 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Waiting but not Aging: Age-of-Information and Utility Optimization Under the Pull Model
Dec 17, 2019
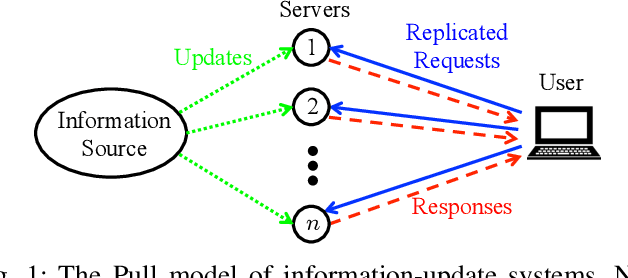
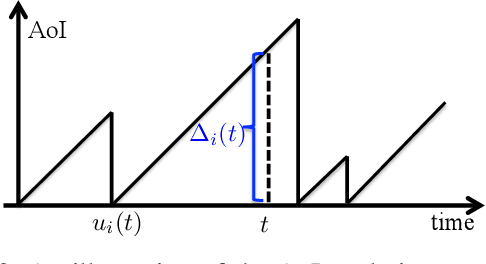
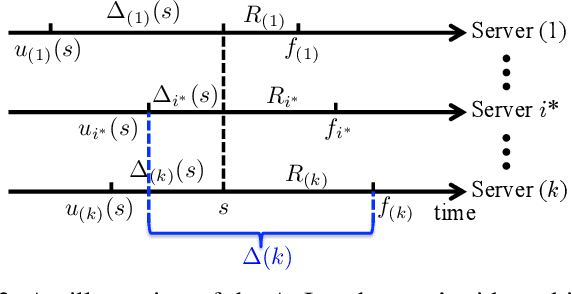
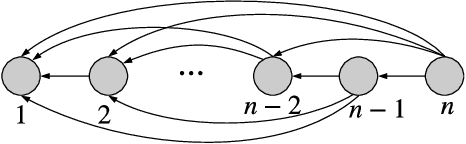
The Age-of-Information (AoI) has recently been proposed as an important metric for investigating the timeliness performance in information-update systems. In this paper, we introduce a new Pull model and study the AoI optimization problem under replication schemes. Interestingly, we find that under this new Pull model, replication schemes capture a novel tradeoff between different levels of information freshness and different response times across the servers, which can be exploited to minimize the expected AoI at the user's side. Specifically, assuming Poisson updating process for the servers and exponentially distributed response time, we derive a closed-form formula for computing the expected AoI and obtain the optimal number of responses to wait for to minimize the expected AoI. Then, we extend our analysis to the setting where the user aims to maximize the AoI-based utility, which represents the user's satisfaction level with respect to freshness of the received information. Furthermore, we consider a more realistic scenario where the user has no knowledge of the system. In this case, we reformulate the utility maximization problem as a stochastic Multi-Armed Bandit problem with side observations and leverage the unique structure of the problem to design learning algorithms with improved performance guarantees. Finally, we conduct extensive simulations to elucidate our theoretical results and compare the performance of different algorithms. Our findings reveal that under the Pull model, waiting for more than one response can significantly reduce the AoI and improve the AoI-based utility in most scenarios.
GFlowNet Foundations
Nov 17, 2021
Generative Flow Networks (GFlowNets) have been introduced as a method to sample a diverse set of candidates in an active learning context, with a training objective that makes them approximately sample in proportion to a given reward function. In this paper, we show a number of additional theoretical properties of GFlowNets. They can be used to estimate joint probability distributions and the corresponding marginal distributions where some variables are unspecified and, of particular interest, can represent distributions over composite objects like sets and graphs. GFlowNets amortize the work typically done by computationally expensive MCMC methods in a single but trained generative pass. They could also be used to estimate partition functions and free energies, conditional probabilities of supersets (supergraphs) given a subset (subgraph), as well as marginal distributions over all supersets (supergraphs) of a given set (graph). We introduce variations enabling the estimation of entropy and mutual information, sampling from a Pareto frontier, connections to reward-maximizing policies, and extensions to stochastic environments, continuous actions and modular energy functions.
