 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An artificial neural network approach to bifurcating phenomena in computational fluid dynamics
Sep 22, 2021


This work deals with the investigation of bifurcating fluid phenomena using a reduced order modelling setting aided by artificial neural networks. We discuss the POD-NN approach dealing with non-smooth solutions set of nonlinear parametrized PDEs. Thus, we study the Navier-Stokes equations describing: (i) the Coanda effect in a channel, and (ii) the lid driven triangular cavity flow, in a physical/geometrical multi-parametrized setting, considering the effects of the domain's configuration on the position of the bifurcation points. Finally, we propose a reduced manifold-based bifurcation diagram for a non-intrusive recovery of the critical points evolution. Exploiting such detection tool, we are able to efficiently obtain information about the pattern flow behaviour, from symmetry breaking profiles to attaching/spreading vortices, even at high Reynolds numbers.
Simplifying approach to Node Classification in Graph Neural Networks
Nov 12, 2021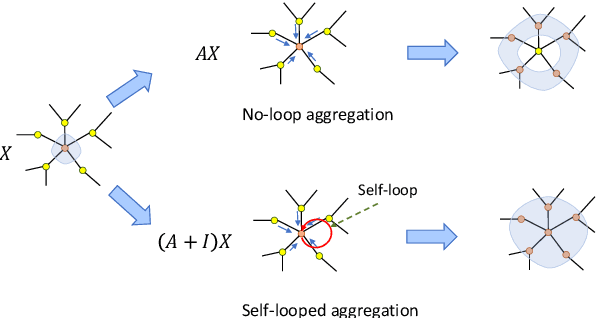
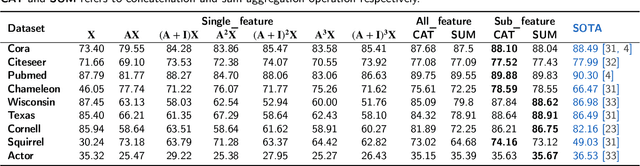
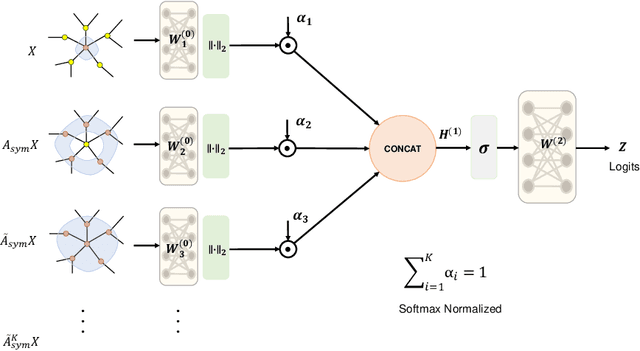
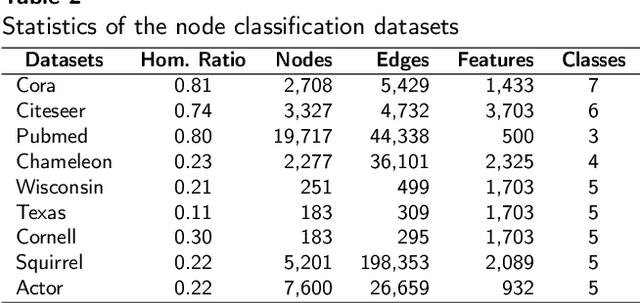
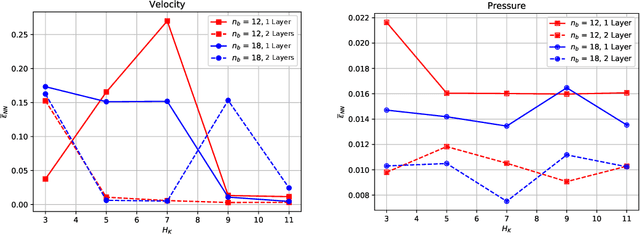
Graph Neural Networks have become one of the indispensable tools to learn from graph-structured data, and their usefulness has been shown in wide variety of tasks. In recent years, there have been tremendous improvements in architecture design, resulting in better performance on various prediction tasks. In general, these neural architectures combine node feature aggregation and feature transformation using learnable weight matrix in the same layer. This makes it challenging to analyze the importance of node features aggregated from various hops and the expressiveness of the neural network layers. As different graph datasets show varying levels of homophily and heterophily in features and class label distribution, it becomes essential to understand which features are important for the prediction tasks without any prior information. In this work, we decouple the node feature aggregation step and depth of graph neural network, and empirically analyze how different aggregated features play a role in prediction performance. We show that not all features