 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Federated Deep Learning with Bayesian Privacy
Sep 27, 2021
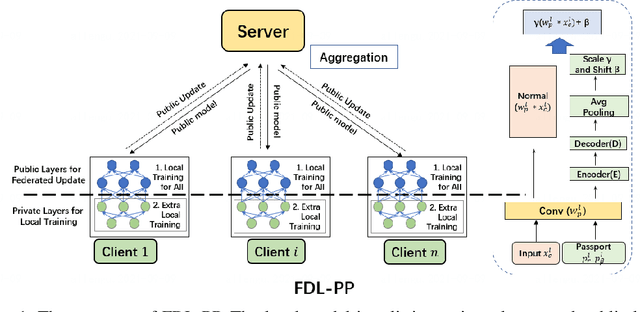
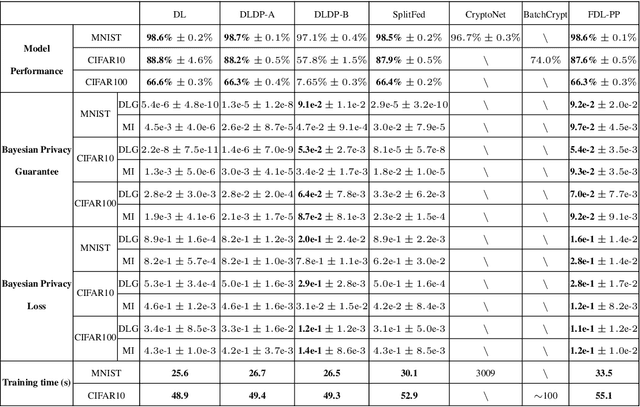
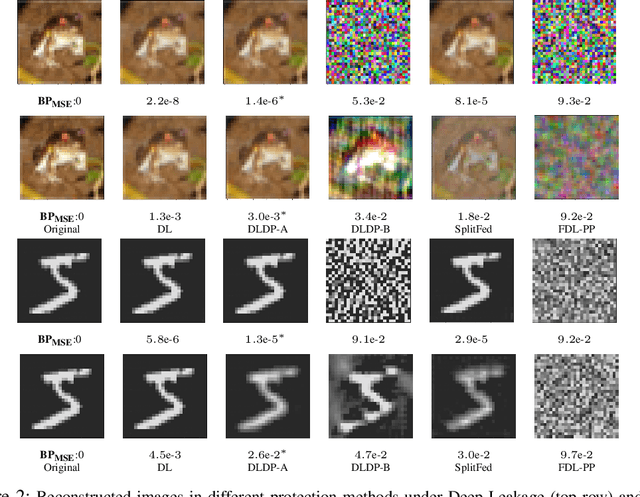
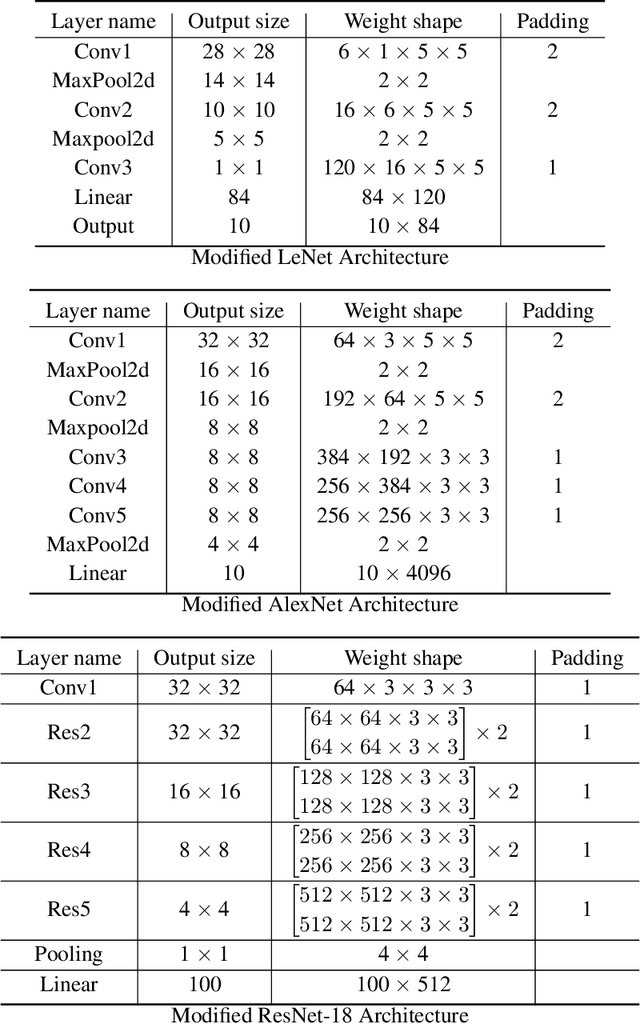
Federated learning (FL) aims to protect data privacy by cooperatively learning a model without sharing private data among users. For Federated Learning of Deep Neural Network with billions of model parameters, existing privacy-preserving solutions are unsatisfactory. Homomorphic encryption (HE) based methods provide secure privacy protections but suffer from extremely high computational and communication overheads rendering it almost useless in practice . Deep learning with Differential Privacy (DP) was implemented as a practical learning algorithm at a manageable cost in complexity. However, DP is vulnerable to aggressive Bayesian restoration attacks as disclosed in the literature and demonstrated in experimental results of this work. To address the aforementioned perplexity, we propose a novel Bayesian Privacy (BP) framework which enables Bayesian restoration attacks to be formulated as the probability of reconstructing private data from observed public information. Specifically, the proposed BP framework accurately quantifies privacy loss by Kullback-Leibler (KL) Divergence between the prior distribution about the privacy data and the posterior distribution of restoration private data conditioning on exposed information}. To our best knowledge, this Bayesian Privacy analysis is the first to provides theoretical justification of secure privacy-preserving capabilities against Bayesian restoration attacks. As a concrete use case, we demonstrate that a novel