 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxon: A Synthesizing Superoptimizer for Tensor Programs
Jun 24, 2026Writing high performance kernels for AI accelerators requires deep expertise in tiling, instruction selection, data layout, and operator fusion placing a significant burden on programmers. In this paper, we focus on tile based AI accelerator programs and present Axon, a synthesizing superoptimizer for tensor programs: it uses program synthesis to automatically generate target instructions from semantics specifications, and explores semantically equivalent program variants to select the best performing kernel empirically. Axon discovers algebraic transformations by propagating operators through computation graphs and uses SMT over unbounded tensors to guarantee that all transformations preserve semantics without requiring hand crafted rewrite rules. It then lowers tensor operations to target ISA instructions, explores tiling configurations constrained by hardware descriptions, and fuses operators and instructions to minimize memory traffic.
Ekka: Automated Diagnosis of Silent Errors in LLM Inference
Jun 03, 2026LLM serving frameworks are quickly evolving with a complex software stack and a vast number of optimizations. The rapid development process can introduce silent errors where output quality silently degrades without any explicit error signals. Diagnosing silent errors is notoriously difficult due to the substantial semantic gap between the high-level symptoms and the low-level root causes. We observe that diagnosis of silent errors can be effectively framed as a differential debugging problem by leveraging the existence of semantically correct reference implementations. We propose Ekka, an automated diagnosis system that identifies root causes by systematically aligning and comparing intermediate execution states between a target and a reference framework. We constructed a benchmark of real-world silent errors from popular serving frameworks, where Ekka shows 80% pass@1 diagnosis accuracy and 88% pass@5 diagnosis accuracy, outperforming state-of-the-art systems. Ekka also diagnoses 4 new silent errors from serving frameworks, all of which have been confirmed by the developers.
TTrace: Lightweight Error Checking and Diagnosis for Distributed Training
Jun 10, 2025Distributed training is essential for scaling the training of large neural network models, such as large language models (LLMs), across thousands of GPUs. However, the complexity of distributed training programs makes them particularly prone to silent bugs, which do not produce explicit error signal but lead to incorrect training outcome. Effectively detecting and localizing such silent bugs in distributed training is challenging. Common debugging practice using metrics like training loss or gradient norm curves can be inefficient and ineffective. Additionally, obtaining intermediate tensor values and determining whether they are correct during silent bug localization is difficult, particularly in the context of low-precision training. To address those challenges, we design and implement TTrace, the first system capable of detecting and localizing silent bugs in distributed training. TTrace collects intermediate tensors from distributing training in a fine-grained manner and compares them against those from a trusted single-device reference implementation. To properly compare the floating-point values in the tensors, we propose novel mathematical analysis that provides a guideline for setting thresholds, enabling TTrace to distinguish bug-induced errors from floating-point round-off errors. Experimental results demonstrate that TTrace effectively detects 11 existing bugs and 3 new bugs in the widely used Megatron-LM framework, while requiring fewer than 10 lines of code change. TTrace is effective in various training recipes, including low-precision recipes involving BF16 and FP8.
Adversarial Examples Detection with Enhanced Image Difference Features based on Local Histogram Equalization
May 08, 2023Deep Neural Networks (DNNs) have recently made significant progress in many fields. However, studies have shown that DNNs are vulnerable to adversarial examples, where imperceptible perturbations can greatly mislead DNNs even if the full underlying model parameters are not accessible. Various defense methods have been proposed, such as feature compression and gradient masking. However, numerous studies have proven that previous methods create detection or defense against certain attacks, which renders the method ineffective in the face of the latest unknown attack methods. The invisibility of adversarial perturbations is one of the evaluation indicators for adversarial example attacks, which also means that the difference in the local correlation of high-frequency information in adversarial examples and normal examples can be used as an effective feature to distinguish the two. Therefore, we propose an adversarial example detection framework based on a high-frequency information enhancement strategy, which can effectively extract and amplify the feature differences between adversarial examples and normal examples. Experimental results show that the feature augmentation module can be combined with existing detection models in a modular way under this framework. Improve the detector's performance and reduce the deployment cost without modifying the existing detection model.
Adversarial Example Defense via Perturbation Grading Strategy
Dec 16, 2022Deep Neural Networks have been widely used in many fields. However, studies have shown that DNNs are easily attacked by adversarial examples, which have tiny perturbations and greatly mislead the correct judgment of DNNs. Furthermore, even if malicious attackers cannot obtain all the underlying model parameters, they can use adversarial examples to attack various DNN-based task systems. Researchers have proposed various defense methods to protect DNNs, such as reducing the aggressiveness of adversarial examples by preprocessing or improving the robustness of the model by adding modules. However, some defense methods are only effective for small-scale examples or small perturbations but have limited defense effects for adversarial examples with large perturbations. This paper assigns different defense strategies to adversarial perturbations of different strengths by grading the perturbations on the input examples. Experimental results show that the proposed method effectively improves defense performance. In addition, the proposed method does not modify any task model, which can be used as a preprocessing module, which significantly reduces the deployment cost in practical applications.
Reversible adversarial examples against local visual perturbation
Oct 06, 2021
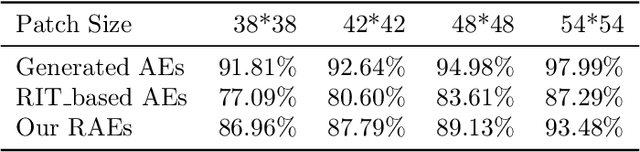
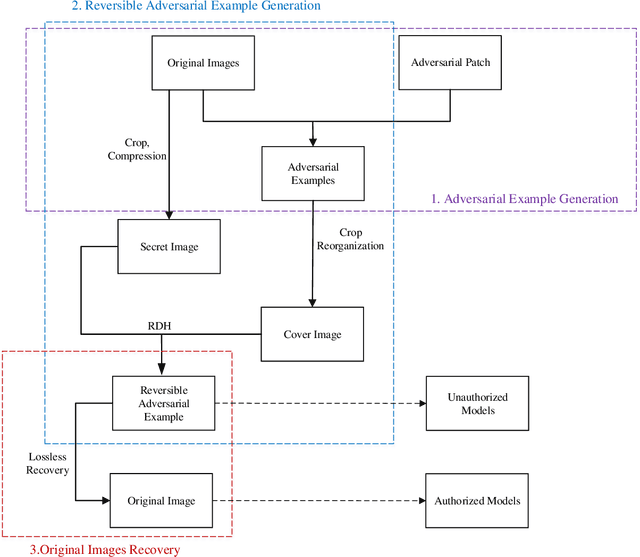

Recently, studies have indicated that adversarial attacks pose a threat to deep learning systems. However, when there are only adversarial examples, people cannot get the original images, so there is research on reversible adversarial attacks. However, the existing strategies are aimed at invisible adversarial perturbation, and do not consider the case of locally visible adversarial perturbation. In this article, we generate reversible adversarial examples for local visual adversarial perturbation, and use reversible data embedding technology to embed the information needed to restore the original image into the adversarial examples to generate examples that are both adversarial and reversible. Experiments on ImageNet dataset show that our method can restore the original image losslessly while ensuring the attack capability.