A Modified Dynamic Time Warping (MDTW) Approach and Innovative Average Non-Self Match Distance (ANSD) Method for Anomaly Detection in ECG Recordings
Nov 01, 2021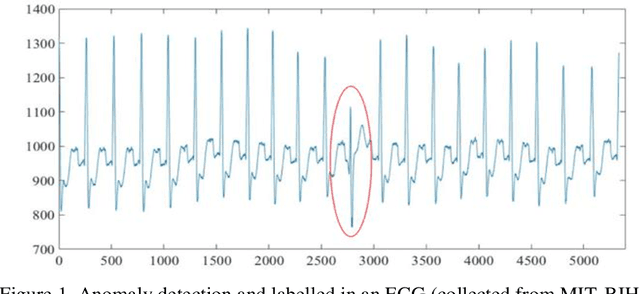
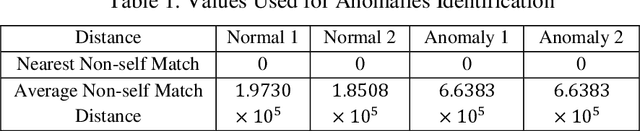
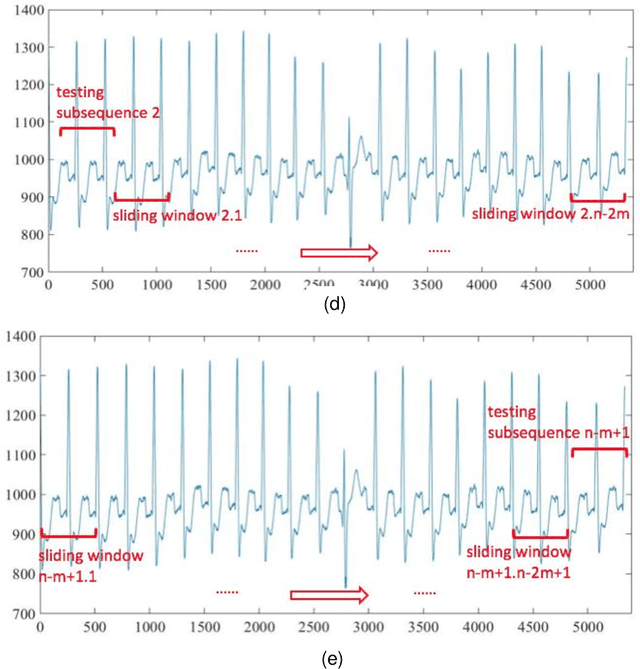
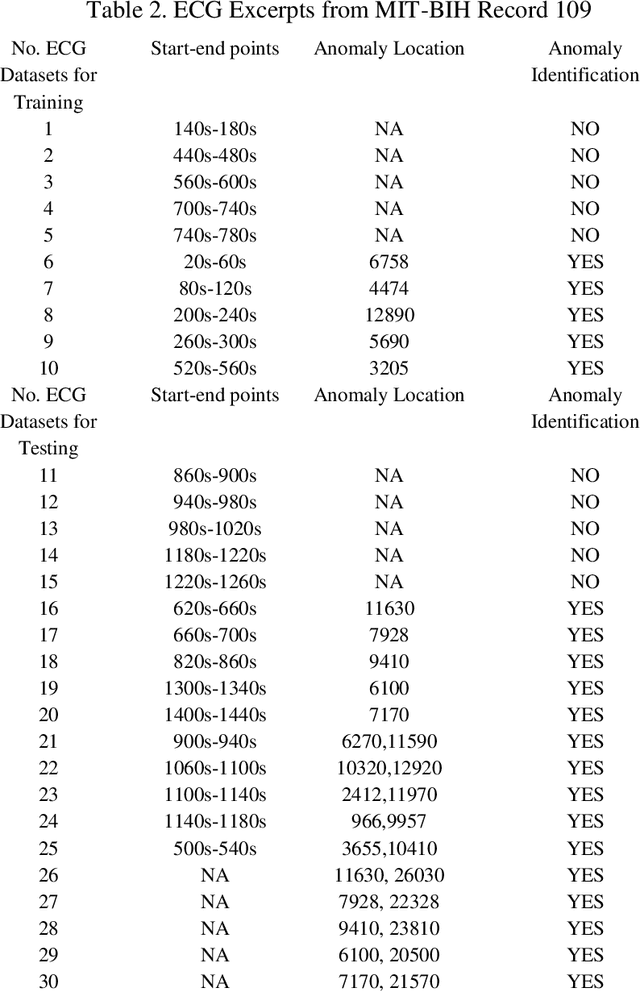
ECGs objectively reflects the working conditions of the hearts as these signals contain vast physiological and pathological information. In this work, in order to improve the efficiency and accuracy of "best so far" time series analysis-based ECG anomaly detection methods, a novel method, comprising a modified dynamic time warping (MDTW) and an innovative average non-self match distance (ANSD) measure, is proposed for ECG anomaly detection. To evaluate the performance of the proposed method, the proposed method is applied to real ECG data selected from the MIT-BIH heartbeat database. To provide a reference for comparison, two existing anomaly detection methods, namely, brute force discord discovery (BFDD) and adaptive window discord discovery (AWDD), are also applied to the same data. The experimental results show that our proposed method outperforms BFDD and AWD.
