 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-supervised High-fidelity and Re-renderable 3D Facial Reconstruction from a Single Image
Nov 16, 2021
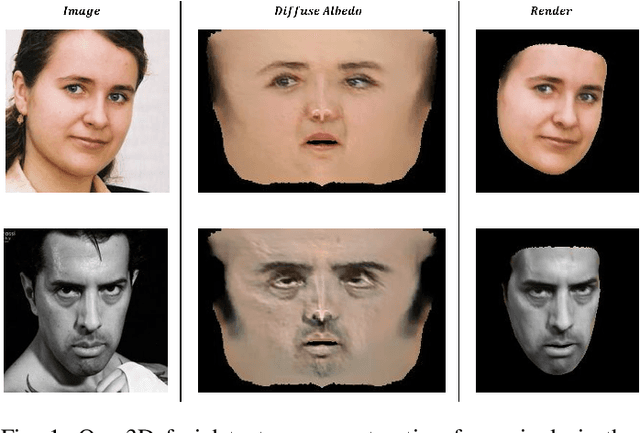

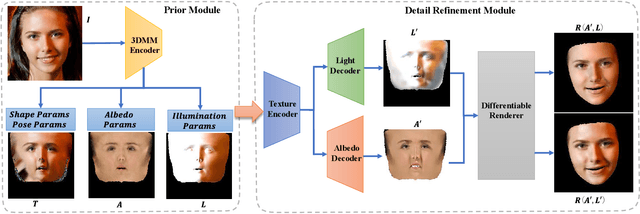

Reconstructing high-fidelity 3D facial texture from a single image is a challenging task since the lack of complete face information and the domain gap between the 3D face and 2D image. The most recent works tackle facial texture reconstruction problem by applying either generation-based or reconstruction-based methods. Although each method has its own advantage, none of them is capable of recovering a high-fidelity and re-renderable facial texture, where the term 're-renderable' demands the facial texture to be spatially complete and disentangled with environmental illumination. In this paper, we propose a novel self-supervised learning framework for reconstructing high-quality 3D faces from single-view images in-the-wild. Our main idea is to first utilize the prior generation module to produce a prior albedo, then leverage the detail refinement module to obtain detailed albedo. To further make facial textures disentangled with illumination, we present a novel detailed illumination representation which is reconstructed with the detailed albedo together. We also design several regularization loss functions on both the albedo side and illumination side to facilitate the disentanglement of these two factors. Finally, thanks to the differentiable rendering technique, our neural network can be efficiently trained in a self-supervised manner. Extensive experiments on challenging datasets demonstrate that our framework substantially outperforms state-of-the-art approaches in both qualitative and quantitative comparisons.
Reducing Data Complexity using Autoencoders with Class-informed Loss Functions
Nov 11, 2021

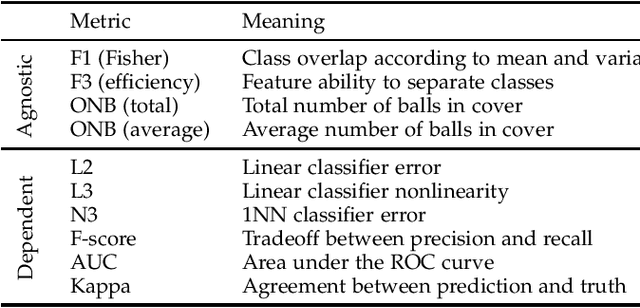
Available data in machine learning applications is becoming increasingly complex, due to higher dimensionality and difficult classes. There exists a wide variety of approaches to measuring complexity of labeled data, according to class overlap, separability or boundary shapes, as well as group morphology. Many techniques can transform the data in order to find better features, but few focus on specifically reducing data complexity. Most data transformation methods mainly treat the dimensionality aspect, leaving aside the available information within class labels which can be useful when classes are somehow complex. This paper proposes an autoencoder-based approach to complexity reduction, using class labels in order to inform the loss function about the adequacy of the generated variables. This leads to three different new feature learners, Scorer, Skaler and Slicer. They are based on Fisher's discriminant ratio, the Kullback-Leibler divergence and least-squares support vector machines, respectively. They can be applied as a preprocessing stage for a binary classification problem. A thorough experimentation across a collection of 27 datasets and a range of complexity and classification metrics shows that class-informed autoencoders perform better than 4 other popular unsupervised feature extraction techniques, especially when the final objective is using the data for a classification task.
