 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Investigating and Modeling the Dynamics of Long Ties
Sep 22, 2021
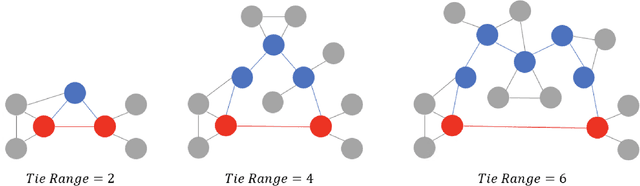
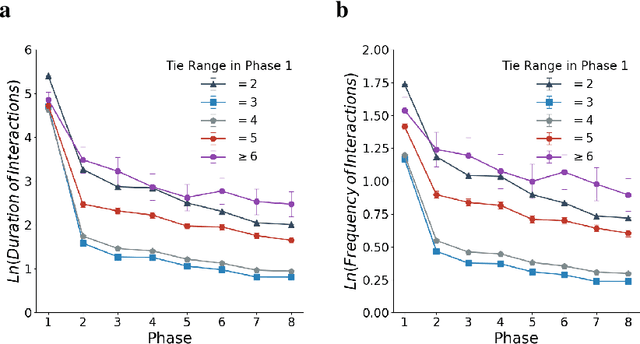
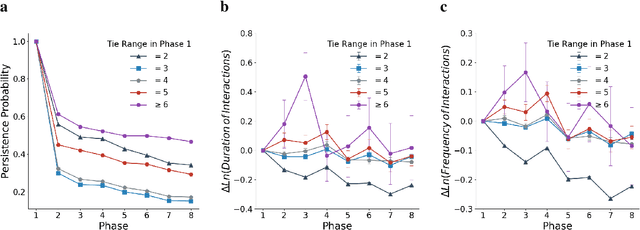
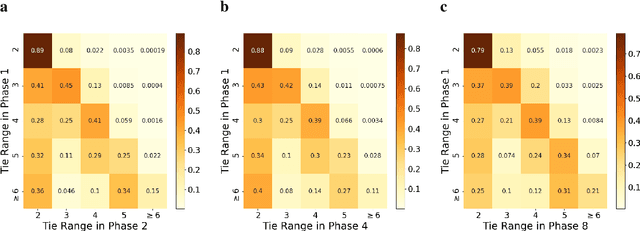
Long ties, the social ties that bridge different communities, are widely believed to play crucial roles in spreading novel information in social networks. However, some existing network theories and prediction models indicate that long ties might dissolve quickly or eventually become redundant, thus putting into question the long-term value of long ties. Our empirical analysis of real-world dynamic networks shows that contrary to such reasoning, long ties are more likely to persist than other social ties, and that many of them constantly function as social bridges without being embedded in local networks. Using a novel cost-benefit analysis model combined with machine learning, we show that long ties are highly beneficial, which instinctively motivates people to expend extra effort to maintain them. This partly explains why long ties are more persistent than what has been suggested by many existing theories and models. Overall, our study suggests the need for social interventions that can promote the formation of long ties, such as mixing people with diverse backgrounds.