Epidemic inference through generative neural networks
Nov 08, 2021
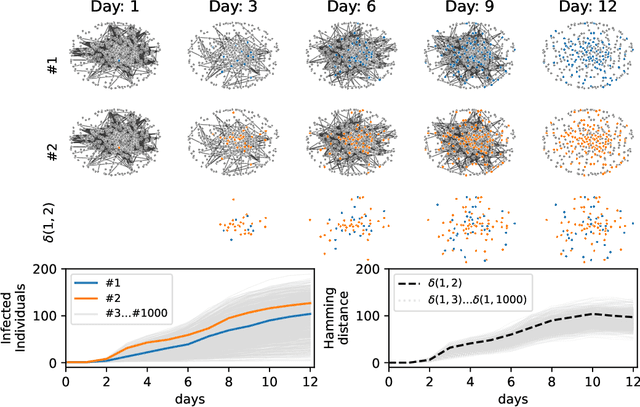
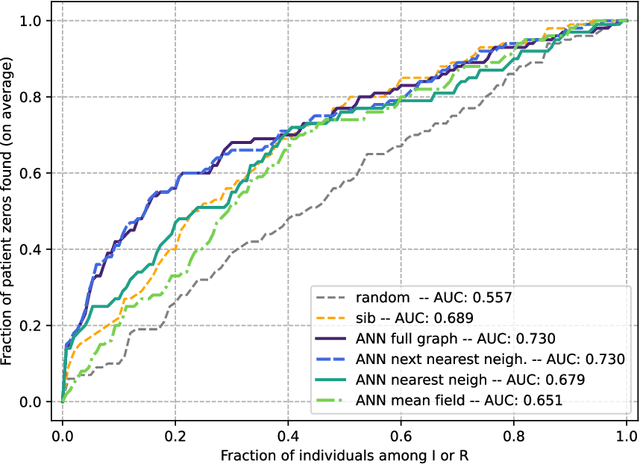
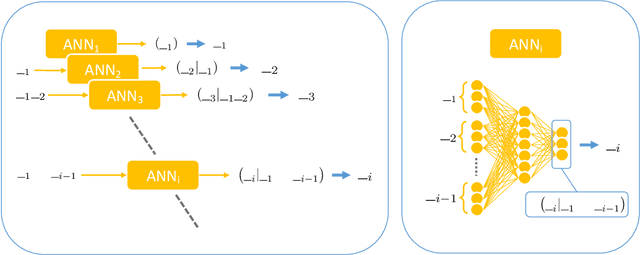
Reconstructing missing information in epidemic spreading on contact networks can be essential in prevention and containment strategies. For instance, identifying and warning infective but asymptomatic individuals (e.g., manual contact tracing) helped contain outbreaks in the COVID-19 pandemic. The number of possible epidemic cascades typically grows exponentially with the number of individuals involved. The challenge posed by inference problems in the epidemics processes originates from the difficulty of identifying the almost negligible subset of those compatible with the evidence (for instance, medical tests). Here we present a new generative neural networks framework that can sample the most probable infection cascades compatible with observations. Moreover, the framework can infer the parameters governing the spreading of infections. The proposed method obtains better or comparable results with existing methods on the patient zero problem, risk assessment, and inference of infectious parameters in synthetic and real case scenarios like spreading infections in workplaces and hospitals.