federated deep learning method using private passport layers is able to simultaneously achieve high model performance, privacy-preserving capability and low computational complexity. Theoretical analysis is in accordance with empirical measurements of information leakage extensively experimented with a variety of DNN networks on image classification MNIST, CIFAR10, and CIFAR100 datasets.
Unpacking the Black Box: Regulating Algorithmic Decisions
Oct 05, 2021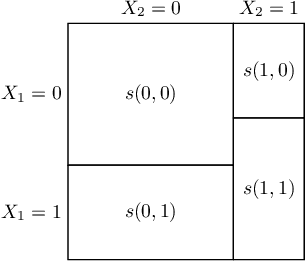
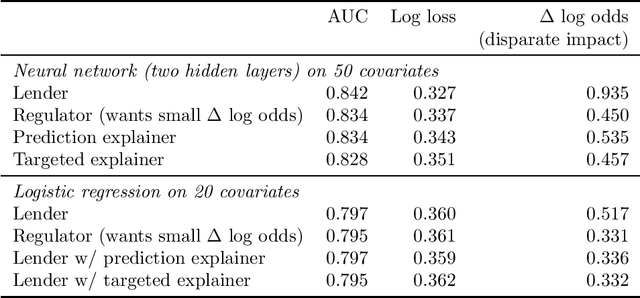
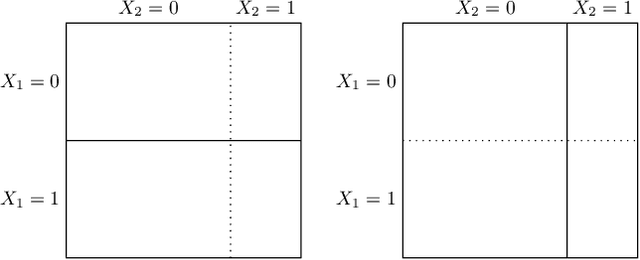
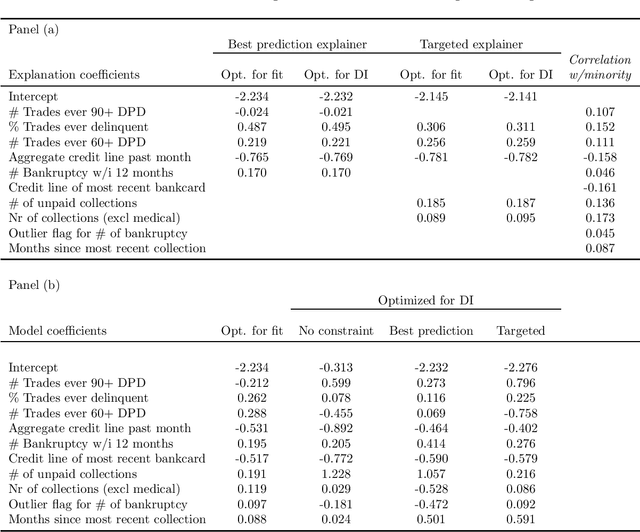
We characterize optimal oversight of algorithms in a world where an agent designs a complex prediction function but a principal is limited in the amount of information she can learn about the prediction function. We show that limiting agents to prediction functions that are simple enough to be fully transparent is inefficient as long as the bias induced by misalignment between principal's and agent's preferences is small relative to the uncertainty about the true state of the world. Algorithmic audits can improve welfare, but the gains depend on the design of the audit tools. Tools that focus on minimizing overall information loss, the focus of many post-hoc explainer tools, will generally be inefficient since they focus on explaining the average behavior of the prediction function rather than sources of mis-prediction, which matter for welfare-relevant outcomes. Targeted tools that focus on the source of incentive misalignment, e.g., excess false positives or racial disparities, can provide first-best solutions. We provide empirical support for our theoretical findings using an application in consumer lending.