generated via aggregation steps are useful, and often using these less informative features can be detrimental to the performance of the GNN model. Through our experiments, we show that learning certain subsets of these features can lead to better performance on wide variety of datasets. We propose to use softmax as a regularizer and "soft-selector" of features aggregated from neighbors at different hop distances; and L2-Normalization over GNN layers. Combining these techniques, we present a simple and shallow model, Feature Selection Graph Neural Network (FSGNN), and show empirically that the proposed model achieves comparable or even higher accuracy than state-of-the-art GNN models in nine benchmark datasets for the node classification task, with remarkable improvements up to 51.1%.
Two-Timescale End-to-End Learning for Channel Acquisition and Hybrid Precoding
Oct 26, 2021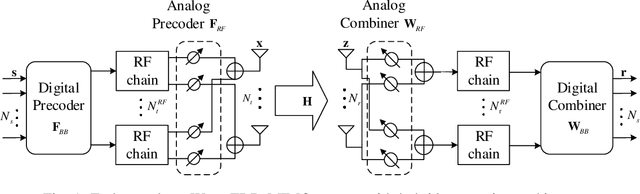

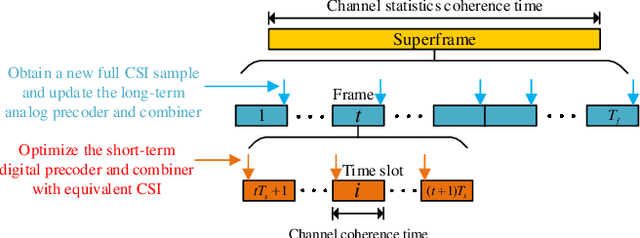
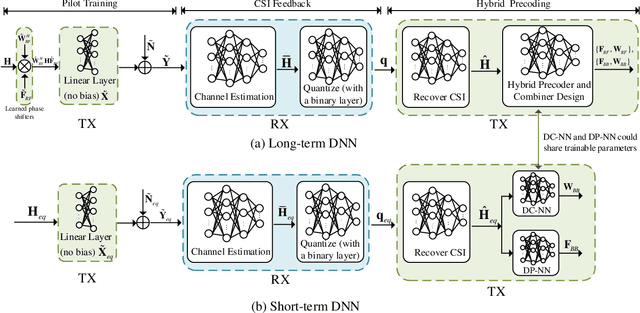
In this paper, we propose an end-to-end deep learning-based joint transceiver design algorithm for millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems, which consists of deep neural network (DNN)-aided pilot training, channel feedback, and hybrid analog-digital (HAD) precoding. Specifically, we develop a DNN architecture that maps the received pilots into feedback bits at the receiver, and then further maps the feedback bits into the hybrid precoder at the transmitter. To reduce the signaling overhead and channel state information (CSI) mismatch caused by the transmission delay, a two-timescale DNN composed of a long-term DNN and a short-term DNN is developed. The analog precoders are designed by the long-term DNN based on the CSI statistics and updated once in a frame consisting of a number of time slots. In contrast, the digital precoders are optimized by the short-term DNN at each time slot based on the estimated low-dimensional equivalent CSI matrices. A two-timescale training method is also developed for the proposed DNN with a binary layer. We then analyze the generalization ability and signaling overhead for the proposed DNN based algorithm. Simulation results show that our proposed technique significantly outperforms conventional schemes in terms of bit-error rate performance with reduced signaling overhead and shorter pilot sequences.
