 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-based Instance Representation Learning
Oct 30, 2021
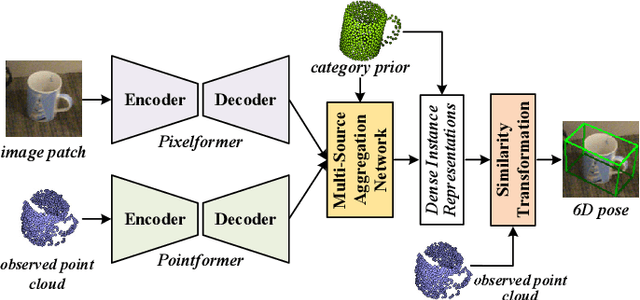


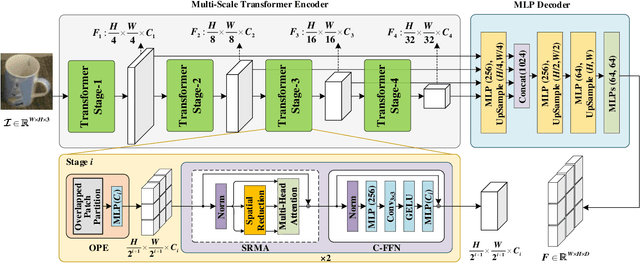
This paper presents 6D-ViT, a transformer-based instance representation learning network, which is suitable for highly accurate category-level object pose estimation on RGB-D images. Specifically, a novel two-stream encoder-decoder framework is dedicated to exploring complex and powerful instance representations from RGB images, point clouds and categorical shape priors. For this purpose, the whole framework consists of two main branches, named Pixelformer and Pointformer. The Pixelformer contains a pyramid transformer encoder with an all-MLP decoder to extract pixelwise appearance representations from RGB images, while the Pointformer relies on a cascaded transformer encoder and an all-MLP decoder to acquire the pointwise geometric characteristics from point clouds. Then, dense instance representations (i.e., correspondence matrix, deformation field) are obtained from a multi-source aggregation network with shape priors, appearance and geometric information as input. Finally, the instance 6D pose is computed by leveraging the correspondence among dense representations, shape priors, and the instance point clouds. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed 3D instance representation learning framework achieves state-of-the-art performance on both datasets, and significantly outperforms all existing methods.
Capacity Optimal Generalized Multi-User MIMO: A Theoretical and Practical Framework
Nov 22, 2021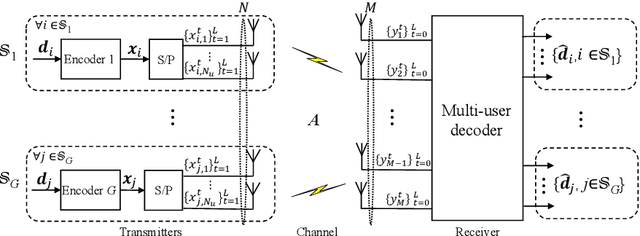
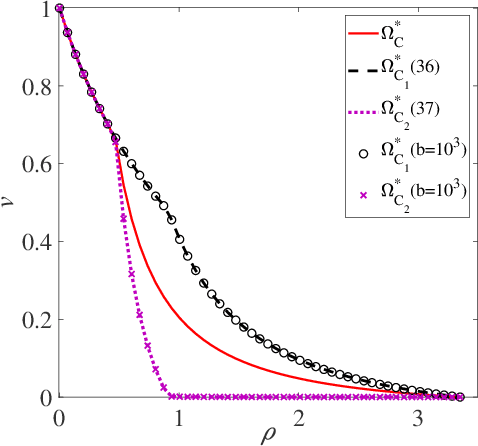
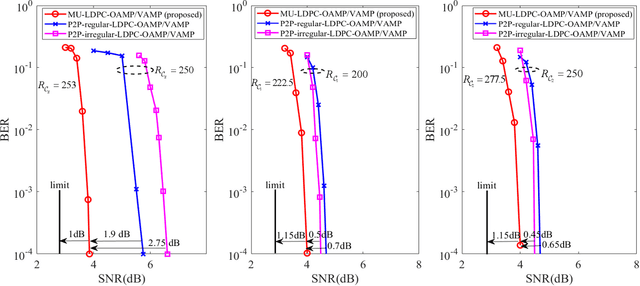
Conventional multi-user multiple-input multiple-output (MU-MIMO) mainly focused on Gaussian signaling, independent and identically distributed (IID) channels, and a limited number of users. It will be laborious to cope with the heterogeneous requirements in next-generation wireless communications, such as various transmission data, complicated communication scenarios, and massive user access. Therefore, this paper studies a generalized MU-MIMO (GMU-MIMO) system with more practical constraints, i.e., non-Gaussian signaling, non-IID channel, and massive users and antennas. These generalized assumptions bring new challenges in theory and practice. For example, there is no accurate capacity analysis for GMU-MIMO. In addition, it is unclear how to achieve the capacity optimal performance with practical complexity. To address these challenges, a unified framework is proposed to derive the GMU-MIMO capacity and design a capacity optimal transceiver, which jointly considers encoding, modulation, detection, and decoding. Group asymmetry is developed to