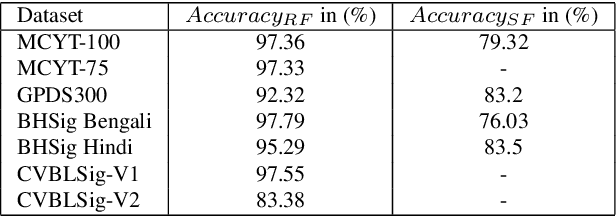
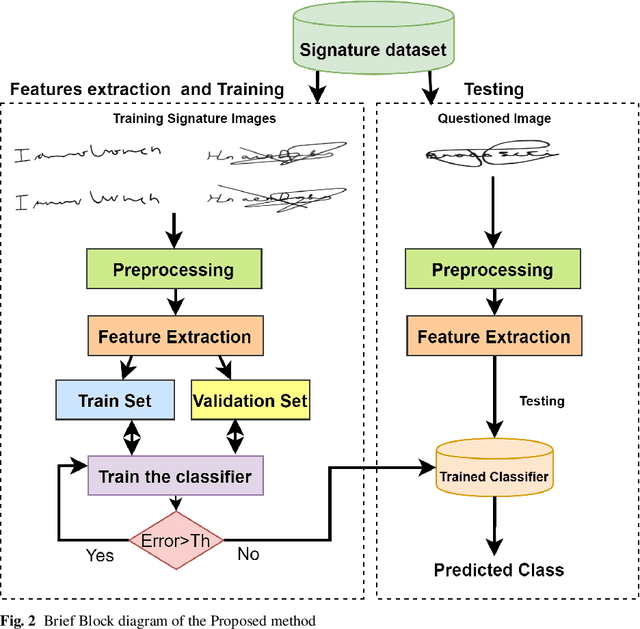
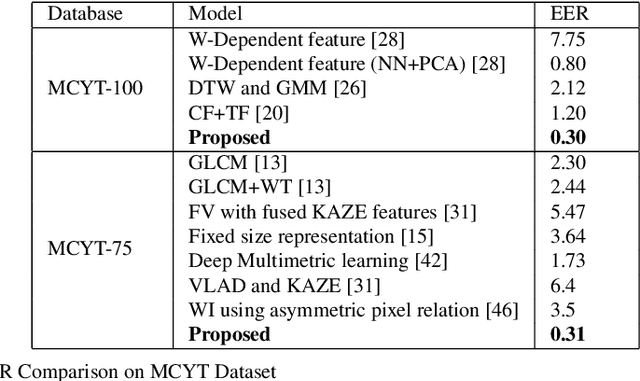
Signature verification has been one of the major researched areas in the field of computer vision. Many financial and legal organizations use signature verification as access control and authentication. Signature images are not rich in texture; however, they have much vital geometrical information. Through this work, we have proposed a signature verification methodology that is simple yet effective. The technique presented in this paper harnesses the geometrical features of a signature image like center, isolated points, connected components, etc., and with the power of Artificial Neural Network (ANN) classifier, classifies the signature image based on their geometrical features. Publicly available dataset MCYT, BHSig260 (contains the image of two regional languages Bengali and Hindi) has been used in this paper to test the effectiveness of the proposed method. We have received a lower Equal Error Rate (EER) on MCYT 100 dataset and higher accuracy on the BHSig260 dataset.