A Visual Technique to Analyze Flow of Information in a Machine Learning System
Aug 02, 2019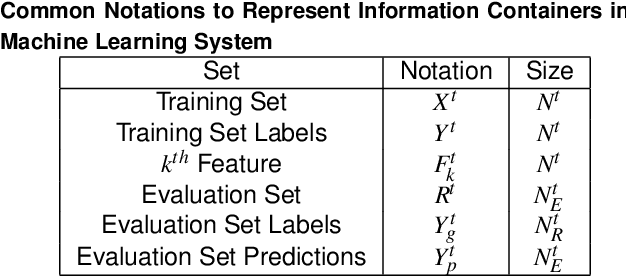

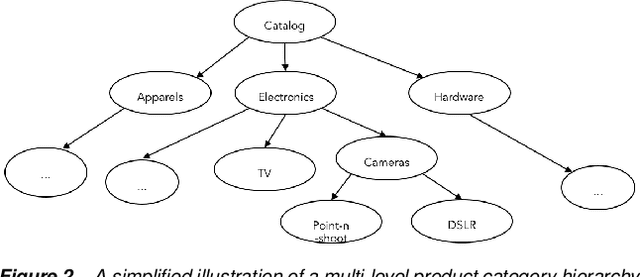
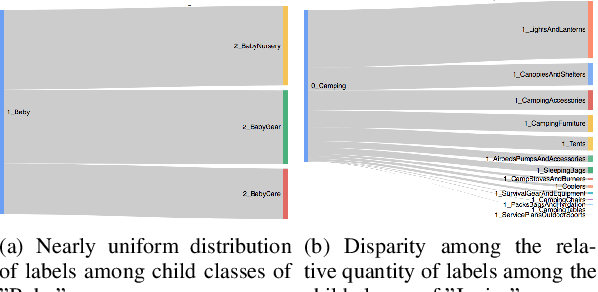
Machine learning (ML) algorithms and machine learning based software systems implicitly or explicitly involve complex flow of information between various entities such as training data, feature space, validation set and results. Understanding the statistical distribution of such information and how they flow from one entity to another influence the operation and correctness of such systems, especially in large-scale applications that perform classification or prediction in real time. In this paper, we propose a visual approach to understand and analyze flow of information during model training and serving phases. We build the visualizations using a technique called Sankey Diagram - conventionally used to understand data flow among sets - to address various use cases of in a machine learning system. We demonstrate how the proposed technique, tweaked and twisted to suit a classification problem, can play a critical role in better understanding of the training data, the features, and the classifier performance. We also discuss how this technique enables diagnostic analysis of model predictions and comparative analysis of predictions from multiple classifiers. The proposed concept is illustrated with the example of categorization of millions of products in the e-commerce domain - a multi-class hierarchical classification problem.
