 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Autonomous Driving Object Detection Misclassifications with Automated Commonsense Reasoning
Jan 07, 2026Autonomous Vehicle (AV) technology has been heavily researched and sought after, yet there are no SAE Level 5 AVs available today in the marketplace. We contend that over-reliance on machine learning technology is the main reason. Use of automated commonsense reasoning technology, we believe, can help achieve SAE Level 5 autonomy. In this paper, we show how automated common- sense reasoning technology can be deployed in situations where there are not enough data samples available to train a deep learning-based AV model that can handle certain abnormal road scenarios. Specifically, we consider two situations where (i) a traffic signal is malfunctioning at an intersection and (ii) all the cars ahead are slowing down and steering away due to an unexpected obstruction (e.g., animals on the road). We show that in such situations, our commonsense reasoning-based solution accurately detects traffic light colors and obstacles not correctly captured by the AV's perception model. We also provide a pathway for efficiently invoking commonsense reasoning by measuring uncertainty in the computer vision model and using commonsense reasoning to handle uncertain sce- narios. We describe our experiments conducted using the CARLA simulator and the results obtained. The main contribution of our research is to show that automated commonsense reasoning effectively corrects AV-based object detection misclassifications and that hybrid models provide an effective pathway to improving AV perception.
* In Proceedings ICLP 2025, arXiv:2601.00047
MC3G: Model Agnostic Causally Constrained Counterfactual Generation
Aug 24, 2025

Machine learning models increasingly influence decisions in high-stakes settings such as finance, law and hiring, driving the need for transparent, interpretable outcomes. However, while explainable approaches can help understand the decisions being made, they may inadvertently reveal the underlying proprietary algorithm: an undesirable outcome for many practitioners. Consequently, it is crucial to balance meaningful transparency with a form of recourse that clarifies why a decision was made and offers actionable steps following which a favorable outcome can be obtained. Counterfactual explanations offer a powerful mechanism to address this need by showing how specific input changes lead to a more favorable prediction. We propose Model-Agnostic Causally Constrained Counterfactual Generation (MC3G), a novel framework that tackles limitations in the existing counterfactual methods. First, MC3G is model-agnostic: it approximates any black-box model using an explainable rule-based surrogate model. Second, this surrogate is used to generate counterfactuals that produce a favourable outcome for the original underlying black box model. Third, MC3G refines cost computation by excluding the ``effort" associated with feature changes that occur automatically due to causal dependencies. By focusing only on user-initiated changes, MC3G provides a more realistic and fair representation of the effort needed to achieve a favourable outcome. We show that MC3G delivers more interpretable and actionable counterfactual recommendations compared to existing techniques all while having a lower cost. Our findings highlight MC3G's potential to enhance transparency, accountability, and practical utility in decision-making processes that incorporate machine-learning approaches.
Building Trustworthy AI by Addressing its 16+2 Desiderata with Goal-Directed Commonsense Reasoning
Jun 15, 2025
Current advances in AI and its applicability have highlighted the need to ensure its trustworthiness for legal, ethical, and even commercial reasons. Sub-symbolic machine learning algorithms, such as the LLMs, simulate reasoning but hallucinate and their decisions cannot be explained or audited (crucial aspects for trustworthiness). On the other hand, rule-based reasoners, such as Cyc, are able to provide the chain of reasoning steps but are complex and use a large number of reasoners. We propose a middle ground using s(CASP), a goal-directed constraint-based answer set programming reasoner that employs a small number of mechanisms to emulate reliable and explainable human-style commonsense reasoning. In this paper, we explain how s(CASP) supports the 16 desiderata for trustworthy AI introduced by Doug Lenat and Gary Marcus (2023), and two additional ones: inconsistency detection and the assumption of alternative worlds. To illustrate the feasibility and synergies of s(CASP), we present a range of diverse applications, including a conversational chatbot and a virtually embodied reasoner.
Symbolic Rule Extraction from Attention-Guided Sparse Representations in Vision Transformers
May 10, 2025



