 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Interaction Fluidity in a Wizard-of-Oz Robotic System: A Prototype for Fluid Error-Correction
Apr 21, 2026Achieving truly fluid interaction with robots with speech interfaces remains a hard problem, and the experience of current Human-Robot Interaction (HRI) remains laboured and frustrating. Some of the barriers to fluid interaction stem from a lack of a suitable development platform for HRI for improving interaction, even in robotic Wizard-of-Oz (WoZ) modes of operation used for data collection and prototyping. Based on previous systems, we propose the properties of interruptibility and correction (IaC), pollability, latency measurement and optimisation and time-accurate reproducibility of actions from logging data as key criteria for a fluid WoZ system to support fluid error correction. We finish by presenting a Virtual Reality (VR) HRI simulation environment for mobile manipulators which meets these criteria.
An Exploration-Analysis-Disambiguation Reasoning Framework for Word Sense Disambiguation with Low-Parameter LLMs
Mar 05, 2026Word Sense Disambiguation (WSD) remains a key challenge in Natural Language Processing (NLP), especially when dealing with rare or domain-specific senses that are often misinterpreted. While modern high-parameter Large Language Models (LLMs) such as GPT-4-Turbo have shown state-of-the-art WSD performance, their computational and energy demands limit scalability. This study investigates whether low-parameter LLMs (<4B parameters) can achieve comparable results through fine-tuning strategies that emphasize reasoning-driven sense identification. Using the FEWS dataset augmented with semi-automated, rationale-rich annotations, we fine-tune eight small-scale open-source LLMs (e.g. Gemma and Qwen). Our results reveal that Chain-of-Thought (CoT)-based reasoning combined with neighbour-word analysis achieves performance comparable to GPT-4-Turbo in zero-shot settings. Importantly, Gemma-3-4B and Qwen-3-4B models consistently outperform all medium-parameter baselines and state-of-the-art models on FEWS, with robust generalization to unseen senses. Furthermore, evaluation on the unseen "Fool Me If You Can'' dataset confirms strong cross-domain adaptability without task-specific fine-tuning. This work demonstrates that with carefully crafted reasoning-centric fine-tuning, low-parameter LLMs can deliver accurate WSD while substantially reducing computational and energy demands.
IndoNLP 2025: Shared Task on Real-Time Reverse Transliteration for Romanized Indo-Aryan languages
Jan 15, 2025



The paper overviews the shared task on Real-Time Reverse Transliteration for Romanized Indo-Aryan languages. It focuses on the reverse transliteration of low-resourced languages in the Indo-Aryan family to their native scripts. Typing Romanized Indo-Aryan languages using ad-hoc transliterals and achieving accurate native scripts are complex and often inaccurate processes with the current keyboard systems. This task aims to introduce and evaluate a real-time reverse transliterator that converts Romanized Indo-Aryan languages to their native scripts, improving the typing experience for users. Out of 11 registered teams, four teams participated in the final evaluation phase with transliteration models for Sinhala, Hindi and Malayalam. These proposed solutions not only solve the issue of ad-hoc transliteration but also empower low-resource language usability in the digital arena.
Can LLMs assist with Ambiguity? A Quantitative Evaluation of various Large Language Models on Word Sense Disambiguation
Nov 27, 2024



Ambiguous words are often found in modern digital communications. Lexical ambiguity challenges traditional Word Sense Disambiguation (WSD) methods, due to limited data. Consequently, the efficiency of translation, information retrieval, and question-answering systems is hindered by these limitations. This study investigates the use of Large Language Models (LLMs) to improve WSD using a novel approach combining a systematic prompt augmentation mechanism with a knowledge base (KB) consisting of different sense interpretations. The proposed method incorporates a human-in-loop approach for prompt augmentation where prompt is supported by Part-of-Speech (POS) tagging, synonyms of ambiguous words, aspect-based sense filtering and few-shot prompting to guide the LLM. By utilizing a few-shot Chain of Thought (COT) prompting-based approach, this work demonstrates a substantial improvement in performance. The evaluation was conducted using FEWS test data and sense tags. This research advances accurate word interpretation in social media and digital communication.