Feature Recommendation for Structural Equation Model Discovery in Process Mining
Aug 13, 2021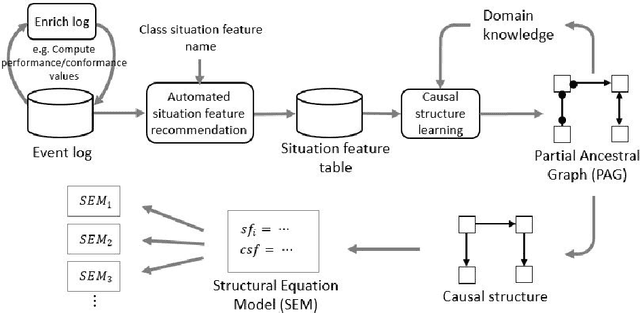
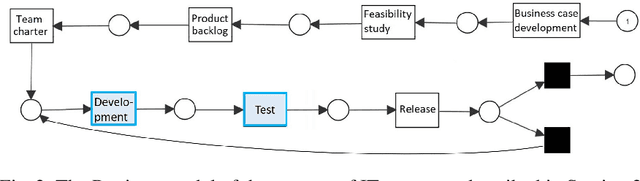
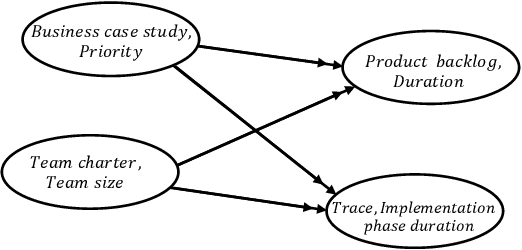
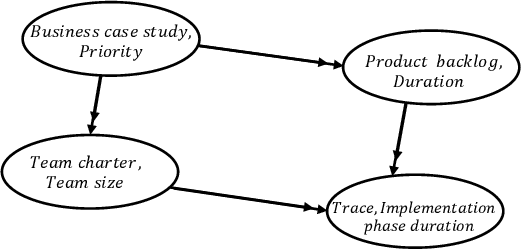
Process mining techniques can help organizations to improve their operational processes. Organizations can benefit from process mining techniques in finding and amending the root causes of performance or compliance problems. Considering the volume of the data and the number of features captured by the information system of today's companies, the task of discovering the set of features that should be considered in root cause analysis can be quite involving. In this paper, we propose a method for finding the set of (aggregated) features with a possible effect on the problem. The root cause analysis task is usually done by applying a machine learning technique to the data gathered from the information system supporting the processes. To prevent mixing up correlation and causation, which may happen because of interpreting the findings of machine learning techniques as causal, we propose a method for discovering the structural equation model of the process that can be used for root cause analysis. We have implemented the proposed method as a plugin in ProM and we have evaluated it using two real and synthetic event logs. These experiments show the validity and effectiveness of the proposed methods.
A Survey on Reinforcement Learning for Recommender Systems
Sep 22, 2021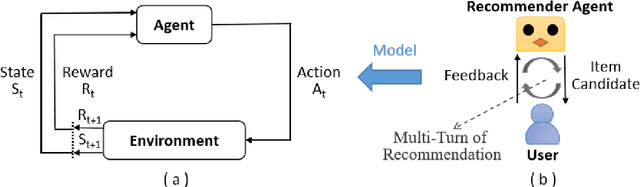

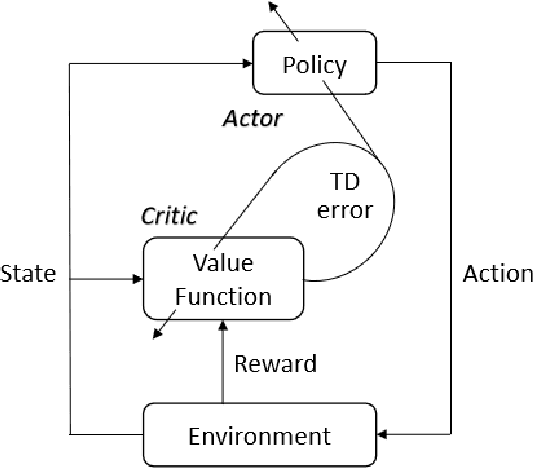
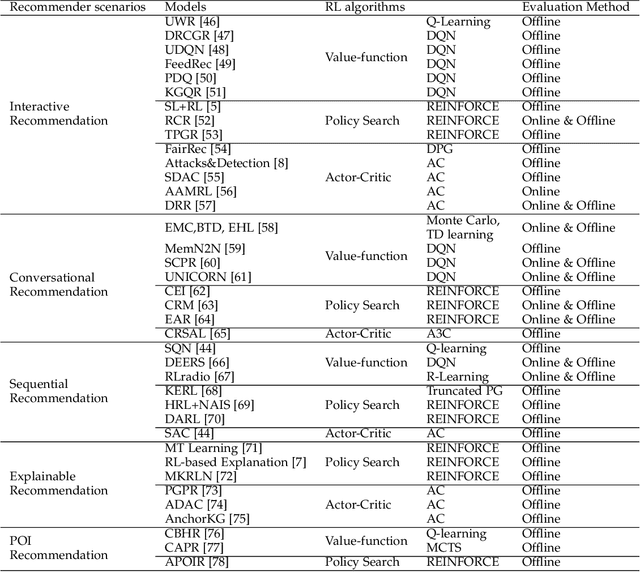
Recommender systems have been widely applied in different real-life scenarios to help us find useful information. Recently, Reinforcement Learning (RL) based recommender systems have become an emerging research topic. It often surpasses traditional recommendation models even most deep learning-based methods, owing to its interactive nature and autonomous learning ability. Nevertheless, there are various challenges of RL when applying in recommender systems. Toward this end, we firstly provide a thorough overview, comparisons, and summarization of RL approaches for five typical recommendation scenarios, following three main categories of RL: value-function, policy search, and Actor-Critic. Then, we systematically analyze the challenges and relevant solutions on the basis of existing literature. Finally, under discussion for open issues of RL and its limitations of recommendation, we highlight some potential research directions in this field.