Analyzing and Characterizing User Intent in Information-seeking Conversations
Apr 23, 2018

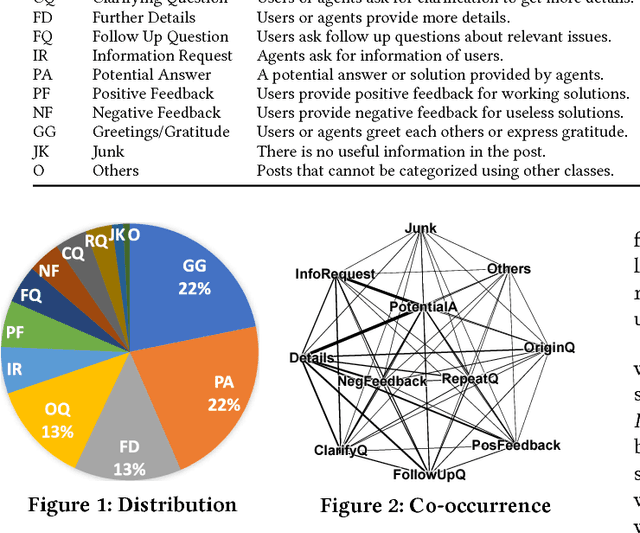
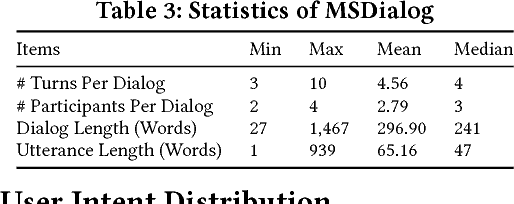
Understanding and characterizing how people interact in information-seeking conversations is crucial in developing conversational search systems. In this paper, we introduce a new dataset designed for this purpose and use it to analyze information-seeking conversations by user intent distribution, co-occurrence, and flow patterns. The MSDialog dataset is a labeled dialog dataset of question answering (QA) interactions between information seekers and providers from an online forum on Microsoft products. The dataset contains more than 2,000 multi-turn QA dialogs with 10,000 utterances that are annotated with user intent on the utterance level. Annotations were done using crowdsourcing. With MSDialog, we find some highly recurring patterns in user intent during an information-seeking process. They could be useful for designing conversational search systems. We will make our dataset freely available to encourage exploration of information-seeking conversation models.
A Feature Consistency Driven Attention Erasing Network for Fine-Grained Image Retrieval
Oct 09, 2021
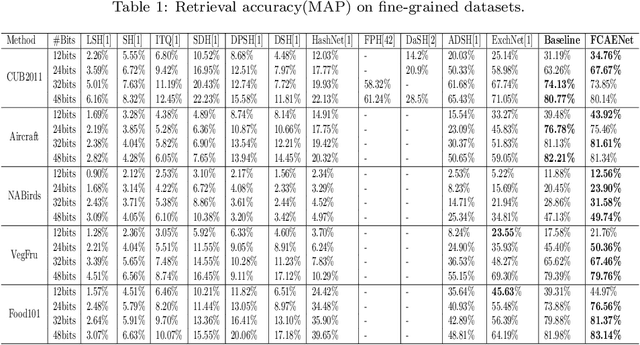
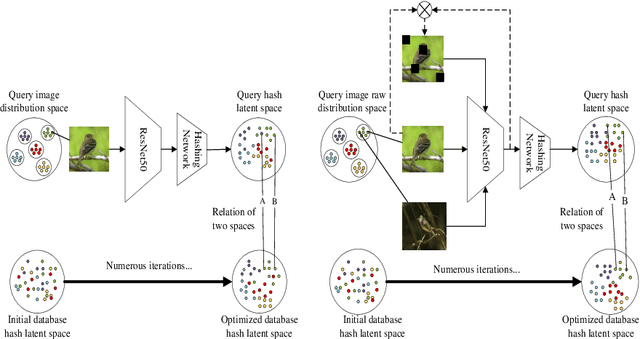
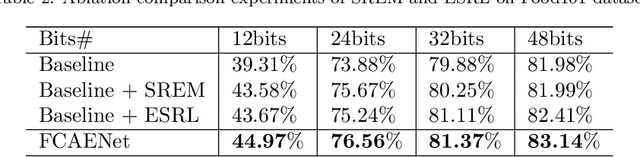
Large-scale fine-grained image retrieval has two main problems. First, low dimensional feature embedding can fasten the retrieval process but bring accuracy reduce due to overlooking the feature of significant attention regions of images in fine-grained datasets. Second, fine-grained images lead to the same category query hash codes mapping into the different cluster in database hash latent space. To handle these two issues, we propose a feature consistency driven attention erasing network (FCAENet) for fine-grained image retrieval. For the first issue, we propose an adaptive augmentation module in FCAENet, which is selective region erasing module (SREM). SREM makes the network more robust on subtle differences of fine-grained task by adaptively covering some regions of raw images. The feature extractor and hash layer can learn more representative hash code for fine-grained images by SREM. With regard to the second issue, we fully exploit the pair-wise similarity information and add the enhancing space relation loss (ESRL) in FCAENet to make the vulnerable relation stabler between the query hash code and database hash code. We conduct extensive experiments on five fine-grained benchmark datasets (CUB2011, Aircraft, NABirds, VegFru, Food101) for 12bits, 24bits, 32bits, 48bits hash code. The results show that FCAENet achieves the state-of-the-art (SOTA) fine-grained retrieval performance compared with other methods.
