 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What can phylogenetic metrics tell us about useful diversity in evolutionary algorithms?
Aug 28, 2021
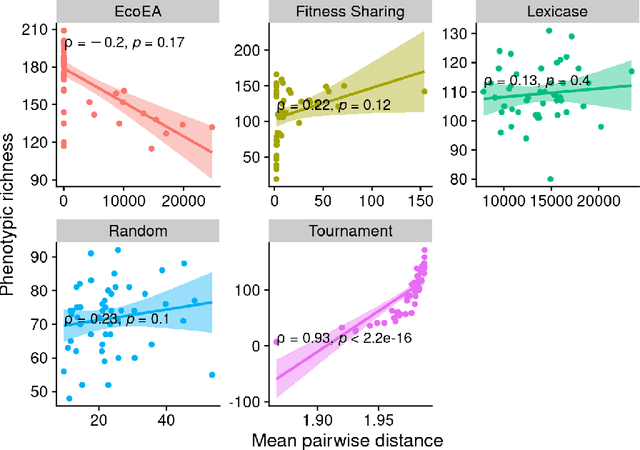
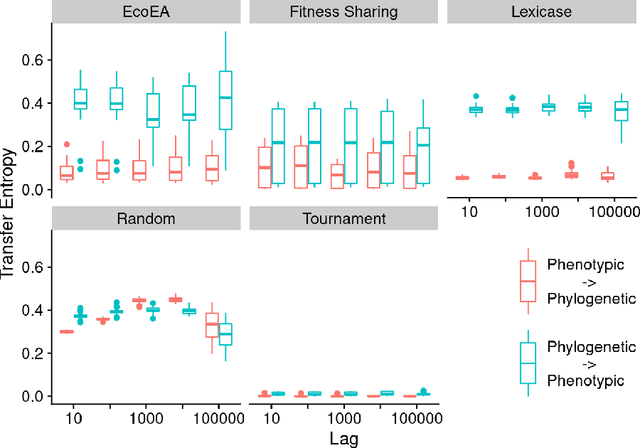
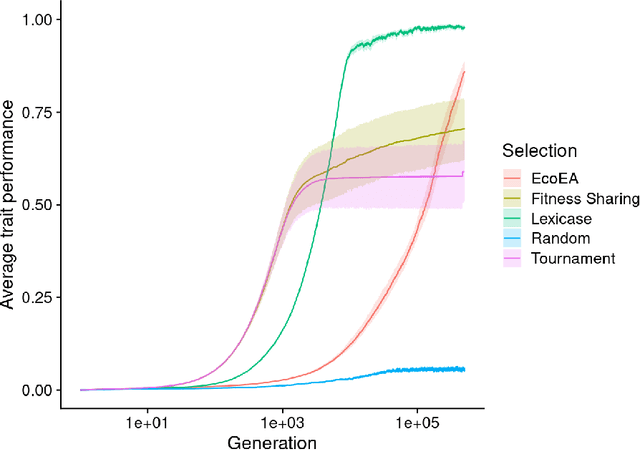
It is generally accepted that "diversity" is associated with success in evolutionary algorithms. However, diversity is a broad concept that can be measured and defined in a multitude of ways. To date, most evolutionary computation research has measured diversity using the richness and/or evenness of a particular genotypic or phenotypic property. While these metrics are informative, we hypothesize that other diversity metrics are more strongly predictive of success. Phylogenetic diversity metrics are a class of metrics popularly used in biology, which take into account the evolutionary history of a population. Here, we investigate the extent to which 1) these metrics provide different information than those traditionally used in evolutionary computation, and 2) these metrics better predict the long-term success of a run of evolutionary computation. We find that, in most cases, phylogenetic metrics behave meaningfully differently from other diversity metrics. Moreover, our results suggest that phylogenetic diversity is indeed a better predictor of success.