Closed-Loop Data Transcription to an LDR via Minimaxing Rate Reduction
Nov 12, 2021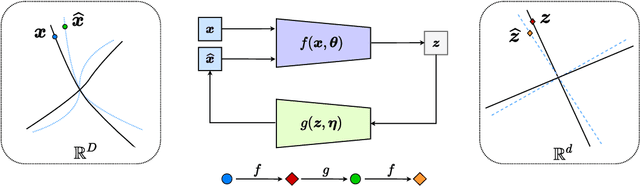
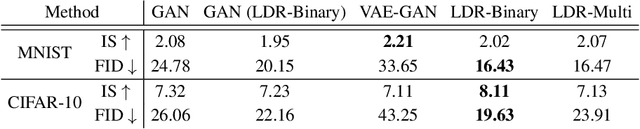
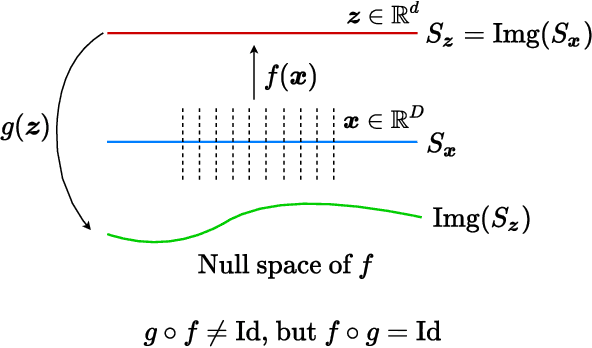
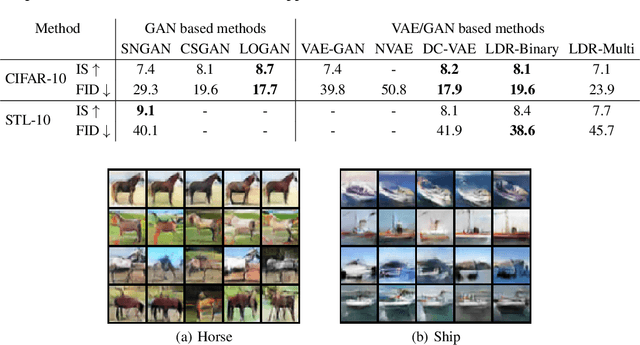
This work proposes a new computational framework for learning an explicit generative model for real-world datasets. In particular we propose to learn {\em a closed-loop transcription} between a multi-class multi-dimensional data distribution and a { linear discriminative representation (LDR)} in the feature space that consists of multiple independent multi-dimensional linear subspaces. In particular, we argue that the optimal encoding and decoding mappings sought can be formulated as the equilibrium point of a {\em two-player minimax game between the encoder and decoder}. A natural utility function for this game is the so-called {\em rate reduction}, a simple information-theoretic measure for distances between mixtures of subspace-like Gaussians in the feature space. Our formulation draws inspiration from closed-loop error feedback from control systems and avoids expensive evaluating and minimizing approximated distances between arbitrary distributions in either the data space or the feature space. To a large extent, this new formulation unifies the concepts and benefits of Auto-Encoding and GAN and naturally extends them to the settings of learning a {\em both discriminative and generative} representation for multi-class and multi-dimensional real-world data. Our extensive experiments on many benchmark imagery datasets demonstrate tremendous potential of this new closed-loop formulation: under fair comparison, visual quality of the learned decoder and classification performance of the encoder is competitive and often better than existing methods based on GAN, VAE, or a combination of both. We notice that the so learned features of different classes are explicitly mapped onto approximately {\em independent principal subspaces} in the feature space; and diverse visual attributes within each class are modeled by the {\em independent principal components} within each subspace.