Recent neuro-symbolic approaches have successfully extracted symbolic rule-sets from CNN-based models to enhance interpretability. However, applying similar techniques to Vision Transformers (ViTs) remains challenging due to their lack of modular concept detectors and reliance on global self-attention mechanisms. We propose a framework for symbolic rule extraction from ViTs by introducing a sparse concept layer inspired by Sparse Autoencoders (SAEs). This linear layer operates on attention-weighted patch representations and learns a disentangled, binarized representation in which individual neurons activate for high-level visual concepts. To encourage interpretability, we apply a combination of L1 sparsity, entropy minimization, and supervised contrastive loss. These binarized concept activations are used as input to the FOLD-SE-M algorithm, which generates a rule-set in the form of logic programs. Our method achieves a 5.14% better classification accuracy than the standard ViT while enabling symbolic reasoning. Crucially, the extracted rule-set is not merely post-hoc but acts as a logic-based decision layer that operates directly on the sparse concept representations. The resulting programs are concise and semantically meaningful. This work is the first to extract executable logic programs from ViTs using sparse symbolic representations. It bridges the gap between transformer-based vision models and symbolic logic programming, providing a step forward in interpretable and verifiable neuro-symbolic AI.
Reliable Collaborative Conversational Agent System Based on LLMs and Answer Set Programming
May 09, 2025


As the Large-Language-Model-driven (LLM-driven) Artificial Intelligence (AI) bots became popular, people realized their strong potential in Task-Oriented Dialogue (TOD). However, bots relying wholly on LLMs are unreliable in their knowledge, and whether they can finally produce a correct result for the task is not guaranteed. The collaboration among these agents also remains a challenge, since the necessary information to convey is unclear, and the information transfer is by prompts -- unreliable, and malicious knowledge is easy to inject. With the help of logic programming tools such as Answer Set Programming (ASP), conversational agents can be built safely and reliably, and communication among the agents made more efficient and secure. We proposed an Administrator-Assistant Dual-Agent paradigm, where the two ASP-driven bots share the same knowledge base and complete their tasks independently, while the information can be passed by a Collaborative Rule Set (CRS). The knowledge and information conveyed are encapsulated and invisible to the users, ensuring the security of information transmission. We have constructed AutoManager, a dual-agent system for managing the drive-through window of a fast-food restaurant such as Taco Bell in the US. In AutoManager, the assistant bot takes the customer's order while the administrator bot manages the menu and food supply. We evaluated our AutoManager and compared it with the real-world Taco Bell Drive-Thru AI Order Taker, and the results show that our method is more reliable.
Proceedings 40th International Conference on Logic Programming
Feb 11, 2025Since the first conference In Marseille in 1982, the International Conference on Logic Programming (ICLP) has been the premier international event for presenting research in logic programming. These proceedings include technical communications about, and abstracts for presentations given at the 40th ICLP held October 14-17, in Dallas Texas, USA. The papers and abstracts in this volume include the following areas and topics. Formal and operational semantics: including non-monotonic reasoning, probabilistic reasoning, argumentation, and semantic issues of combining logic with neural models. Language design and programming methodologies such as answer set programming. inductive logic programming, and probabilistic programming. Program analysis and logic-based validation of generated programs. Implementation methodologies including constraint implementation, tabling, Logic-based prompt engineering, and the interaction of logic programming with LLMs.
Improving Interpretability and Accuracy in Neuro-Symbolic Rule Extraction Using Class-Specific Sparse Filters
Jan 28, 2025
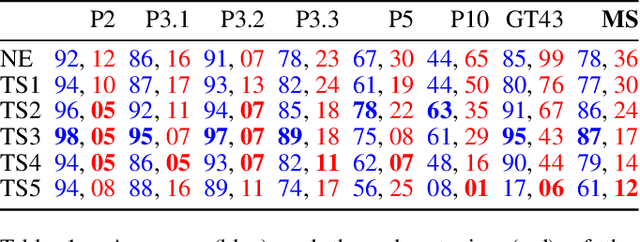