BERT-CoQAC: BERT-based Conversational Question Answering in Context
Apr 23, 2021
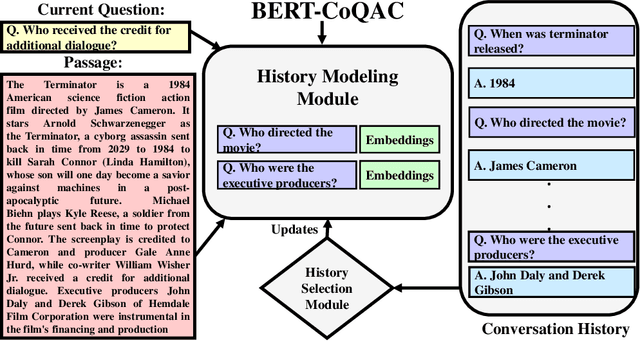
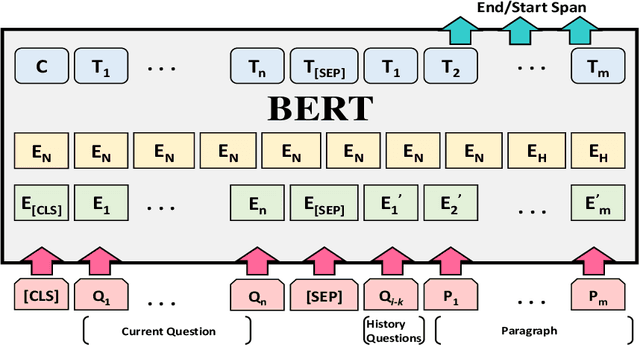
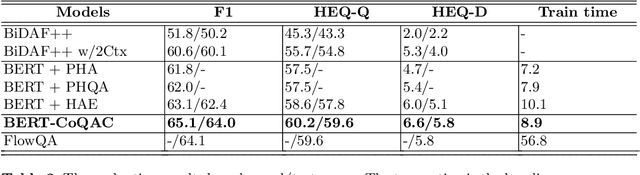
As one promising way to inquire about any particular information through a dialog with the bot, question answering dialog systems have gained increasing research interests recently. Designing interactive QA systems has always been a challenging task in natural language processing and used as a benchmark to evaluate a machine's ability of natural language understanding. However, such systems often struggle when the question answering is carried out in multiple turns by the users to seek more information based on what they have already learned, thus, giving rise to another complicated form called Conversational Question Answering (CQA). CQA systems are often criticized for not understanding or utilizing the previous context of the conversation when answering the questions. To address the research gap, in this paper, we explore how to integrate conversational history into the neural machine comprehension system. On one hand, we introduce a framework based on a publically available pre-trained language model called BERT for incorporating history turns into the system. On the other hand, we propose a history selection mechanism that selects the turns that are relevant and contributes the most to answer the current question. Experimentation results revealed that our framework is comparable in performance with the state-of-the-art models on the QuAC leader board. We also conduct a number of experiments to show the side effects of using entire context information which brings unnecessary information and noise signals resulting in a decline in the model's performance.
Data Analytics for Smart cities: Challenges and Promises
Sep 12, 2021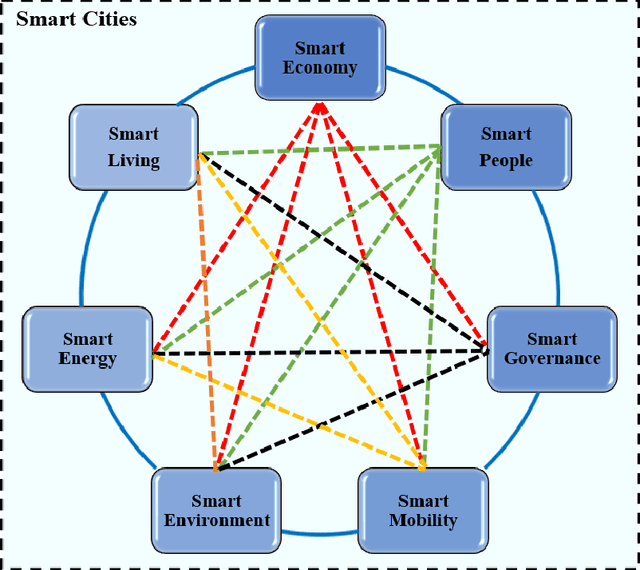
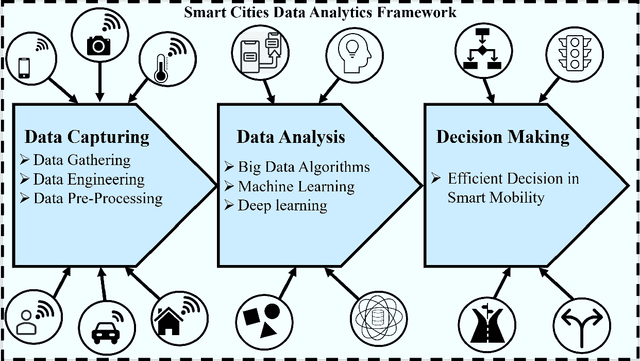
The explosion of advancements in artificial intelligence, sensor technologies, and wireless communication activates ubiquitous sensing through distributed sensors. These sensors are various domains of networks that lead us to smart systems in healthcare, transportation, environment, and other relevant branches/networks. Having collaborative interaction among the smart systems connects end-user devices to each other which enables achieving a new integrated entity called Smart Cities. The goal of this study is to provide a comprehensive survey of data analytics in smart cities. In this paper, we aim to focus on one of the smart cities important branches, namely Smart Mobility, and its positive ample impact on the smart cities decision-making process. Intelligent decision-making systems in smart mobility offer many advantages such as saving energy, relaying city traffic, and more importantly, reducing air pollution by offering real-time useful