Exceeding the limits of algorithmic self-calibration in super-resolution imaging
Sep 15, 2021
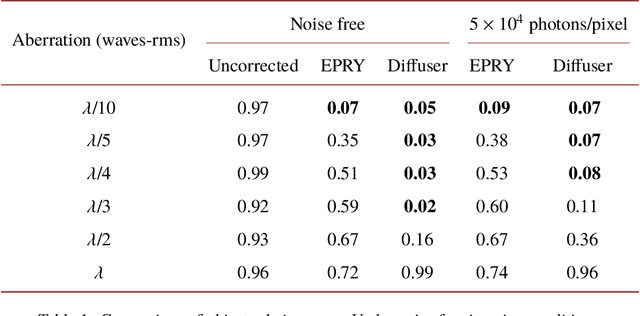
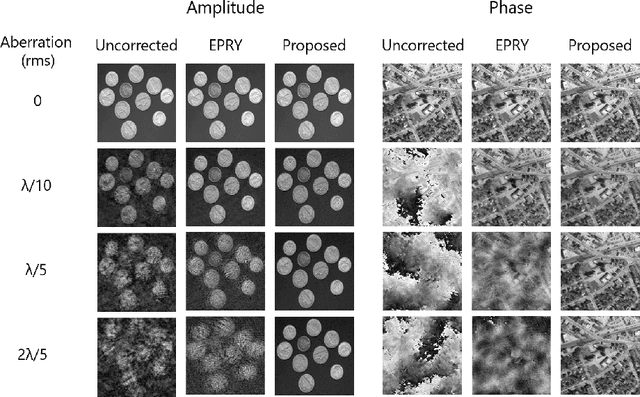
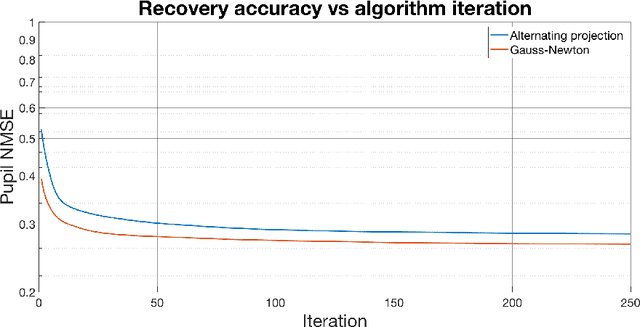
Fourier ptychographic microscopy is a computational imaging technique that provides quantitative phase information and high resolution over a large field-of-view. Although the technique presents numerous advantages over conventional microscopy, model mismatch due to unknown optical aberrations can significantly limit reconstruction quality. Many attempts to address this issue rely on embedding pupil recovery into the reconstruction algorithm. In this paper we demonstrate the limitations of a purely algorithmic approach and evaluate the merits of implementing a simple, dedicated calibration procedure. In simulations, we find that for a target sample reconstruction error, we can image without any aberration corrections up to a maximum aberration magnitude of $\lambda$/40. When we use algorithmic self-calibration, we can increase the aberration magnitude up to $\lambda$/10, and with our in situ speckle calibration technique, this working range is extended further to a maximum aberration magnitude of $\lambda$/3. Hence, one can trade-off complexity for accuracy by using a separate calibration process, which is particularly useful for larger aberrations.