Lightweight Image Super-Resolution with Information Multi-distillation Network
Sep 26, 2019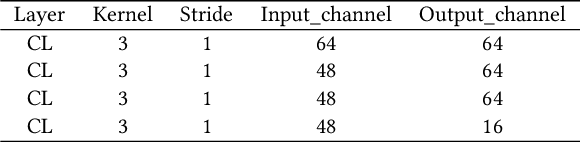
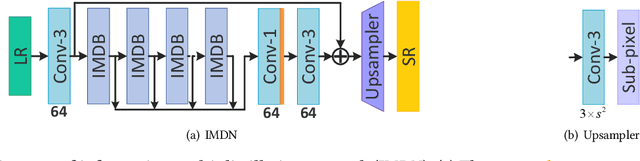
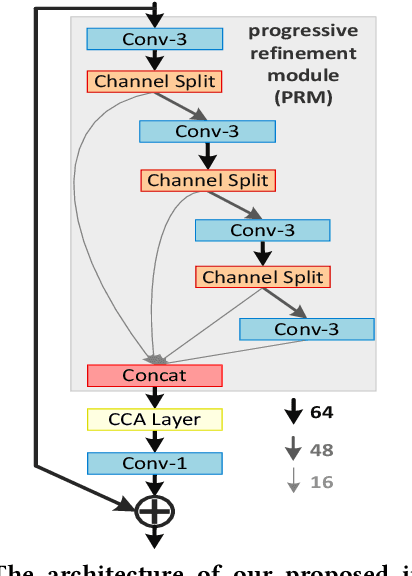

In recent years, single image super-resolution (SISR) methods using deep convolution neural network (CNN) have achieved impressive results. Thanks to the powerful representation capabilities of the deep networks, numerous previous ways can learn the complex non-linear mapping between low-resolution (LR) image patches and their high-resolution (HR) versions. However, excessive convolutions will limit the application of super-resolution technology in low computing power devices. Besides, super-resolution of any arbitrary scale factor is a critical issue in practical applications, which has not been well solved in the previous approaches. To address these issues, we propose a lightweight information multi-distillation network (IMDN) by constructing the cascaded information multi-distillation blocks (IMDB), which contains distillation and selective fusion parts. Specifically, the distillation module extracts hierarchical features step-by-step, and fusion module aggregates them according to the importance of candidate features, which is evaluated by the proposed contrast-aware channel attention mechanism. To process real images with any sizes, we develop an adaptive cropping strategy (ACS) to super-resolve block-wise image patches using the same well-trained model. Extensive experiments suggest that the proposed method performs favorably against the state-of-the-art SR algorithms in term of visual quality, memory footprint, and inference time. Code is available at \url{https://github.com/Zheng222/IMDN}.
Silhouette based View embeddings for Gait Recognition under Multiple Views
Aug 12, 2021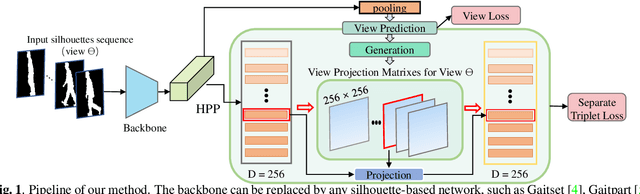
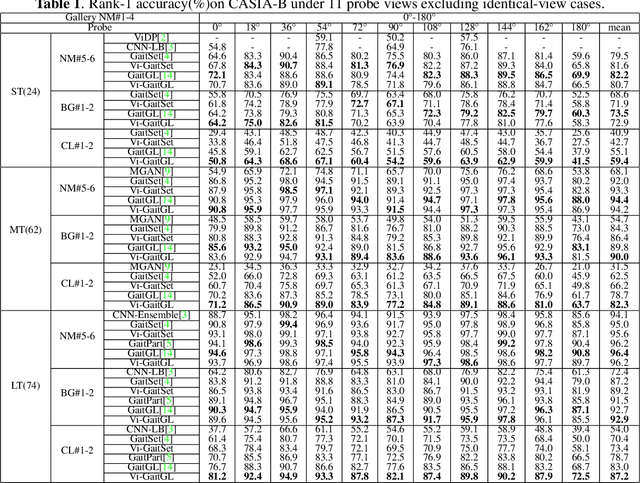

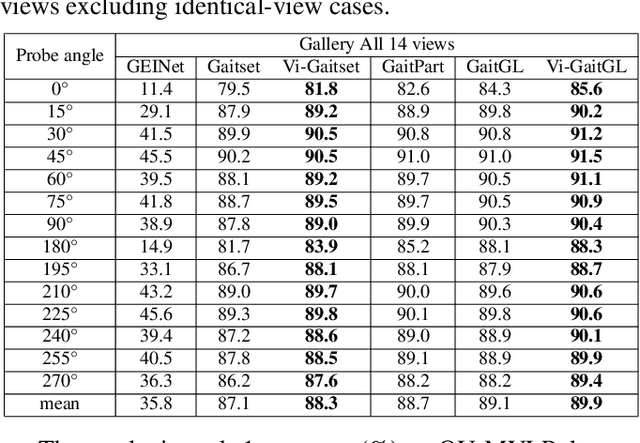