BRACS: A Dataset for BReAst Carcinoma Subtyping in H&E Histology Images
Nov 08, 2021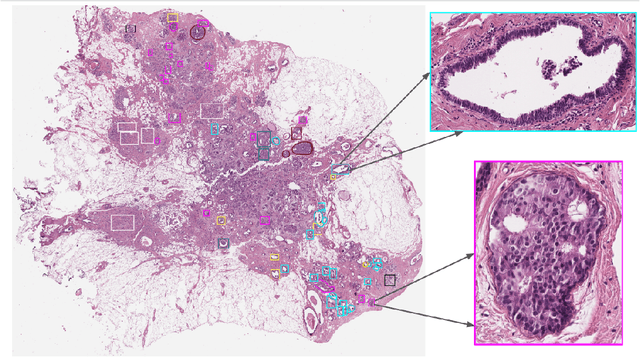

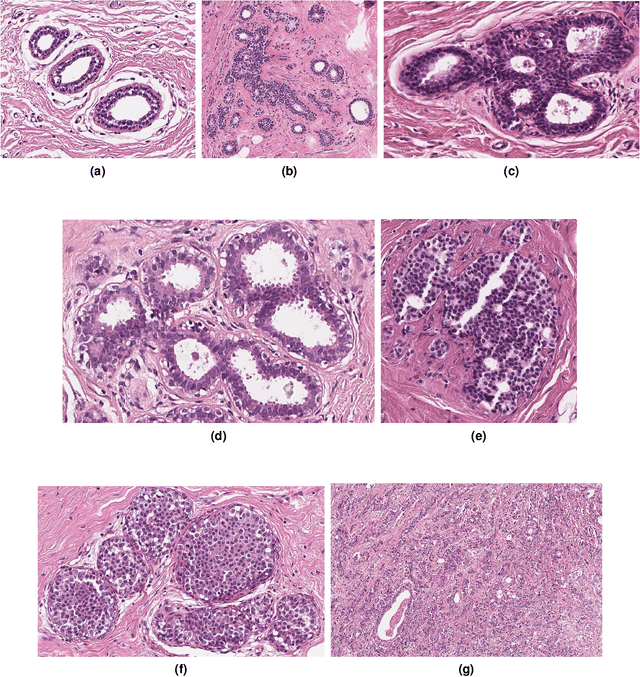
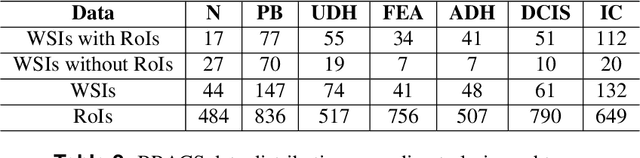
Breast cancer is the most commonly diagnosed cancer and registers the highest number of deaths for women with cancer. Recent advancements in diagnostic activities combined with large-scale screening policies have significantly lowered the mortality rates for breast cancer patients. However, the manual inspection of tissue slides by the pathologists is cumbersome, time-consuming, and is subject to significant inter- and intra-observer variability. Recently, the advent of whole-slide scanning systems have empowered the rapid digitization of pathology slides, and enabled to develop digital workflows. These advances further enable to leverage Artificial Intelligence (AI) to assist, automate, and augment pathological diagnosis. But the AI techniques, especially Deep Learning (DL), require a large amount of high-quality annotated data to learn from. Constructing such task-specific datasets poses several challenges, such as, data-acquisition level constrains, time-consuming and expensive annotations, and anonymization of private information. In this paper, we introduce the BReAst Carcinoma Subtyping (BRACS) dataset, a large cohort of annotated Hematoxylin & Eosin (H&E)-stained images to facilitate the characterization of breast lesions. BRACS contains 547 Whole-Slide Images (WSIs), and 4539 Regions of Interest (ROIs) extracted from the WSIs. Each WSI, and respective ROIs, are