information and imperative knowledge. Making a decision in smart cities in time is challenging due to various and high dimensional factors and parameters, which are not frequently collected. In this paper, we first address current challenges in smart cities and provide an overview of potential solutions to these challenges. Then, we offer a framework of these solutions, called universal smart cities decision making, with three main sections of data capturing, data analysis, and decision making to optimize the smart mobility within smart cities. With this framework, we elaborate on fundamental concepts of big data, machine learning, and deep leaning algorithms that have been applied to smart cities and discuss the role of these algorithms in decision making for smart mobility in smart cities.
Generating Concurrent Programs From Sequential Data Structure Knowledge Using Answer Set Programming
Sep 17, 2021


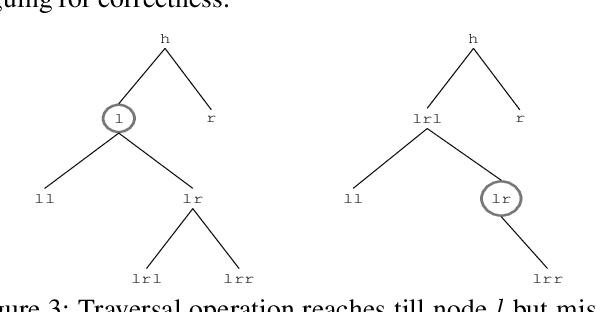
We tackle the problem of automatically designing concurrent data structure operations given a sequential data structure specification and knowledge about concurrent behavior. Designing concurrent code is a non-trivial task even in simplest of cases. Humans often design concurrent data structure operations by transforming sequential versions into their respective concurrent versions. This requires an understanding of the data structure, its sequential behavior, thread interactions during concurrent execution and shared memory synchronization primitives. We mechanize this design process using automated commonsense reasoning. We assume that the data structure description is provided as axioms alongside the sequential code of its algebraic operations. This information is used to automatically derive concurrent code for that data structure, such as dictionary operations for linked lists and binary search trees. Knowledge in our case is expressed using Answer Set Programming (ASP), and we employ deduction and abduction -- just as humans do -- in the reasoning involved. ASP allows for succinct modeling of first order theories of pointer data structures, run-time thread interactions and shared memory synchronization. Our reasoner can systematically make the same judgments as a human reasoner, while constructing provably safe concurrent code. We present several reasoning challenges involved in transforming the sequential data structure into its equivalent concurrent version. All the reasoning tasks are encoded in ASP and our reasoner can make sound judgments to transform sequential code into concurrent code. To the best of our knowledge, our work is the first one to use commonsense reasoning to automatically transform sequential programs into concurrent code. We also have developed a tool that we describe that relies on state-of-the-art ASP solvers and performs the reasoning tasks involved to generate concurrent code.