Alzheimer's Dementia Recognition Using Acoustic, Lexical, Disfluency and Speech Pause Features Robust to Noisy Inputs
Jun 29, 2021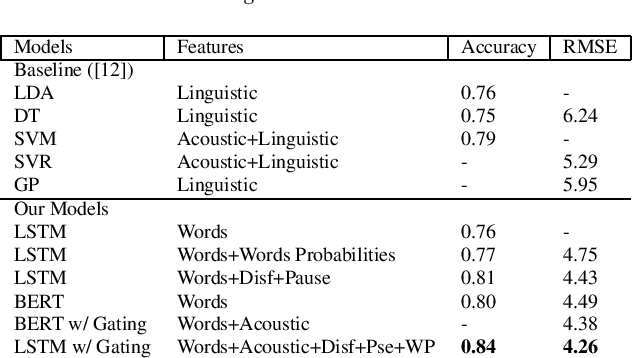

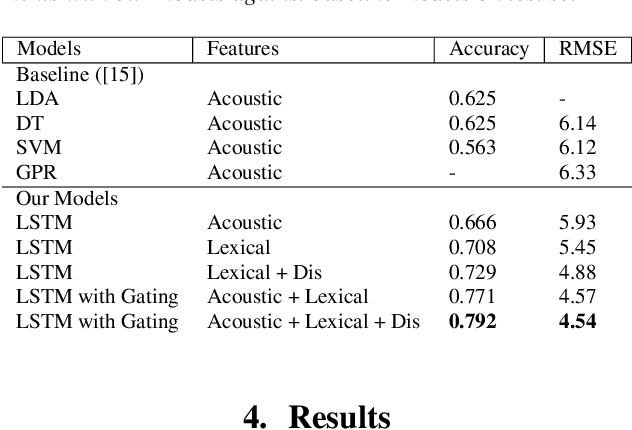
We present two multimodal fusion-based deep learning models that consume ASR transcribed speech and acoustic data simultaneously to classify whether a speaker in a structured diagnostic task has Alzheimer's Disease and to what degree, evaluating the ADReSSo challenge 2021 data. Our best model, a BiLSTM with highway layers using words, word probabilities, disfluency features, pause information, and a variety of acoustic features, achieves an accuracy of 84% and RSME error prediction of 4.26 on MMSE cognitive scores. While predicting cognitive decline is more challenging, our models show improvement using the multimodal approach and word probabilities, disfluency and pause information over word-only models. We show considerable gains for AD classification using multimodal fusion and gating, which can effectively deal with noisy inputs from acoustic features and ASR hypotheses.
Multi-modal fusion with gating using audio, lexical and disfluency features for Alzheimer's Dementia recognition from spontaneous speech
Jun 17, 2021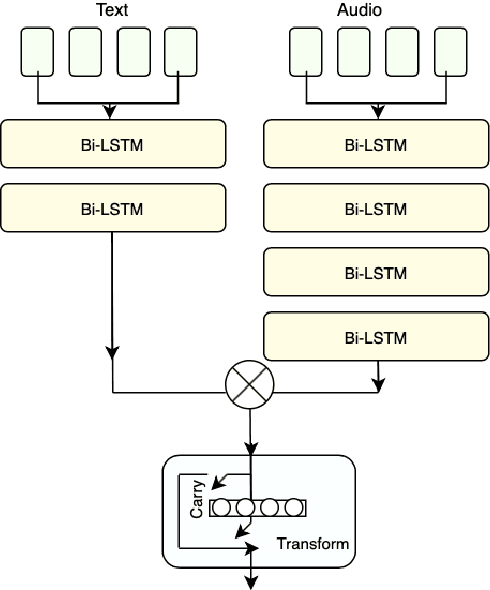

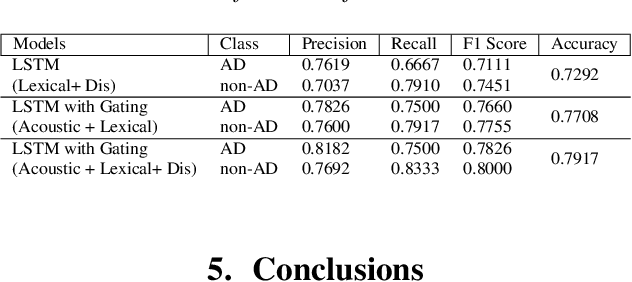
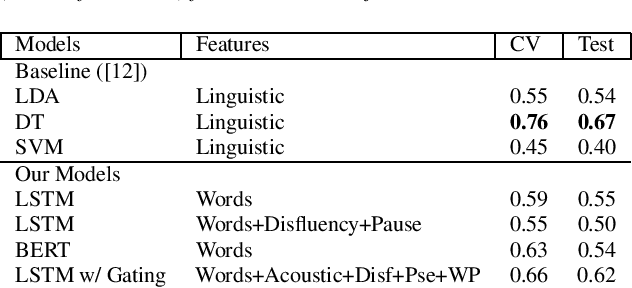
This paper is a submission to the Alzheimer's Dementia Recognition through Spontaneous Speech (ADReSS) challenge, which aims to develop methods that can assist in the automated prediction of severity of Alzheimer's Disease from speech data. We focus on acoustic and natural language