Scheduling Servers with Stochastic Bilinear Rewards
Dec 13, 2021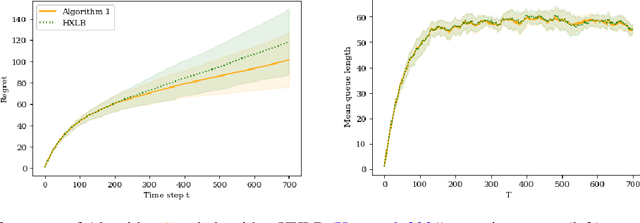
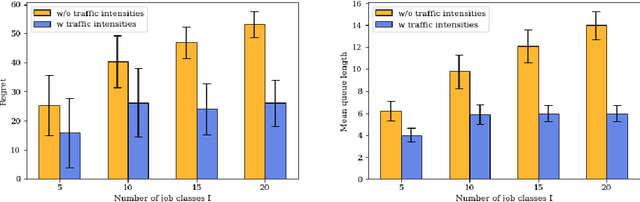
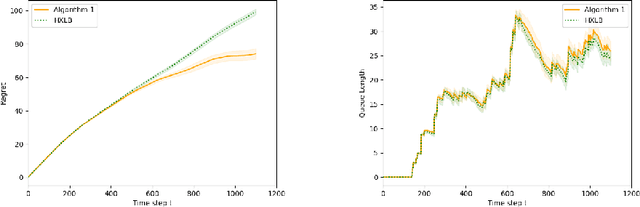
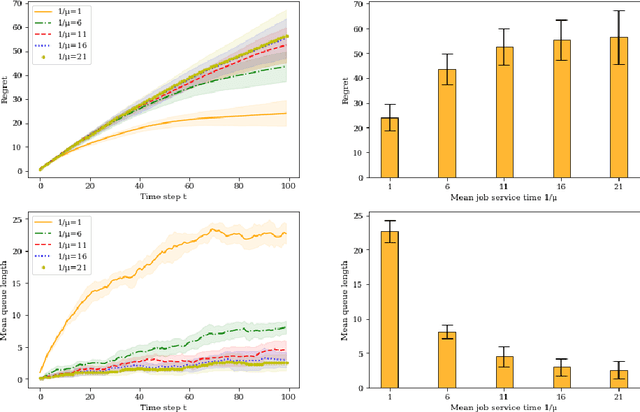
In this paper we study a multi-class, multi-server queueing system with stochastic rewards of job-server assignments following a bilinear model in feature vectors representing jobs and servers. Our goal is regret minimization against an oracle policy that has a complete information about system parameters. We propose a scheduling algorithm that uses a linear bandit algorithm along with dynamic allocation of jobs to servers. For the baseline setting, in which mean job service times are identical for all jobs, we show that our algorithm has a sub-linear regret, as well as a sub-linear bound on the mean queue length, in the horizon time. We further show that similar bounds hold under more general assumptions, allowing for non-identical mean job service times for different job classes and a time-varying set of server classes. We also show that better regret and mean queue length bounds can be guaranteed by an algorithm having access to traffic intensities of job classes. We present results of numerical experiments demonstrating how regret and mean queue length of our algorithms depend on various system parameters and compare their performance against a previously proposed algorithm using synthetic randomly generated data and a real-world cluster computing data trace.
