 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of Storage and Loading for High-Performance 3D Point Cloud Data Processing
Mar 16, 2026With the rapid development of computer vision and deep learning, significant advancements have been made in 3D vision, partic- ularly in autonomous driving, robotic perception, and augmented reality. 3D point cloud data, as a crucial representation of 3D information, has gained widespread attention. However, the vast scale and complexity of point cloud data present significant chal- lenges for loading and processing and traditional algorithms struggle to handle large-scale datasets.The diversity of storage formats for point cloud datasets (e.g., PLY, XYZ, BIN) adds complexity to data handling and results in inefficiencies in data preparation. Al- though binary formats like BIN and NPY have been used to speed up data access, they still do not fully address the time-consuming data loading and processing phase. To overcome these challenges, we propose the .PcRecord format, a unified data storage solution designed to reduce the storage occupation and accelerate the processing of point cloud data. We also introduce a high-performance data processing pipeline equipped with multiple modules. By leveraging a multi-stage parallel pipeline architecture, our system optimizes the use of computational resources, significantly improving processing speed and efficiency. This paper details the im- plementation of this system and demonstrates its effectiveness in addressing the challenges of handling large-scale point cloud datasets.On average, our system achieves performance improvements of 6.61x (ModelNet40), 2.69x (S3DIS), 2.23x (ShapeNet), 3.09x (Kitti), 8.07x (SUN RGB-D), and 5.67x (ScanNet) with GPU and 6.9x, 1.88x, 1.29x, 2.28x, 25.4x, and 19.3x with Ascend.
6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-based Instance Representation Learning
Oct 30, 2021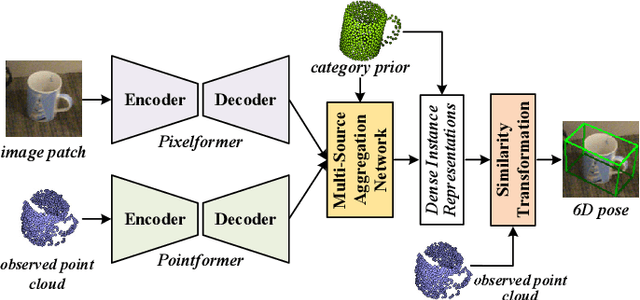


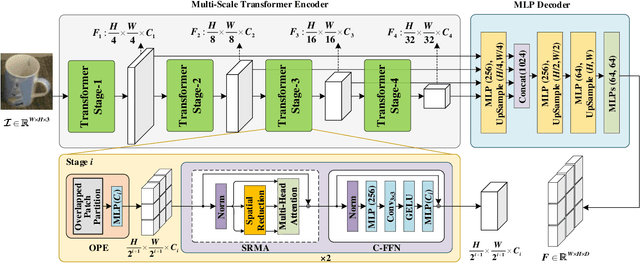
This paper presents 6D-ViT, a transformer-based instance representation learning network, which is suitable for highly accurate category-level object pose estimation on RGB-D images. Specifically, a novel two-stream encoder-decoder framework is dedicated to exploring complex and powerful instance representations from RGB images, point clouds and categorical shape priors. For this purpose, the whole framework consists of two main branches, named Pixelformer and Pointformer. The Pixelformer contains a pyramid transformer encoder with an all-MLP decoder to extract pixelwise appearance representations from RGB images, while the Pointformer relies on a cascaded transformer encoder and an all-MLP decoder to acquire the pointwise geometric characteristics from point clouds. Then, dense instance representations (i.e., correspondence matrix, deformation field) are obtained from a multi-source aggregation network with shape priors, appearance and geometric information as input. Finally, the instance 6D pose is computed by leveraging the correspondence among dense representations, shape priors, and the instance point clouds. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed 3D instance representation learning framework achieves state-of-the-art performance on both datasets, and significantly outperforms all existing methods.