features for cognitive impairment detection in spontaneous speech in the context of Alzheimer's Disease Diagnosis and the mini-mental state examination (MMSE) score prediction. We proposed a model that obtains unimodal decisions from different LSTMs, one for each modality of text and audio, and then combines them using a gating mechanism for the final prediction. We focused on sequential modelling of text and audio and investigated whether the disfluencies present in individuals' speech relate to the extent of their cognitive impairment. Our results show that the proposed classification and regression schemes obtain very promising results on both development and test sets. This suggests Alzheimer's Disease can be detected successfully with sequence modeling of the speech data of medical sessions.
Re-framing Incremental Deep Language Models for Dialogue Processing with Multi-task Learning
Nov 13, 2020
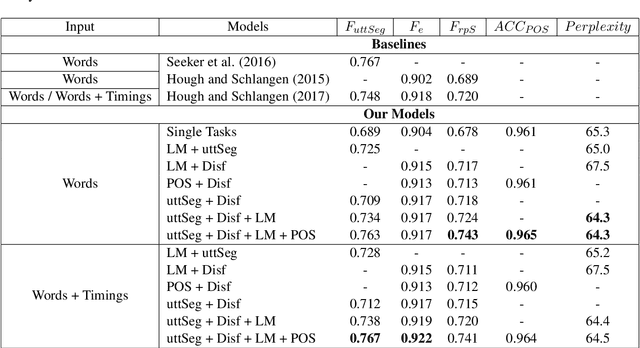
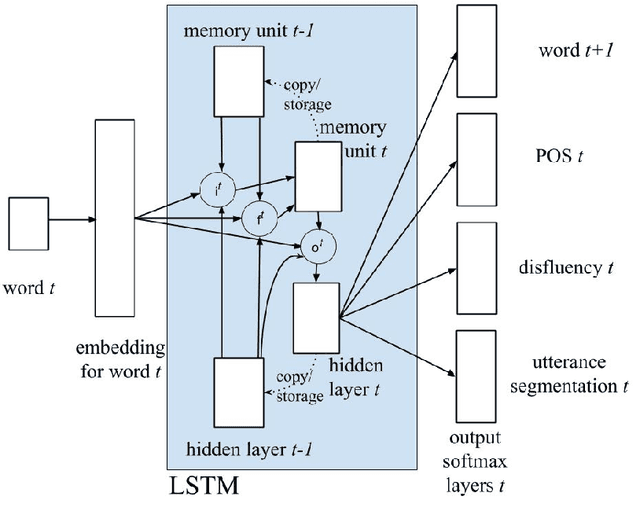
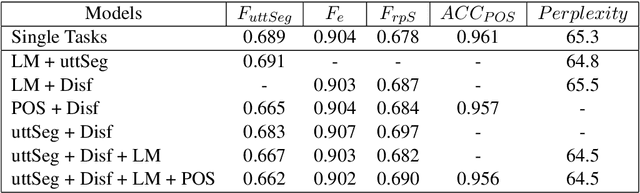
We present a multi-task learning framework to enable the training of one universal incremental dialogue processing model with four tasks of disfluency detection, language modelling, part-of-speech tagging, and utterance segmentation in a simple deep recurrent setting. We show that these tasks provide positive inductive biases to each other with the optimal contribution of each one relying on the severity of the noise from the task. Our live multi-task model outperforms similar individual tasks, delivers competitive performance, and is beneficial for future use in conversational agents in psychiatric treatment.