annotated by the consensus of three board-certified pathologists into different lesion categories. Specifically, BRACS includes three lesion types, i.e., benign, malignant and atypical, which are further subtyped into seven categories. It is, to the best of our knowledge, the largest annotated dataset for breast cancer subtyping both at WSI- and ROI-level. Further, by including the understudied atypical lesions, BRACS offers an unique opportunity for leveraging AI to better understand their characteristics.
Audio-Visual Grounding Referring Expression for Robotic Manipulation
Sep 22, 2021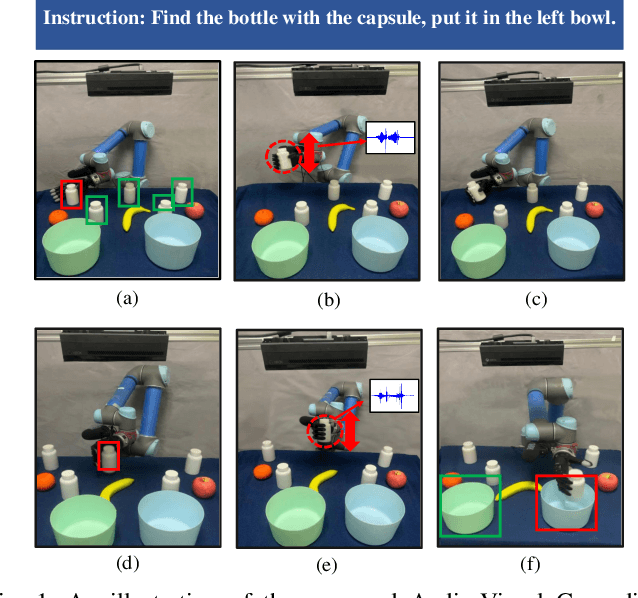
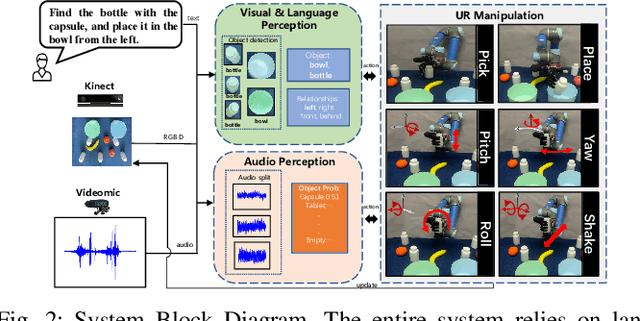
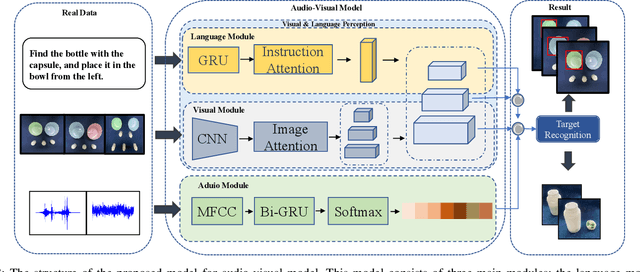

Referring expressions are commonly used when referring to a specific target in people's daily dialogue. In this paper, we develop a novel task of audio-visual grounding referring expression for robotic manipulation. The robot leverages both the audio and visual information to understand the referring expression in the given manipulation instruction and the corresponding manipulations are implemented. To solve the proposed task, an audio-visual framework is proposed for visual localization and sound recognition. We have also established a dataset which contains visual data, auditory data and manipulation instructions for evaluation. Finally, extensive experiments are conducted both offline and online to verify the effectiveness of the proposed audio-visual framework. And it is demonstrated that the robot performs better with the audio-visual data than with only the visual data.