Alzheimer's Dementia Recognition Using Acoustic, Lexical, Disfluency and Speech Pause Features Robust to Noisy Inputs
Jun 29, 2021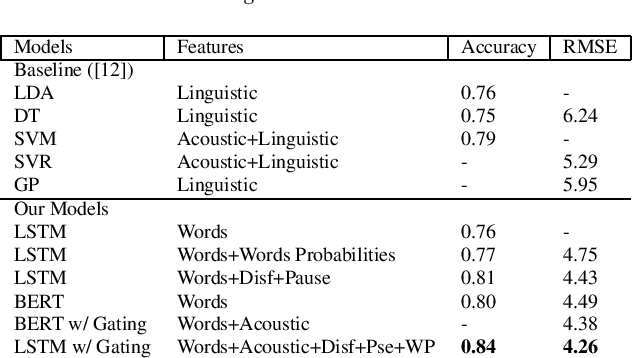

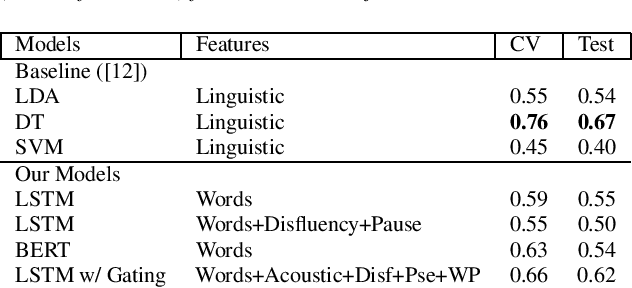
We present two multimodal fusion-based deep learning models that consume ASR transcribed speech and acoustic data simultaneously to classify whether a speaker in a structured diagnostic task has Alzheimer's Disease and to what degree, evaluating the ADReSSo challenge 2021 data. Our best model, a BiLSTM with highway layers using words, word probabilities, disfluency features, pause information, and a variety of acoustic features, achieves an accuracy of 84% and RSME error prediction of 4.26 on MMSE cognitive scores. While predicting cognitive decline is more challenging, our models show improvement using the multimodal approach and word probabilities, disfluency and pause information over word-only models. We show considerable gains for AD classification using multimodal fusion and gating, which can effectively deal with noisy inputs from acoustic features and ASR hypotheses.
Discovering Latent Information By Spreading Activation Algorithm For Document Retrieval
Jul 29, 2018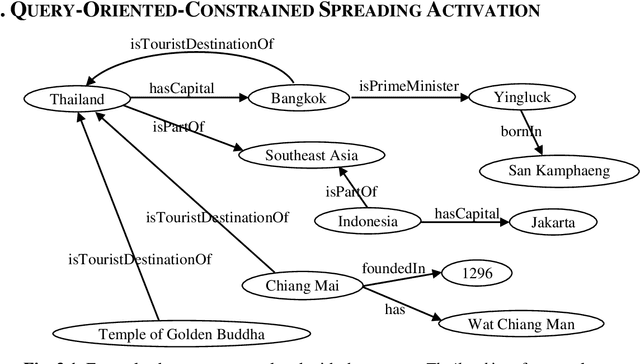
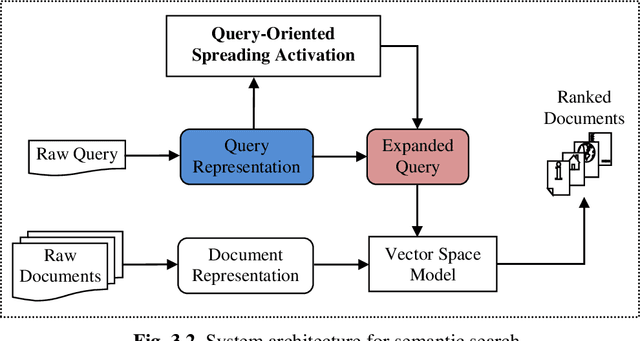
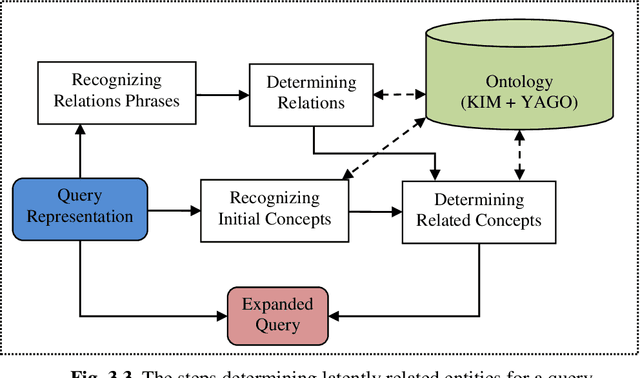
Syntactic search relies on keywords contained in a query to find suitable documents. So, documents that do not contain the keywords but contain information related to the query are not retrieved. Spreading activation is an algorithm for finding latent information in a query by exploiting relations between nodes in an associative network or semantic network. However, the classical spreading activation algorithm uses all relations of a node in the network that will add unsuitable information into the query. In this paper, we propose a