make a tradeoff between user rate allocation and implementation complexity. Specifically, the capacity region of group asymmetric GMU-MIMO is characterized by using the celebrated mutual information and minimum mean-square error (MMSE) lemma and the MMSE optimality of orthogonal approximate message passing (OAMP)/vector AMP (VAMP). Furthermore, a theoretically optimal multi-user OAMP/VAMP receiver and practical multi-user low-density parity-check (MU-LDPC) codes are proposed to achieve the capacity region of group asymmetric GMU-MIMO. Numerical results verify that the gaps between theoretical detection thresholds of the proposed framework with optimized MU-LDPC codes and QPSK modulation and the sum capacity of GMU-MIMO are about 0.2 dB. Moreover, their finite-length performances are about 1~2 dB away from the associated sum capacity.
Multi-Server Private Linear Computation with Joint and Individual Privacy Guarantees
Aug 23, 2021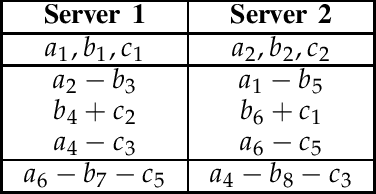
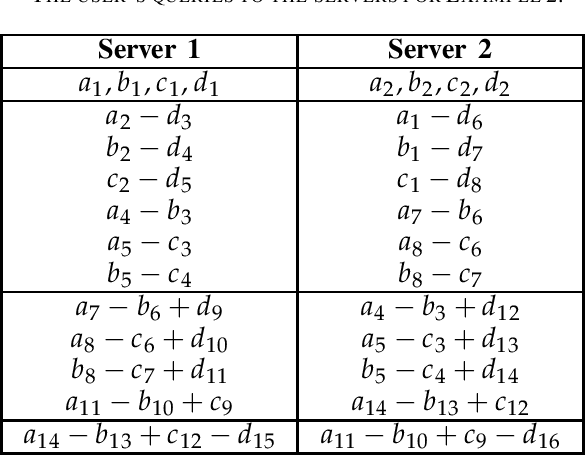
This paper considers the problem of multi-server Private Linear Computation, under the joint and individual privacy guarantees. In this problem, identical copies of a dataset comprised of $K$ messages are stored on $N$ non-colluding servers, and a user wishes to obtain one linear combination of a $D$-subset of messages belonging to the dataset. The goal is to design a scheme for performing the computation such that the total amount of information downloaded from the servers is minimized, while the privacy of the $D$ messages required for the computation is protected. When joint privacy is required, the identities of all of these $D$ messages must be kept private jointly, and when individual privacy is required, the identity of every one of these $D$ messages must be kept private individually. In this work, we characterize the capacity, which is defined as the maximum achievable download rate, under both joint and individual privacy requirements. In particular, we show that when joint privacy is required the capacity is given by ${(1+1/N+\dots+1/N^{K-D})^{-1}}$, and when individual privacy is required the capacity is given by ${(1+1/N+\dots+1/N^{\lceil K/D\rceil-1})^{-1}}$ assuming that $D$ divides $K$, or $K\pmod D$ divides $D$. Our converse proofs are based on reduction from two variants of the multi-server Private Information Retrieval problem in the presence of side information. Our achievability schemes build up on our recently proposed schemes for single-server Private Linear Transformation and the multi-server private computation scheme proposed by Sun and Jafar. Using similar proof techniques, we also establish upper and lower bounds on the capacity for the cases in which the user wants to compute $L$ (potentially more than one) linear combinations.
