 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Model Reduction using WeldNet: Windowed Encoders for Learning Dynamics
Dec 11, 2025Many problems in science and engineering involve time-dependent, high dimensional datasets arising from complex physical processes, which are costly to simulate. In this work, we propose WeldNet: Windowed Encoders for Learning Dynamics, a data-driven nonlinear model reduction framework to build a low-dimensional surrogate model for complex evolution systems. Given time-dependent training data, we split the time domain into multiple overlapping windows, within which nonlinear dimension reduction is performed by auto-encoders to capture latent codes. Once a low-dimensional representation of the data is learned, a propagator network is trained to capture the evolution of the latent codes in each window, and a transcoder is trained to connect the latent codes between adjacent windows. The proposed windowed decomposition significantly simplifies propagator training by breaking long-horizon dynamics into multiple short, manageable segments, while the transcoders ensure consistency across windows. In addition to the algorithmic framework, we develop a mathematical theory establishing the representation power of WeldNet under the manifold hypothesis, justifying the success of nonlinear model reduction via deep autoencoder-based architectures. Our numerical experiments on various differential equations indicate that WeldNet can capture nonlinear latent structures and their underlying dynamics, outperforming both traditional projection-based approaches and recently developed nonlinear model reduction methods.
Deep Neural Networks are Adaptive to Function Regularity and Data Distribution in Approximation and Estimation
Jun 08, 2024



Deep learning has exhibited remarkable results across diverse areas. To understand its success, substantial research has been directed towards its theoretical foundations. Nevertheless, the majority of these studies examine how well deep neural networks can model functions with uniform regularity. In this paper, we explore a different angle: how deep neural networks can adapt to different regularity in functions across different locations and scales and nonuniform data distributions. More precisely, we focus on a broad class of functions defined by nonlinear tree-based approximation. This class encompasses a range of function types, such as functions with uniform regularity and discontinuous functions. We develop nonparametric approximation and estimation theories for this function class using deep ReLU networks. Our results show that deep neural networks are adaptive to different regularity of functions and nonuniform data distributions at different locations and scales. We apply our results to several function classes, and derive the corresponding approximation and generalization errors. The validity of our results is demonstrated through numerical experiments.
High Dimensional Binary Classification under Label Shift: Phase Transition and Regularization
Dec 08, 2022Label Shift has been widely believed to be harmful to the generalization performance of machine learning models. Researchers have proposed many approaches to mitigate the impact of the label shift, e.g., balancing the training data. However, these methods often consider the underparametrized regime, where the sample size is much larger than the data dimension. The research under the overparametrized regime is very limited. To bridge this gap, we propose a new asymptotic analysis of the Fisher Linear Discriminant classifier for binary classification with label shift. Specifically, we prove that there exists a phase transition phenomenon: Under certain overparametrized regime, the classifier trained using imbalanced data outperforms the counterpart with reduced balanced data. Moreover, we investigate the impact of regularization to the label shift: The aforementioned phase transition vanishes as the regularization becomes strong.
TL-SDD: A Transfer Learning-Based Method for Surface Defect Detection with Few Samples
Aug 16, 2021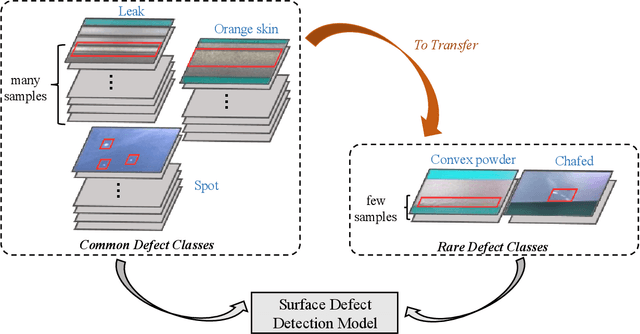
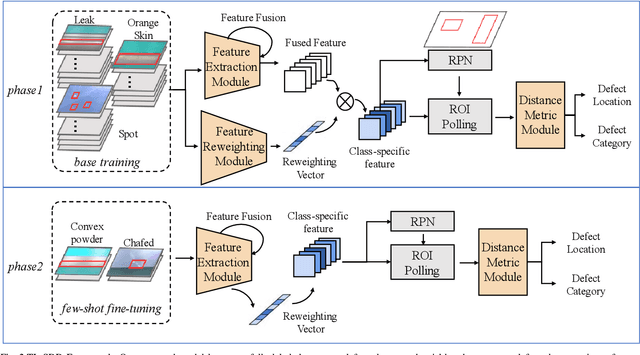
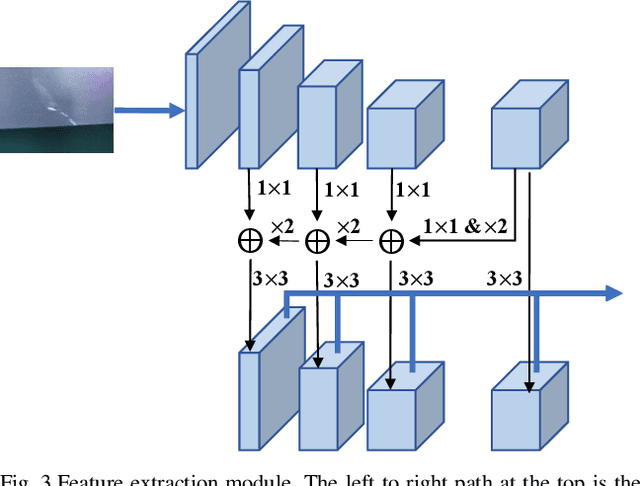
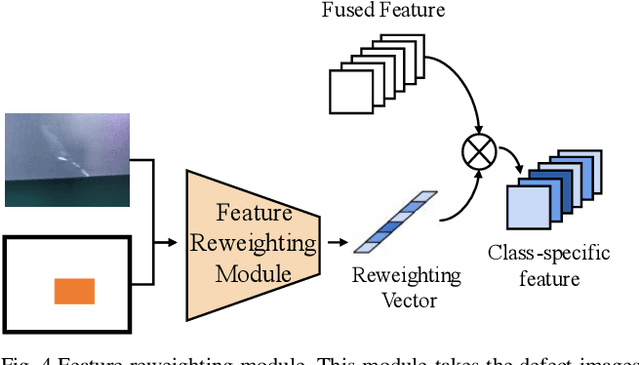
Surface defect detection plays an increasingly important role in manufacturing industry to guarantee the product quality. Many deep learning methods have been widely used in surface defect detection tasks, and have been proven to perform well in defects classification and location. However, deep learning-based detection methods often require plenty of data for training, which fail to apply to the real industrial scenarios since the distribution of defect categories is often imbalanced. In other words, common defect classes have many samples but rare defect classes have extremely few samples, and it is difficult for these methods to well detect rare defect classes. To solve the imbalanced distribution problem, in this paper we propose TL-SDD: a novel Transfer Learning-based method for Surface Defect Detection. First, we adopt a two-phase training scheme to transfer the knowledge from common defect classes to rare defect classes. Second, we propose a novel Metric-based Surface Defect Detection (M-SDD) model. We design three modules for this model: (1) feature extraction module: containing feature fusion which combines high-level semantic information with low-level structural information. (2) feature reweighting module: transforming examples to a reweighting vector that indicates the importance of features. (3) distance metric module: learning a metric space in which defects are classified by computing distances to representations of each category. Finally, we validate the performance of our proposed method on a real dataset including surface defects of aluminum profiles. Compared to the baseline methods, the performance of our proposed method has improved by up to 11.98% for rare defect classes.