3D High-Quality Magnetic Resonance Image Restoration in Clinics Using Deep Learning
Nov 28, 2021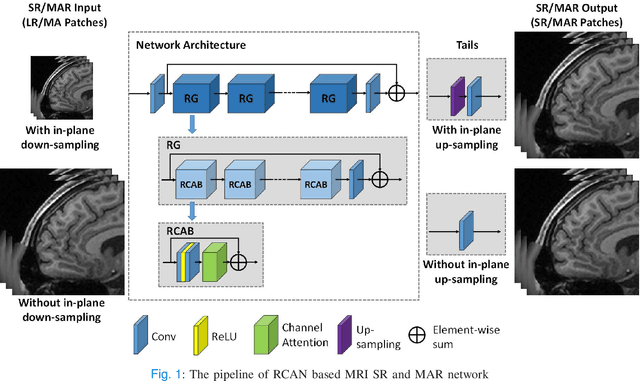
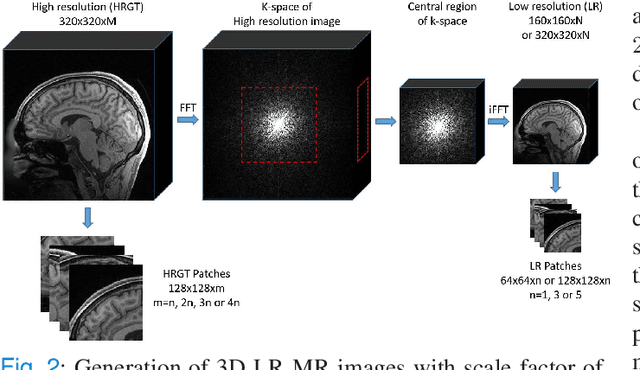
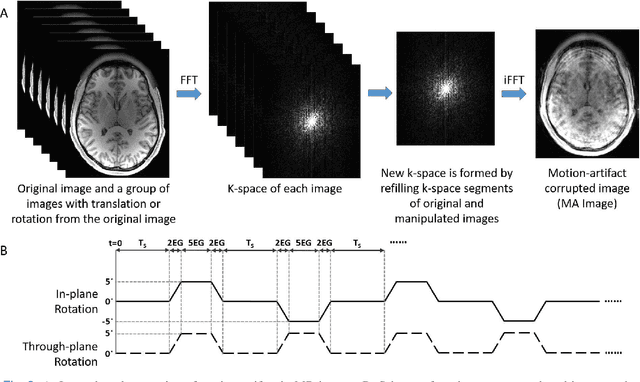

Shortening acquisition time and reducing the motion-artifact are two of the most essential concerns in magnetic resonance imaging. As a promising solution, deep learning-based high quality MR image restoration has been investigated to generate higher resolution and motion artifact-free MR images from lower resolution images acquired with shortened acquisition time, without costing additional acquisition time or modifying the pulse sequences. However, numerous problems still exist to prevent deep learning approaches from becoming practical in the clinic environment. Specifically, most of the prior works focus solely on the network model but ignore the impact of various downsampling strategies on the acquisition time. Besides, the long inference time and high GPU consumption are also the bottle neck to deploy most of the prior works in clinics. Furthermore, prior studies employ random movement in retrospective motion artifact generation, resulting in uncontrollable severity of motion artifact. More importantly, doctors are unsure whether the generated MR images are trustworthy, making diagnosis difficult. To overcome all these problems, we employed a unified 2D deep learning neural network for both 3D MRI super resolution and motion artifact reduction, demonstrating such a framework can achieve better performance in 3D MRI restoration task compared to other states of the art methods and remains the GPU consumption and inference time significantly low, thus easier to deploy. We also analyzed several downsampling strategies based on the acceleration factor, including multiple combinations of in-plane and through-plane downsampling, and developed a controllable and quantifiable motion artifact generation method. At last, the pixel-wise uncertainty was calculated and used to estimate the accuracy of generated image, providing additional information for reliable diagnosis.