Capturing scattered discriminative information using a deep architecture in acoustic scene classification
Jul 09, 2020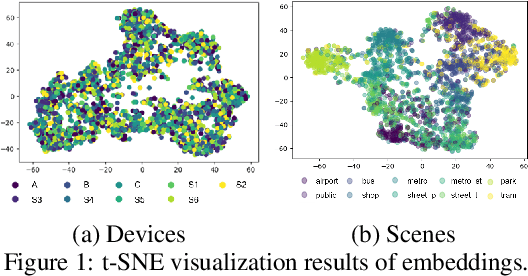
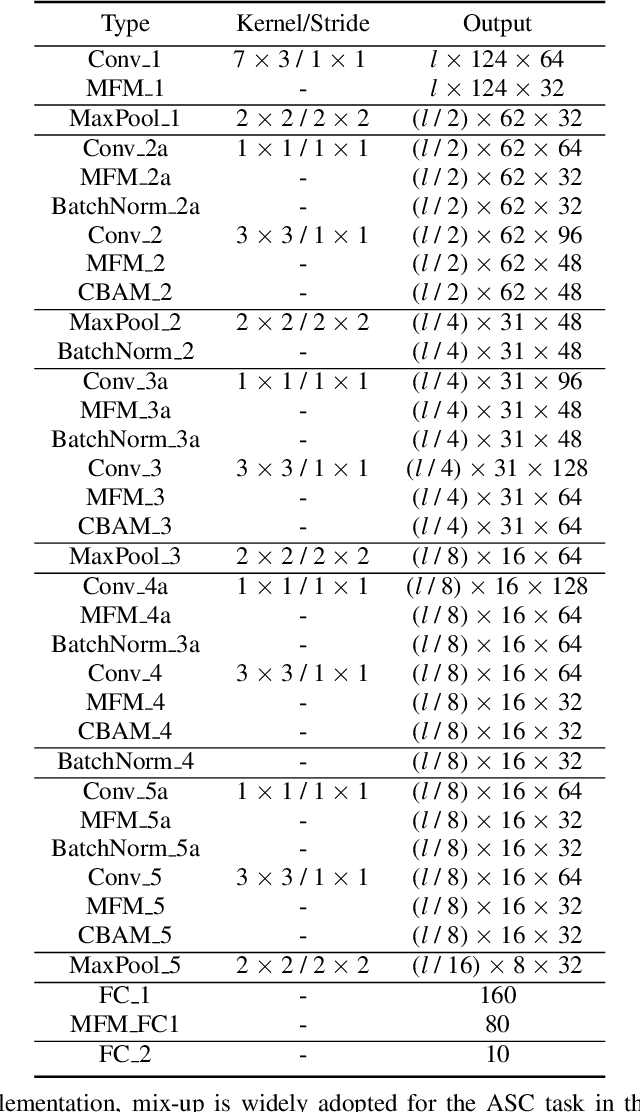
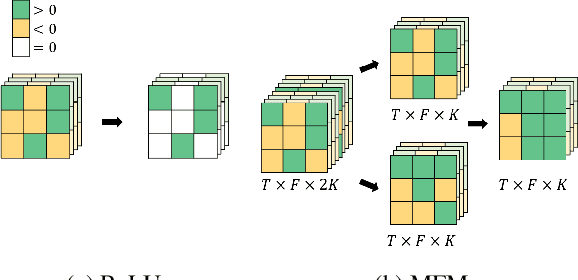
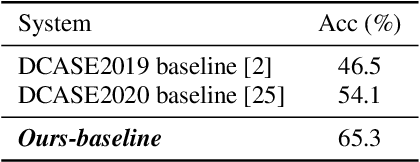
Frequently misclassified pairs of classes that share many common acoustic properties exist in acoustic scene classification (ASC). To distinguish such pairs of classes, trivial details scattered throughout the data could be vital clues. However, these details are less noticeable and are easily removed using conventional non-linear activations (e.g. ReLU). Furthermore, making design choices to emphasize trivial details can easily lead to overfitting if the system is not sufficiently generalized. In this study, based on the analysis of the ASC task's characteristics, we investigate various methods to capture discriminative information and simultaneously mitigate the overfitting problem. We adopt a max feature map method to replace conventional non-linear activations in a deep neural network, and therefore, we apply an element-wise comparison between different filters of a convolution layer's output. Two data augment methods and two deep architecture modules are further explored to reduce overfitting and sustain the system's discriminative power. Various experiments are conducted using the detection and classification of acoustic scenes and events 2020 task1-a dataset to validate the proposed methods. Our results show that the proposed system consistently outperforms the baseline, where the single best performing system has an accuracy of 70.4% compared to 65.1% of the baseline.