* In Proceedings ICLP 2021, arXiv:2109.07914. arXiv admin note: substantial text overlap with arXiv:2011.04045
HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization
Jun 19, 2021
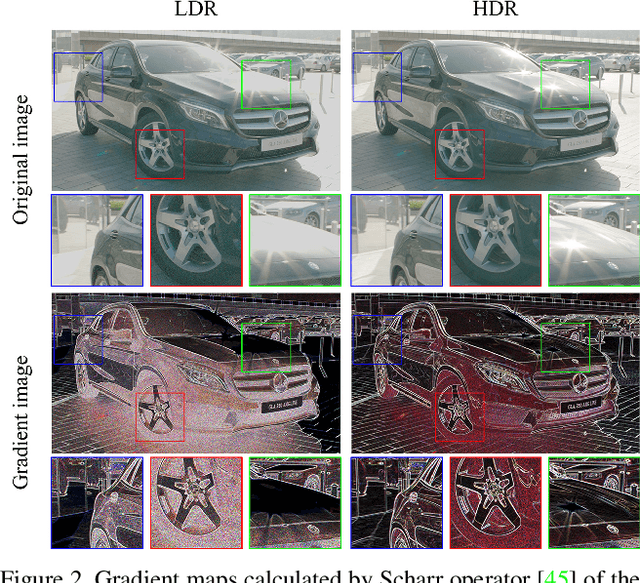
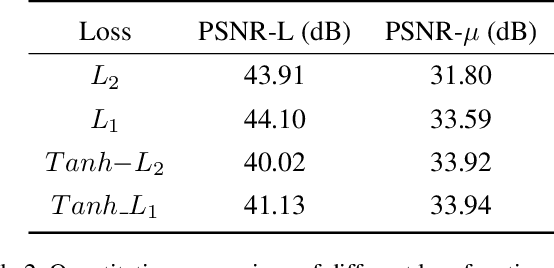
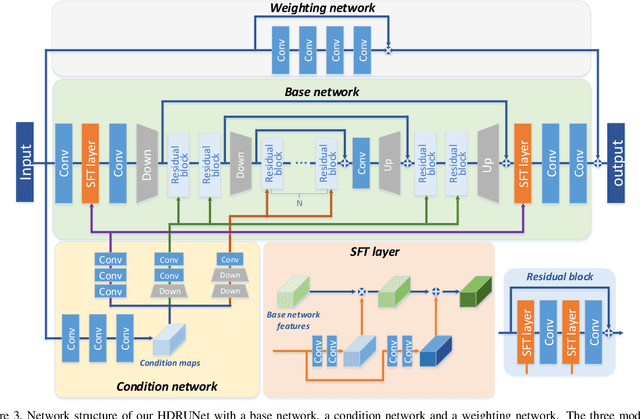
Most consumer-grade digital cameras can only capture a limited range of luminance in real-world scenes due to sensor constraints. Besides, noise and quantization errors are often introduced in the imaging process. In order to obtain high dynamic range (HDR) images with excellent visual quality, the most common solution is to combine multiple images with different exposures. However, it is not always feasible to obtain multiple images of the same scene and most HDR reconstruction methods ignore the noise and quantization loss. In this work, we propose a novel learning-based approach using a spatially dynamic encoder-decoder network, HDRUNet, to learn an end-to-end mapping for single image HDR reconstruction with denoising and dequantization. The network consists of a UNet-style base network to make full use of the hierarchical multi-scale information, a condition network to perform pattern-specific modulation and a weighting network for selectively retaining information. Moreover, we propose a Tanh_L1 loss function to balance the impact of over-exposed values and well-exposed values on the network learning. Our method achieves the state-of-the-art performance in quantitative comparisons and visual quality. The proposed HDRUNet model won the second place in the single frame track of NITRE2021 High Dynamic Range Challenge.