Semantic Table Retrieval using Keyword and Table Queries
May 13, 2021
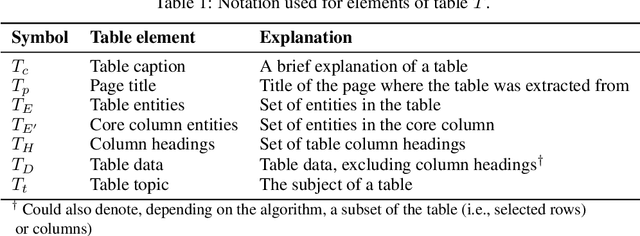
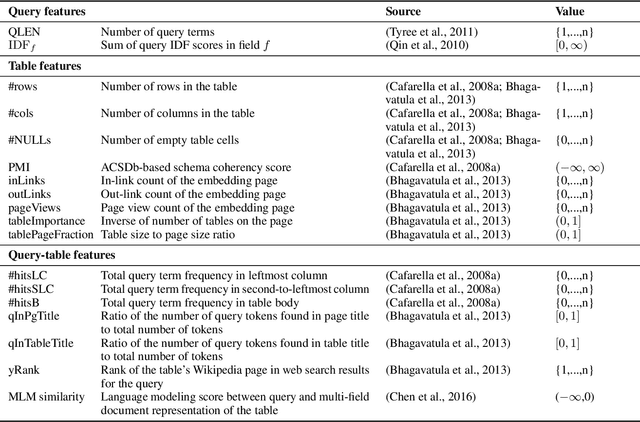
Tables on the Web contain a vast amount of knowledge in a structured form. To tap into this valuable resource, we address the problem of table retrieval: answering an information need with a ranked list of tables. We investigate this problem in two different variants, based on how the information need is expressed: as a keyword query or as an existing table ("query-by-table"). The main novel contribution of this work is a semantic table retrieval framework for matching information needs (keyword or table queries) against tables. Specifically, we (i) represent queries and tables in multiple semantic spaces (both discrete sparse and continuous dense vector representations) and (ii) introduce various similarity measures for matching those semantic representations. We consider all possible combinations of semantic representations and similarity measures and use these as features in a supervised learning model. Using two purpose-built test collections based on Wikipedia tables, we demonstrate significant and substantial improvements over state-of-the-art baselines.
Meta-Path Constrained Random Walk Inference for Large-Scale Heterogeneous Information Networks
Dec 02, 2019
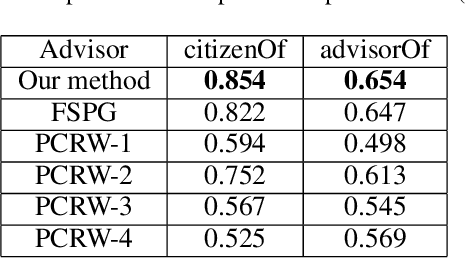

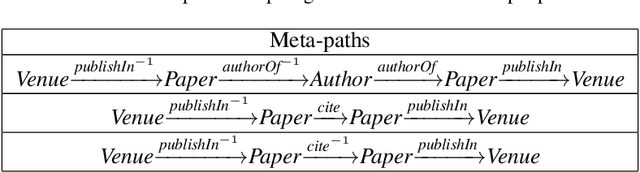
Heterogeneous information network (HIN) has shown its power of modeling real world data as a multi-typed entity-relation graph. Meta-path is the key contributor to this power since it enables inference by capturing the proximities between entities via rich semantic links. Previous HIN studies ask users to provide either 1) the meta-path(s) directly or 2) biased examples to generate the meta-path(s). However, lots of HINs (e.g., YAGO2 and Freebase) have rich schema consisting of a sophisticated and large number of types of entities and relations. It is impractical for users to provide the meta-path(s) to support the large scale inference, and biased examples will result in incorrect meta-path based inference, thus limit the power of the meta-path. In this paper, we propose a meta-path constrained inference framework to further release the ability of the meta-path, by efficiently learning the HIN inference patterns via a carefully designed tree structure; and performing unbiased random walk inference with little user guidance. The experiment results on YAGO2 and DBLP datasets show the state-of-the-art performance of the meta-path constrained inference framework.