novel approach for semantic text search, called query-oriented-constrained spreading activation that only uses relations relating to the content of the query to find really related information. Experiments on a benchmark dataset show that, in terms of the MAP measure, our search engine is 18.9% and 43.8% respectively better than the syntactic search and the search using the classical constrained spreading activation. KEYWORDS: Information Retrieval, Ontology, Semantic Search, Spreading Activation
Disentangling Online Chats with DAG-Structured LSTMs
Jun 16, 2021
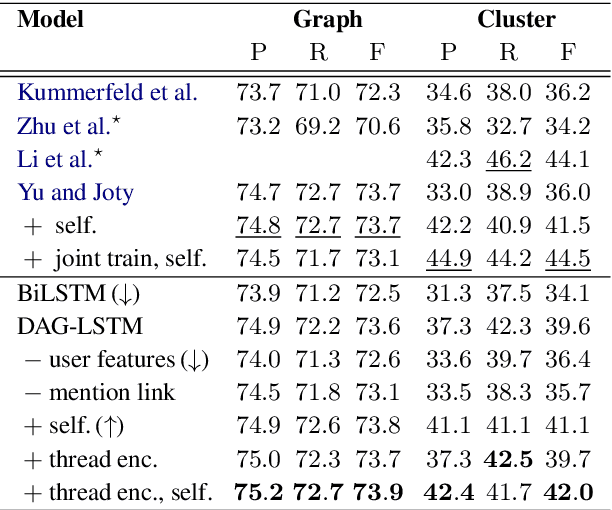
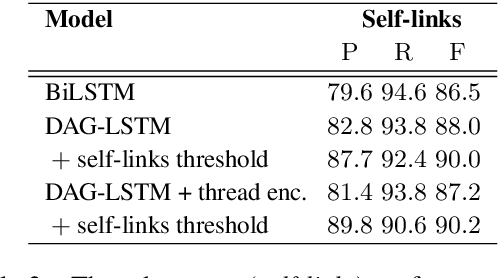

Many modern messaging systems allow fast and synchronous textual communication among many users. The resulting sequence of messages hides a more complicated structure in which independent sub-conversations are interwoven with one another. This poses a challenge for any task aiming to understand the content of the chat logs or gather information from them. The ability to disentangle these conversations is then tantamount to the success of many downstream tasks such as summarization and question answering. Structured information accompanying the text such as user turn, user mentions, timestamps, is used as a cue by the participants themselves who need to follow the conversation and has been shown to be important for disentanglement. DAG-LSTMs, a generalization of Tree-LSTMs that can handle directed acyclic dependencies, are a natural way to incorporate such information and its non-sequential nature. In this paper, we apply DAG-LSTMs to the conversation disentanglement task. We perform our experiments on the Ubuntu IRC dataset. We show that the novel model we propose achieves state of the art status on the task of recovering reply-to relations and it is competitive on other disentanglement metrics.