Time-Distributed Feature Learning in Network Traffic Classification for Internet of Things
Sep 29, 2021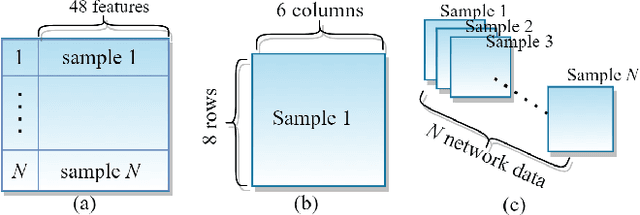
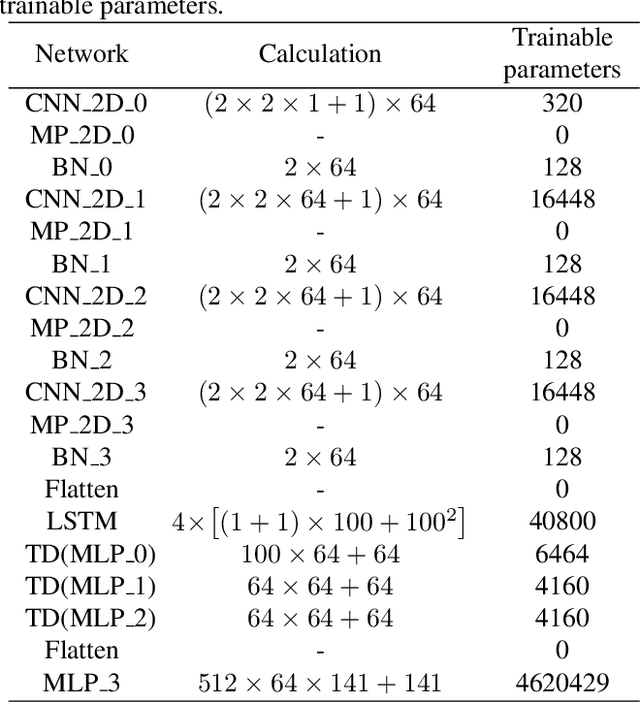
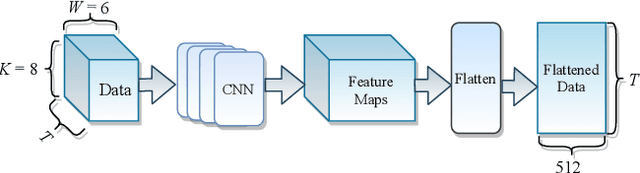

The plethora of Internet of Things (IoT) devices leads to explosive network traffic. The network traffic classification (NTC) is an essential tool to explore behaviours of network flows, and NTC is required for Internet service providers (ISPs) to manage the performance of the IoT network. We propose a novel network data representation, treating the traffic data as a series of images. Thus, the network data is realized as a video stream to employ time-distributed (TD) feature learning. The intra-temporal information within the network statistical data is learned using convolutional neural networks (CNN) and long short-term memory (LSTM), and the inter pseudo-temporal feature among the flows is learned by TD multi-layer perceptron (MLP). We conduct experiments using a large data-set with more number of classes. The experimental result shows that the TD feature learning elevates the network classification performance by 10%.