Identifying nonlinear dynamical systems from multi-modal time series data
Nov 04, 2021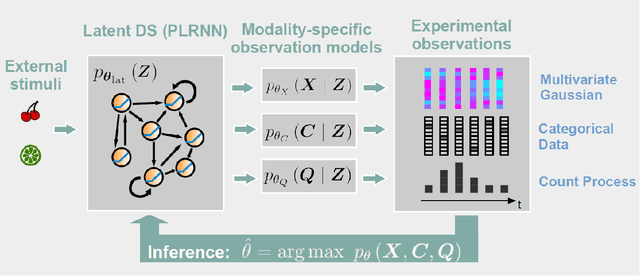
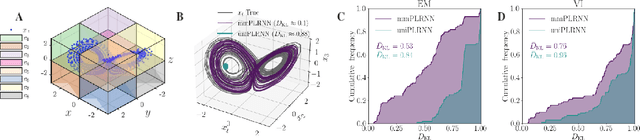

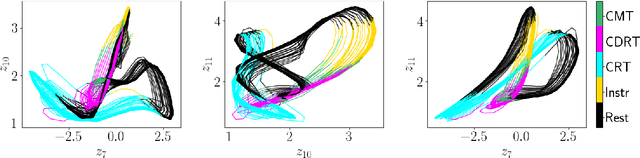
Empirically observed time series in physics, biology, or medicine, are commonly generated by some underlying dynamical system (DS) which is the target of scientific interest. There is an increasing interest to harvest machine learning methods to reconstruct this latent DS in a completely data-driven, unsupervised way. In many areas of science it is common to sample time series observations from many data modalities simultaneously, e.g. electrophysiological and behavioral time series in a typical neuroscience experiment. However, current machine learning tools for reconstructing DSs usually focus on just one data modality. Here we propose a general framework for multi-modal data integration for the purpose of nonlinear DS identification and cross-modal prediction. This framework is based on dynamically interpretable recurrent neural networks as general approximators of nonlinear DSs, coupled to sets of modality-specific decoder models from the class of generalized linear models. Both an expectation-maximization and a variational inference algorithm for model training are advanced and compared. We show on nonlinear DS benchmarks that our algorithms can efficiently compensate for too noisy or missing information in one data channel by exploiting other channels, and demonstrate on experimental neuroscience data how the algorithm learns to link different data domains to the underlying dynamics
MLBiNet: A Cross-Sentence Collective Event Detection Network
May 23, 2021
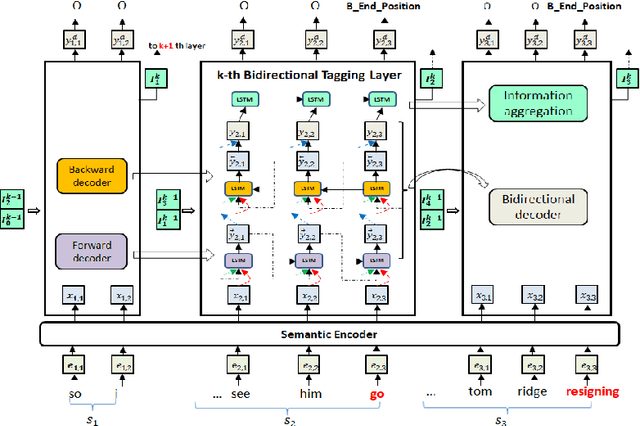
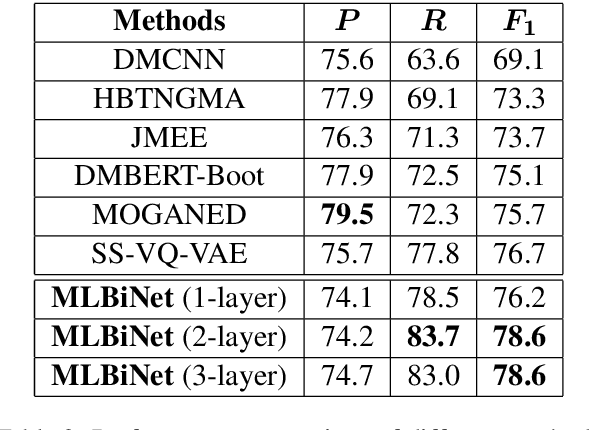
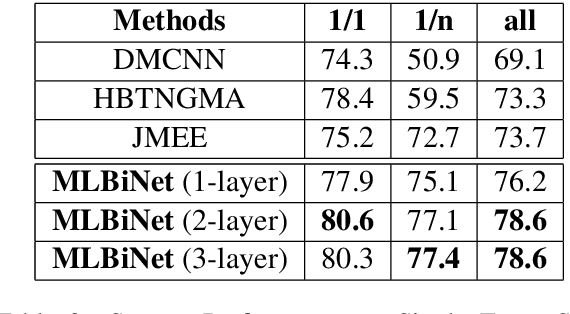