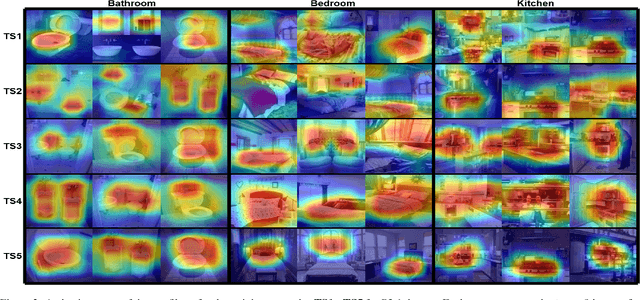
There has been significant focus on creating neuro-symbolic models for interpretable image classification using Convolutional Neural Networks (CNNs). These methods aim to replace the CNN with a neuro-symbolic model consisting of the CNN, which is used as a feature extractor, and an interpretable rule-set extracted from the CNN itself. While these approaches provide interpretability through the extracted rule-set, they often compromise accuracy compared to the original CNN model. In this paper, we identify the root cause of this accuracy loss as the post-training binarization of filter activations to extract the rule-set. To address this, we propose a novel sparsity loss function that enables class-specific filter binarization during CNN training, thus minimizing information loss when extracting the rule-set. We evaluate several training strategies with our novel sparsity loss, analyzing their effectiveness and providing guidance on their appropriate use. Notably, we set a new benchmark, achieving a 9% improvement in accuracy and a 53% reduction in rule-set size on average, compared to the previous SOTA, while coming within 3% of the original CNN's accuracy. This highlights the significant potential of interpretable neuro-symbolic models as viable alternatives to black-box CNNs.
CoGS: Model Agnostic Causality Constrained Counterfactual Explanations using goal-directed ASP
Oct 30, 2024


Machine learning models are increasingly used in critical areas such as loan approvals and hiring, yet they often function as black boxes, obscuring their decision-making processes. Transparency is crucial, as individuals need explanations to understand decisions, primarily if the decisions result in an undesired outcome. Our work introduces CoGS (Counterfactual Generation with s(CASP)), a model-agnostic framework capable of generating counterfactual explanations for classification models. CoGS leverages the goal-directed Answer Set Programming system s(CASP) to compute realistic and causally consistent modifications to feature values, accounting for causal dependencies between them. By using rule-based machine learning algorithms (RBML), notably the FOLD-SE algorithm, CoGS extracts the underlying logic of a statistical model to generate counterfactual solutions. By tracing a step-by-step path from an undesired outcome to a desired one, CoGS offers interpretable and actionable explanations of the changes required to achieve the desired outcome. We present details of the CoGS framework along with its evaluation.
A Reliable Common-Sense Reasoning Socialbot Built Using LLMs and Goal-Directed ASP
Jul 26, 2024The development of large language models (LLMs), such as GPT, has enabled the construction of several socialbots, like ChatGPT, that are receiving a lot of attention for their ability to simulate a human conversation. However, the conversation is not guided by a goal and is hard to control. In addition, because LLMs rely more on pattern recognition than deductive reasoning, they can give confusing answers and have difficulty integrating multiple topics into a cohesive response. These limitations often lead the LLM to deviate from the main topic to keep the conversation interesting. We propose AutoCompanion, a socialbot that uses an LLM model to translate natural language into predicates (and vice versa) and employs commonsense reasoning based on Answer Set Programming (ASP) to hold a social conversation with a human. In particular, we rely on s(CASP), a goal-directed implementation of ASP as the backend. This paper presents the framework design and how an LLM is used to parse user messages and generate a response from the s(CASP) engine output. To validate our proposal, we describe (real) conversations in which the chatbot's goal is to keep the user entertained by talking about movies and books, and s(CASP) ensures (i) correctness of answers, (ii) coherence (and precision) during the conversation, which it dynamically regulates to achieve its specific purpose, and (iii) no deviation from the main topic.
CoGS: Causality Constrained Counterfactual Explanations using goal-directed ASP
Jul 11, 2024


Machine learning models are increasingly used in areas such as loan approvals and hiring, yet they often function as black boxes, obscuring their decision-making processes. Transparency is crucial, and individuals need explanations to understand decisions, especially for the ones not desired by the user. Ethical and legal considerations require informing individuals of changes in input attribute values (features) that could lead to a desired outcome for the user. Our work aims to generate counterfactual explanations by considering causal dependencies between features. We present the CoGS (Counterfactual Generation with s(CASP)) framework that utilizes the goal-directed Answer Set Programming system s(CASP) to generate counterfactuals from rule-based machine learning models, specifically the FOLD-SE algorithm. CoGS computes realistic and causally consistent changes to attribute values taking causal dependencies between them into account. It finds a path from an undesired outcome to a desired one using counterfactuals. We present details of the CoGS framework along with its evaluation.