Revisiting joint decoding based multi-talker speech recognition with DNN acoustic model
Oct 31, 2021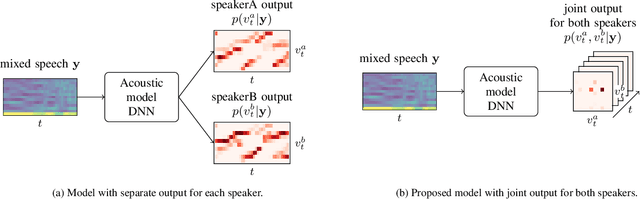
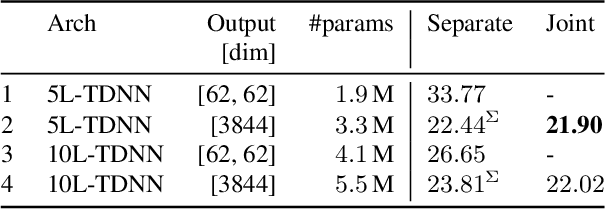
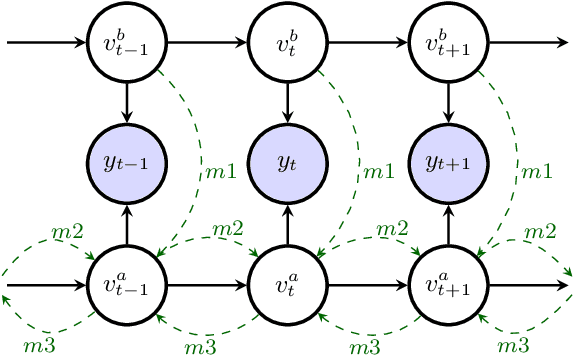
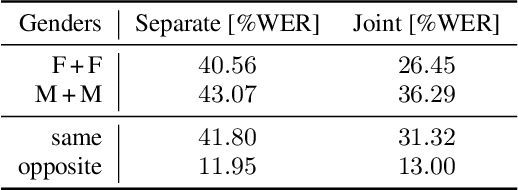
In typical multi-talker speech recognition systems, a neural network-based acoustic model predicts senone state posteriors for each speaker. These are later used by a single-talker decoder which is applied on each speaker-specific output stream separately. In this work, we argue that such a scheme is sub-optimal and propose a principled solution that decodes all speakers jointly. We modify the acoustic model to predict joint state posteriors for all speakers, enabling the network to express uncertainty about the attribution of parts of the speech signal to the speakers. We employ a joint decoder that can make use of this uncertainty together with higher-level language information. For this, we revisit decoding algorithms used in factorial generative models in early multi-talker speech recognition systems. In contrast with these early works, we replace the GMM acoustic model with DNN, which provides greater modeling power and simplifies part of the inference. We demonstrate the advantage of joint decoding in proof of concept experiments on a mixed-TIDIGITS dataset.
Least Square Calibration for Peer Review
Oct 25, 2021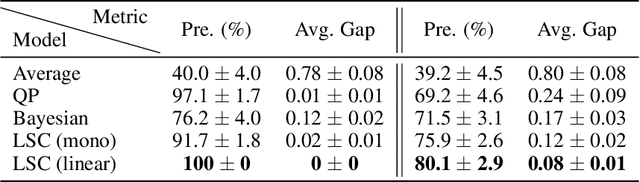
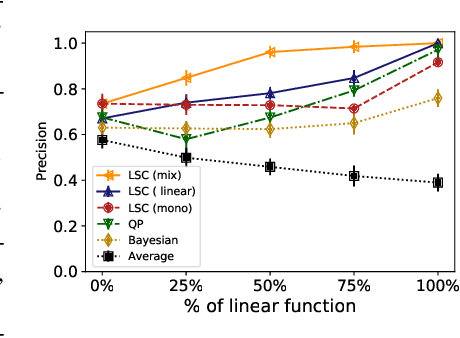

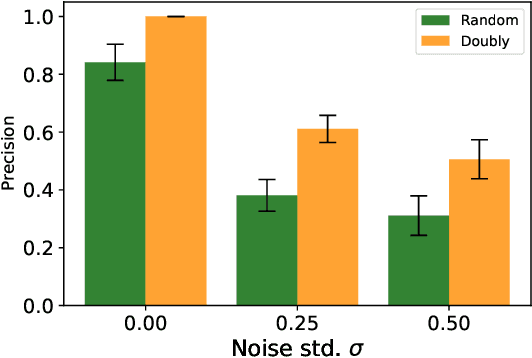
Peer review systems such as conference paper review often suffer from the issue of miscalibration. Previous works on peer review calibration usually only use the ordinal information or assume simplistic reviewer scoring functions such as linear functions. In practice, applications like academic conferences often rely on manual methods, such as open discussions, to mitigate miscalibration. It remains an important question to develop algorithms that can handle different types of miscalibrations based on available prior knowledge. In this paper, we propose a flexible framework, namely least square calibration (LSC), for selecting top candidates from peer ratings. Our framework provably performs perfect calibration from noiseless linear scoring functions under mild assumptions, yet also provides competitive calibration results when the scoring function is from broader classes beyond linear functions and with arbitrary noise. On our synthetic dataset, we empirically demonstrate that our algorithm consistently outperforms the baseline which select top papers based on the highest average ratings.