Negative Sample Matters: A Renaissance of Metric Learning for Temporal Grounding
Sep 10, 2021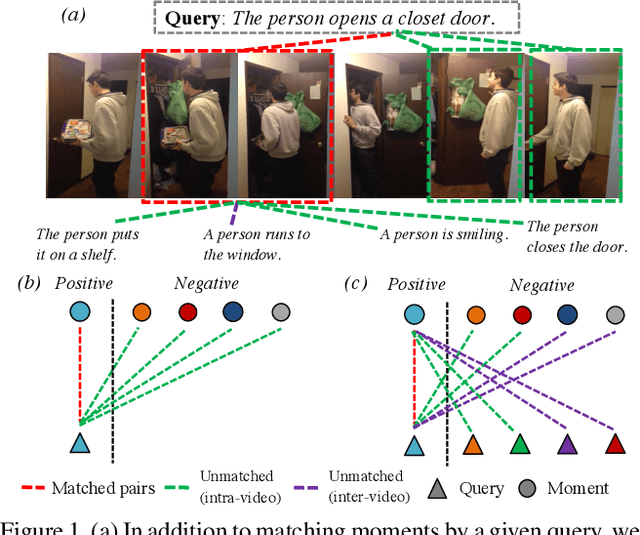

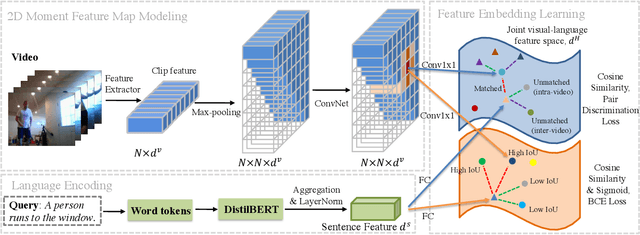
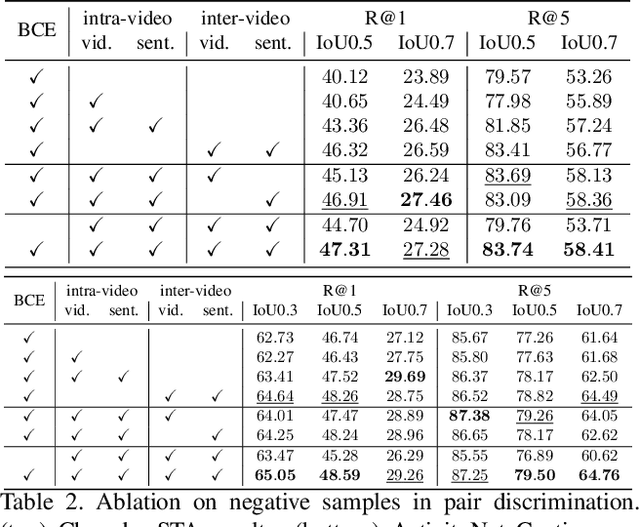
Temporal grounding aims to temporally localize a video moment in the video whose semantics are related to a given natural language query. Existing methods typically apply a detection or regression pipeline on the fused representation with a focus on designing complicated heads and fusion strategies. Instead, from a perspective on temporal grounding as a metric-learning problem, we present a Dual Matching Network (DMN), to directly model the relations between language queries and video moments in a joint embedding space. This new metric-learning framework enables fully exploiting negative samples from two new aspects: constructing negative cross-modal pairs from a dual matching scheme and mining negative pairs across different videos. These new negative samples could enhance the joint representation learning of two modalities via cross-modal pair discrimination to maximize their mutual information. Experiments show that DMN achieves highly competitive performance compared with state-of-the-art methods on four video grounding benchmarks. Based on DMN, we present a winner solution for STVG challenge of the 3rd PIC workshop. This suggests that metric-learning is still a promising method for temporal grounding via capturing the essential cross-modal correlation in a joint embedding space.