GlyphCRM: Bidirectional Encoder Representation for Chinese Character with its Glyph
Jul 01, 2021
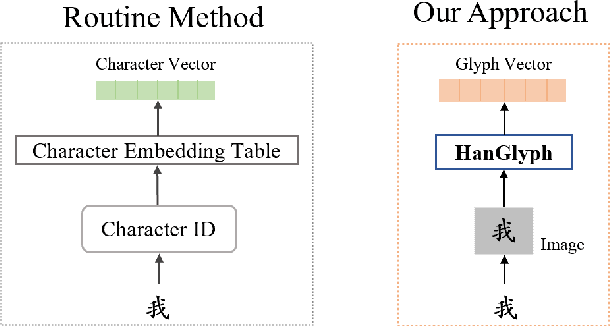
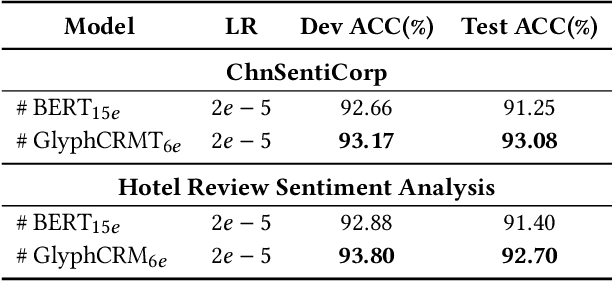
Previous works indicate that the glyph of Chinese characters contains rich semantic information and has the potential to enhance the representation of Chinese characters. The typical method to utilize the glyph features is by incorporating them into the character embedding space. Inspired by previous methods, we innovatively propose a Chinese pre-trained representation model named as GlyphCRM, which abandons the ID-based character embedding method yet solely based on sequential character images. We render each character into a binary grayscale image and design two-channel position feature maps for it. Formally, we first design a two-layer residual convolutional neural network, namely HanGlyph to generate the initial glyph representation of Chinese characters, and subsequently adopt multiple bidirectional encoder Transformer blocks as the superstructure to capture the context-sensitive information. Meanwhile, we feed the glyph features extracted from each layer of the HanGlyph module into the underlying Transformer blocks by skip-connection method to fully exploit the glyph features of Chinese characters. As the HanGlyph module can obtain a sufficient glyph representation of any Chinese character, the long-standing out-of-vocabulary problem could be effectively solved. Extensive experimental results indicate that GlyphCRM substantially outperforms the previous BERT-based state-of-the-art model on 9 fine-tuning tasks, and it has strong transferability and generalization on specialized fields and low-resource tasks. We hope this work could spark further research beyond the realms of well-established representation of Chinese texts.