Multi-label Classification of Aircraft Heading Changes Using Neural Network to Resolve Conflicts
Sep 18, 2021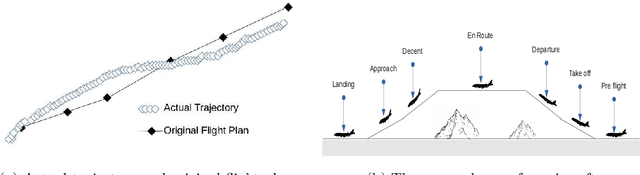

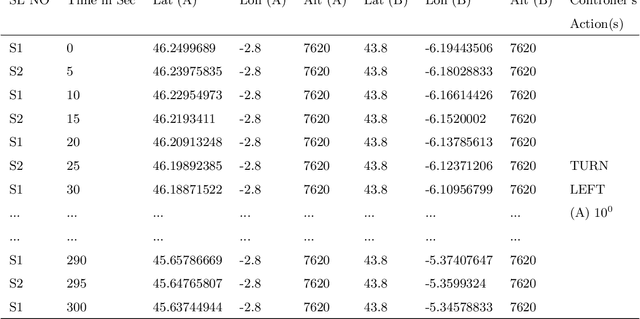
An aircraft conflict occurs when two or more aircraft cross at a certain distance at the same time. Specific air traffic controllers are assigned to solve such conflicts. A controller needs to consider various types of information in order to solve a conflict. The most common and preliminary information is the coordinate position of the involved aircraft. Additionally, a controller has to take into account more information such as flight planning, weather, restricted territory, etc. The most important challenges a controller has to face are: to think about the issues involved and make a decision in a very short time. Due to the increased number of aircraft, it is crucial to reduce the workload of the controllers and help them make quick decisions. A conflict can be solved in many ways, therefore, we consider this problem as a multi-label classification problem. In doing so, we are proposing a multi-label classification model which provides multiple heading advisories for a given conflict. This model we named CRMLnet is based on a novel application of a multi-layer neural network and helps the controllers in their decisions. When compared to other machine learning models, our CRMLnet has achieved the best results with an accuracy of 98.72% and ROC of 0.999. The simulated data set that we have developed and used in our experiments will be delivered to the research community.