We consider the problem of collectively detecting multiple events, particularly in cross-sentence settings. The key to dealing with the problem is to encode semantic information and model event inter-dependency at a document-level. In this paper, we reformulate it as a Seq2Seq task and propose a Multi-Layer Bidirectional Network (MLBiNet) to capture the document-level association of events and semantic information simultaneously. Specifically, a bidirectional decoder is firstly devised to model event inter-dependency within a sentence when decoding the event tag vector sequence. Secondly, an information aggregation module is employed to aggregate sentence-level semantic and event tag information. Finally, we stack multiple bidirectional decoders and feed cross-sentence information, forming a multi-layer bidirectional tagging architecture to iteratively propagate information across sentences. We show that our approach provides significant improvement in performance compared to the current state-of-the-art results.
Learning Representation over Dynamic Graph using Aggregation-Diffusion Mechanism
Jun 03, 2021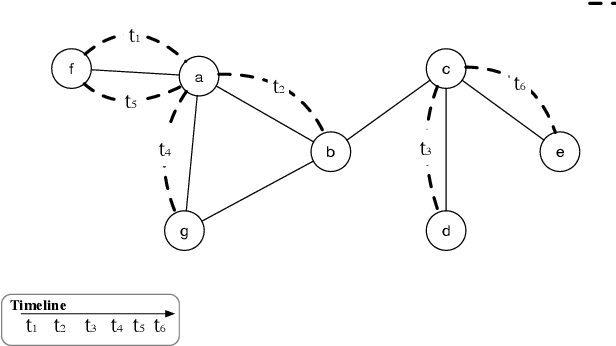
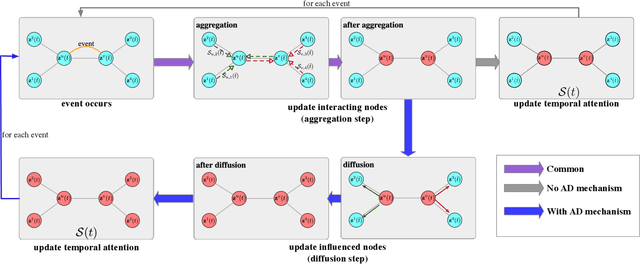
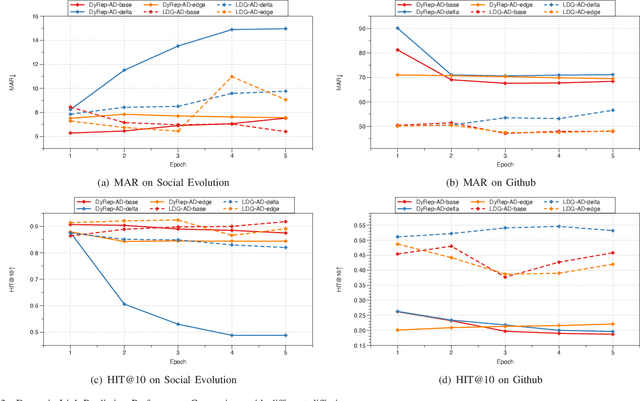
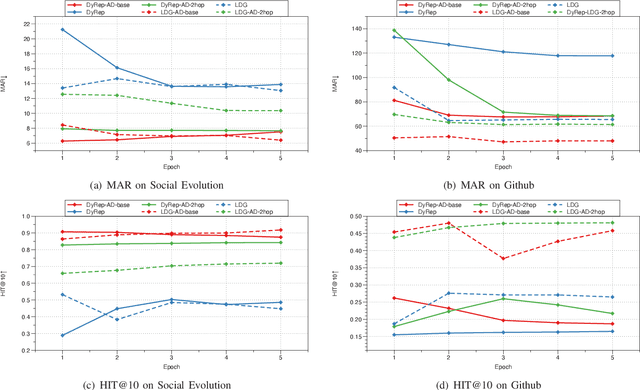
Representation learning on graphs that evolve has recently received significant attention due to its wide application scenarios, such as bioinformatics, knowledge graphs, and social networks. The propagation of information in graphs is important in learning dynamic graph representations, and most of the existing methods achieve this by aggregation. However, relying only on aggregation to propagate information in dynamic graphs can result in delays in information propagation and thus affect the performance of the method. To alleviate this problem, we propose an aggregation-diffusion (AD) mechanism that actively propagates information to its neighbor by diffusion after the node updates its embedding through the aggregation mechanism. In experiments on two real-world datasets in the dynamic link prediction task, the AD mechanism outperforms the baseline models that only use aggregation to propagate information. We further conduct extensive experiments to discuss the influence of different factors in the AD mechanism.