Bridger: Toward Bursting Scientific Filter Bubbles and Boosting Innovation via Novel Author Discovery
Aug 12, 2021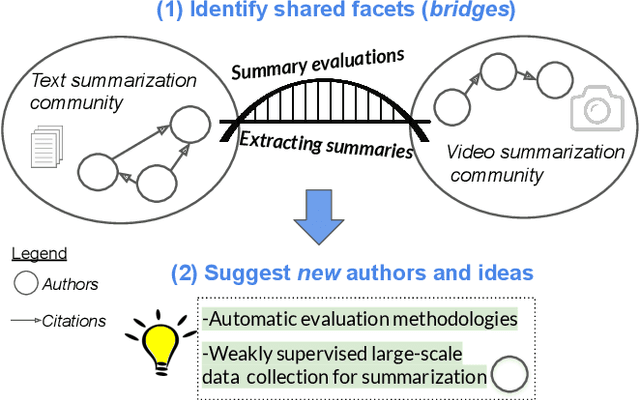
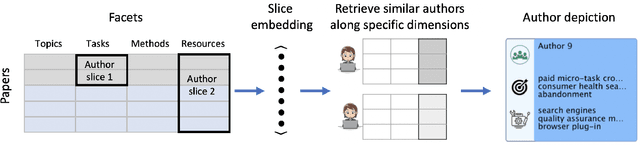
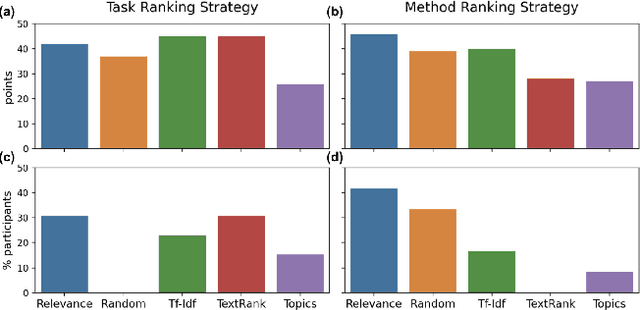
Scientific silos can hinder innovation. These information "filter bubbles" and the growing challenge of information overload limit awareness across the literature, making it difficult to keep track of even narrow areas of interest, let alone discover new ones. Algorithmic curation and recommendation, which often prioritize relevance, can further reinforce these bubbles. In response, we describe Bridger, a system for facilitating discovery of scholars and their work, to explore design tradeoffs among relevant and novel recommendations. We construct a faceted representation of authors using information extracted from their papers and inferred personas. We explore approaches both for recommending new content and for displaying it in a manner that helps researchers to understand the work of authors who they are unfamiliar with. In studies with computer science researchers, our approach substantially improves users' abilities to do so. We develop an approach that locates commonalities and contrasts between scientists---retrieving partially similar authors, rather than aiming for strict similarity. We find this approach helps users discover authors useful for generating novel research ideas of relevance to their work, at a higher rate than a state-of-art neural model. Our analysis reveals that Bridger connects authors who have different citation profiles, publish in different venues, and are more distant in social co-authorship networks, raising the prospect of bridging diverse communities and facilitating discovery.