Spatio-Temporal Recurrent Networks for Event-Based Optical Flow Estimation
Sep 10, 2021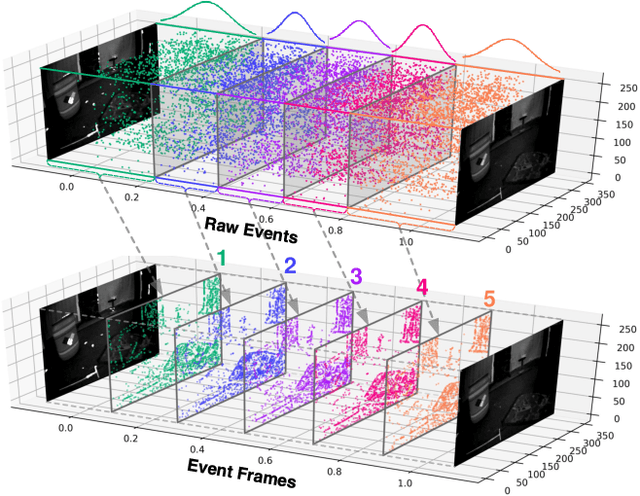
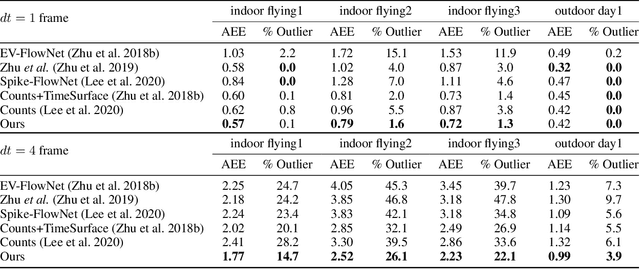
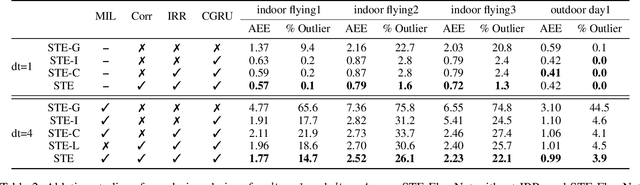
Event camera has offered promising alternative for visual perception, especially in high speed and high dynamic range scenes. Recently, many deep learning methods have shown great success in providing model-free solutions to many event-based problems, such as optical flow estimation. However, existing deep learning methods did not address the importance of temporal information well from the perspective of architecture design and cannot effectively extract spatio-temporal features. Another line of research that utilizes Spiking Neural Network suffers from training issues for deeper architecture. To address these points, a novel input representation is proposed that captures the events temporal distribution for signal enhancement. Moreover, we introduce a spatio-temporal recurrent encoding-decoding neural network architecture for event-based optical flow estimation, which utilizes Convolutional Gated Recurrent Units to extract feature maps from a series of event images. Besides, our architecture allows some traditional frame-based core modules, such as correlation layer and iterative residual refine scheme, to be incorporated. The network is end-to-end trained with self-supervised learning on the Multi-Vehicle Stereo Event Camera dataset. We have shown that it outperforms all the existing state-of-the-art methods by a large margin.