Dual Transfer Learning for Event-based End-task Prediction via Pluggable Event to Image Translation
Sep 04, 2021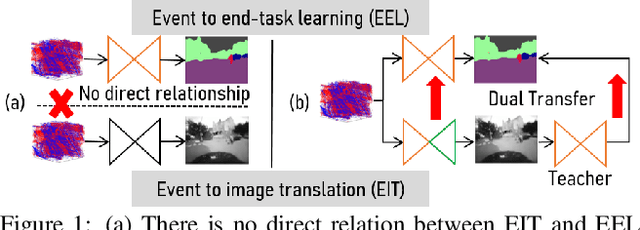



Event cameras are novel sensors that perceive the per-pixel intensity changes and output asynchronous event streams with high dynamic range and less motion blur. It has been shown that events alone can be used for end-task learning, \eg, semantic segmentation, based on encoder-decoder-like networks. However, as events are sparse and mostly reflect edge information, it is difficult to recover original details merely relying on the decoder. Moreover, most methods resort to pixel-wise loss alone for supervision, which might be insufficient to fully exploit the visual details from sparse events, thus leading to less optimal performance. In this paper, we propose a simple yet flexible two-stream framework named Dual Transfer Learning (DTL) to effectively enhance the performance on the end-tasks without adding extra inference cost. The proposed approach consists of three parts: event to end-task learning (EEL) branch, event to image translation (EIT) branch, and transfer learning (TL) module that simultaneously explores the feature-level affinity information and pixel-level knowledge from the EIT branch to improve the EEL branch. This simple yet novel method leads to strong representation learning from events and is evidenced by the significant performance boost on the end-tasks such as semantic segmentation and depth estimation.
A Partition Filter Network for Joint Entity and Relation Extraction
Sep 09, 2021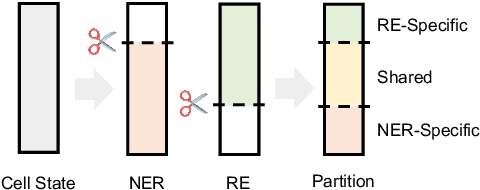