MCUa: Multi-level Context and Uncertainty aware Dynamic Deep Ensemble for Breast Cancer Histology Image Classification
Aug 24, 2021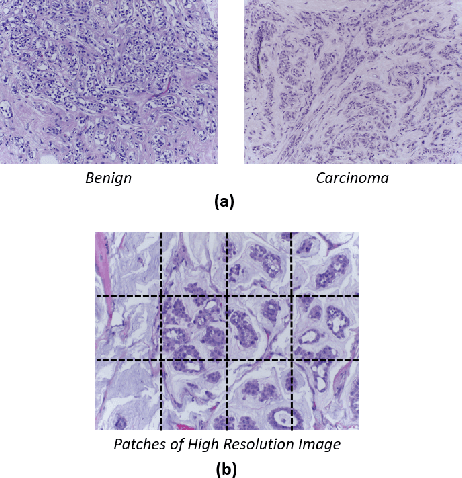
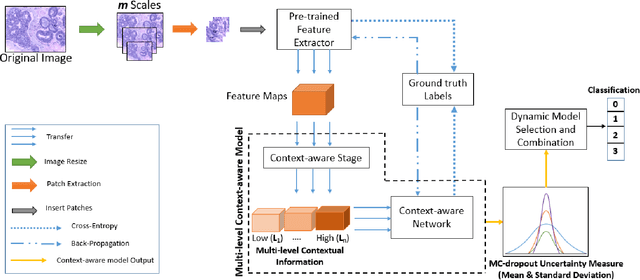

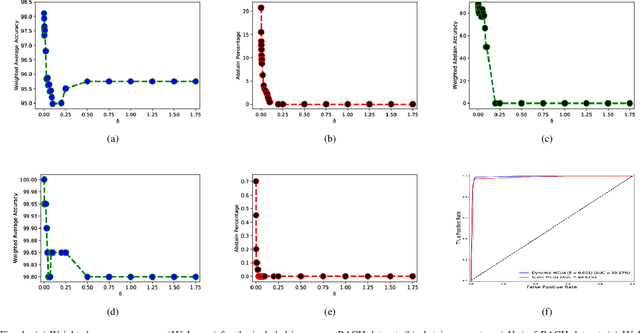
Breast histology image classification is a crucial step in the early diagnosis of breast cancer. In breast pathological diagnosis, Convolutional Neural Networks (CNNs) have demonstrated great success using digitized histology slides. However, tissue classification is still challenging due to the high visual variability of the large-sized digitized samples and the lack of contextual information. In this paper, we propose a novel CNN, called Multi-level Context and Uncertainty aware (MCUa) dynamic deep learning ensemble model.MCUamodel consists of several multi-level context-aware models to learn the spatial dependency between image patches in a layer-wise fashion. It exploits the high sensitivity to the multi-level contextual information using an uncertainty quantification component to accomplish a novel dynamic ensemble model.MCUamodelhas achieved a high accuracy of 98.11% on a breast cancer histology image dataset. Experimental results show the superior effectiveness of the proposed solution compared to the state-of-the-art histology classification models.
* accepted by IEEE Transactions on Biomedical Engineering
Reversible adversarial examples against local visual perturbation
Oct 06, 2021
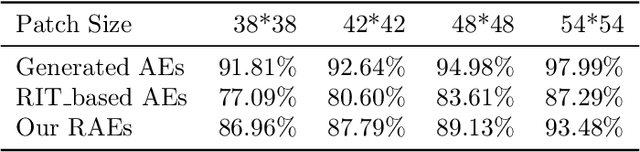
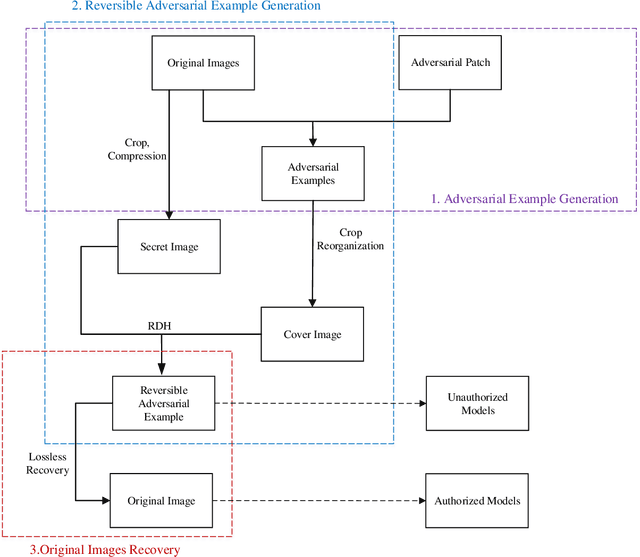

Recently, studies have indicated that adversarial attacks pose a threat to deep learning systems. However, when there are only adversarial examples, people cannot get the original images, so there is research on reversible adversarial attacks. However, the existing strategies are aimed at invisible adversarial perturbation, and do not consider the case of locally visible adversarial perturbation. In this article, we generate reversible adversarial examples for local visual adversarial perturbation, and use reversible data embedding technology to embed the information needed to restore the original image into the adversarial examples to generate examples that are both adversarial and reversible. Experiments on ImageNet dataset show that our method can restore the original image losslessly while ensuring the attack capability.