PlaTe: Visually-Grounded Planning with Transformers in Procedural Tasks
Sep 10, 2021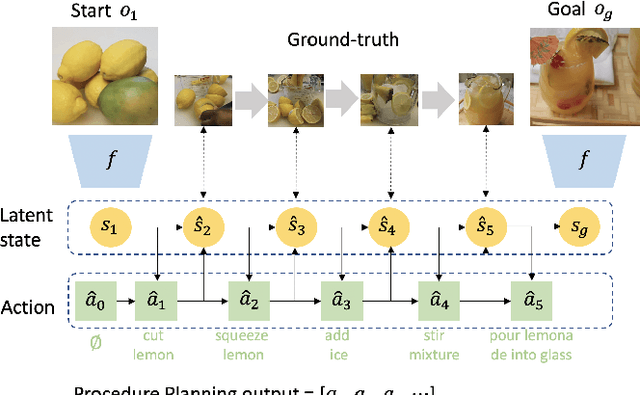
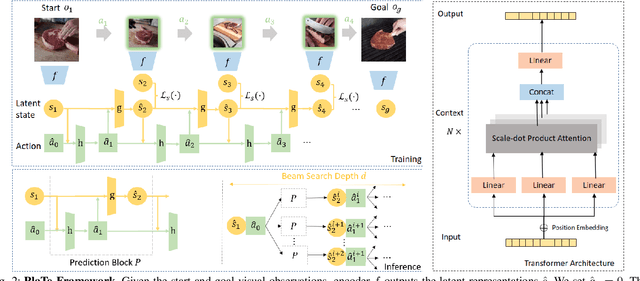

In this work, we study the problem of how to leverage instructional videos to facilitate the understanding of human decision-making processes, focusing on training a model with the ability to plan a goal-directed procedure from real-world videos. Learning structured and plannable state and action spaces directly from unstructured videos is the key technical challenge of our task. There are two problems: first, the appearance gap between the training and validation datasets could be large for unstructured videos; second, these gaps lead to decision errors that compound over the steps. We address these limitations with Planning Transformer (PlaTe), which has the advantage of circumventing the compounding prediction errors that occur with single-step models during long model-based rollouts. Our method simultaneously learns the latent state and action information of assigned tasks and the representations of the decision-making process from human demonstrations. Experiments conducted on real-world instructional videos and an interactive environment show that our method can achieve a better performance in reaching the indicated goal than previous algorithms. We also validated the possibility of applying procedural tasks on a UR-5 platform.
Enabling risk-aware Reinforcement Learning for medical interventions through uncertainty decomposition
Sep 16, 2021
Reinforcement Learning (RL) is emerging as tool for tackling complex control and decision-making problems. However, in high-risk environments such as healthcare, manufacturing, automotive or aerospace, it is often challenging to bridge the gap between an apparently optimal policy learnt by an agent and its real-world deployment, due to the uncertainties and risk associated with it. Broadly speaking RL agents face two kinds of uncertainty, 1. aleatoric uncertainty, which reflects randomness or noise in the dynamics of the world, and 2. epistemic uncertainty, which reflects the bounded knowledge of the agent due to model limitations and finite amount of information/data the agent has acquired about the world. These two types of uncertainty carry fundamentally different implications for the evaluation of performance and the level of risk or trust. Yet these aleatoric and epistemic uncertainties are generally confounded as standard and even distributional RL is agnostic to this difference. Here we propose how a distributional approach (UA-DQN) can be recast to render uncertainties by decomposing the net effects of each uncertainty. We demonstrate the operation of this method in grid world examples to build intuition and then show a proof of concept application for an RL agent operating as a clinical decision support system in critical care