Beyond Glass-Box Features: Uncertainty Quantification Enhanced Quality Estimation for Neural Machine Translation
Sep 15, 2021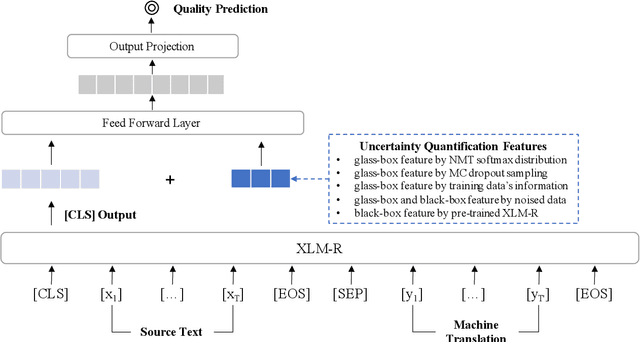
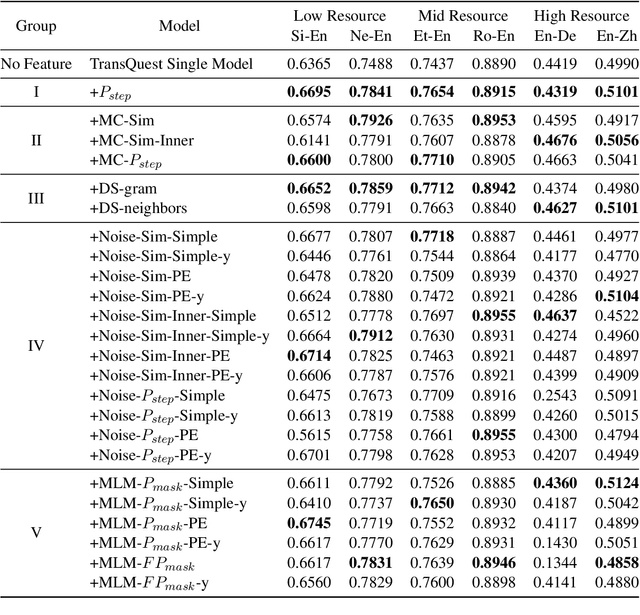
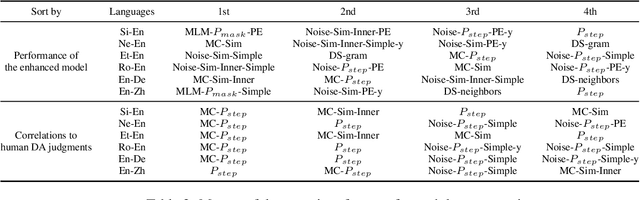
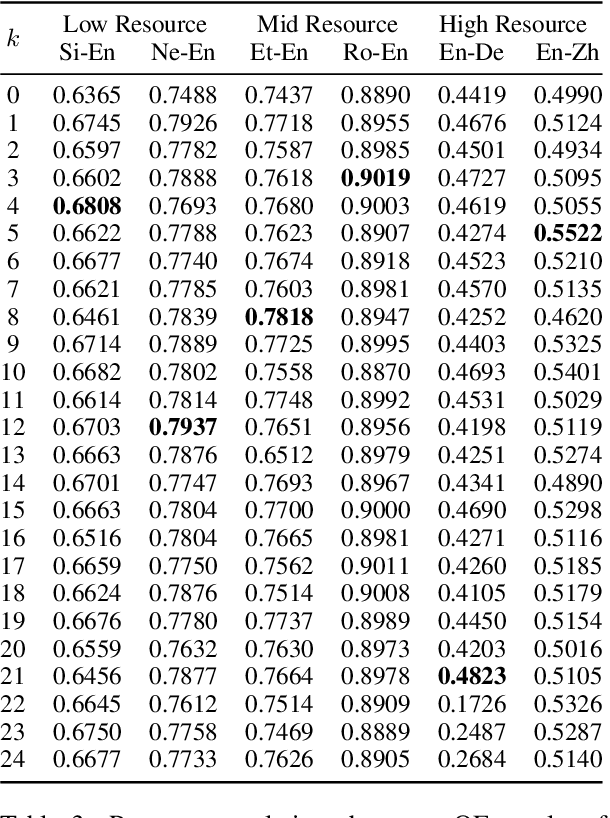
Quality Estimation (QE) plays an essential role in applications of Machine Translation (MT). Traditionally, a QE system accepts the original source text and translation from a black-box MT system as input. Recently, a few studies indicate that as a by-product of translation, QE benefits from the model and training data's information of the MT system where the translations come from, and it is called the "glass-box QE". In this paper, we extend the definition of "glass-box QE" generally to uncertainty quantification with both "black-box" and "glass-box" approaches and design several features deduced from them to blaze a new trial in improving QE's performance. We propose a framework to fuse the feature engineering of uncertainty quantification into a pre-trained cross-lingual language model to predict the translation quality. Experiment results show that our method achieves state-of-the-art performances on the datasets of WMT 2020 QE shared task.
LegaLMFiT: Efficient Short Legal Text Classification with LSTM Language Model Pre-Training