Performance Effectiveness of Multimedia Information Search Using the Epsilon-Greedy Algorithm
Nov 22, 2019


In the search and retrieval of multimedia objects, it is impractical to either manually or automatically extract the contents for indexing since most of the multimedia contents are not machine extractable, while manual extraction tends to be highly laborious and time-consuming. However, by systematically capturing and analyzing the feedback patterns of human users, vital information concerning the multimedia contents can be harvested for effective indexing and subsequent search. By learning from the human judgment and mental evaluation of users, effective search indices can be gradually developed and built up, and subsequently be exploited to find the most relevant multimedia objects. To avoid hovering around a local maximum, we apply the epsilon-greedy method to systematically explore the search space. Through such methodic exploration, we show that the proposed approach is able to guarantee that the most relevant objects can always be discovered, even though initially it may have been overlooked or not regarded as relevant. The search behavior of the present approach is quantitatively analyzed, and closed-form expressions are obtained for the performance of two variants of the epsilon-greedy algorithm, namely EGSE-A and EGSE-B. Simulations and experiments on real data set have been performed which show good agreement with the theoretical findings. The present method is able to leverage exploration in an effective way to significantly raise the performance of multimedia information search, and enables the certain discovery of relevant objects which may be otherwise undiscoverable.
Alignment Attention by Matching Key and Query Distributions
Oct 25, 2021

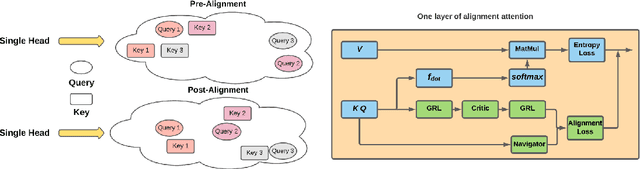
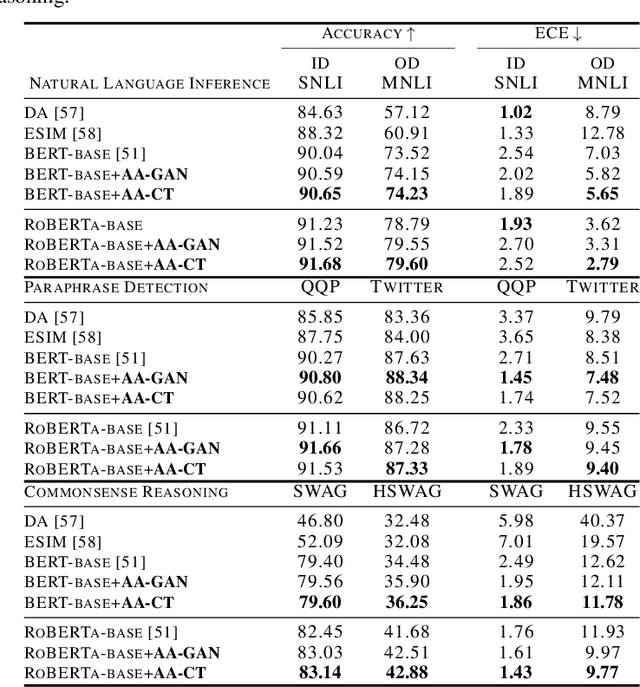
The neural attention mechanism has been incorporated into deep neural networks to achieve state-of-the-art performance in various domains. Most such models use multi-head self-attention which is appealing for the ability to attend to information from different perspectives. This paper introduces alignment attention that explicitly encourages self-attention to match the distributions of the key and query within each head. The resulting alignment attention networks can be optimized as an unsupervised regularization in the existing attention framework. It is simple to convert any models with self-attention, including pre-trained ones, to the proposed alignment attention. On a variety of language understanding tasks, we show the effectiveness of our method in accuracy, uncertainty estimation, generalization across domains, and robustness to adversarial attacks. We further demonstrate the general applicability of our approach on graph attention and visual question answering, showing the great potential of incorporating our alignment method into various attention-related tasks.