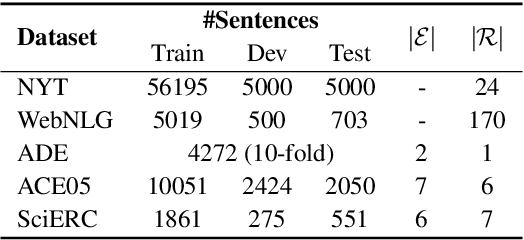
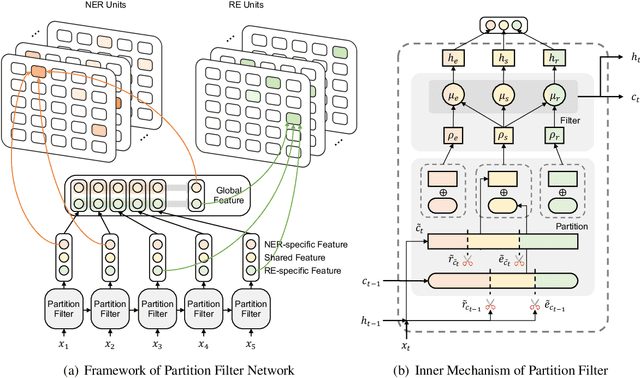
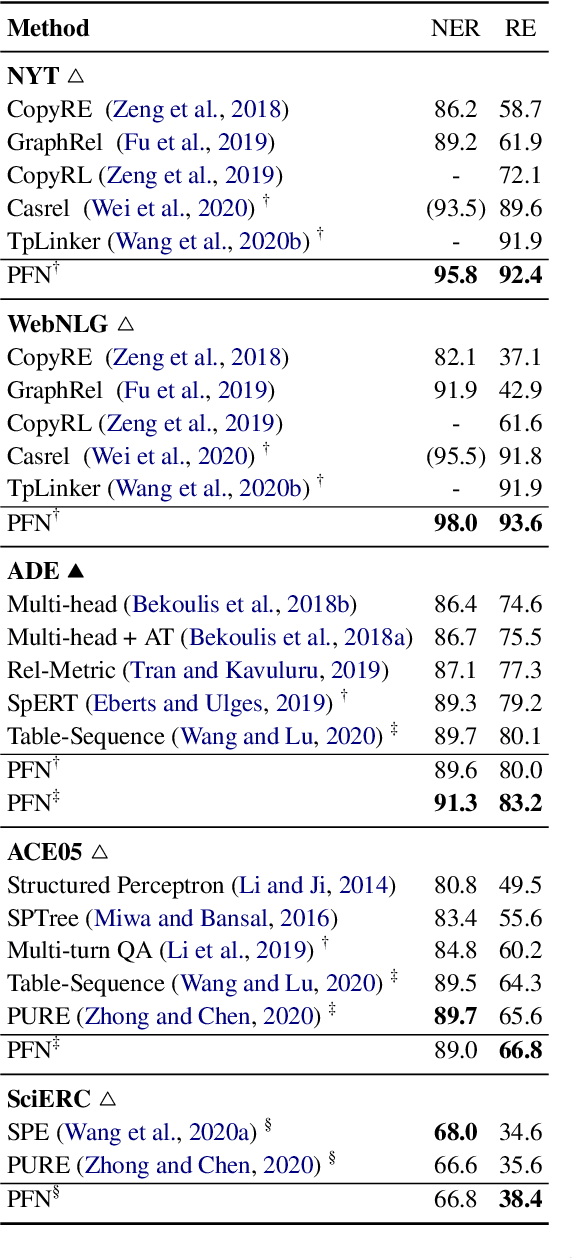
In joint entity and relation extraction, existing work either sequentially encode task-specific features, leading to an imbalance in inter-task feature interaction where features extracted later have no direct contact with those that come first. Or they encode entity features and relation features in a parallel manner, meaning that feature representation learning for each task is largely independent of each other except for input sharing. We propose a partition filter network to model two-way interaction between tasks properly, where feature encoding is decomposed into two steps: partition and filter. In our encoder, we leverage two gates: entity and relation gate, to segment neurons into two task partitions and one shared partition. The shared partition represents inter-task information valuable to both tasks and is evenly shared across two tasks to ensure proper two-way interaction. The task partitions represent intra-task information and are formed through concerted efforts of both gates, making sure that encoding of task-specific features is dependent upon each other. Experiment results on six public datasets show that our model performs significantly better than previous approaches. In addition, contrary to what previous work has claimed, our auxiliary experiments suggest that relation prediction is contributory to named entity prediction in a non-negligible way. The source code can be found at https://github.com/Coopercoppers/PFN.