Exploring Semantic Incrementality with Dynamic Syntax and Vector Space Semantics
Nov 01, 2018

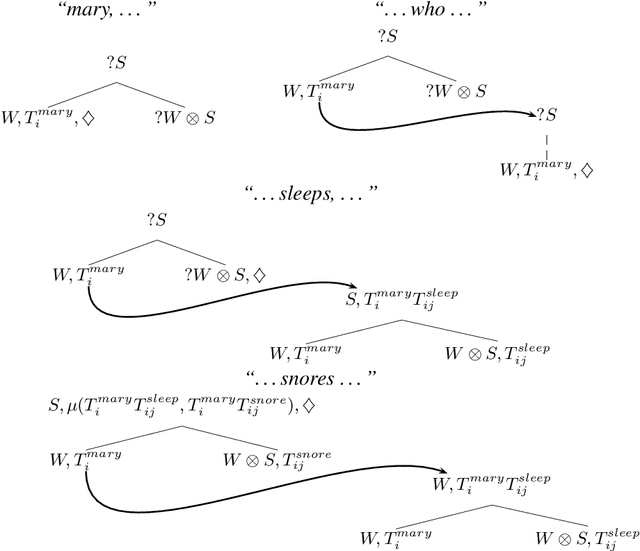
One of the fundamental requirements for models of semantic processing in dialogue is incrementality: a model must reflect how people interpret and generate language at least on a word-by-word basis, and handle phenomena such as fragments, incomplete and jointly-produced utterances. We show that the incremental word-by-word parsing process of Dynamic Syntax (DS) can be assigned a compositional distributional semantics, with the composition operator of DS corresponding to the general operation of tensor contraction from multilinear algebra. We provide abstract semantic decorations for the nodes of DS trees, in terms of vectors, tensors, and sums thereof; using the latter to model the underspecified elements crucial to assigning partial representations during incremental processing. As a working example, we give an instantiation of this theory using plausibility tensors of compositional distributional semantics, and show how our framework can incrementally assign a semantic plausibility measure as it parses phrases and sentences.
Strongly Incremental Repair Detection
Aug 29, 2014
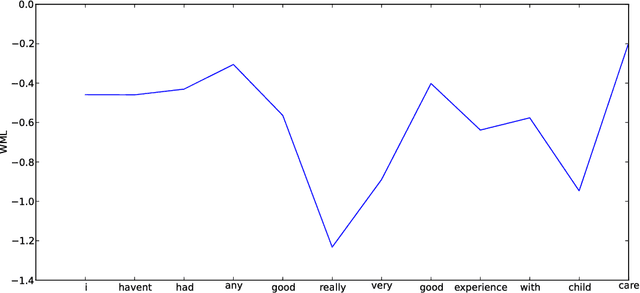
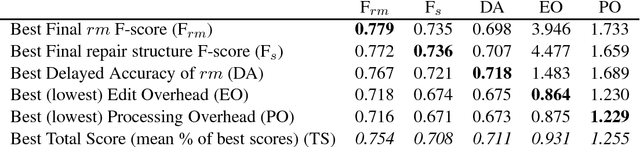
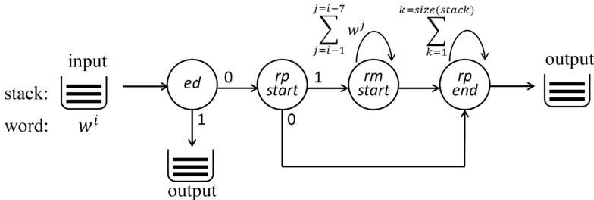
We present STIR (STrongly Incremental Repair detection), a system that detects speech repairs and edit terms on transcripts incrementally with minimal latency. STIR uses information-theoretic measures from n-gram models as its principal decision features in a pipeline of classifiers detecting the different stages of repairs. Results on the Switchboard disfluency tagged corpus show utterance-final accuracy on a par with state-of-the-art incremental repair detection methods, but with better incremental accuracy, faster time-to-detection and less computational overhead. We evaluate its performance using incremental metrics and propose new repair processing evaluation standards.