Sep 15, 2021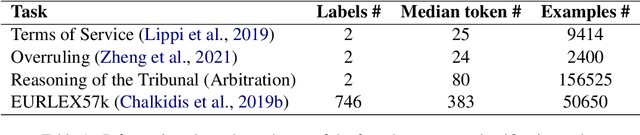
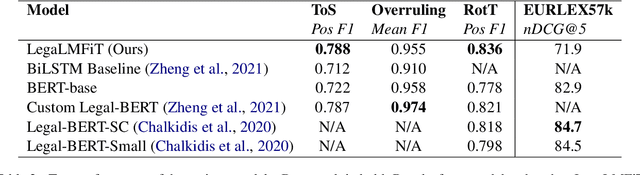
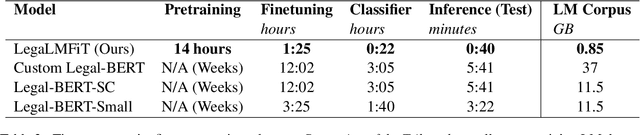
Large Transformer-based language models such as BERT have led to broad performance improvements on many NLP tasks. Domain-specific variants of these models have demonstrated excellent performance on a variety of specialised tasks. In legal NLP, BERT-based models have led to new state-of-the-art results on multiple tasks. The exploration of these models has demonstrated the importance of capturing the specificity of the legal language and its vocabulary. However, such approaches suffer from high computational costs, leading to a higher ecological impact and lower accessibility. Our findings, focusing on English language legal text, show that lightweight LSTM-based Language Models are able to capture enough information from a small legal text pretraining corpus and achieve excellent performance on short legal text classification tasks. This is achieved with a significantly reduced computational overhead compared to BERT-based models. However, our method also shows degraded performance on a more complex task, multi-label classification of longer documents, highlighting the limitations of this lightweight approach.