Smart On-Chip Electromagnetic Environment
Sep 07, 2021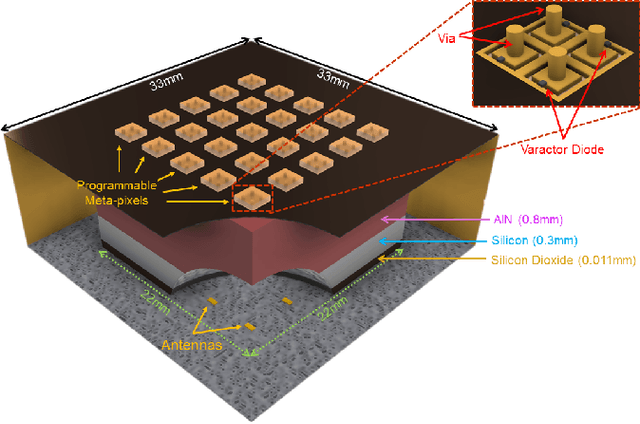
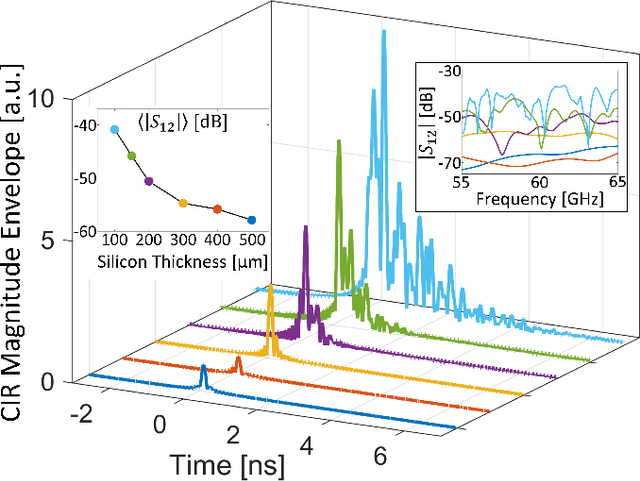
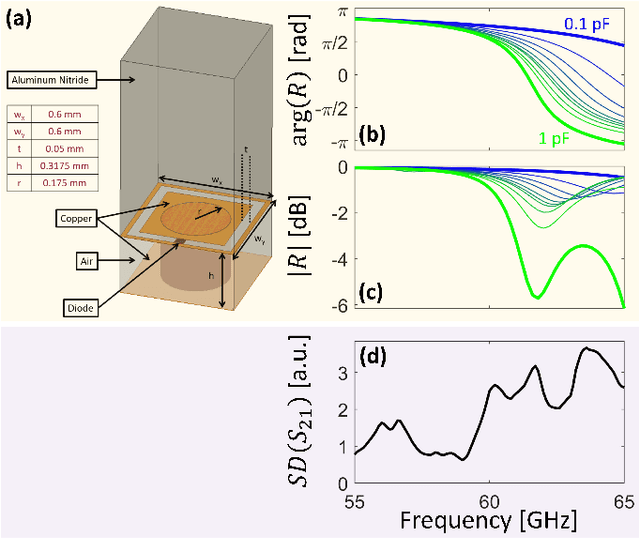
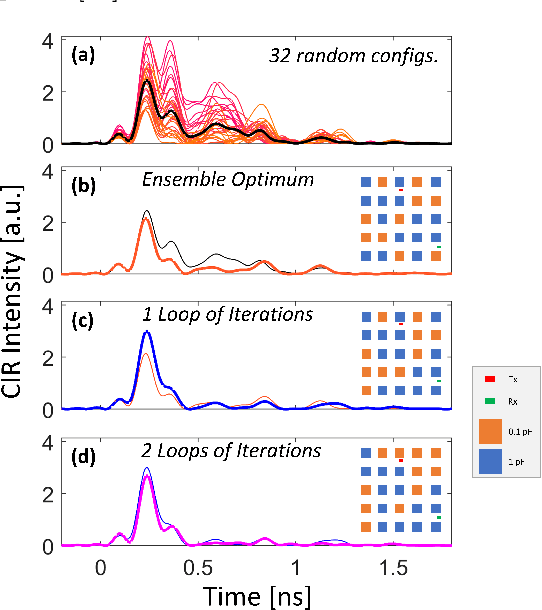
We introduce the concept of smart radio environments, currently extensively studied for wireless communication in metasurface-programmable meter-scaled environments (e.g., inside rooms), on the chip scale. Wired intra-chip communication for information exchange between cores increasingly becomes a computation-speed-bottleneck for modern multi-core chips. Wireless intra-chip links with millimeter waves are a candidate technology to address this challenge, but they currently face their own problems: the on-chip propagation environment can be highly reverberant due to the metallic chip enclosure but transceiver modules must be kept simple (on/off keying) such that long channel impulse responses (CIRs) slow down the communication rate. Here, we overcome this problem by endowing the on-chip propagation environment with in situ programmability, allowing us to shape the CIR at will, and to impose, for instance, a pulse-like CIR despite the strong multi-path environment. Using full-wave simulations, we design a programmable metasurface suitable for integration in the on-chip environment ("on-chip reconfigurable intelligent surface"), and we demonstrate that the spatial control offered by the metasurface allows us to shape the CIR profile. We envision (i) dynamic multi-channel CIR shaping adapted to on-chip traffic patterns, (ii) analog wave-based over-the-air computing inside the chip enclosure, and (iii) the application of the explored concepts to off-chip communication inside racks, inside the chassis of personal computers, etc.