Gait recognition under multiple views is an important computer vision and pattern recognition task. In the emerging convolutional neural network based approaches, the information of view angle is ignored to some extent. Instead of direct view estimation and training view-specific recognition models, we propose a compatible framework that can embed view information into existing architectures of gait recognition. The embedding is simply achieved by a selective projection layer. Experimental results on two large public datasets show that the proposed framework is very effective.
DA-LMR: A Robust Lane Markings Representation for Data Association Methods
Nov 17, 2021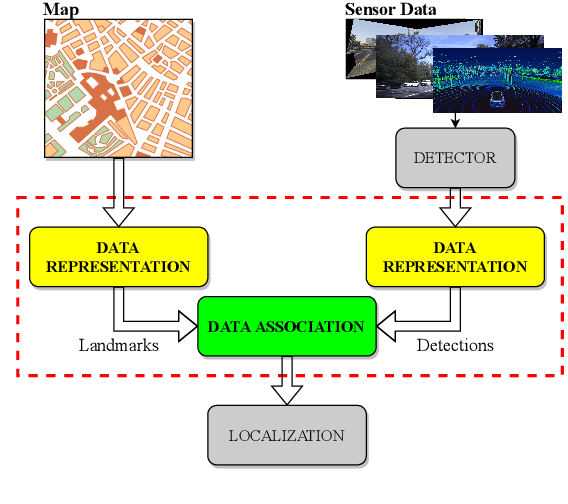
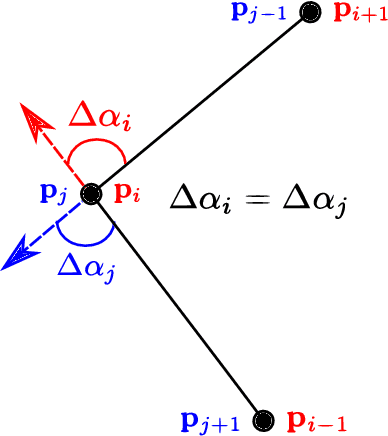

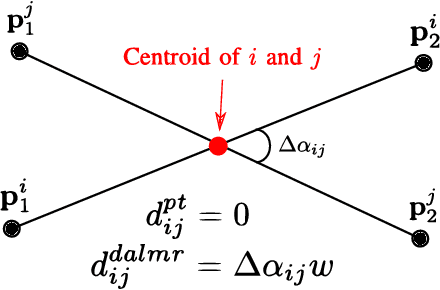
While complete localization approaches are widely studied in the literature, their data association and data representation subprocesses usually go unnoticed. However, both are a key part of the final pose estimation. In this work, we present DA-LMR (Delta-Angle Lane Markings Representation), a robust data representation in the context of localization approaches. We propose a representation of lane markings that encodes how a curve changes in each point and includes this information in an additional dimension, thus providing a more detailed geometric structure description of the data. We also propose DC-SAC (Distance-Compatible Sample Consensus), a data association method. This is a heuristic version of RANSAC that dramatically reduces the hypothesis space by distance compatibility restrictions. We compare the presented methods with some state-of-the-art data representation and data association approaches in different noisy scenarios. The DA-LMR and DC-SAC produce the most promising combination among those compared, reaching 98.1% in precision and 99.7% in recall for noisy data with 0.5m of standard deviation.