MTFNet: Mutual-Transformer Fusion Network for RGB-D Salient Object Detection
Dec 02, 2021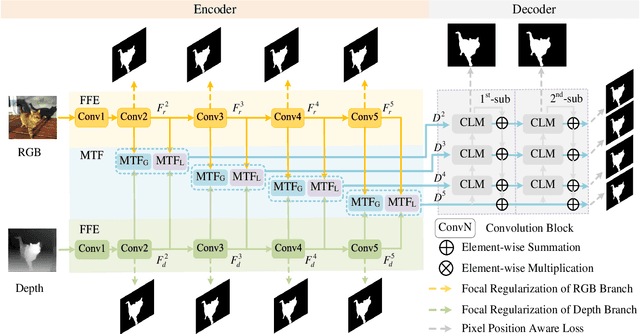
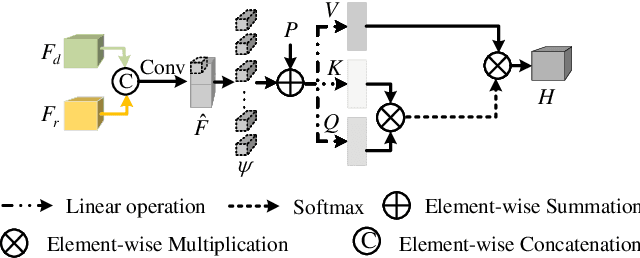
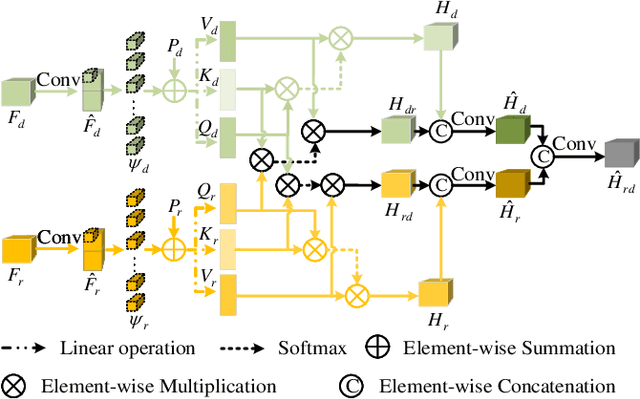
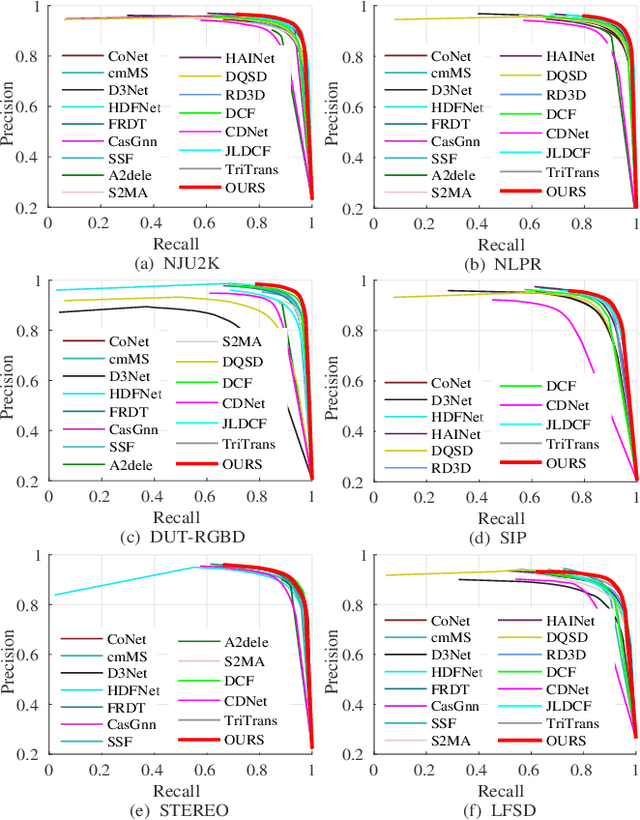
Salient object detection (SOD) on RGB-D images is an active problem in computer vision. The main challenges for RGB-D SOD problem are how to 1) extract the accurate features for RGB and Depth image data with clutter background or poor image quality and 2) explore the complementary information between RGB and Depth image data. To address these challenges, we propose a novel Mutual-Transformer Fusion Network (MTFNet) for RGB-D SOD. MTFNet contains two main modules, $i.e.$, Focal Feature Extractor (FFE) and Mutual-Transformer Fusion (MTF). FFE aims to extract the more accurate CNN features for RGB and Depth images by introducing a novel pixel-level focal regularization to guide CNN feature extractor. MTF is designed to deeply exploit the multi-modal interaction between RGB and Depth images on both coarse and fine scales. The main benefit of MTF is that it conducts the learning of intra-modality and inter-modality simultaneously and thus can achieve communication across different modalities more directly and sufficiently. Comprehensive experimental results on six public benchmarks demonstrate the superiority of our proposed MTFNet.
