 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6D-ViT: Category-Level 6D Object Pose Estimation via Transformer-based Instance Representation Learning
Paper and Code
Oct 30, 2021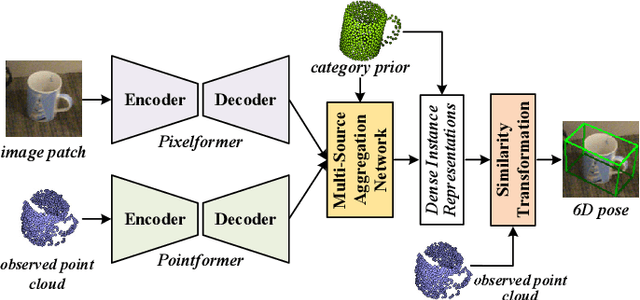


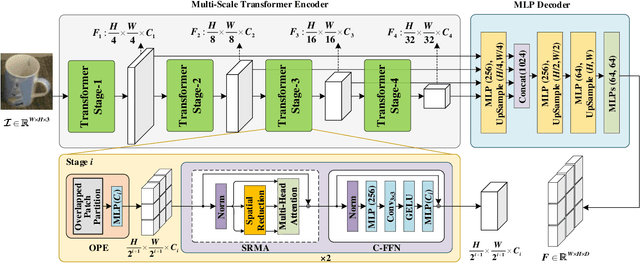
This paper presents 6D-ViT, a transformer-based instance representation learning network, which is suitable for highly accurate category-level object pose estimation on RGB-D images. Specifically, a novel two-stream encoder-decoder framework is dedicated to exploring complex and powerful instance representations from RGB images, point clouds and categorical shape priors. For this purpose, the whole framework consists of two main branches, named Pixelformer and Pointformer. The Pixelformer contains a pyramid transformer encoder with an all-MLP decoder to extract pixelwise appearance representations from RGB images, while the Pointformer relies on a cascaded transformer encoder and an all-MLP decoder to acquire the pointwise geometric characteristics from point clouds. Then, dense instance representations (i.e., correspondence matrix, deformation field) are obtained from a multi-source aggregation network with shape priors, appearance and geometric information as input. Finally, the instance 6D pose is computed by leveraging the correspondence among dense representations, shape priors, and the instance point clouds. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed 3D instance representation learning framework achieves state-of-the-art performance on both datasets, and significantly outperforms all existing methods.