Trustworthy Multimodal Regression with Mixture of Normal-inverse Gamma Distributions
Nov 11, 2021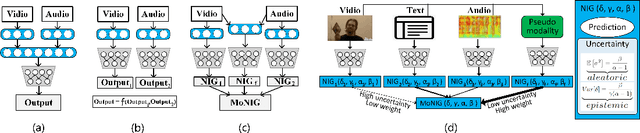
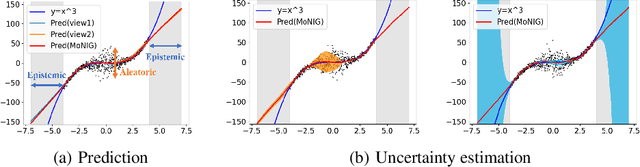
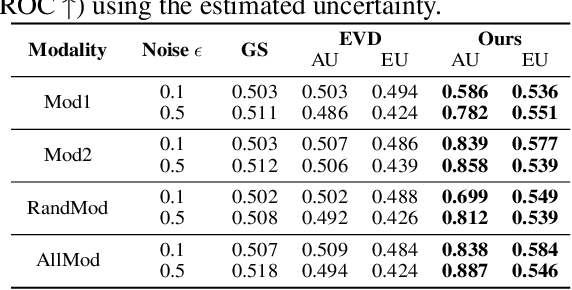
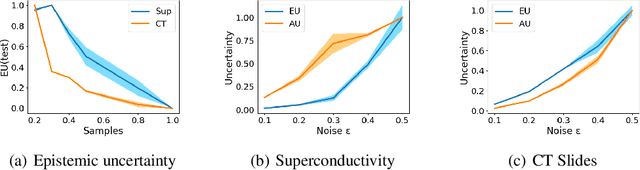
Multimodal regression is a fundamental task, which integrates the information from different sources to improve the performance of follow-up applications. However, existing methods mainly focus on improving the performance and often ignore the confidence of prediction for diverse situations. In this study, we are devoted to trustworthy multimodal regression which is critical in cost-sensitive domains. To this end, we introduce a novel Mixture of Normal-Inverse Gamma distributions (MoNIG) algorithm, which efficiently estimates uncertainty in principle for adaptive integration of different modalities and produces a trustworthy regression result. Our model can be dynamically aware of uncertainty for each modality, and also robust for corrupted modalities. Furthermore, the proposed MoNIG ensures explicitly representation of (modality-specific/global) epistemic and aleatoric uncertainties, respectively. Experimental results on both synthetic and different real-world data demonstrate the effectiveness and trustworthiness of our method on various multimodal regression tasks (e.g., temperature prediction for superconductivity, relative location prediction for CT slices, and multimodal sentiment analysis).