TL-SDD: A Transfer Learning-Based Method for Surface Defect Detection with Few Samples
Aug 16, 2021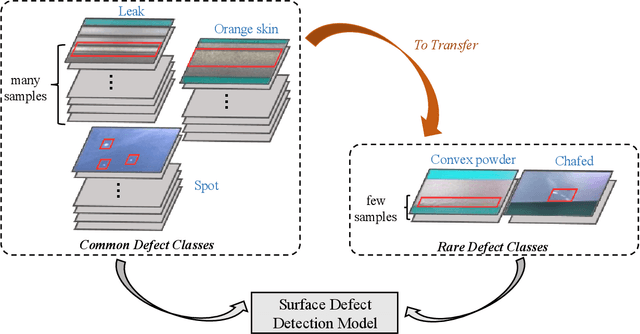
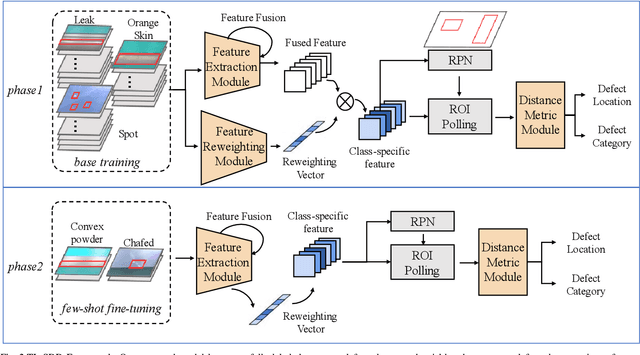
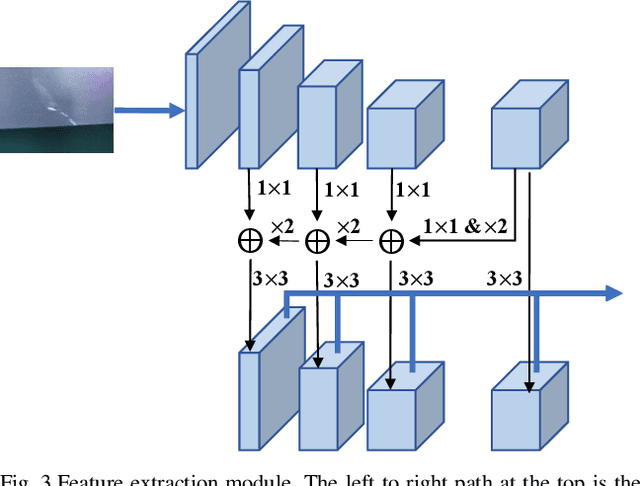
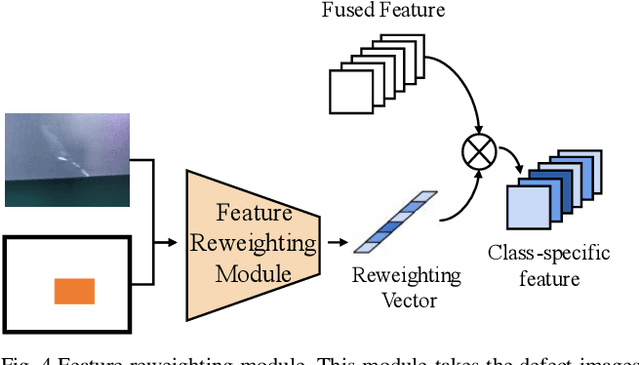
Surface defect detection plays an increasingly important role in manufacturing industry to guarantee the product quality. Many deep learning methods have been widely used in surface defect detection tasks, and have been proven to perform well in defects classification and location. However, deep learning-based detection methods often require plenty of data for training, which fail to apply to the real industrial scenarios since the distribution of defect categories is often imbalanced. In other words, common defect classes have many samples but rare defect classes have extremely few samples, and it is difficult for these methods to well detect rare defect classes. To solve the imbalanced distribution problem, in this paper we propose TL-SDD: a novel Transfer Learning-based method for Surface Defect Detection. First, we adopt a two-phase training scheme to transfer the knowledge from common defect classes to rare defect classes. Second, we propose a novel Metric-based Surface Defect Detection (M-SDD) model. We design three modules for this model: (1) feature extraction module: containing feature fusion which combines high-level semantic information with low-level structural information. (2) feature reweighting module: transforming examples to a reweighting vector that indicates the importance of features. (3) distance metric module: learning a metric space in which defects are classified by computing distances to representations of each category. Finally, we validate the performance of our proposed method on a real dataset including surface defects of aluminum profiles. Compared to the baseline methods, the performance of our proposed method has improved by up to 11.98% for rare defect classes.