Meeting-Merging-Mission: A Multi-robot Coordinate Framework for Large-Scale Communication-Limited Exploration
Sep 16, 2021
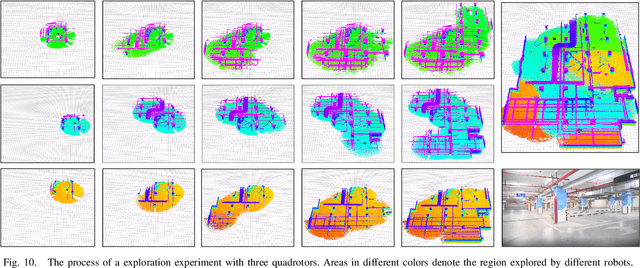
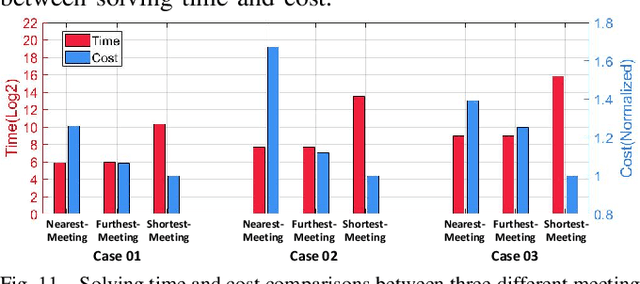
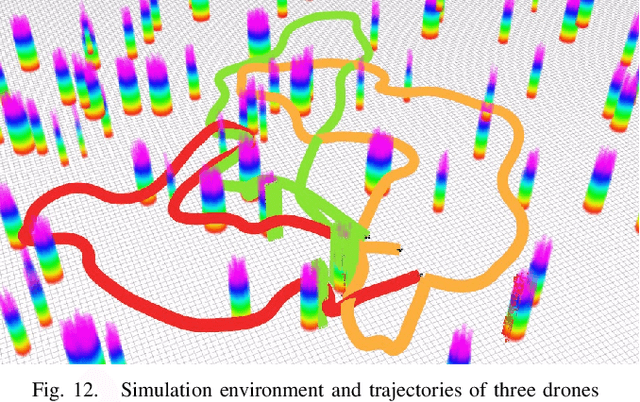
This letter presents a complete framework Meeting-Merging-Mission for multi-robot exploration under communication restriction. Considering communication is limited in both bandwidth and range in the real world, we propose a lightweight environment presentation method and an efficient cooperative exploration strategy. For lower bandwidth, each robot utilizes specific polytopes to maintains free space and super frontier information (SFI) as the source for exploration decision-making. To reduce repeated exploration, we develop a mission-based protocol that drives robots to share collected information in stable rendezvous. We also design a complete path planning scheme for both centralized and decentralized cases. To validate that our framework is practical and generic, we present an extensive benchmark and deploy our system into multi-UGV and multi-UAV platforms.
Neural-network acceleration of projection-based model-order-reduction for finite plasticity: Application to RVEs
Sep 16, 2021

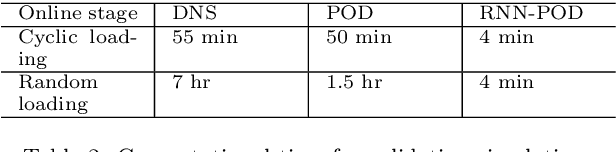
Compared to conventional projection-based model-order-reduction, its neural-network acceleration has the advantage that the online simulations are equation-free, meaning that no system of equations needs to be solved iteratively. Consequently, no stiffness matrix needs to be constructed and the stress update needs to be computed only once per increment. In this contribution, a recurrent neural network is developed to accelerate a projection-based model-order-reduction of the elastoplastic mechanical behaviour of an RVE. In contrast to a neural network that merely emulates the relation between the macroscopic deformation (path) and the macroscopic stress, the neural network acceleration of projection-based model-order-reduction preserves all microstructural information, at the price of computing this information once per increment.