TransZero: Attribute-guided Transformer for Zero-Shot Learning
Dec 03, 2021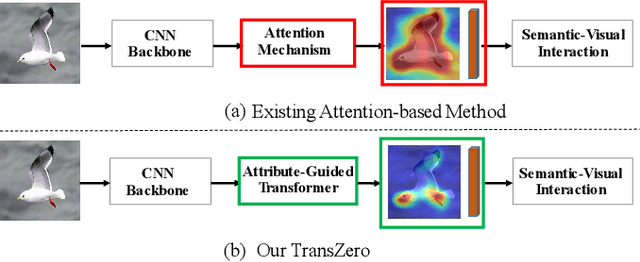
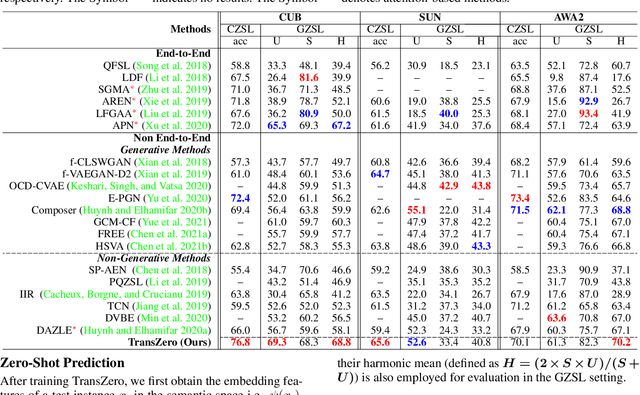
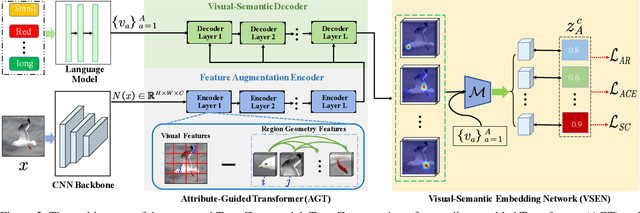
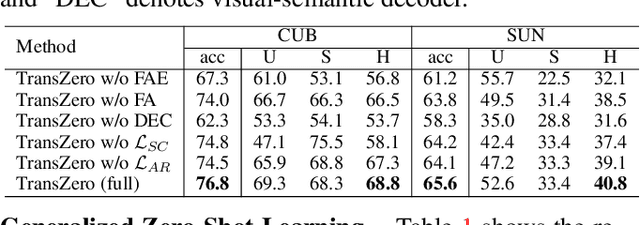
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen ones. Semantic knowledge is learned from attribute descriptions shared between different classes, which act as strong priors for localizing object attributes that represent discriminative region features, enabling significant visual-semantic interaction. Although some attention-based models have attempted to learn such region features in a single image, the transferability and discriminative attribute localization of visual features are typically neglected. In this paper, we propose an attribute-guided Transformer network, termed TransZero, to refine visual features and learn attribute localization for discriminative visual embedding representations in ZSL. Specifically, TransZero takes a feature augmentation encoder to alleviate the cross-dataset bias between ImageNet and ZSL benchmarks, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. To learn locality-augmented visual features, TransZero employs a visual-semantic decoder to localize the image regions most relevant to each attribute in a given image, under the guidance of semantic attribute information. Then, the locality-augmented visual features and semantic vectors are used to conduct effective visual-semantic interaction in a visual-semantic embedding network. Extensive experiments show that TransZero achieves the new state of the art on three ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero}.
IV-GNN : Interval Valued Data Handling Using Graph Neural Network
Nov 17, 2021
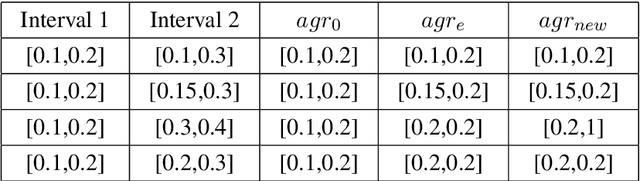

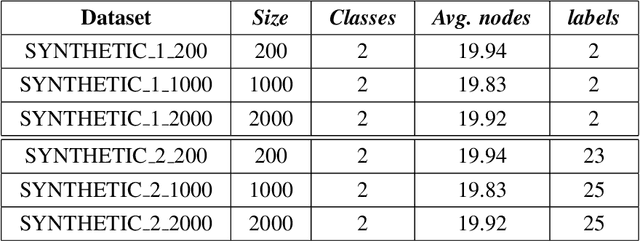
Graph Neural Network (GNN) is a powerful tool to perform standard machine learning on graphs. To have a Euclidean representation of every node in the Non-Euclidean graph-like data, GNN follows neighbourhood aggregation and combination of information recursively along the edges of the graph. Despite having many GNN variants in the literature, no model can deal with graphs having nodes with interval-valued features. This article proposes an Interval-ValuedGraph Neural Network, a novel GNN model where, for the first time, we relax the restriction of the feature space being countable. Our model is much more general than existing models as any countable set is always a subset of the universal set $R^{n}$, which is uncountable. Here, to deal with interval-valued feature vectors, we propose a new aggregation scheme of intervals and show its expressive power to capture different interval structures. We validate our theoretical findings about our model for graph classification tasks by comparing its performance with those of the state-of-the-art models on several benchmark network and synthetic datasets.