Label-Attention Transformer with Geometrically Coherent Objects for Image Captioning
Sep 16, 2021
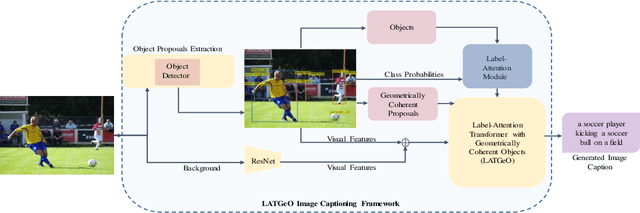
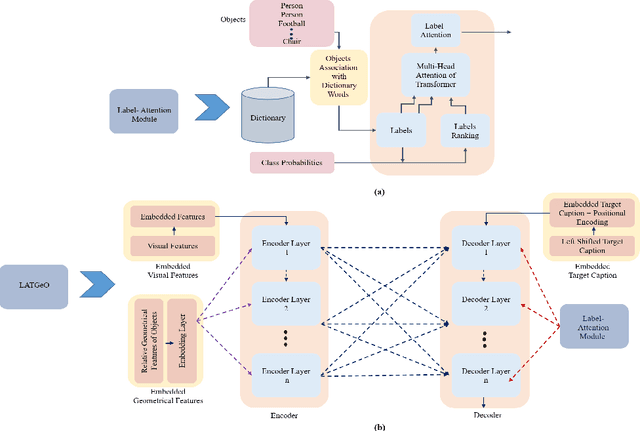
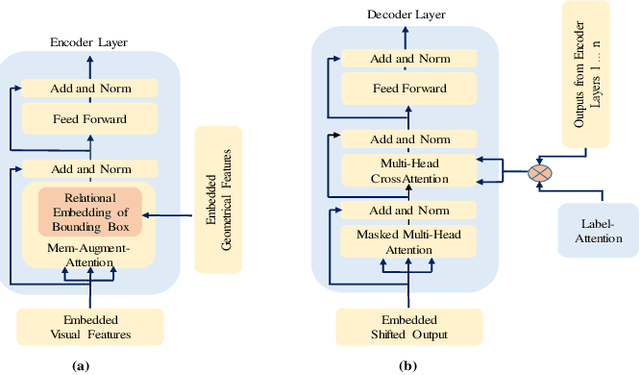
Automatic transcription of scene understanding in images and videos is a step towards artificial general intelligence. Image captioning is a nomenclature for describing meaningful information in an image using computer vision techniques. Automated image captioning techniques utilize encoder and decoder architecture, where the encoder extracts features from an image and the decoder generates a transcript. In this work, we investigate two unexplored ideas for image captioning using transformers: First, we demonstrate the enforcement of using objects' relevance in the surrounding environment. Second, learning an explicit association between labels and language constructs. We propose label-attention Transformer with geometrically coherent objects (LATGeO). The proposed technique acquires a proposal of geometrically coherent objects using a deep neural network (DNN) and generates captions by investigating their relationships using a label-attention module. Object coherence is defined using the localized ratio of the geometrical properties of the proposals. The label-attention module associates the extracted objects classes to the available dictionary using self-attention layers. The experimentation results show that objects' relevance in surroundings and binding of their visual feature with their geometrically localized ratios combined with its associated labels help in defining meaningful captions. The proposed framework is tested on the MSCOCO dataset, and a thorough evaluation resulting in overall better quantitative scores pronounces its superiority.
A Mathematical Approach to Constraining Neural Abstraction and the Mechanisms Needed to Scale to Higher-Order Cognition
Aug 12, 2021
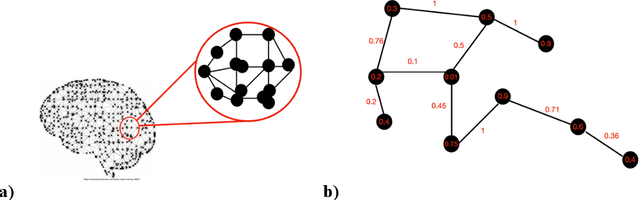

Artificial intelligence has made great strides in the last decade but still falls short of the human brain, the best-known example of intelligence. Not much is known of the neural processes that allow the brain to make the leap to achieve so much from so little beyond its ability to create knowledge structures that can be flexibly and dynamically combined, recombined, and applied in new and novel ways. This paper proposes a mathematical approach using graph theory and spectral graph theory, to hypothesize how to constrain these neural clusters of information based on eigen-relationships. This same hypothesis is hierarchically applied to scale up from the smallest to the largest clusters of knowledge that eventually lead to model building and reasoning.
InfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019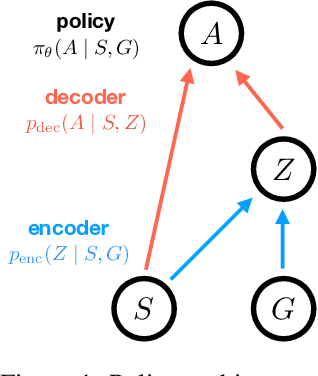



A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.