High-Resolution Talking Face Generation via Mutual Information Approximation
Dec 17, 2018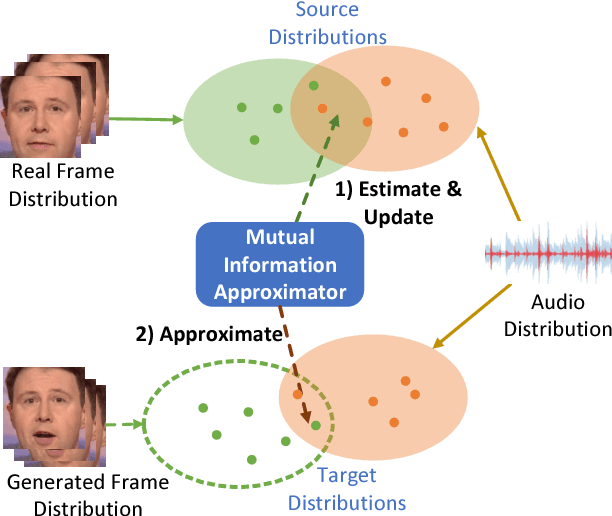
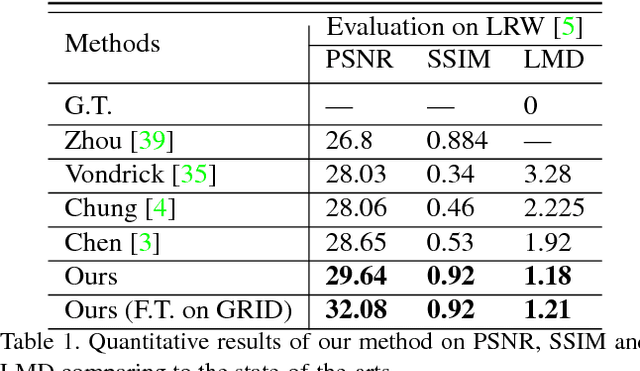
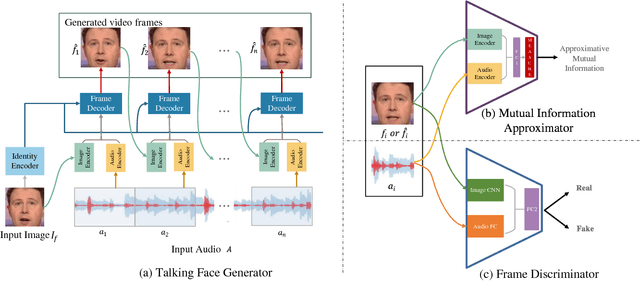
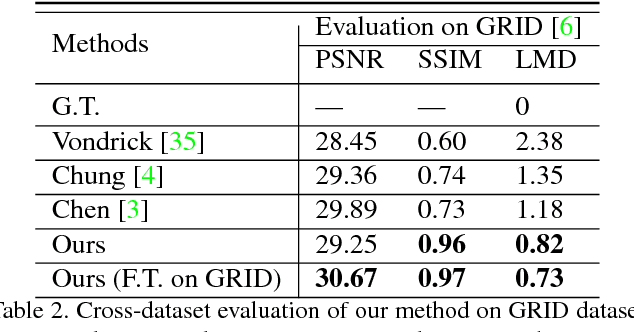
Given an arbitrary speech clip and a facial image, talking face generation aims to synthesize a talking face video with precise lip synchronization as well as a smooth transition of facial motion over the entire video speech. Most existing methods mainly focus on either disentangling the information in a single image or learning temporal information between frames. However, speech audio and video often have cross-modality coherence that has not been well addressed during synthesis. Therefore, this paper proposes a novel high-resolution talking face generation model for arbitrary person by discovering the cross-modality coherence via Mutual Information Approximation (MIA). By assuming the modality difference between audio and video is larger that of real video and generated video, we estimate mutual information between real audio and video, and then use a discriminator to enforce generated video distribution approach real video distribution. Furthermore, we introduce a dynamic attention technique on the mouth to enhance the robustness during the training stage. Experimental results on benchmark dataset LRW transcend the state-of-the-art methods on prevalent metrics with robustness on gender, pose variations and high-resolution synthesizing.
Iris Recognition Based on SIFT Features
Oct 30, 2021Biometric methods based on iris images are believed to allow very high accuracy, and there has been an explosion of interest in iris biometrics in recent years. In this paper, we use the Scale Invariant Feature Transformation (SIFT) for recognition using iris images. Contrarily to traditional iris recognition systems, the SIFT approach does not rely on the transformation of the iris pattern to polar coordinates or on highly accurate segmentation, allowing less constrained image acquisition conditions. We extract characteristic SIFT feature points in scale space and perform matching based on the texture information around the feature points using the SIFT operator. Experiments are done using the BioSec multimodal database, which includes 3,200 iris images from 200 individuals acquired in two different sessions. We contribute with the analysis of the influence of different SIFT parameters on the recognition performance. We also show the complementarity between the SIFT approach and a popular matching approach based on transformation to polar coordinates and Log-Gabor wavelets. The combination of the two approaches achieves significantly better performance than either of the individual schemes, with a performance improvement of 24% in the Equal Error Rate.