Higher Order Kernel Mean Embeddings to Capture Filtrations of Stochastic Processes
Sep 08, 2021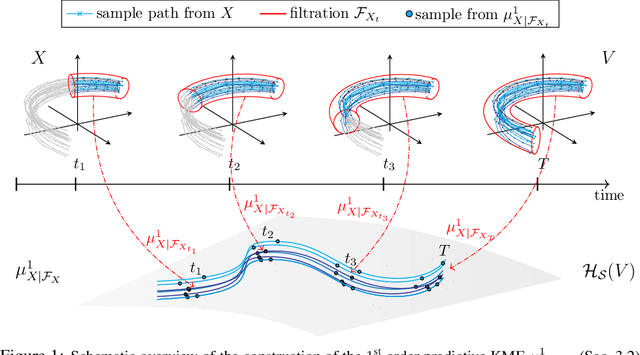


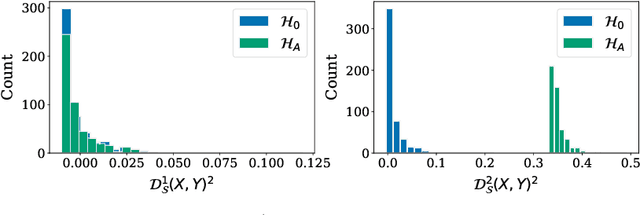
Stochastic processes are random variables with values in some space of paths. However, reducing a stochastic process to a path-valued random variable ignores its filtration, i.e. the flow of information carried by the process through time. By conditioning the process on its filtration, we introduce a family of higher order kernel mean embeddings (KMEs) that generalizes the notion of KME and captures additional information related to the filtration. We derive empirical estimators for the associated higher order maximum mean discrepancies (MMDs) and prove consistency. We then construct a filtration-sensitive kernel two-sample test able to pick up information that gets missed by the standard MMD test. In addition, leveraging our higher order MMDs we construct a family of universal kernels on stochastic processes that allows to solve real-world calibration and optimal stopping problems in quantitative finance (such as the pricing of American options) via classical kernel-based regression methods. Finally, adapting existing tests for conditional independence to the case of stochastic processes, we design a causal-discovery algorithm to recover the causal graph of structural dependencies among interacting bodies solely from observations of their multidimensional trajectories.
DORA: Distributed Online Risk-Aware Explorer
Sep 29, 2021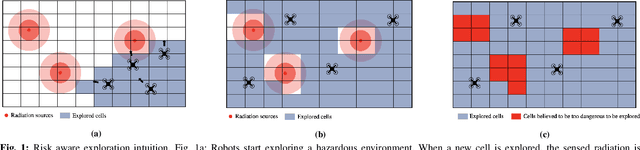
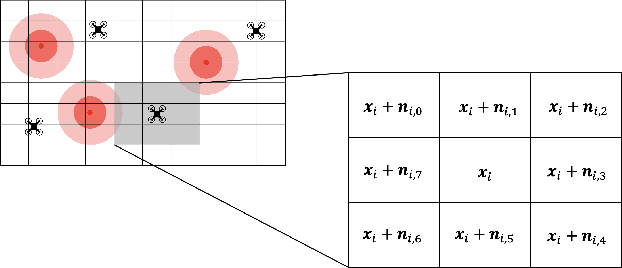

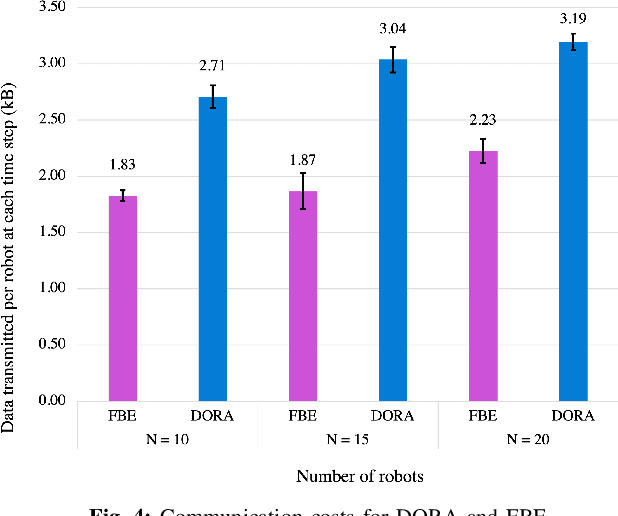
Exploration of unknown environments is an important challenge in the field of robotics. While a single robot can achieve this task alone, evidence suggests it could be accomplished more efficiently by groups of robots, with advantages in terms of terrain coverage as well as robustness to failures. Exploration can be guided through belief maps, which provide probabilistic information about which part of the terrain is interesting to explore (either based on risk management or reward). This process can be centrally coordinated by building a collective belief map on a common server. However, relying on a central processing station creates a communication bottleneck and single point of failure for the system. In this paper, we present Distributed Online Risk-Aware (DORA) Explorer, an exploration system that leverages decentralized information sharing to update a common risk belief map. DORA Explorer allows a group of robots to explore an unknown environment discretized as a 2D grid with obstacles, with high coverage while minimizing exposure to risk, effectively reducing robot failures